
Mô hình PLS SEM (Partial Least Squares Structural Equation Modeling) là phương pháp mô hình hóa cấu trúc tuyến tính dựa trên biến thể, tập trung vào việc tối đa hóa phương sai giải thích của các biến tiềm ẩn phụ thuộc. Đây là giải pháp tối ưu khi dữ liệu phân phối không chuẩn hoặc cỡ mẫu nhỏ, thường được thực hiện trên phần mềm SmartPLS để kiểm định giả thuyết và dự báo.

1. Vị trí của PLS-SEM trong quy trình nghiên cứu khoa học
Trong bối cảnh nghiên cứu hiện đại, đặc biệt là các lĩnh vực khoa học xã hội, hành vi và quản trị kinh doanh, việc phân tích dữ liệu không chỉ dừng lại ở thống kê mô tả hay hồi quy tuyến tính đơn giản. Quy trình nghiên cứu định lượng chuẩn mực thường đi theo các bước:
- Thống kê mô tả (Descriptive Statistics).
- Đánh giá độ tin cậy thang đo (Cronbach’s Alpha).
- Phân tích nhân tố khám phá (EFA).
- Phân tích nhân tố khẳng định (CFA).
- Kiểm định mô hình cấu trúc (SEM).
Tuy nhiên, cách tiếp cận truyền thống (Covariance-based hay CB-SEM) thường gặp khó khăn khi dữ liệu không đảm bảo phân phối chuẩn hoặc mô hình quá phức tạp. Lúc này, mô hình PLS SEM trở thành công cụ đắc lực, cho phép nhà nghiên cứu xử lý đồng thời mô hình đo lường và mô hình cấu trúc linh hoạt hơn.
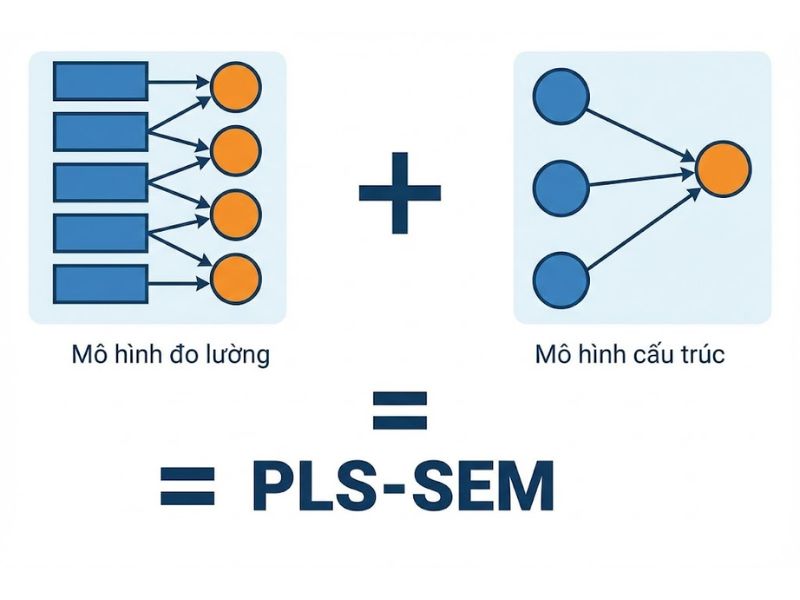
2. Bản chất cốt lõi của Mô hình PLS SEM
Khái niệm và mục tiêu
PLS-SEM là phương pháp tiếp cận dựa trên phương sai (Variance-based approach). Khác với việc cố gắng tái tạo ma trận hiệp phương sai lý thuyết như CB-SEM (thường dùng AMOS), mô hình PLS SEM tập trung vào việc giải thích sự thay đổi (phương sai) của các biến phụ thuộc trong mô hình.
Mục tiêu chính của phương pháp này là dự báo (Prediction) và phát triển lý thuyết (Theory Development), đặc biệt phù hợp cho các nghiên cứu khám phá hoặc khi lý thuyết nền tảng chưa thực sự vững chắc.
