
Vấn đề thiếu hụt nền tảng lý thuyết vững chắc thường làm cản trở việc xác định chính xác các mối quan hệ biến số trong mô hình nghiên cứu là một thách thức lớn đối với giới học thuật. Nguyên nhân chính là do sự giới hạn về tri thức trong các giai đoạn đầu của việc phát triển lý thuyết. Giải pháp nhanh nhất là ứng dụng thuật toán tìm kiếm đặc tả hướng dự đoán [Predictive Feedforward – PF] trong phương pháp Phân tích thành phần cấu trúc tổng quát [Generalized Structured Component Analysis – GSCA] để tự động hóa việc chọn lọc biến dự báo dựa trên việc tối thiểu hóa sai số dự đoán (CVPE_T).
1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: A Prediction-Oriented Specification Search Algorithm for Generalized Structured Component Analysis
- Tiêu đề tiếng Việt: Một Thuật toán tìm kiếm đặc tả định hướng dự đoán cho Phân tích thành phần cấu trúc tổng quát
- Tác giả: Gyeongcheol Cho, Heungsun Hwang, Marko Sarstedt và Christian M. Ringle
- Tạp chí: Structural Equation Modeling: A Multidisciplinary Journal (2022)
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Trong thực tiễn nghiên cứu khoa học, các lý thuyết không phải lúc nào cũng có sẵn để chỉ định một cách hoàn chỉnh và rõ ràng các mối quan hệ giữa các biến số (biến quan sát hoặc biến thành phần). Khi sự hỗ trợ từ lý thuyết và kiến thức chuyên ngành còn khan hiếm, đặc biệt là khi các nhà nghiên cứu đang ở giai đoạn đầu của việc phát triển lý thuyết, các nhà nghiên cứu cần thực hiện chiến lược tìm kiếm đặc tả [Specification Search] (Long, 1983; MacCallum, 1986) nhằm khám phá các mối quan hệ cấu trúc theo hướng tiếp cận định hướng dữ liệu [Data-driven] hoặc thống kê.
Mặc dù phương pháp Phân tích thành phần cấu trúc tổng quát (GSCA) có khả năng thực hiện lựa chọn mô hình định hướng dự đoán (thông qua chỉ số kiểm chứng chéo Out-of-bag Prediction Error – OPE, xác định sức mạnh bằng cách kiểm chứng chéo các tập mẫu huấn luyện và mẫu xác thực qua phương pháp bootstrap của Efron, 1979), phương pháp này trước đây chưa được trang bị chiến lược tìm kiếm đặc tả tự động nhằm tối ưu hóa sai số. Đặc biệt, một chiến lược tìm kiếm đặc tả hướng dự đoán chỉ dựa trên việc dự đoán các quan sát chưa thấy sẽ cực kỳ hấp dẫn vì nó không yêu cầu cung cấp mô hình chính xác từ trước để đảm bảo tính hợp lệ (Shmueli, 2010; Shmueli & Koppius, 2011). Một tìm kiếm đặc tả loại này tập trung vào việc kiểm tra tính có thể sai về mặt lý thuyết của các mô hình khác nhau (Popper, 1962). Bài báo này ra đời để lấp đầy khoảng trống đó bằng cách đề xuất thuật toán Predictive Feedforward (PF).
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
- Phân tích thành phần cấu trúc tổng quát (GSCA): Đây là một phương pháp đa biến tổng quát dùng để chỉ định và kiểm định mối quan hệ giữa các biến quan sát và các thành phần theo một cách thức hợp lý về mặt lý thuyết. Một thành phần được hiểu là một tổ hợp tuyến tính hoặc tổng có trọng số của các biến quan sát có thể đóng vai trò như một chỉ số tóm tắt và xếp hạng các quan sát cụ thể (Cho et al., 2021; Rigdon, 2022). Cho rằng điểm số của các biến quan sát là độc lập tuyến tính (Lay et al., 2015), GSCA có thể cung cấp các điểm số thành phần duy nhất, xác định cho từng quan sát cá nhân, mà việc tính toán dựa trên các trọng số thu được từ ước lượng tham số.
