
Phân tích đa nhóm trong PLS-SEM (Multigroup Analysis – MGA) là một kỹ thuật thống kê nâng cao được sử dụng để kiểm định xem liệu các ước lượng tham số (ví dụ: trọng số đường dẫn, trọng số ngoài) có sự khác biệt mang ý nghĩa thống kê giữa các nhóm dữ liệu khác nhau hay không (ví dụ: so sánh hành vi khách hàng giữa 3 quốc gia: Anh, Pháp, Đức).
Vấn đề cấp bách hiện nay là các nhà nghiên cứu thường mắc sai lầm nghiêm trọng khi bỏ qua Kiểm định tổng thể (Omnibus Test) khi so sánh nhiều hơn hai nhóm, dẫn đến việc gia tăng Sai lầm loại I (Type I error) – tức là kết luận sai rằng có sự khác biệt trong khi thực tế không có.
Giải pháp chuẩn khoa học được đề xuất bởi Cheah et al. (2023) là tuân thủ nghiêm ngặt quy trình 3 bước:
- Đánh giá Bất biến đo lường (MICOM): Đảm bảo các khái niệm được hiểu giống nhau giữa các nhóm.
- Lựa chọn Kiểm định tổng thể: Sử dụng Kiểm định tổng quát (OTG) hoặc Kiểm định dựa trên khoảng cách phi tham số (NDT) để sàng lọc.
- So sánh từng cặp (Pairwise Comparisons): Thực hiện so sánh chi tiết nhưng bắt buộc phải áp dụng hiệu chỉnh Bonferroni hoặc Šidák để kiểm soát sai số.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1. Thông tin định danh bài báo
Để đảm bảo tính trích dẫn khoa học chuẩn xác (theo chuẩn APA) và tôn trọng bản quyền học thuật, dưới đây là thông tin định danh của công trình nghiên cứu gốc được sử dụng làm xương sống cho bài giảng này:
- Tiêu đề gốc: Multigroup analysis of more than two groups in PLS-SEM: A review, illustration, and recommendations.
- Tiêu đề tiếng Việt: Phân tích đa nhóm đối với nhiều hơn hai nhóm trong PLS-SEM: Tổng quan, minh họa và các khuyến nghị.
- Tác giả: Jun-Hwa Cheah, Suzanne Amaro, José L. Roldán.
- Tạp chí: Journal of Business Research, Tập 156, Mã bài báo 113539.
- Năm xuất bản: 2023.
1.2. Bối cảnh thực tiễn & Thực trạng nghiên cứu
Trong nghiên cứu quản trị kinh doanh, marketing và du lịch hiện đại, tính không đồng nhất (heterogeneity) của dữ liệu là một vấn đề cốt lõi không thể bỏ qua. Các giả thuyết nghiên cứu và mô hình lý thuyết thường không đúng tuyệt đối với tất cả mọi đối tượng; chúng biến thiên tùy theo đặc điểm nhân khẩu học (giới tính, thu nhập, độ tuổi), văn hóa (quốc gia, vùng miền), hoặc hành vi (tần suất mua hàng, mức độ trung thành).
Tuy nhiên, các phương pháp Phân tích đa nhóm trong PLS-SEM truyền thống thường chỉ tập trung vào việc so sánh hai nhóm đơn giản (ví dụ: Nam vs Nữ, Khách hàng Mới vs Khách hàng Cũ). Khi nhà nghiên cứu đối mặt với biến phân loại có nhiều hơn hai nhóm (ví dụ: So sánh Thế hệ X, Y, Z), họ thường mắc sai lầm là thực hiện ngay các phép so sánh từng cặp (t-test) mà không thực hiện kiểm định tổng thể trước đó.
Dựa trên khảo sát tài liệu toàn diện từ 378 bài báo nghiên cứu thực nghiệm trên cơ sở dữ liệu Science Direct và SCOPUS (tính đến năm 2021), các con số thống kê cho thấy một “lỗ hổng” lớn về phương pháp luận:
- Sự khan hiếm: Chỉ có 18% (67 bài) thực hiện so sánh từ 3 nhóm trở lên. Đa số tuyệt đối (82%) chỉ dừng lại ở việc so sánh 2 nhóm.
- Chủ đề phổ biến: Trong các nghiên cứu đa nhóm, so sánh Quốc gia chiếm tỷ trọng cao nhất (25%), tiếp theo là Nhóm tuổi (11%).
- Thiếu sót nghiêm trọng: Có tới 61% (229 bài) hoàn toàn không báo cáo việc đánh giá tính bất biến phép đo (Measurement Invariance – MICOM), dù đây là điều kiện tiên quyết bắt buộc để so sánh nhóm.
- Thiếu kiểm định nâng cao: Số lượng nghiên cứu áp dụng OTG chỉ chiếm 4.48%, hiệu chỉnh Bonferroni/Šidák chỉ chiếm 1.49% và đặc biệt chưa có nghiên cứu nào áp dụng NDT (0%).
Hàm ý: Điều này chứng tỏ phần lớn các kết luận về sự khác biệt đa nhóm trong văn thù trước đây có thể thiếu độ tin cậy do không kiểm soát sai số theo họ (family-wise error rate) và không đảm bảo tính bất biến. Nghiên cứu của Cheah et al. (2023) ra đời để lấp đầy khoảng trống này.
