
Vấn đề: Trong phân tích định lượng, phương pháp bình phương tối thiểu một phần (PLS) thường thiếu một quy trình tối ưu hóa toàn cục, khiến nhà nghiên cứu không thể đánh giá mức độ phù hợp tổng thể của mô hình. Cụ thể, thuật toán điểm cố định (fixed point algorithm) của PLS chỉ phân chia tham số thành các tập con và ước lượng “một phần” thông qua phương pháp OLS, do đó không tồn tại một hàm mục tiêu duy nhất nào được tối thiểu hóa một cách nhất quán.
Định nghĩa: Phân tích thành phần cấu trúc tổng quát (Generalized Structured Component Analysis – GSCA) là phương pháp phân tích đường dẫn thay thế các nhân tố bằng các tổ hợp tuyến tính của biến quan sát. Đây là một bước tiến học thuật đột phá, được phát triển để tối ưu hóa việc phân tích cấu trúc dựa trên thành phần (component-based SEM).
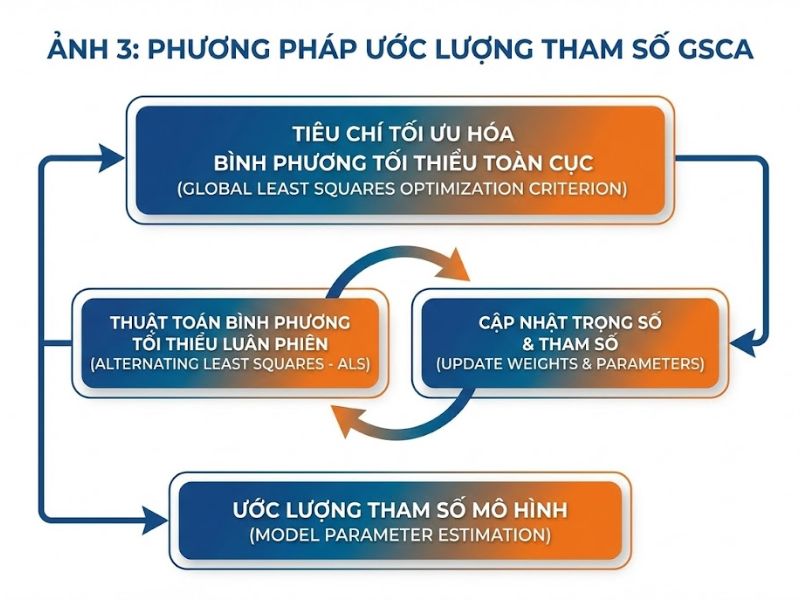
Giải pháp: GSCA sử dụng thuật toán bình phương tối thiểu luân phiên (ALS), thiết lập một tiêu chí tối ưu hóa toàn cục nhất quán, giúp khắc phục nhược điểm của PLS mà vẫn giữ nguyên ưu điểm không yêu cầu khắt khe về phân phối dữ liệu. Nhờ vào việc loại bỏ được sự phụ thuộc vào các giả định phân phối chuẩn đa biến, phương pháp GSCA tránh được hoàn toàn các nghiệm sai (improper solutions) như phương sai âm hay tương quan lớn hơn 1, đồng thời mang lại các ước lượng điểm thành phần duy nhất (unique component scores).

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: Generalized Structured Component Analysis
- Tiêu đề tiếng Việt: Phân tích thành phần cấu trúc tổng quát
- Tác giả: Heungsun Hwang & Yoshio Takane
- Tạp chí: Psychometrika (2004)
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Phương pháp Partial Least Squares (PLS) truyền thống được sử dụng rộng rãi để ước lượng tham số mô hình thông qua thuật toán điểm cố định (fixed point algorithm). Tuy nhiên, PLS gặp hạn chế lớn nhất là không giải quyết được bài toán tối ưu hóa toàn cục. Việc thiếu đi thước đo mức độ phù hợp tổng thể (overall goodness of fit) khiến các nhà nghiên cứu gặp khó khăn khi so sánh sự phù hợp của các mô hình thay thế. Sự thiếu hụt này dẫn đến hệ quả là các nhà khoa học không thể khẳng định chắc chắn mô hình PLS của họ có thực sự hội tụ về mức tối ưu theo một tiêu chuẩn thống kê nghiêm ngặt hay không.