- Ví dụ thực tiễn: Tình trạng kinh tế xã hội [Socioeconomic Status – SES] thường được đại diện bởi tổng có trọng số của giáo dục, thu nhập và nghề nghiệp (American Psychological Association, 2007). Trong nghiên cứu hệ gen, một gen được coi là một cụm sinh học của nhiều đa hình đơn nucleotide (SNPs) xảy ra trong gen, do đó các nhà nghiên cứu thường biểu diễn một gen dưới dạng tổng có trọng số của các SNPs của nó (Horne & Camp, 2004; Dai et al., 2013; Hwang et al., 2021).
- Lý thuyết Chấp nhận và Sử dụng Công nghệ Thống nhất (UTAUT): Để minh họa thực nghiệm, nghiên cứu này sử dụng mô hình UTAUT. Lý thuyết này giả định rằng ý định hành vi [Behavioral Intention – BI] và hành vi sử dụng công nghệ CNTT mới tiếp theo của người dùng [Use Behavior – USE] bị ảnh hưởng bởi bốn thành phần: Kỳ vọng hiệu năng (PE), Kỳ vọng nỗ lực (EE), Ảnh hưởng xã hội (SI), và Điều kiện thuận lợi (FC) (Venkatesh et al., 2003).
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
2.1 Định nghĩa và Bản chất của Thuật toán
Thuật toán tìm kiếm đặc tả hướng dự đoán (PF) là một quy trình tự động hóa nhằm khám phá cấu trúc mô hình tốt nhất bằng cách tìm kiếm sự kết hợp tối ưu của các biến dự báo sao cho sai số dự đoán kỳ vọng của các biến mục tiêu là nhỏ nhất. Trong thuật toán này, các nhà nghiên cứu không cần phải chỉ định hoàn toàn các mối quan hệ từ trước; họ chỉ cần quyết định biến nào là mục tiêu và biến nào là dự báo ứng viên. Khái niệm này hoạt động dựa trên cơ chế đánh giá chéo K-fold [K-fold Cross-validation] để tính toán chỉ số CVPE_T [Cross-Validation estimate of expected Prediction Error for Target variables].
2.2 Đặc tả Mô hình Toán học trong GSCA (Mathematical Model Specification)
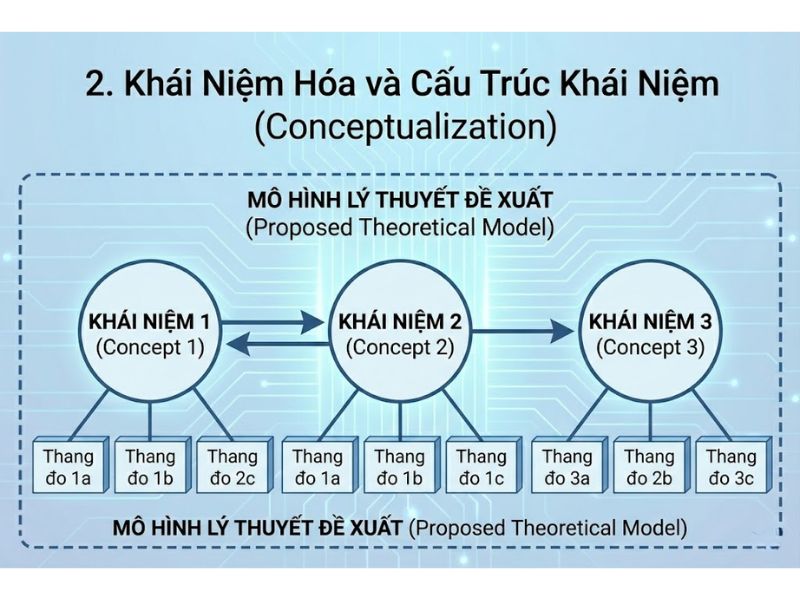
Để hiểu rõ cấu trúc của thuật toán PF, chúng ta cần mổ xẻ cấu trúc toán học của GSCA. Đầu tiên, gọi Γ là một ma trận thành phần kích thước N nhân P, trong đó N là số lượng quan sát. Gọi Z biểu thị một ma trận biến quan sát N nhân J. Gọi C biểu thị ma trận P nhân J bao gồm các hệ số tải (loadings). Gọi B biểu thị ma trận P nhân P gồm các hệ số đường dẫn. Gọi W biểu thị ma trận J nhân P gồm các trọng số thành phần. Gọi E_Z và E_Γ lần lượt là ma trận sai số cho các chỉ báo và thành phần. Bất kỳ mô hình Phân tích thành phần cấu trúc tổng quát nào cũng bao gồm ba mô hình con cốt lõi:
- Mô hình đo lường [Measurement Model]: Chỉ định mối quan hệ giữa các biến quan sát (Z) và thành phần (Γ).