1.3. Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Bài báo dựa trên các nguyên lý thống kê tham số và phi tham số trong kiểm định giả thuyết khoa học:
- Lý thuyết kiểm định ý nghĩa thống kê (NHST): Sử dụng kỹ thuật Bootstrapping (lấy mẫu lại) và Permutation (hoán vị ngẫu nhiên) để xác định xem sự khác biệt giữa các nhóm có thực sự tồn tại hay chỉ do ngẫu nhiên của việc chọn mẫu.
- Kiểm định Omnibus (Omnibus Test): Tương tự như kiểm định F trong phân tích phương sai (ANOVA). Trước khi biết “nhóm nào khác nhóm nào”, nhà nghiên cứu cần trả lời câu hỏi tổng quát: “Liệu có bất kỳ sự khác biệt nào tồn tại trong tổng thể hay không?”. Đây là bước tiên quyết, đóng vai trò như “cánh cổng gác” trong quy trình MGA mở rộng.
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Để thực hiện Phân tích đa nhóm trong PLS-SEM thành công, chúng ta cần phân biệt rõ ràng các khái niệm thống kê và các trường phái kiểm định sau đây.
2.1. Phân biệt MGA 2 nhóm và MGA > 2 nhóm
| Đặc điểm | MGA 2 Nhóm (Truyền thống) | MGA > 2 Nhóm (Nâng cao) |
| Đối tượng | Nam vs Nữ; Mua vs Không mua. | Thu nhập Thấp vs Trung bình vs Cao; 3 Quốc gia trở lên. |
| Rủi ro sai lầm | Thấp. Kiểm định trực tiếp sự khác biệt t-test. | Cao. Xảy ra hiện tượng Lạm phát sai lầm loại I (Family-wise error rate) nếu không kiểm soát. |
| Quy trình chuẩn | MICOM → Permutation/Bootstrap t-test. | MICOM → Omnibus Test (OTG) hoặc NDT → Pairwise Comparison (với hiệu chỉnh Bonferroni/Šidák). |
| Công cụ hỗ trợ | SmartPLS 3, SmartPLS 4. | SmartPLS 4 (hỗ trợ tính năng OTG tự động), R (gói cSEM). |
2.2. Tranh luận kỹ thuật: OTG hay NDT?
Dữ liệu từ Cheah et al. (2023) đặt ra một cuộc tranh luận học thuật quan trọng giữa hai phương pháp kiểm định tổng thể:
a. Kiểm định tổng quát về sự khác biệt nhóm (OTG – Omnibus Test of Group Differences)
- Được Sarstedt et al. (2011) giới thiệu, phương pháp này kết hợp bootstrapping và hoán vị để tạo ra thống kê kiểm định.
- Trong quy trình MGA, OTG đóng vai trò sàng lọc sơ bộ. Nếu kết quả OTG không có ý nghĩa thống kê (p > 0.05), nhà nghiên cứu không được phép tiến hành so sánh từng cặp sâu hơn.
- Hạn chế: Klesel et al. (2022) lập luận rằng OTG thường quá nhạy cảm, dễ dẫn đến sai lầm loại I (bác bỏ giả thuyết H0 sai) khi số lượng vòng lặp bootstrap tăng lên. Nó chỉ cho biết “có sự khác biệt” nhưng không chỉ rõ sự khác biệt nằm ở tham số nào.
b. Kiểm định dựa trên khoảng cách phi tham số (NDT – Non-parametric Distance-based Test)
- Được phát triển bởi Klesel et al. (2019), đây là phương pháp so sánh ma trận tương quan chỉ báo ngụ ý của mô hình giữa các nhóm.
- Chỉ số đo lường:
- Khoảng cách Euclid bình phương trung bình (d_L): Nhạy hơn với các sai biệt nhỏ.
- Khoảng cách trắc địa trung bình (d_G): Khắt khe hơn, đo lường khoảng cách trên bề mặt cong của không gian tham số.
- Ưu điểm: Đánh giá toàn bộ mô hình (Global model assessment) thay vì từng tham số lẻ tẻ. NDT được khuyến nghị khi muốn xem xét sự khác biệt cấu trúc tổng thể.
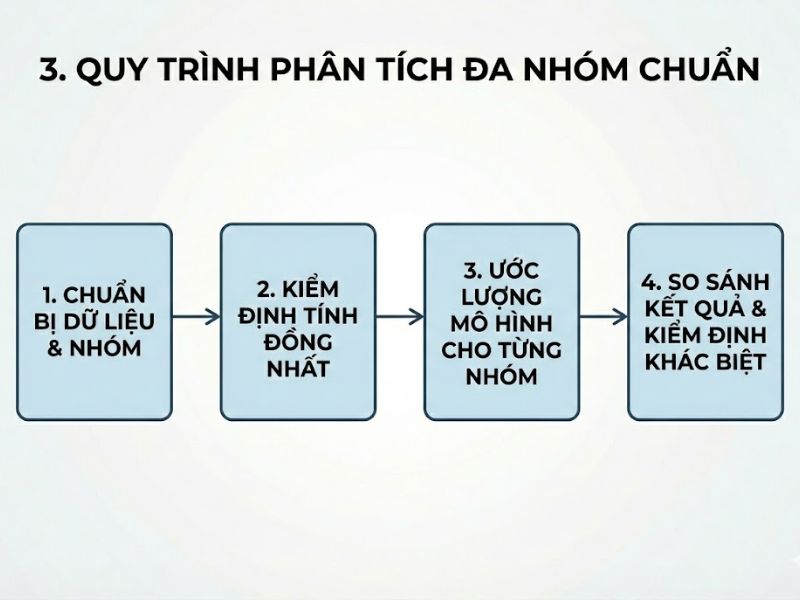
3. Quy Trình Phân Tích Đa Nhóm Chuẩn (The Standard Procedure)
Dưới đây là quy trình 4 bước chuẩn mực để thực hiện Phân tích đa nhóm trong PLS-SEM cho dữ liệu nhiều hơn 2 nhóm:
Bước 1: Chuẩn bị Dữ liệu (Data Preparation)
- Xác định nhóm: Phân chia nhóm dựa trên cơ sở lý thuyết vững chắc (ví dụ: chia theo văn hóa quốc gia, loại hình doanh nghiệp).