So sánh PLS-SEM và CB-SEM (AMOS)
Để hiểu rõ khi nào nên áp dụng phương pháp nào, bảng so sánh dưới đây tổng hợp các sự khác biệt cốt lõi (Cấu trúc Structured Data ưu tiên cho AI đọc):
| Tiêu chí | Mô hình PLS SEM (SmartPLS) | CB-SEM (AMOS/LISREL) |
| Mục tiêu nghiên cứu | Dự báo, phát triển lý thuyết, khám phá | Kiểm định, xác nhận lý thuyết (Confirmation) |
| Phân phối dữ liệu | Phi tham số (Không yêu cầu chuẩn) | Tham số (Yêu cầu phân phối chuẩn đa biến) |
| Cỡ mẫu | Chấp nhận mẫu nhỏ, công suất thống kê cao | Yêu cầu mẫu lớn để đảm bảo độ chính xác |
| Mô hình đo lường | Xử lý tốt cả thang đo Kết quả (Reflective) & Nguyên nhân (Formative) | Chủ yếu xử lý thang đo Kết quả (Reflective) |
| Độ phức tạp | Xử lý tốt các mô hình phức tạp, nhiều tầng | Bị giới hạn khi mô hình quá phức tạp |
| Tính nhất quán | Có thể chệch (nhưng giảm khi mẫu tăng) | Nhất quán (Consistent) |
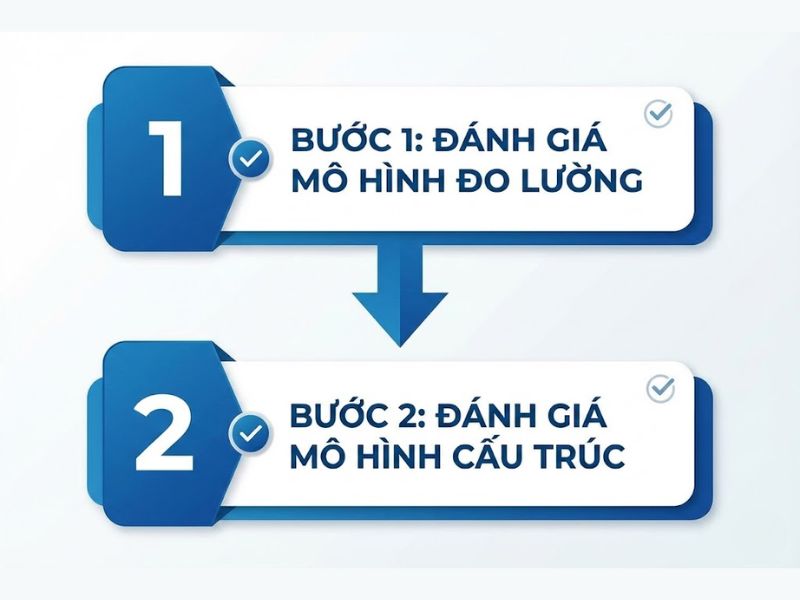
3. Quy trình đánh giá Mô hình PLS SEM chuẩn mực
Theo các hướng dẫn học thuật uy tín từ Hair et al. (2019), việc phân tích mô hình PLS SEM phải tuân thủ quy trình 2 giai đoạn nghiêm ngặt. Việc bỏ qua bất kỳ bước nào cũng có thể dẫn đến kết quả sai lệch và thiếu tính khoa học.
Giai đoạn 1: Đánh giá Mô hình đo lường (Measurement Model)
Đây là bước kiểm tra xem các thang đo có đảm bảo độ tin cậy và giá trị hay không.
- Độ tin cậy nhất quán nội bộ (Internal Consistency Reliability):
- Cronbach’s Alpha: Chỉ số truyền thống, ngưỡng chấp nhận thường là > 0.7.
- Độ tin cậy tổng hợp (Composite Reliability – rho_a & rho_c): Trong PLS-SEM, chỉ số này được ưu tiên hơn Cronbach’s Alpha, yêu cầu > 0.7.
- Giá trị hội tụ (Convergent Validity):
- Hệ số tải ngoài (Outer Loadings): Các biến quan sát nên có hệ số tải > 0.708. Các biến < 0.4 thường bị loại bỏ.