- Mô hình cấu trúc [Structural Model]: Biểu diễn mối quan hệ giữa các thành phần với nhau.
- Mô hình quan hệ có trọng số [Weighted Relation Model]: Định nghĩa mỗi thành phần như một hỗn hợp có trọng số của các biến chỉ báo (W), khẳng định bản chất dựa trên thành phần của GSCA.
Ba mô hình này được tích hợp thành phương trình tổng quát duy nhất của mô hình GSCA:
(trong đó V=[I, W], A=[C, B], và E=[E_Z, E_Γ]) và giải quyết bằng hàm mục tiêu bình phương tối thiểu luân phiên [Alternating Least Squares]:

GSCA ước lượng các tham số mà không yêu cầu giả định về phân phối chuẩn đa biến của dữ liệu. Nó thu được các sai số chuẩn hoặc khoảng tin cậy một cách phi tham số thông qua phương pháp bootstrap.
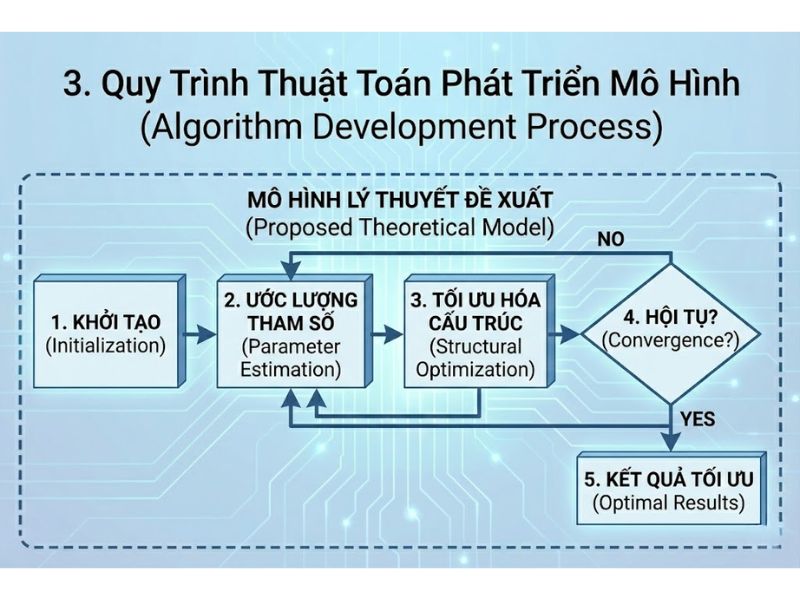
3. Quy Trình Thuật Toán Phát Triển Mô Hình (Algorithm Development Process)
Dưới góc độ đánh giá và lựa chọn mô hình, Thuật toán tìm kiếm đặc tả hướng dự đoán thiết lập quy trình ba bước chuẩn mực để tìm ra cấu trúc tối ưu:
- Bước 1: Khởi tạo mô hình cơ sở (M1): Bắt đầu bằng việc điều hợp [fitting] một mô hình mặc định (có thể là mô hình null không có biến dự báo hoặc mô hình có một số biến dự báo). Ước lượng sai số dự đoán kỳ vọng của M1 thông qua phương pháp kiểm chứng chéo K-fold để tính toán giá trị CVPE_T. Trong K-fold, mẫu được chia thành K mẫu con, một mẫu làm xác thực và các mẫu còn lại làm huấn luyện. Công thức tính toán cốt lõi cho các biến mục tiêu (với Q là số lượng biến mục tiêu) là:
- Bước 2: Đánh giá mô hình cạnh tranh: Xây dựng một tập hợp các mô hình, mỗi mô hình thêm đúng một biến dự báo mới riêng biệt vào M1. Khớp tất cả các mô hình và chọn mô hình có CVPE_T nhỏ nhất (Ký hiệu là M2). Kiểm định sự khác biệt giữa M1 và M2 bằng khoảng tin cậy Bootstrap phi tham số 95% trên H mẫu bootstrap; nếu khoảng tin cậy không chứa số 0, sự khác biệt CVPE_T có ý nghĩa thống kê, M2 bây giờ được chọn làm cơ sở mới M1 để thay thế, và tiếp tục lặp lại quá trình cho các biến dự báo còn lại.