- Lưu ý: Tránh việc “nhị phân hóa” nhân tạo các biến liên tục (ví dụ: tự ý chia độ tuổi thành Già/Trẻ) nếu không có lý do mạnh mẽ, vì điều này làm giảm độ mạnh thống kê (Statistical Power).
- Cỡ mẫu: Đảm bảo cỡ mẫu đủ lớn (Power of 80%) và tương đương về số lượng giữa các nhóm để tránh sai lệch.
Bước 2: Đánh giá Bất biến Đo lường (MICOM)
Trước khi so sánh các hệ số đường dẫn, phải đảm bảo các khái niệm (constructs) được hiểu giống nhau giữa các nhóm.
- Bước 2a: Bất biến cấu hình (Configural Invariance): Mô hình phải giống hệt nhau về cấu trúc, chỉ báo và thuật toán xử lý ở tất cả các nhóm.
- Bước 2b: Bất biến hợp thành (Compositional Invariance): Trọng số của các chỉ báo không khác biệt đáng kể. Tương quan giữa điểm số biến tiềm ẩn gốc và biến tiềm ẩn ghép nhóm (c) phải lớn hơn hoặc bằng phân vị 5% (c_u).
- Bước 2c: Bất biến trung bình và phương sai: Cần thiết nếu muốn so sánh giá trị trung bình biến tiềm ẩn. Nếu chỉ so sánh hệ số đường dẫn, Bất biến một phần (Partial invariance) (đạt bước 2a và 2b) là đủ điều kiện.
Bước 3: Lựa chọn Kiểm định Tổng thể (OTG hoặc NDT)
- Sử dụng NDT (d_L, d_G) nếu mục tiêu là so sánh sự khác biệt trong mô hình hoàn chỉnh.
- Sử dụng OTG nếu muốn sàng lọc sơ bộ cho từng tham số (nhưng cần thận trọng vì độ nhạy cao).
- Quy tắc: Nếu p < 0.05 (có sự khác biệt tổng thể) → Chuyển sang Bước 4. Nếu không, dừng lại và kết luận không có sự khác biệt.
Bước 4: So sánh từng cặp (Post-hoc Pairwise Comparisons) với Hiệu chỉnh
Khi so sánh nhiều nhóm, số lượng phép thử tăng lên (Ví dụ: 3 nhóm = 3 phép so sánh; 4 nhóm = 6 phép so sánh). Điều này làm tăng sai số theo họ. Bắt buộc phải hiệu chỉnh P-value:
- Hiệu chỉnh Bonferroni: Phương pháp bảo thủ nhất.
- p(corrected) = α(original) / m
- (Trong đó m là số cặp so sánh).
- Hiệu chỉnh Šidák: Chính xác hơn về mặt xác suất thống kê.
- p(corrected) = 1 – (1 – α)^(1/m)
- Ví dụ thực tế: Với mức ý nghĩa mong muốn α = 0.05 và so sánh 3 nhóm (m=3 cặp), ngưỡng P-value mới theo Šidák là:
- 1 – (1 – 0.05)^(1/3) ≈ 0.017
- → Kết quả so sánh từng cặp chỉ được coi là có ý nghĩa khi p < 0.017.
4. Minh Họa Thực Nghiệm: Tình yêu Thương hiệu Điểm đến
Nghiên cứu minh họa trong bài báo sử dụng bộ dữ liệu thực tế về du lịch của sinh viên Erasmus để kiểm chứng quy trình và so sánh hiệu quả của các phương pháp.
4.1. Mô hình và Dữ liệu
- Chủ đề: Các tiền tố và kết quả của Tình yêu thương hiệu điểm đến (Destination Brand Love – DBL).
- 3 Nhóm so sánh:
- Đức (Germany, n=161)
- Ý (Italy, n=196)
- Bồ Đào Nha (Portugal, n=132)
- Công cụ phân tích: Phần mềm SmartPLS 3.3.9 và ngôn ngữ R (gói cSEM).
4.2. Thang Đo Lường Chính Thức (Measurement Scale)
Các biến quan sát được đo lường bằng Thang đo Likert 7 điểm (1 = Hoàn toàn không đồng ý, 7 = Hoàn toàn đồng ý):
a. Nhận thức Rủi ro (Perceived Risk – PR)
- PR1: I worried about the safety of myself and my family at the destination. (Tôi lo lắng về sự an toàn của bản thân và gia đình tại điểm đến).
- PR2: I worried about the political stability at the destination. (Tôi lo lắng về sự ổn định chính trị tại điểm đến).
- PR3: I worried about the quality of medical services at the destination. (Tôi lo lắng về chất lượng dịch vụ y tế tại điểm đến).
b. Hình ảnh Điểm đến (Destination Image – DI)
- DI1: Good beaches. (Những bãi biển đẹp).
- DI2: Good climate. (Khí hậu tốt).
- DI3: Interesting landscape. (Phong cảnh thú vị).