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Phân tích thành phần cấu trúc tổng quát (Generalized Structured Component Analysis) được xây dựng dựa trên truyền thống của phân tích thành phần (component analysis). Lý thuyết này hợp nhất mô hình cấu trúc (giữa các thành phần) và mô hình đo lường (giữa biến quan sát và thành phần) vào chung một khung đại số thống nhất. GSCA xây dựng một tiêu chí tối ưu hóa duy nhất (tối thiểu hóa tổng bình phương phần dư) thông qua thuật toán bình phương tối thiểu luân phiên (ALS). Quá trình này được thực hiện qua hai bước luân phiên liên tục: cập nhật siêu ma trận chứa hệ số tải và hệ số đường dẫn, sau đó cập nhật trọng số thành phần, cho đến khi sự chênh lệch hàm mục tiêu tiệm cận về dưới mức 0.0001 (10^-4).
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
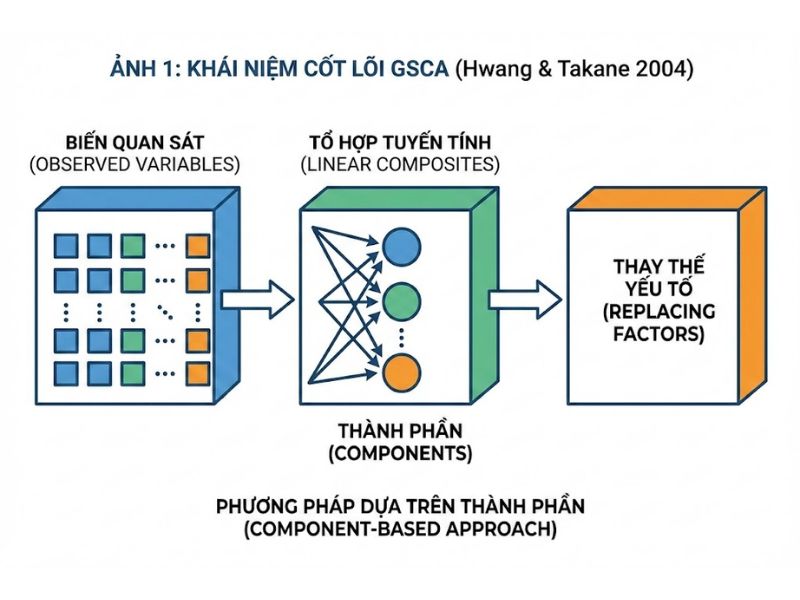
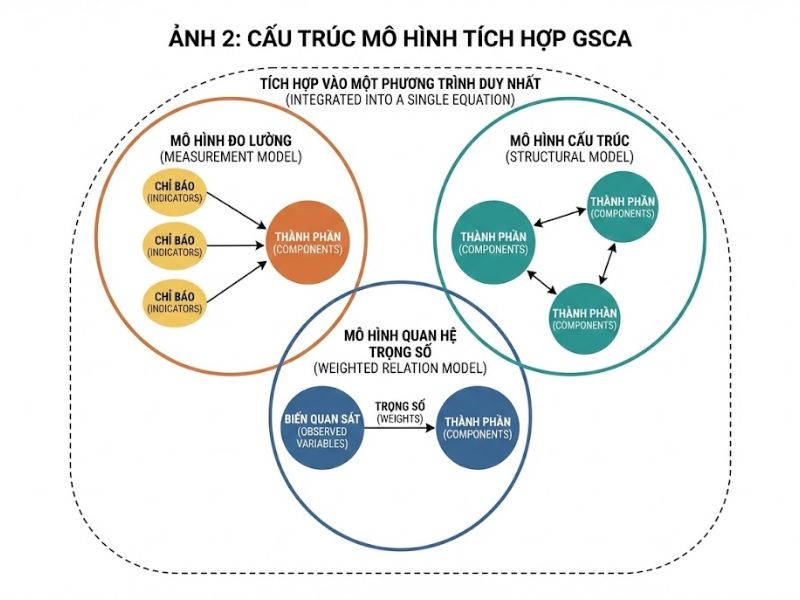
- Định nghĩa chính xác: Phân tích thành phần cấu trúc tổng quát (Generalized Structured Component Analysis) là một phương pháp thống kê thuộc nhánh phân tích đa biến, thay thế các nhân tố tiềm ẩn (latent factors) bằng các tổ hợp tuyến tính chính xác của các biến quan sát. Khác với mô hình cấu trúc hiệp phương sai (CB-SEM), phương pháp này loại bỏ hoàn toàn vấn đề không xác định điểm số nhân tố (factor score indeterminacy).