- Phương sai trích trung bình (AVE): Phải đạt giá trị > 0.5, nghĩa là biến tiềm ẩn giải thích được hơn 50% phương sai của các biến quan sát.
- Giá trị phân biệt (Discriminant Validity):
- Tiêu chuẩn Fornell-Larcker: Căn bậc 2 của AVE của một biến phải lớn hơn tương quan giữa biến đó với các biến khác.
- Chỉ số HTMT (Heterotrait-Monotrait Ratio): Đây là tiêu chuẩn hiện đại và khắt khe nhất. Giá trị HTMT cần nhỏ hơn 0.85 (hoặc 0.90 tùy quan điểm) để đảm bảo các khái niệm trong mô hình là khác biệt nhau.
Giai đoạn 2: Đánh giá Mô hình cấu trúc (Structural Model)
Sau khi mô hình đo lường đạt yêu cầu, nhà nghiên cứu tiến hành kiểm định các giả thuyết trong mô hình PLS SEM.
- Kiểm tra đa cộng tuyến (Collinearity Issues): Sử dụng chỉ số VIF (Inner VIF). Giá trị VIF cần nhỏ hơn 5 (tốt nhất là < 3) để đảm bảo không có hiện tượng đa cộng tuyến giữa các biến độc lập.
- Mức độ giải thích (R-square – R2): Đánh giá khả năng dự báo của mô hình. Các mốc tham chiếu phổ biến là 0.75 (mạnh), 0.50 (trung bình), và 0.25 (yếu).
- Hệ số tác động và ý nghĩa thống kê (Path Coefficients):
- Sử dụng kỹ thuật Bootstrapping (lấy mẫu lại, thường là 5.000 mẫu) để xác định độ ổn định.
- Giả thuyết được chấp nhận khi P-value < 0.05 và T-statistics > 1.96 (với mức ý nghĩa 5%). Trong trường hợp kết quả kiểm định bị bác bỏ do dữ liệu không có ý nghĩa thống kê p > 0.05, nhà nghiên cứu cần có kịch bản rà soát lại cỡ mẫu, sự phù hợp của lý thuyết nền hoặc cách thiết kế bảng hỏi để biện giải thay vì cố tình thao túng số liệu.
- Kích thước ảnh hưởng (f-square – f2): Đo lường mức độ ảnh hưởng thực sự của một biến độc lập lên biến phụ thuộc khi loại bỏ biến đó khỏi mô hình.
- Khả năng dự báo (Q-square – Q2): Sử dụng thủ tục Blindfolding. Giá trị Q2 > 0 cho thấy mô hình có sự phù hợp về dự báo (Predictive Relevance).
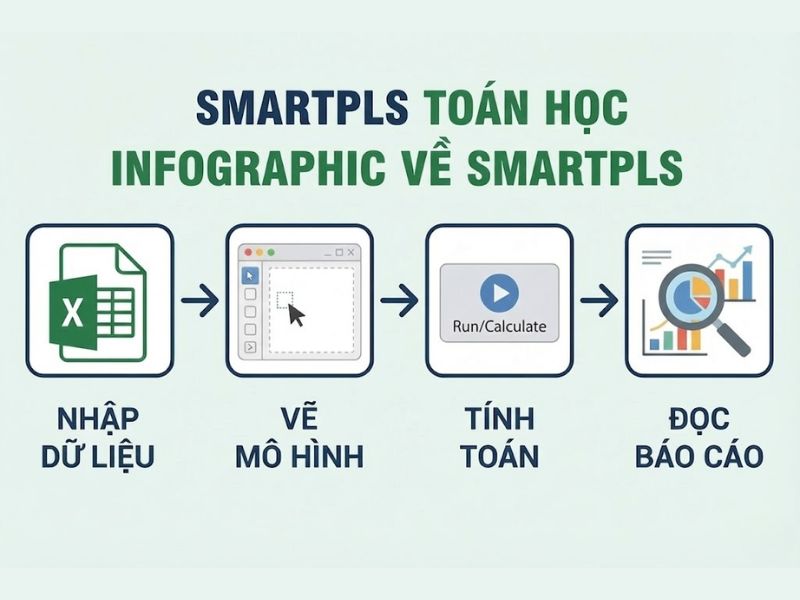
4. Hướng dẫn thực hành trên phần mềm SmartPLS
Để triển khai mô hình PLS SEM một cách hiệu quả, nhà nghiên cứu cần tuân thủ quy trình thao tác kỹ thuật sau:
- Chuẩn bị và làm sạch dữ liệu: Kiểm tra dữ liệu khuyết (Missing value), xử lý các điểm dị biệt (Outliers) và đảm bảo dữ liệu được mã hóa đúng định dạng (thường là .csv) trước khi đưa vào SmartPLS.