- DI4: Exotic place. (Địa điểm độc đáo/kỳ lạ).
c. Sự Hài lòng (Satisfaction – SAT)
- SAT1: I am satisfied with my decision to visit Cape Verde. (Tôi hài lòng với quyết định đến thăm Cape Verde).
- SAT2: My choice to visit Cape Verde was a wise one. (Lựa chọn đến thăm Cape Verde là một lựa chọn khôn ngoan).
- SAT3: I am happy with the visit to Cape Verde. (Tôi hạnh phúc với chuyến đi đến Cape Verde).
d. Lòng trung thành (Loyalty – LOY)
- LOY1: I will encourage my friends and relatives to visit Cape Verde. (Tôi sẽ khuyến khích bạn bè và người thân đến thăm Cape Verde).
- LOY2: I will recommend Cape Verde to others. (Tôi sẽ giới thiệu Cape Verde cho những người khác).
- LOY3: I will say positive things about Cape Verde to other people. (Tôi sẽ nói những điều tích cực về Cape Verde với người khác).
4.3. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
- Tiền tố (Antecedents):
- Nhận thức rủi ro: Dự kiến tác động tiêu cực đến Sự hài lòng.
- Hình ảnh điểm đến: Dự kiến tác động tích cực đến Sự hài lòng.
- Biến trung gian (Mediator): Sự hài lòng (Satisfaction).
- Hậu tố (Consequences): Lòng trung thành (Loyalty) và Truyền miệng điện tử (eWOM).
- Biến phân nhóm: Quốc gia (Đức, Ý, Bồ Đào Nha).

5. Phân Tích và Diễn Giải Kết Quả (Analysis & Interpretation)
Đây là phần quan trọng nhất, hướng dẫn chi tiết cách đọc và biện giải kết quả từ minh họa thực nghiệm trên, áp dụng quy trình chuẩn 3 bước.
5.1. Kết quả MICOM (Bước 2)
Trước hết, cần kiểm tra tính so sánh được của dữ liệu:
- Bất biến cấu hình: Đạt (do thiết kế mô hình giống nhau).
- Bất biến thành phần: Kết quả cho thấy tương quan gốc (c) lớn hơn ngưỡng tới hạn 5% (c_u). Quan trọng hơn, giá trị P-value của phép kiểm định hoán vị cho tất cả các biến đều lớn hơn ngưỡng hiệu chỉnh Šidák (0.017).
- Kết luận: Dữ liệu đạt Bất biến một phần (Partial Invariance). Điều này đủ điều kiện để tiến hành so sánh các hệ số đường dẫn giữa 3 quốc gia.
5.2. Kết quả OTG và NDT (Bước 3)
Sự khác biệt thú vị giữa hai phương pháp kiểm định tổng thể đã xuất hiện trong nghiên cứu này:
- Kết quả OTG: Kiểm định này báo cáo sự khác biệt có ý nghĩa thống kê ở hầu hết các đường dẫn (p < 0.001). Tuy nhiên, như lý thuyết đã cảnh báo, kết quả này có thể bị sai lệch do OTG quá nhạy cảm với số lượng mẫu lặp.
- Kết quả NDT:
- Chỉ số khoảng cách trắc địa d_G: Không có ý nghĩa thống kê (Không bác bỏ giả thuyết H0).
- Chỉ số khoảng cách Euclid d_L: Có ý nghĩa thống kê (Bác bỏ giả thuyết H0).
- Quyết định: Vì có một chỉ số (d_L) báo hiệu sự khác biệt, nhà nghiên cứu quyết định tiếp tục đi sâu vào so sánh chi tiết từng cặp.
5.3. Kết quả So sánh từng cặp (NPT) với Hiệu chỉnh (Bước 4)
Để minh họa tầm quan trọng của việc hiệu chỉnh sai số, hãy xem xét kỹ ví dụ sau:
Sử dụng công cụ tính toán, mức Alpha hiệu chỉnh theo Šidák cho 3 nhóm là ~0.017.
- Ví dụ 1: Mối quan hệ DBL → Ý định giới thiệu (Recommendation)
- So sánh cặp Đức vs Bồ Đào Nha: P-value truyền thống (chưa hiệu chỉnh) là 0.023.
- Nếu dùng chuẩn p < 0.05: Ta sẽ kết luận CÓ sự khác biệt giữa hai quốc gia này.
- Sau khi hiệu chỉnh Šidák (ngưỡng 0.017): Vì 0.023 > 0.017, ta phải kết luận KHÔNG có sự khác biệt đáng kể.
- → Bài học: Việc không hiệu chỉnh P-value sẽ dẫn đến kết luận sai lầm (Sai lầm loại I) về hành vi khách hàng, dẫn đến các quyết định quản trị sai lệch.
- Ví dụ 2: Mối quan hệ DBL → E-WOM
- Kết quả cho thấy nhóm Đức khác biệt so với nhóm Ý và Bồ Đào Nha một cách có ý nghĩa thống kê ngay cả sau khi đã hiệu chỉnh nghiêm ngặt (p < 0.001).
6. Hướng Dẫn Ứng Dụng & Hàm Ý (Implications)
6.1. Ứng dụng Nghiên cứu (Academic Implications)
Dành cho nghiên cứu sinh và giảng viên hướng dẫn:
- Bắt buộc báo cáo MICOM: Hãy dành riêng một bảng trong chương Kết quả của luận văn/bài báo để báo cáo kết quả MICOM (Bước 2). Điều này chứng minh cho hội đồng thấy tính chính xác về mặt phương pháp luận.