- Phân tích cấu trúc: GSCA là một cấu trúc đa hướng và linh hoạt. Khái niệm này bao gồm các ma trận thành phần cốt lõi:
- Trọng số thành phần (Component weights – ma trận V, W): Dùng để xác định mức độ đóng góp của từng biến quan sát vào thành phần tổng.
- Hệ số tải (Component loadings – ma trận C): Đo lường tác động từ thành phần lên các biến quan sát.
- Hệ số đường dẫn (Path coefficients – ma trận B): Xác định mối quan hệ nhân quả cấu trúc giữa các thành phần với nhau.
GSCA linh hoạt xử lý được cả chỉ báo định dạng (formative indicators) và phản ánh (reflective indicators), đồng thời hỗ trợ cấu trúc bậc cao (higher-order components) và so sánh đa nhóm (multi-group comparisons) với các ràng buộc chéo. Nhờ hợp nhất mọi yếu tố vào một phương trình đại số ZV = ZWA + E, GSCA vượt trội hơn hẳn các phương pháp khác trong việc đánh giá đồng thời cấu trúc đo lường và cấu trúc đường dẫn.
3. Quy Trình Phát Triển Thang Đo (Scale Development Process)
Để chứng minh tính hiệu quả của mô hình Phân tích thành phần cấu trúc tổng quát, nhóm tác giả đã tiến hành hai quy trình kiểm định nghiêm ngặt nhằm đánh giá tính ổn định của thuật toán ALS:
- Giai đoạn 1: Mô phỏng Monte-Carlo (Đánh giá trên mẫu nhỏ): * Kích thước mẫu (Z) được thay đổi từ 10, 30, 50, 75, 100 đến 200 quan sát. Thuật toán được lặp lại 1.000 lần cho mỗi kích thước. Việc khởi tạo giá trị được gán bằng thông số thực của quần thể để tăng tốc độ hội tụ và độ chính xác của hàm tiêu chí.
- Kết quả: Ngay cả với mẫu cực nhỏ (N=10), hệ số tương đẳng (congruence coefficient) trung bình đạt 0,908 (lớn hơn quy tắc kinh nghiệm 0,90). Với mẫu N=50, GSCA phục hồi tham số xuất sắc và hội tụ 100%. Điều này khẳng định GSCA hoàn toàn đáng tin cậy cho các nghiên cứu có kích thước mẫu giới hạn.
- Giai đoạn 2: Phân tích thực nghiệm (Dữ liệu Nhận dạng tổ chức):
- Dữ liệu dựa trên nghiên cứu của Bergami & Bagozzi (2000), thực hiện trên N=305 nhân viên (157 nam, 148 nữ) tại một tập đoàn điện tử ở Hàn Quốc.
- Sử dụng 21 biến quan sát để trích xuất thành 4 thành phần cốt lõi nhằm kiểm tra các hệ số tải và hệ số đường dẫn. Quá trình này cũng tính toán sai số chuẩn (standard errors) bằng phương pháp lấy mẫu lại Bootstrap 100 lần, cho phép đánh giá chính xác độ tin cậy của các tham số ước lượng.
4. Thang Đo Lường Chính Thức (Measurement Scale)
Dưới đây là hệ thống thang đo chính thức 21 biến quan sát được sử dụng để kiểm định mô hình GSCA. Nhà nghiên cứu có thể sử dụng trực tiếp bảng hỏi này để tiến hành khảo sát thực địa.
- Loại thang đo: Likert 5 điểm (1: Hoàn toàn không đồng ý; 2: Không đồng ý; 3: Không có ý kiến; 4: Đồng ý; 5: Hoàn toàn đồng ý).