- Bước 3: Lựa chọn mô hình cuối cùng: Quá trình dừng lại khi CVPE_T của M2 lớn hơn M1, hoặc sự khác biệt CVPE_T giữa M1 và M2 không có ý nghĩa thống kê, hoặc M1 đã xem xét tất cả các biến ứng viên. Mô hình M1 còn lại cuối cùng được chọn là mô hình có sức mạnh dự đoán tốt nhất cho các biến mục tiêu.
3.1 Bốn Đặc Tính Ưu Việt Của Thuật Toán PF
- Tính nhất quán của Bootstrap: PF chỉ áp dụng lấy mẫu lại [Bootstrap] trên mẫu gốc đúng một lần và dùng chung tập mẫu bootstrap này để so sánh sự khác biệt CVPE_T giữa hai mô hình, loại bỏ khả năng sai số do việc đổi tập mẫu khác nhau.
- Khác biệt với Hồi quy từng bước (Stepwise Regression): Mặc dù tiến hành tương tự hồi quy lựa chọn tiến, thuật toán PF không dùng sức mạnh giải thích của mẫu hiện tại như R² hay F-statistic (vốn bị chỉ trích bởi Harrel, 2001 và Smith, 2018 vì dễ gây quá khớp [over-fitting] và phụ thuộc vào p-value chỉ đúng khi mô hình khớp là đúng) mà so sánh dựa trên sai số dự đoán kỳ vọng của dữ liệu chưa thấy [unseen data].
- Tối ưu hóa gánh nặng tính toán: Mức thiết lập K-fold ở K=5 hoặc K=10 (khuyến nghị bởi Breiman & Spector, 1992; Kohavi, 1995) và số mẫu Bootstrap H=100 được chứng minh qua mô phỏng là cân bằng hoàn hảo giữa độ chệch [bias] và phương sai [variance], hoạt động cực tốt để xác định mô hình ít biến sai.
- Không giả định phân phối: Toàn bộ thuật toán và các bước không yêu cầu dữ liệu tuân theo phân phối chuẩn, phù hợp tuyệt đối với bản chất của phương pháp GSCA.
4. Thang Đo Lường Chính Thức (Measurement Scale)
Trong phần ứng dụng thực nghiệm, bài báo sử dụng bộ thang đo từ mô hình UTAUT với cỡ mẫu thực tế lớn N=772, lấy từ cơ sở dữ liệu SmartPLS. Dưới đây là hệ thống các biến cấu trúc được trích xuất từ mô hình đo lường:
- Kỳ vọng hiệu năng [Performance Expectancy – PE]: Đo lường qua các biến z1, z2, z3, z4.