- Ưu tiên SmartPLS 4: Hãy sử dụng phiên bản SmartPLS 4 trở lên vì phần mềm này đã tích hợp sẵn nút tính năng “Permutation Multi-Group Analysis” bao gồm cả kiểm định OTG tự động, giúp giảm thiểu sai sót tính toán thủ công.
- Thận trọng với P-value: Khi so sánh 3 nhóm trở lên, hãy nhớ rằng ngưỡng ý nghĩa thống kê mặc định p < 0.05 là không hợp lệ. Bắt buộc phải tính toán và sử dụng ngưỡng p < α(corrected) (theo công thức Bonferroni hoặc Šidák).
- Chiến lược lựa chọn: Sử dụng NDT khi muốn so sánh sự khác biệt của toàn bộ cấu trúc mô hình, và sử dụng NPT (Permutation Test) khi muốn so sánh các đường dẫn cụ thể.
6.2. Ứng dụng Quản trị Doanh nghiệp (Managerial Implications)
Kết quả từ Phân tích đa nhóm trong PLS-SEM giúp nhà quản trị đưa ra quyết định “may đo” (tailored strategies) chính xác hơn:
- Phân khúc thị trường: Nếu kết quả (sau khi hiệu chỉnh) khẳng định nhóm khách hàng Đức và Ý thực sự khác biệt về độ nhạy cảm giá, doanh nghiệp cần thiết kế hai chiến lược định giá riêng biệt.
- Tối ưu hóa nguồn lực: Ngược lại, nếu kiểm định cho thấy không có sự khác biệt (như ví dụ DBL → Recommendation ở trên), doanh nghiệp có thể tự tin áp dụng một quy trình chuẩn hóa (standardized) cho cả hai thị trường Đức và Bồ Đào Nha để tiết kiệm chi phí vận hành, thay vì lãng phí ngân sách để địa phương hóa (localize) không cần thiết.
7. Các Hướng Nghiên Cứu Tương Lai (Future Research)
Dựa trên những hạn chế hiện tại, bài báo của Cheah et al. (2023) đề xuất các hướng nghiên cứu mở rộng:
- So sánh PLS-SEM và CB-SEM: Cần có thêm nghiên cứu so sánh kết quả MGA > 2 nhóm giữa phương pháp bình phương tối thiểu riêng phần (PLS-SEM) và mô hình cấu trúc hiệp phương sai (CB-SEM).
- Mở rộng sang phương pháp khác: Áp dụng quy trình chuẩn này cho các phương pháp dựa trên thành phần khác như GSCA (Generalized Structured Component Analysis) hay RGCCA (Regularized Generalized Canonical Correlation Analysis).
- Mô phỏng Monte Carlo: Thực hiện các nghiên cứu mô phỏng để so sánh độ mạnh thống kê (statistical power) và độ chính xác của các phương pháp điều chỉnh p-value khác nhau (Bonferroni, Šidák, Holm, v.v.) trong bối cảnh đặc thù của PLS-SEM.
8. Các Câu Hỏi Thường Gặp (FAQ)
1. Tại sao tôi không thể chạy MGA so sánh từng cặp ngay lập tức mà phải chạy Omnibus Test (OTG) hoặc NDT?
Nếu bạn chạy nhiều phép kiểm định t-test độc lập trên cùng một bộ dữ liệu, xác suất mắc sai lầm loại I (kết luận sai là có sự khác biệt) sẽ tăng lên theo cấp số nhân (Family-wise error rate). OTG và NDT đóng vai trò như các bộ lọc giúp kiểm soát rủi ro này ngay từ đầu, đảm bảo tính khoa học của kết luận.
2. Nếu kết quả MICOM cho thấy không đạt “Bất biến hợp thành” (Compositional Invariance), tôi phải làm gì?
Điều này có nghĩa là cấu trúc ý nghĩa của biến tiềm ẩn đã thay đổi giữa các nhóm. Bạn không thể tiến hành Phân tích đa nhóm (MGA) cho biến đó. Giải pháp là xem xét loại bỏ các biến quan sát (items) gây ra sự khác biệt hoặc chấp nhận rằng khái niệm này có ý nghĩa hoàn toàn khác nhau giữa các nhóm (đặc thù văn hóa) và không thể so sánh trực tiếp.
3. Có công cụ nào khác ngoài SmartPLS để chạy phân tích này không?
Có, bạn có thể sử dụng ngôn ngữ lập trình R (với các gói thư viện như semPLS hoặc cSEM) hoặc phần mềm ADANCO. Trong đó, R đặc biệt mạnh mẽ và linh hoạt cho các kiểm định NDT mới nhất mà một số phần mềm đồ họa chưa cập nhật kịp.
9. Tài Liệu Tham Khảo (References)
Dưới đây là danh sách tài liệu tham khảo gốc từ bài báo, được giữ nguyên định dạng chuẩn APA để phục vụ tra cứu:
Aguinis, H., Edwards, J. R., & Bradley, K. J. (2017). Improving our understanding of moderation and mediation in strategic management research. Organizational Research Methods, 20(4), 665-685.
Aguirre-Urreta, M., & Rönkkö, M. (2015). Sample Size Determination and Statistical Power Analysis in PLS Using R: An Annotated Tutorial. Communications of the Association for Information Systems, 36, 33-51.
Ahmad, W., Kim, W. G., Choi, H. M., & Haq, J. U. (2021). Modeling behavioral intention to use travel reservation apps: A cross-cultural examination between US and China. Journal of Retailing and Consumer Services, 63, 102689.