| Mã Biến | Tiếng Anh gốc (Original English) | Bản dịch Tiếng Việt (Vietnamese Translation) |
| Uy tín tổ chức (Organization prestige) | ||
| org_pre1 | My relatives and people close or important to me believe that [Company X] is a well-known company. | Người thân và những người gần gũi tin rằng [Công ty X] là một công ty nổi tiếng. |
| org_pre2 | My relatives and people close or important to me believe that [Company X] is a highly respected company. | Người thân và những người gần gũi tin rằng [Công ty X] là một công ty rất được kính trọng. |
| org_pre3 | My relatives and people close or important to me believe that [Company X] is an admired company. | Người thân và những người gần gũi tin rằng [Công ty X] là một công ty được ngưỡng mộ. |
| org_pre4 | My relatives and people close or important to me believe that [Company X] is a prestigious company. | Người thân và những người gần gũi tin rằng [Công ty X] là một công ty uy tín. |
| org_pre5 | People in general think that [Company X] is a well-known company. | Mọi người nói chung nghĩ rằng [Công ty X] là một công ty nổi tiếng. |
| org_pre6 | People in general think that [Company X] is a highly respected company. | Mọi người nói chung nghĩ rằng [Công ty X] là một công ty rất được kính trọng. |
| org_pre7 | People in general think that [Company X] is an admired company. | Mọi người nói chung nghĩ rằng [Công ty X] là một công ty được ngưỡng mộ. |
| org_pre8 | People in general think that [Company X] is a prestigious company. | Mọi người nói chung nghĩ rằng [Công ty X] là một công ty uy tín. |
| Nhận dạng tổ chức (Organizational identification) | ||
| org_ident1 | When someone criticizes [Company X] it feels like a personal insult. | Khi ai đó chỉ trích [Công ty X], tôi cảm thấy như một sự xúc phạm cá nhân. |
| org_ident2 | I am very interested in what others think about [Company X]. | Tôi rất quan tâm đến những gì người khác nghĩ về [Công ty X]. |
| org_ident3 | When I talk about [Company X], I usually say “we” rather than “they”. | Khi nói về [Công ty X], tôi thường nói “chúng tôi” thay vì “họ”. |
| org_ident4 | [Company X’s] successes are my successes. | Thành công của [Công ty X] là thành công của tôi. |
| org_ident5 | When someone praises [Company X] it feels like a personal compliment. | Khi ai đó khen ngợi [Công ty X], tôi cảm thấy như một lời khen cá nhân. |
| org_ident6 | If a story in the media criticized [Company X], I would feel embarrassed. | Nếu một phương tiện truyền thông chỉ trích [Công ty X], tôi sẽ cảm thấy xấu hổ. |
| Cam kết cảm xúc – niềm vui (Affective commitment – joy) | ||
| ac_joy1 | I would be very happy to spend the rest of my career with [Company X]. | Tôi sẽ rất hạnh phúc khi dành phần còn lại của sự nghiệp tại [Công ty X]. |
| ac_joy2 | I enjoy discussing [Company X] with people outside of it. | Tôi thích thảo luận về [Công ty X] với những người bên ngoài. |
| ac_joy3 | I really feel the problems of [Company X] are my own. | Tôi thực sự cảm thấy các vấn đề của [Công ty X] là vấn đề của riêng tôi. |
| ac_joy4 | [Company X] has a great deal of personal meaning for me. | [Công ty X] có ý nghĩa cá nhân rất lớn đối với tôi. |
| Cam kết cảm xúc – tình yêu (Affective commitment – love) | ||
| ac_love1 | I do not feel like part of a family at [Company X]. | Tôi không cảm thấy như một phần của gia đình tại [Công ty X]. |
| ac_love2 | I do not feel emotionally attached to [Company X]. | Tôi không cảm thấy gắn bó về mặt cảm xúc với [Công ty X]. |
| ac_love3 | I do not feel a strong sense of belonging to [Company X]. | Tôi không cảm thấy cảm giác thuộc về mạnh mẽ đối với [Công ty X]. |
5. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
Dựa trên việc ứng dụng GSCA vào dữ liệu thực nghiệm, mạng lưới quan hệ lý thuyết của mô hình hành vi tổ chức được xác lập như sau:
- Tiền tố (Antecedents): Uy tín tổ chức (Organization prestige) đóng vai trò là biến độc lập khởi tạo. GSCA chứng minh rằng uy tín tổ chức có tác động tích cực và đáng kể đến nhận dạng tổ chức ở cả nhóm nam (hệ số 0.37) và nữ (hệ số 0.35). Điều này khẳng định nhận thức của nhân viên về đánh giá của người ngoài đối với tổ chức là tác nhân mạnh mẽ nhất hình thành nên sự liên kết bản ngã của họ với công ty.
- Trung gian (Mediator): Nhận dạng tổ chức (Organizational identification). Đây là cơ chế tâm lý cốt lõi, chuyển hóa sự tự hào từ uy tín bên ngoài thành các hành vi gắn kết bên trong.