- Kỳ vọng nỗ lực [Effort Expectancy – EE]: Đo lường qua các biến z5, z6, z7, z8.
- Ảnh hưởng xã hội [Social Influence – SI]: Đo lường qua các biến z9, z10, z11.
- Điều kiện thuận lợi [Facilitating Condition – FC]: Đo lường qua các biến z12, z13, z14.
- Ý định hành vi [Behavioral Intention – BI]: Đo lường qua các biến z15, z16, z17.
- Hành vi sử dụng [Use Behavior – USE]: Đo lường qua các biến z18, z19, z20, z21.
5. Mạng Lưới Quan Hệ Lý Thuyết & Kết Quả Nghiên Cứu Mô Phỏng (Nomological Network & Simulation Results)
5.1 Kết Quả Nghiên Cứu Mô Phỏng (Simulation Study)
Để chứng minh độ tin cậy, các tác giả đã thiết kế mô hình quần thể phức tạp với 10 thành phần độc lập (tương quan 0.3) và 2 thành phần phụ thuộc, mỗi thành phần có 3 chỉ báo (hệ số tải lần lượt là 0.6, 0.7, 0.8; trọng số 0.4027, 0.4698, 0.5396). Các hệ số đường dẫn cấu trúc được gán là b1=0.2, b2=0.4, b3=0.6, b4=0.2, và b5=0.6 để phản ánh tác động nhỏ, trung bình và lớn. Mô hình được kiểm tra trên các kích thước mẫu N = 50, 100, 250, 500, 1000 qua 500 bộ dữ liệu mô phỏng. Kết quả so sánh giữa thuật toán PF và thuật toán Tabu Search (Kích thước tabu = 5, vòng lặp = 30) cho thấy:
| Tiêu chí | Thuật toán Đề xuất (PF) | Thuật toán Tìm kiếm Tabu |
| Tỷ lệ chọn sai (False Positive Rate) | Gần như bằng 0 ở mọi kích thước mẫu (loại trừ hoàn toàn 16 đường dẫn bằng 0). | Xấp xỉ 20% ở mọi kích thước mẫu. |
| Bản chất mô hình được chọn | Ưu tiên mô hình tiết kiệm (parsimonious), chứa phần lớn các hệ số khác 0 khi mẫu nhỏ. | Thường ưu ái mô hình chứa trung bình 3-4 hệ số đường dẫn sai (zero path) vô nghĩa. |
| Độ hội tụ | Đạt 100% tỷ lệ chọn đúng toàn bộ hệ số khi N=1,000. | Đạt tỷ lệ chọn đúng cao ở mẫu nhỏ (N<500), nhưng luôn kèm nhiễu dương tính giả cao. |
5.2 Mạng Lưới Quan Hệ Mô Hình UTAUT Thực Tế
Dựa trên kết quả chạy thuật toán PF (với K=5 và H=100) trên tập dữ liệu UTAUT thực tế, hai thuật toán đều chọn cùng một mô hình cuối cùng [Mô hình 40]. Thuật toán không chỉ xác nhận các mối quan hệ gốc mà còn tự động tìm ra hai đường dẫn mới có ý nghĩa dự đoán cao:
- Điều kiện thuận lợi (FC) $\rightarrow$ Ý định (BI): Theo Venkatesh et al. (2012), FC có thể khác nhau đáng kể giữa các bối cảnh và có thể hoạt động giống như “kiểm soát hành vi nhận thức” trong Lý thuyết Hành vi Kế hoạch (TPB), qua đó tác động trực tiếp đến cả ý định và hành vi.
- Ảnh hưởng xã hội (SI) $\rightarrow$ Hành vi sử dụng (USE): Theo phân tích tổng hợp trên 1.935 mẫu của Blut et al. (2022), SI có tương quan mạnh với thói quen và áp lực cưỡng chế [coercive pressure] từ các cơ quan quản lý (tạo ra áp lực chính thức hoặc không chính thức), tạo ra tác động trực tiếp lên hành vi thực tế (Bozan et al., 2016).

6. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Đối với các nghiên cứu sinh và nhà khoa học đang sử dụng phương pháp Phân tích thành phần cấu trúc tổng quát, thuật toán PF cung cấp một bộ công cụ định lượng mạnh mẽ:
- Xử lý khi thiếu hụt lý thuyết: Khi bạn đang ở giai đoạn đầu của việc phát triển lý thuyết, hãy chọn lọc các biến mục tiêu và cung cấp danh sách các biến dự báo tiềm năng. Thuật toán tìm kiếm đặc tả hướng dự đoán PF sẽ thiết lập cấu trúc tối ưu cho bạn, đặc biệt hữu ích cho các mô hình không bị chỉ định sai cơ bản mà chỉ bị thiếu đường dẫn hoặc chỉ định quá mức.
- Cảnh báo về Suy diễn Nhân quả (Causality Limitations): Mặc dù thuật toán cung cấp đặc tả mô hình tốt từ góc độ dự đoán, các bước bổ sung cần thiết lập để bảo vệ tính hợp lệ. Thuật toán PF tìm kiếm mối quan hệ dự đoán [predictive power], không tự động đảm bảo tính nhân quả. Nếu bạn bỏ sót một biến gốc thực sự gây ra biến mục tiêu (Omitted Variable Bias), thuật toán có thể chọn nhầm một biến dự báo sai chỉ vì nó có liên hệ thống kê với biến bị bỏ sót, dẫn đến đánh giá quá cao tác động (Angrist & Pischke, 2009, Chương 3). Thêm vào đó, một mô hình đơn giản hơn có thể có sức mạnh dự đoán cao hơn mô hình thực trong điều kiện mẫu hữu hạn (Shmueli, 2010).
- Định hướng nghiên cứu tương lai (Future Research): Các học giả có thể ứng dụng GSCA kết hợp với các thuật toán tối ưu hóa heuristic như Tối ưu hóa đàn kiến [Ant Colony Optimization] (Marcoulides & Drezner, 2003) hoặc Thuật toán Di truyền [Genetic Algorithm] (Marcoulides & Drezner, 2001). Đồng thời, cần mở rộng thuật toán để phân tích các lớp biến phức tạp, các hiệu ứng tương tác phi tuyến hoặc các mối quan hệ trung gian tuần tự [Sequential Mediation].
7. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Kết quả từ mô hình UTAUT được trích xuất bởi Thuật toán tìm kiếm đặc tả hướng dự đoán cung cấp những chiến lược cốt lõi cho các Marketer:
- Tối ưu hóa nguồn lực triển khai (FC tác động lên BI): Bằng chứng thực nghiệm xác nhận Điều kiện thuận lợi ảnh hưởng trực tiếp đến ý định. Doanh nghiệp cần cung cấp các công cụ hỗ trợ (tài liệu, hạ tầng CNTT) mạnh mẽ ngay từ giai đoạn khách hàng đang cân nhắc, không đợi đến khi họ đã mua sản phẩm. Nó hoạt động như một lớp kiểm soát hành vi mạnh mẽ cho người dùng mới.
- Kích hoạt hiệu ứng lan truyền xã hội (SI tác động lên USE): Ảnh hưởng xã hội tác động trực tiếp đến việc sử dụng thực tế thay vì chỉ dừng ở ý định. Điều này gợi ý rằng việc tận dụng áp lực đồng trang lứa hoặc sức mạnh của các tổ chức, cơ quan quản lý (tạo ra áp lực cưỡng chế) sẽ trực tiếp chuyển đổi khách hàng từ trạng thái trung lập sang hành vi sử dụng thực tế liên tục.
8. Các Câu Hỏi Thường Gặp (FAQ)
Thuật toán PF (Predictive Feedforward) có thay thế hoàn toàn được cơ sở lý thuyết truyền thống không?