Amaro, S., Barroco, C., & Antunes, J. (2020). Exploring the antecedents and outcomes of destination brand love. Journal of Product & Brand Management, 30(3), 433-448.
Arsenovic, J., De Keyser, A., Edvardsson, B., Tronvoll, B., & Gruber, T. (2021). Justice (is not the same) for all: The role of relationship activity for post-recovery outcomes. Journal of Business Research, 134, 342-351.
Assaker, G., Hallak, R., Assaf, A. G., & Assad, T. (2015). Validating a Structural Model of Destination Image, Satisfaction, and Loyalty Across Gender and Age: Multigroup Analysis with PLS-SEM. Tourism Analysis, 20(6), 577-591.
Basco, R., Hernández-Perlines, F., & Rodríguez-García, M. (2020). The effect of entrepreneurial orientation on firm performance: A multigroup analysis comparing China, Mexico, and Spain. Journal of Business Research, 113, 409-421.
Becker, J.-M., Cheah, J.-H., Gholamzade, R., Ringle, C. M., & Sarstedt, M. (2022). PLS-SEM’s most wanted guidance. International Journal of Contemporary Hospitality Management.
Becker, J.-M., Rai, A., Ringle, C. M., & Völckner, F. (2013). Discovering unobserved heterogeneity in structural equation models to choose between gloabl and segment-specific path models. MIS Quarterly, 37(3), 665-689.
Bortz, J., Lienert, G. A., & Boehnke, K. (2003). Verteilungsfreie Methoden in der Biostatistik (3 ed.). Springer.
Bruhn, M., Georgi, D., & Hadwich, K. (2008). Customer equity management as formative second-order construct. Journal of Business Research, 61(12), 1292-1301.
Carranza, R., Díaz, E., Martín-Consuegra, D., & Fernández-Ferrín, P. (2020). PLS-SEM in business promotion strategies. A multigroup analysis of mobile coupon users using MICOM. Industrial Management & Data Systems, 120(12), 2349-2374.
Cheah, J. H., Thurasamy, R., Memon, M. A., Chuah, F., & Ting, H. (2020). Multigroup analysis using SmartPLS: Step-by-step guidelines for business research. Asian Journal of Business Research, 10(3).
Cheah, J. H., Nitzl, C., Roldán, J. L., Cepeda-Carrion, G., & Gudergan, S. P. (2021). A primer on the conditional mediation analysis in PLS-SEM. The DATABASE for Advances in Information Systems, 52(SI), 43-100.
Cheah, J. H., Sarstedt, M., Ringle, C. M., Ramayah, T., & Ting, H. (2018). Convergent validity assessment of formatively measured constructs in PLS-SEM: On using single-item versus multi-item measures in redundancy analyses. International Journal of Contemporary Hospitality Management, 30(11), 3192-3210.
Chin, W. W. (2003). A permutation procedure for multigroup comparison of PLS models. In Proceedings of the International Symposium PLS 03 (pp. 33-43).
Chin, W., Cheah, J.-H., Liu, Y., Ting, H., Lim, X.-J., & Cham, T. H. (2020). Demystifying the role of causal-predictive modeling using partial least squares structural equation modeling in information systems research. Industrial Management & Data Systems, 120(12), 2161-2209.
Chin, W. W., & Dibbern, J. (2010). An introduction to a permutation-based procedure for multigroup PLS analysis. In Handbook of partial least squares (pp. 171-193). Springer.
Chin, W. W., Mills, A. M., Steel, D. J., & Schwarz, A. (2012). Multi-Group Invariance Testing: An Illustrative Comparison of PLS Permutation and Covariance-Based SEM Invariance Analysis. In 7th International Conference on Partial Least Squares.
Cohen, J. (1988). Statistical power analysis for the behavioural sciences (2nd ed.). Lawrence Erlbaum.
Dijkstra, T. K., & Henseler, J. (2015a). Consistent Partial Least Squares Path Modeling. MIS Quarterly, 39(2), 297-316.
Franke, G., & Sarstedt, M. (2019). Heuristics versus statistics in discriminant validity testing: A comparison of four procedures. Internet Research, 29(3), 430-447.
Ghasemy, M., Mohajer, L., Cepeda-Carrión, G., & Roldán, J. L. (2020). Job performance as a mediator between affective states and job satisfaction: A multigroup analysis based on gender. Current Psychology.
Gudergan, S. P., Ringle, C. M., Wende, S., & Will, A. (2008). Confirmatory tetrad analysis in PLS path modeling. Journal of Business Research, 61(12), 1238-1249.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage Learning.
Hair, J. F., Howard, M., & Nitzl, C. (2020). Assessing measurement model quality in PLS-SEM using confirmatory composite analysis. Journal of Business Research, 109, 101-110.
Hair, J. F., Hult, G. T. M., Ringle, C. M., Sarstedt, M., Danks, N. P., & Ray, S. (2022b). Partial Least Squares Structural Equation Modeling (PLS-SEM) Using R. Springer.
Hair, J. F., Page, M., & Brunsveld, N. (2020). Essentials of Business Research Methods (4th ed.). Routledge.
Hair, J. F., Risher, J. J., Sarstedt, M., & Ringle, C. M. (2019). When to use and how to report the results of PLS-SEM. European Business Review, 31(1), 2-24.
Hair, J. F., & Sarstedt, M. (2019). Factors versus Composites: Guidelines for Choosing the Right Structural Equation Modeling Method. Project Management Journal, 50(6), 619-624.