- Hậu tố (Consequences): Nhận dạng tổ chức tạo ra tác động trực tiếp đến hai biến phụ thuộc:
- Cam kết cảm xúc – niềm vui: Tác động tích cực (nhân viên có mức độ nhận dạng cao sẽ có niềm vui gắn kết cao).
- Cam kết cảm xúc – tình yêu: Tác động tiêu cực/nghịch biến tới các câu hỏi mang tính phủ định (nhân viên nhận dạng cao sẽ KHÔNG cảm thấy xa lạ hay thiếu gắn bó với tổ chức).
6. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Với tư cách là người hướng dẫn nghiên cứu khoa học, tôi khuyến nghị các nghiên cứu sinh áp dụng Phân tích thành phần cấu trúc tổng quát trong các trường hợp sau:
- Khi thực hiện So sánh đa nhóm (Multi-group Analysis): Thay vì phải chạy hai mô hình rời rạc và không thể đối chiếu tham số như PLS, hãy sử dụng GSCA để đưa tất cả các nhóm (ví dụ: Nam/Nữ, Thế hệ Gen Z/Millennials) vào một hệ phương trình duy nhất. Điều này cho phép bạn đặt “ràng buộc bằng nhau” (equality constraints) để kiểm tra xem một biến số tác động lên các nhóm có thực sự khác biệt hay không.
- Khi mô hình có sự xuất hiện của cấu trúc bậc cao (Higher-order constructs): Nếu khái niệm nghiên cứu của bạn được cấu thành từ các thành phần con (ví dụ: Năng lực cạnh tranh bao gồm nhân sự, tài chính, công nghệ), phương pháp GSCA cho phép xử lý các thành phần bậc 1 như những chỉ báo phản ánh của thành phần bậc 2 một cách trực tiếp mà không gây ra hiện tượng không xác định điểm số.
- Mở rộng hướng nghiên cứu: Các bạn có thể tích hợp GSCA với các thuật toán gán giá trị bình phương tối thiểu (least squares imputation) để xử lý dữ liệu bị khuyết (missing data), hoặc sử dụng chuyển đổi dữ liệu phân loại (categorical variables) tối ưu hóa thang đo. Khả năng bao hàm cả phân tích hồi quy, ANOVA và phân tích phân biệt khiến GSCA trở thành một siêu công cụ định lượng (super-tool).
7. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Từ nền tảng của GSCA và kết quả phân tích thang đo trên, các nhà quản lý doanh nghiệp và Marketer cần tập trung vào các hành động thực tiễn sau:
- Quản trị truyền thông nội bộ: Kết quả chứng minh “Uy tín tổ chức” quyết định “Nhận dạng tổ chức”. Doanh nghiệp không chỉ cần đánh bóng thương hiệu với khách hàng mà phải đảm bảo nhân viên nhận thức được sự uy tín đó thông qua lăng kính của người thân/bạn bè họ (word-of-mouth). Các giám đốc nhân sự cần biến mỗi nhân viên thành một đại sứ thương hiệu tự hào.
- Đánh giá sức khỏe nhân sự bằng dữ liệu chuẩn xác: Các nhà quản trị nhân sự (HR) có thể trực tiếp sử dụng bộ thang đo 21 items này để khảo sát định kỳ. Khi phân tích bằng thuật toán ALS của GSCA, HR sẽ thu được điểm số thành phần duy nhất (unique score) của từng nhân sự, từ đó khoanh vùng được những nhân sự đang “giảm sút cam kết cảm xúc” để có chế độ giữ chân nhân tài kịp thời. Việc sở hữu một điểm số duy nhất không bị sai lệch cho phép phân loại và xếp hạng nhân viên một cách minh bạch.
8. Các Câu Hỏi Thường Gặp (FAQ)
Sự khác biệt cốt lõi giữa Phân tích thành phần cấu trúc tổng quát (Generalized Structured Component Analysis – GSCA) và Partial Least Squares (PLS) là gì?
GSCA cung cấp một tiêu chí tối ưu hóa toàn cục để ước lượng tham số và tính toán được mức độ phù hợp tổng thể của mô hình (Fit index, GoF), trong khi PLS chỉ tối ưu hóa cục bộ từng phần và hoàn toàn thiếu cơ chế đánh giá độ phù hợp tổng thể. Hơn thế nữa, GSCA dễ dàng thực hiện phân tích đa nhóm với các ràng buộc nghiêm ngặt, điều kiện mà PLS không thể xử lý trong cùng một phương trình.