Hoàn toàn không. PF là thuật toán định hướng dữ liệu nhằm tối thiểu hóa sai số dự đoán. Các nhà nghiên cứu bắt buộc phải cung cấp cơ sở lý luận học thuật mạnh mẽ để biện minh cho các mối quan hệ được thuật toán lựa chọn nếu muốn diễn dịch theo hướng nhân quả. Việc kiểm chứng chéo trong các bối cảnh và mẫu khác nhau là bắt buộc.
Thuật toán tìm kiếm đặc tả PF khác biệt thế nào so với Hồi quy từng bước (Stepwise Regression)?
Thuật toán PF không đánh giá mô hình dựa trên sức mạnh giải thích dữ liệu hiện tại (như R² hoặc p-value) vốn dễ dẫn đến tình trạng quá khớp [over-fitting]. Thay vào đó, nó dựa hoàn toàn vào sai số dự đoán kỳ vọng trên các dữ liệu chưa thấy thông qua kiểm chứng chéo CVPE_T.
Khi nào nên sử dụng phương pháp Phân tích thành phần cấu trúc tổng quát (GSCA) thay vì PLS-SEM?
Nên sử dụng GSCA khi bạn cần một phương pháp dựa trên thành phần cung cấp điểm số thành phần xác định duy nhất cho từng quan sát. Đặc biệt, phương pháp này tối ưu hóa một hàm mục tiêu toàn cục (bình phương tối thiểu luân phiên) và không yêu cầu các giả định nghiêm ngặt về phân phối chuẩn đa biến của dữ liệu.
9. Tài Liệu Tham Khảo (References)
Al-Gahtani, S. S., Hubona, G. S., & Wang, J. (2007). Information technology (IT) in Saudi Arabia: Culture and the acceptance and use of IT. Information & Management, 44, 681-691.
American Psychological Association. (2007). Report of the APA Task Force on Socioeconomic Status.
Angrist, J., & Pischke, J.-S. (2009). Mostly harmless econometrics: An empiricist’s companion. Princeton University Press.
Blut, M., Chong, A. Y., Loong; Tsigna, Z., & Venkatesh, V. (2022). Meta-analysis of the unified theory of acceptance and use of technology (UTAUT): Challenging its validity and charting a research agenda in the red ocean. Journal of the Association for Information Systems, 23, 13-95.
Bozan, K., Parker, K., & Davey, B. (2016). A closer look at the social influence construct in the UTAUT Model: An institutional theory based approach to investigate health IT adoption patterns of the elderly. 2016 49th Hawaii International Conference on System Sciences (HICSS), 3105-3114.
Breiman, L., & Spector, P. (1992). Submodel selection and evaluation in regression. The X-random case. International Statistical Review, 60, 291-319.
Cho, G., & Choi, J. Y. (2020). An empirical comparison of generalized structured component analysis and partial least squares path modeling under variance-based structural equation models. Behaviormetrika, 47, 243-272.
Cho, G., Jung, K., & Hwang, H. (2019). Out-of-bag prediction error: A cross validation index for generalized structured component analysis. Multivariate Behavioral Research, 54, 505-513.
Cho, G., Kim, S., Hwang, H., Lee, J., Sarstedt, M., & Ringle, C. M. (2022). A comparative study of the predictive power of component-based approaches to structural equation modeling. European Journal of Marketing, Advance online publication.
Cho, G., Sarstedt, M., & Hwang, H. (2021). A comparative evaluation of factor and component-based structural equation modeling methods under (in)consistent model specifications. British Journal of Mathematical and Statistical Psychology, Advance online publication.
Dai, H., Zhao, Y., Qian, C., Cai, M., Zhang, R., Chu, M., Dai, J., Hu, Z., Shen, H., & Chen, F. (2013). Weighted SNP set analysis in genome-wide association study. PLoS One, 8, e75897.
Efron, B. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 7, 1-26.
Harrel, F. (2001). Regression modeling strategies. Springer-Verlag.
Hastie, T., Tibshirani, R., & Friedman, J. (2001). The elements of statistical learning. Springer.