Hair, J. F., Sarstedt, M., Ringle, C. M., & Gudergan, S. P. (2018). Advanced issues in partial least squares structural equation modeling. Sage Publications.
Hair, J. F. J., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022a). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3rd ed.). SAGE Publications.
Hayes, A. F., & Preacher, K. J. (2014). Statistical mediation analysis with a multicategorical independent variable. British Journal of Mathematical and Statistical Psychology, 67(3), 451-470.
Henseler, J. (2012). PLS-MGA: A non-parametric approach to partial least squares-based multigroup analysis. In Challenges at the interface of data analysis, computer science, and optimization. Springer.
Henseler, J., & Schuberth, F. (2020). Using confirmatory composite analysis to assess emergent variables in business research. Journal of Business Research, 120, 147-156.
Henseler, J., Ringle, C. M., & Sarstedt, M. (2015). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115-135.
Henseler, J., Ringle, C. M., & Sarstedt, M. (2016). Testing measurement invariance of composites using partial least squares. International Marketing Review, 33(3), 405-431.
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6(2), 65-70.
Huaman-Ramirez, R., & Merunka, D. (2019). Brand experience effects on brand attachment: The role of brand trust, age, and income. European Business Review, 31(5), 610-645.
Hwang, H., Ho, M. R., & Lee, J. (2010). Generalized structured component analysis with latent interactions. Psychometrika, 75(2), 228-242.
Keil, M., Tan, B. C. Y., Wei, K.-K., Saarinen, T., Tuunainen, V., & Wassenaar, A. (2000). A cross-cultural study on escalation of commitment behavior in software projects. MIS Quarterly, 24(2), 299-325.
Klesel, M., Schuberth, F., Henseler, J., & Niehaves, B. (2019). A test for multigroup comparison using partial least squares path modeling. Internet Research, 29(3), 464-477.
Klesel, M., Schuberth, F., Niehaves, B., & Henseler, J. (2022). Multigroup analysis in information systems research using PLS-PM: A systematic investigation of approaches. The DATABASE for Advances in Information Systems, 53(3), 26-48.
Kock, N., & Hadaya, P. (2018). Minimum sample size estimation in PLS-SEM: The inverse square root and gamma-exponential methods. Information Systems Journal, 28(1), 227-261.
Lee, R., & Lockshin, L. (2021). Halo Effects of Tourists’ Destination Image on Domestic Product Perceptions. Australasian Marketing Journal, 19(1), 7-13.
Liengaard, B. D., Sharma, P. N., Hult, G. T. M., Jensen, M. B., Sarstedt, M., Hair, J. F., & Ringle, C. M. (2021). Prediction: Coveted, yet forsaken? Introducing a cross-validated predictive ability test in partial least squares path modeling. Decision Sciences, 52(2), 362-392.
Lim, X. J., Cheah, J. H., Ng, S. I., Basha, N. K., & Liu, Y. (2021). Are men from Mars, women from Venus? Examining gender differences towards continuous use intention of branded apps. Journal of Retailing and Consumer Services, 60, 102422.
MacKenzie, S. B., Podsakoff, P. M., & Jarvis, C. B. (2005). The problem of measurement model misspecification in behavioral and organizational research. Journal of Applied Psychology, 90(4), 710-730.
Mahmoud, A. B., Grigoriou, N., Fuxman, L., Reisel, W. D., Hack-Polay, D., & Mohr, I. (2020). A generational study of employees customer orientation. Journal of Strategic Marketing, 30(8), 746-763.
Matthews, L. (2017). Applying Multigroup Analysis in PLS-SEM: A Step-by-Step Process. In Partial Least Squares Path Modeling (pp. 219-243). Springer.
Matthews, L., Hair, J. F., & Matthews, R. (2018). PLS-SEM: The Holy Grail For Advanced Analysis. Marketing Management Journal, 28(1), 1-13.
Mikalef, P., Boura, M., Lekakos, G., & Krogstie, J. (2020). The role of information governance in big data analytics driven innovation. Information & Management, 57(7), 103361.
Moore, Z., Harrison, D. E., & Hair, J. (2021). Data quality assurance begins before data collection and never ends. International Journal of Market Research, 63(6), 693-714.
Nunnally, J. C., & Bernstein, L. H. (1994). Psychometric theory (3rd ed.). McGraw-Hill.
Pitman, E. J. G. (1938). Significance tests which may be applied to samples from any population. Journal of the Royal Statistical Society Supplement, 4(1), 119-130.
Rademaker, M. E., & Schuberth, F. (2021). cSEM: Composite-based Structural Equation Modeling (Version: 0.4.0.9000).
Ramli, N. A., Latan, H., & Solovida, G. T. (2019). Determinants of capital structure and firm financial performance-A PLS-SEM approach. The Quarterly Review of Economics and Finance, 71, 148-160.
Ringle, C., Wende, S., & Becker, J.-M. (2015). SmartPLS 3. SmartPLS.
Roberts, N., & Thatcher, J. (2009). Conceptualizing and testing formative constructs. The DATABASE for Advances in Information Systems, 40(3), 9-39.
Roy, S. K., Balaji, M. S., Soutar, G., Lassar, W. M., & Roy, R. (2018). Customer engagement behavior in individualistic and collectivistic markets. Journal of Business Research, 86, 281-290.
Sanchez-Franco, M. J., & Roldán, J. L. (2010). Expressive aesthetics to ease perceived community support. Computers in Human Behavior, 26(6), 1445-1457.