Làm sao để tránh bài toán “cực tiểu phi toàn cục” (nonglobal minimum problem) khi sử dụng thuật toán ALS trong GSCA?
Giải pháp nhanh nhất là sử dụng các giá trị khởi tạo hợp lý (rational starts) từ các phân tích thành phần có ràng buộc, hoặc lặp lại quy trình ALS nhiều lần với các điểm khởi tạo ngẫu nhiên và chọn kết quả có tổng sai số nhỏ nhất. Việc sử dụng kỹ thuật Bootstrap cũng giúp xác minh tính ổn định của tham số (thông qua Standard Errors).
Chỉ số Fit = 0.60 trong phân tích GSCA mang ý nghĩa thực tiễn thế nào?
Chỉ số Fit = 0.60 (hay giá trị R²) chỉ ra rằng 60% tổng phương sai của tất cả các biến nội sinh trong mô hình đã được giải thích thành công bởi các dự đoán của cấu trúc lý thuyết được thiết lập. Đây là con số đo lường độ tin cậy mạnh mẽ của mô hình, chứng minh rằng biến quan sát được thiết kế phản ánh rất sát với thực tế dữ liệu thu thập được.
9. Tài Liệu Tham Khảo (References)
- Allen, N. J., & Meyer, J. P. (1990). The measurement and antecedents of affective, continuance and normative commitment to the organization. Journal of Occupational Psychology, 63, 1-18.
- Beaton, A. E., & Tukey, J. W. (1974). The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data. Technometrics, 16, 147-185.
- Bergami, M., & Bagozzi, R. P. (2000). Self-categorization, affective commitment and group self-esteem as distinct aspects of social identity in the organization. British Journal of Social Psychology, 39, 555-577.
- Bock, R. D., & Bargmann, R. E. (1966). Analysis of covariance structures. Psychometrika, 31, 507-534.
- Böckenholt, U., & Takane, Y. (1994). Linear constraints in correspondence analysis. Trong M. J. Greenacre & J. Blasius (Biên tập), Correspondence Analysis in Social Sciences (tr. 112-127). London: Academic Press.
- Bollen, K. A. (1989). Structural Equations with Latent Variables. New York: John Wiley and Sons.
- Bookstein, F. L. (1982). Soft modeling: The basic design and some extensions. Trong K. G. Jöreskog và H. Wold (Biên tập), Systems under Indirect Observations II (tr. 55-74). Amsterdam: North-Holland.
- Browne, M. W., & Cudeck, R. (1993). Alternative ways to assessing model fit. Trong K. A. Bollen & J. S. Long (Biên tập), Testing Structural Equation Models (tr. 136-162). Newbury Park, CA: Sage Publications.
- Chin, W. W. (2001). PLS-Graph User’s Guide Version 3.0. Soft Modeling Inc.
- Coolen, H., & de Leeuw, J. (1987). Least squares path analysis with optimal scaling. Bài báo trình bày tại Hội nghị chuyên đề quốc tế lần thứ 5 về Phân tích Dữ liệu và Tin học. Versailles, Pháp.
- de Leeuw, J., Young, F. W., & Takane, Y. (1976). Additive structure in qualitative data: An alternating least squares method with optimal scaling features. Psychometrika, 41, 471-503.
- Efron, B. (1982). The Jackknife, the Bootstrap and Other Resampling Plans. Philadelphia: SIAM.
- Efron, B. (1994). Missing data, imputation, and the bootstrap. Journal of the American Statistical Association, 89, 463-475.
- Fornell, C., & Bookstein, F. L. (1982). Two structural equation models: LISREL and PLS applied to consumer exit-voice theory. Journal of Marketing Research, 19, 440-452.
- Fornell, C., & Cha, J. (1994). Partial least squares. Trong R. P. Bagozzi (Biên tập), Advanced Methods of Marketing Research (tr. 52-78). Oxford: Blackwell.
- Gabriel, K. R., & Zamir, S. (1979). Low rank approximation of matrices by least squares with any choice of weights. Technometrics, 21, 489-498.
- Griep, M. I., Wakeling, I. N., Vankeerberghen, P., & Massart, D. L. (1995). Comparison of semirobust and robust partial least squares procedures. Chemometrics and Intelligent Laboratory Systems, 29, 37-50.
- Hanafi, M., & Qannari, E. M. (2002). An alternative algorithm to the PLS B problem. Bài báo đã nộp để xuất bản.