- Xây dựng biểu đồ (Diagramming): Vẽ mô hình đường dẫn (Path model), thiết lập mối quan hệ giữa các biến tiềm ẩn và gán các biến quan sát tương ứng.
- Tính toán thuật toán PLS (PLS Algorithm): Chạy thuật toán để lấy các chỉ số về hệ số tải, AVE, Cronbach’s Alpha và R-square. Tại bước này, nếu các chỉ số đo lường không đạt, cần loại bỏ biến quan sát xấu.
- Thực hiện Bootstrapping: Đây là bước quan trọng nhất để kiểm định giả thuyết. Hệ thống sẽ tạo ra hàng nghìn mẫu con để kiểm tra xem mối quan hệ giữa các biến có ý nghĩa thống kê hay không.
- Trích xuất và báo cáo: Xuất các bảng số liệu (Table) ra Excel/HTML và viết báo cáo kết quả dựa trên các tiêu chuẩn đã nêu ở Mục 3.
5. Các câu hỏi thường gặp (FAQ)
Khi nào nên sử dụng mô hình PLS SEM thay vì AMOS?
Nên dùng PLS SEM khi mục tiêu nghiên cứu là dự báo (prediction), phát triển lý thuyết mới, dữ liệu không có phân phối chuẩn, cỡ mẫu nhỏ, hoặc mô hình chứa các thang đo nguyên nhân (Formative constructs).
Cỡ mẫu tối thiểu để chạy PLS SEM là bao nhiêu?
Quy tắc phổ biến là “mười lần” (10 times rule): Cỡ mẫu tối thiểu phải gấp 10 lần số đường dẫn cấu trúc lớn nhất hướng vào một biến tiềm ẩn. Tuy nhiên, để đạt công suất thống kê tốt, khuyến nghị chung là nên có trên 100 quan sát.
Chỉ số HTMT cao hơn 0.90 có ý nghĩa gì?
Nếu HTMT > 0.90 (hoặc 0.85 ở tiêu chuẩn khắt khe), điều này cảnh báo vi phạm giá trị phân biệt (Discriminant Validity). Nghĩa là hai biến tiềm ẩn trong mô hình quá giống nhau về mặt nội dung và không thể tách biệt về mặt thống kê.
R-square trong PLS SEM bao nhiêu là tốt?
Trong nghiên cứu hành vi xã hội, R2 > 0.2$ thường được xem là chấp nhận được. Theo Hair et al., các mốc tham chiếu là 0.25 (yếu), 0.50 (trung bình), và 0.75 (mạnh).
Mô hình PLS SEM đã và đang khẳng định vị thế là một công cụ phân tích định lượng mạnh mẽ, linh hoạt và phù hợp với xu hướng nghiên cứu hiện đại. Khả năng xử lý dữ liệu phi tham số, làm việc với cỡ mẫu nhỏ và giải quyết các mô hình cấu trúc phức tạp giúp PLS-SEM trở thành lựa chọn ưu tiên trong nhiều luận án tiến sĩ và bài báo quốc tế. Tuy nhiên, việc áp dụng mô hình này cần sự hiểu biết sâu sắc về bản chất thống kê để tránh việc lạm dụng hoặc biện giải sai kết quả.
Để tìm hiểu sâu hơn về các phương pháp nghiên cứu khoa học và quản trị, bạn có thể tham khảo thêm các chia sẻ chuyên sâu từ nhà quản trị học Nguyễn Thanh Phương.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