Horne, B. D., & Camp, N. J. (2004). Principal component analysis for selection of optimal SNP-sets that capture intragenic genetic variation. Genetic Epidemiology, 26, 11-21.
Hwang, H., Cho, G., Jin, M. J., Ryoo, J. H., Choi, Y., & Lee, S.-H. (2021). A knowledge-based multivariate statistical method for examining gene-brain-behavioral/cognitive relationships: Imaging genetics generalized structured component analysis. PLoS One, 16, e0247592.
Hwang, H., Sarstedt, M., Cheah, J. H., & Ringle, C. M. (2020). A concept analysis of methodological research on composite-based structural equation modeling: Bridging PLSPM and GSCA. Behaviormetrika, 47, 219-241.
Hwang, H., & Takane, Y. (2004). Generalized structured component analysis. Psychometrika, 69, 81-99.
Hwang, H., & Takane, Y. (2014). Generalized structured component analysis: A component-based approach to structural equation modeling. Chapman and Hall/CRC Press.
Kohavi, R. (1995). A study of cross-validation and bootstrap for accuracy estimation and model selection. Proceedings of the 14th International Joint Conference on Artificial Intelligence Volume 2, (pp. 1137-1143). Morgan Kaufmann Publishers Inc.
Lay, D. C., Lay, S. R., & McDonald, J. J. (2015). Linear algebra and its applications (5th ed.). Pearson Education.
Long, J. S. (1983). Covariance structure models. SAGE Publications.
MacCallum, R. C. (1986). Specification searches in covariance structure modeling. Psychological Bulletin, 100, 107-120.
Marcoulides, G. A., & Drezner, Z. (2001). Specification searches in structural equation modeling with a genetic algorithm. Trong New developments and techniques in structural equation modeling (pp. 247-268). Lawrence Erlbaum Associates Publishers.
Marcoulides, G. A., & Drezner, Z. (2003). Model specification searches using ant colony optimization algorithms. Structural Equation Modeling, 10, 154-164.
Marcoulides, G. A., Drezner, Z., & Schumacker, R. E. (1998). Model specification searches in structural equation modeling using tabu search. Structural Equation Modeling, 5, 365-376.
Marcoulides, K. M., & Falk, C. F. (2018). Model specification searches in structural equation modeling with R. Structural Equation Modeling, 25, 484-491.
Popper, K. (1962). Conjectures and refutations: The growth of scientific knowledge. Basic Books.
Rigdon, E. (2022). Needed developments in the understanding of quasi factor methods. Communications of the Association for Information Systems (forthcoming).
Shmueli, G. (2010). To explain or to predict? Statistical Science, 25, 289-310.
Shmueli, G., & Koppius, O. R. (2011). Predictive analytics in information systems research. MIS Quarterly, 35, 553-572.
Smith, G. (2018). Step away from stepwise. Journal of Big Data, 5, 32.
Venkatesh, V., Morris, M. G., Davis, G. B., & Davis, F. D. (2003). User acceptance of information technology: Toward a unified view. MIS Quarterly, 27, 425-478.
Venkatesh, V., Thong, J. Y. L., & Xu, X. (2012). Consumer acceptance and use of information technology: Extending the unified theory of acceptance and use of technology. MIS Quarterly, 36, 157-178.
10. Lời kêu gọi hành động (CTA)
Để nắm bắt toàn diện các cơ sở toán học cốt lõi của Thuật toán tìm kiếm đặc tả hướng dự đoán và ứng dụng trọn vẹn sức mạnh của phương pháp Phân tích thành phần cấu trúc tổng quát vào luận án của bạn, hãy xem qua tài liệu nghiên cứu chi tiết bên dưới.
Cho, G., Hwang, H., Sarstedt, M., & Ringle, C. M. (2022). A prediction-oriented specification search algorithm for generalized structured component analysis. Structural Equation Modeling: A Multidisciplinary Journal, 29(4), 611-619.