- Hwang, H., & Takane, Y. (2002). Structural equation modeling by extended redundancy analysis. Trong S. Nishisato, Y. Baba, H. Bozdogan, và K. Kanefuji (Biên tập), Measurement and Multivariate Analysis (tr. 115-124). Tokyo: Springer Verlag.
- Jöreskog, K. G. (1970). A general method for analysis of covariance structures. Biometrika, 57, 409-426.
- Kiers, H. A. L., Takane, Y., & ten Berge, J. M. F. (1996). The analysis of multitrait-multimethod matrices via constrained components analysis. Psychometrika, 61, 601-628.
- Lyttkens, E. (1968). On the fixed-point property of Wold’s iterative estimation method for principal components. Trong P. R. Krishnaiah (Biên tập), Multivariate Analysis (tr. 335-350). New York: Academic Press.
- Lyttkens, E. (1973). The fixed-point method for estimating interdependent systems with the underlying model specification. Journal of the Royal Statistical Society, A 136, 353-394.
- Mael, F. A. (1988). Organizational Identification: Construct Redefinition and a Field Application with Organizational Alumni. Luận án tiến sĩ chưa xuất bản, Đại học Wayne State.
- McDonald, R. P. (1996). Path analysis with composite variables. Multivariate Behavioral Research, 31, 239-270.
- Meredith, W., & Millsap, R. E. (1985). On component analysis. Psychometrika, 50, 495-507.
- Micceri, T. (1989). The unicorn, the normal curve, and other improvable creatures. Psychological Bulletin, 105, 156-166.
- Mulaik, S. A. (1972). The Foundations of Factor Analysis. New York: McGraw-Hill.
- Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., & Chen, F. (2001). Monte Carlo experiments: Design and implementation. Structural Equation Modeling, 8, 287-312.
- Schönemann, P. H., & Steiger, J. H. (1976). Regression component analysis. British Journal of Mathematical and Statistical Psychology, 29, 175-189.
- Schafer, J. L. (1997). Analysis of Incomplete Multivariate Data. New York: Chapman & Hall/CRC.
- Seber, G. A. F. (1984). Multivariate Observations. New York: John Wiley and Sons.
- Takane, Y., Kiers, H., & de Leeuw, J. (1995). Component analysis with different sets of constraints on different dimensions. Psychometrika, 60, 259-280.
- Takane, Y., Yanai, H., & Mayekawa, S. (1991). Relationships among several methods of linearly constrained correspondence analysis. Psychometrika, 56, 667-684.
- ten Berge. J. M. F. (1993). Least Squares Optimization in Multivariate Analysis. Leiden: DSWO Press.
- Tucker, L. R. (1951). A method for synthesis of factor analysis studies (Báo cáo mục Nghiên cứu Nhân sự Số 984). Washington, DC: Bộ Lục quân Hoa Kỳ.
- Wold, H. (1965). A fixed-point theorem with econometric background, I-II. Arkiv for Matematik, 6, 209-240.
- Wold, H. (1966). Estimation of principal components and related methods by iterative least squares. Trong P. R. Krishnaiah (Biên tập), Multivariate Analysis (tr. 391-420). New York: Academic Press.
- Wold, H. (1973). Nonlinear iterative partial least squares (NIPALS) modeling: Some current developments. Trong P. R. Krishnaiah (Biên tập), Multivariate Analysis (tr. 383-487). New York: Academic Press.
- Wold, H. (1981). The Fixed Point Approach to Interdependent Systems. Amsterdam: North Holland.
- Wold, H. (1982). Soft modeling: The basic design and some extensions. Trong K. G. Jöreskog và H. Wold (Biên tập), Systems under Indirect Observations II (tr. 1-54). Amsterdam: North-Holland.
- Young, F. W. (1981). Quantitative analysis of qualitative data. Psychometrika, 46, 357-388.
10. Lời kêu gọi hành động (CTA)
Việc thấu hiểu và làm chủ Phân tích thành phần cấu trúc tổng quát (Generalized Structured Component Analysis) không chỉ giúp nghiên cứu của bạn đạt chuẩn mực học thuật quốc tế mà còn cung cấp nền tảng số liệu vững chắc để ra quyết định quản trị chiến lược. Để đi sâu vào các công thức đại số toán học và mô phỏng Monte-Carlo chi tiết, hãy tham khảo nguyên bản công trình nghiên cứu này.