Sarstedt, M., & Cheah, J.-H. (2019). Partial least squares structural equation modeling using SmartPLS: A software review. Journal of Marketing Analytics, 7(3), 196-202.
Sarstedt, M., Radomir, L., Moisescu, O. I., & Ringle, C. M. (2022c). Latent class analysis in PLS-SEM: A review and recommendations. Journal of Business Research, 138, 398-407.
Sarstedt, M., & Ringle, C. M. (2010). Treating unobserved heterogeneity in PLS path modeling: A comparison of FIMIX-PLS. Journal of Applied Statistics, 37(8), 1299-1318.
Sarstedt, M., Hair, J. F., Pick, M., Liengaard, B. D., Radomir, L., & Ringle, C. M. (2022a). Progress in partial least squares structural equation modeling use in marketing research. Psychology & Marketing, 39(5), 1035-1064.
Sarstedt, M., Hair, J. F., Jr., & Ringle, C. M. (2022b). PLS-SEM: Indeed a silver bullet. Journal of Marketing Theory and Practice.
Sarstedt, M., Henseler, J., & Ringle, C. M. (2011). Multigroup Analysis in Partial Least Squares (PLS) Path Modeling. International Marketing Review, 22, 195-218.
Sarstedt, M., & Mooi, E. (2019). A concise guide to market research. Springer.
Schade, M., Hegner, S., Horstmann, F., & Brinkmann, N. (2016). The impact of attitude functions on luxury brand consumption: An age-based group comparison. Journal of Business Research, 69(1), 314-322.
Schlägel, C., & Sarstedt, M. (2016). Assessing the measurement invariance of the four-dimensional cultural intelligence scale across countries. European Management Journal, 34(6), 633-649.
Sharma, P. N., Liengaard, B. D. D., Hair, J. F., Sarstedt, M., & Ringle, C. M. (2022). Predictive model assessment and selection in composite-based modeling using PLS-SEM. European Journal of Marketing.
Shmueli, G., Sarstedt, M., Hair, J. F., Cheah, J.-H., Ting, H., Vaithilingam, S., & Ringle, C. M. (2019). Predictive model assessment in PLS-SEM: Guidelines for using PLSpredict. European Journal of Marketing, 53(11), 2322-2347.
Streukens, S., & Leroi-Werelds, S. (2016). Bootstrapping and PLS-SEM. European Management Journal, 34(6), 618-632.
Tenenhaus, A., & Tenenhaus, M. (2011). Regularized generalized canonical correlation analysis. Psychometrika, 76(2), 257.
Ting, H., Fam, K. S., Hwa, J. C. J., Richard, J. E., & Xing, N. (2019). Ethnic food consumption intention at the touring destination. Tourism Management, 71, 518-529.
Trojanowski, M., & Kułak, J. (2017). The Impact of Moderators and Trust on Consumer’s Intention to Use a Mobile Phone for Purchases. Journal of Management and Business Administration. Central Europe, 25(2), 91-116.
Urbach, N., & Ahlemann, F. (2010). Structural equation modeling in information systems research using partial least squares. Journal of Information Technology Theory and Application, 11(2), 2.
Velayutham, S., Aldridge, J. M., & Fraser, B. (2012). Gender Differences in Student Motivation And Self-Regulation In Science Learning. International Journal of Science and Mathematics Education, 10(6), 1347-1368.
Voorhees, C. M., Brady, M. K., Calantone, R., & Ramirez, E. (2015). Discriminant validity testing in marketing. Journal of the Academy of Marketing Science, 44(1), 119-134.
Yáñez-Araque, B., Sánchez-Infante Hernández, J. P., Gutiérrez-Broncano, S., & Jiménez-Estévez, P. (2021). Corporate social responsibility in micro-, small and medium-sized enterprises. Journal of Business Research, 124, 581-592.
10. Phụ lục (Appendices) – Mã nguồn R
Dành cho các nhà nghiên cứu muốn sử dụng ngôn ngữ R để tái lập kết quả kiểm định NDT (theo phương pháp của Klesel et al., 2019), dưới đây là đoạn mã nguồn chuẩn:
Phụ lục A: Các bước thực hiện NDT trong R
(Yêu cầu cài đặt gói cSEM và readxl)
R
# Tải thư viện cần thiết
library(readxl)
library(cSEM)
# Bước 1: Nhập dữ liệu và định nghĩa mô hình
# (Structural và Composite model cần được định nghĩa trước tại đây)
# … (Phần code định nghĩa biến)
# Bước 2: Thực hiện ước lượng mô hình PLS
res_pls <- csem(.data = ErasmusPLS, .model = model)
# Bước 3: Chạy kiểm định MGA (NDT) với 1000 lần hoán vị
# .approach_mgd = ‘Klesel’ chỉ định sử dụng phương pháp của Klesel et al. (2019)
outMGD <- testMGD(res_pls, .R_permutation = 1000, .approach_mgd = ‘Klesel’)
# Bước 4: Hiển thị kết quả
outMGD
11. Kết Luận
Nghiên cứu về Phân tích đa nhóm trong PLS-SEM là một bước tiến quan trọng để nâng cao độ chính xác và tính thuyết phục của các kết luận khoa học trong luận án và bài báo quốc tế.
Để nắm các thuật toán phức tạp, xem chi tiết bảng đối chiếu P-value trước và sau hiệu chỉnh, cũng như các biểu đồ minh họa trực quan, tôi khuyến khích các bạn tải và đọc kỹ tài liệu gốc dưới đây.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



