
Mô hình phương trình cấu trúc (SEM) là một khuôn khổ thống kê đa biến tổng quát để chỉ định và kiểm định các mối quan hệ nhân quả giữa các biến quan sát, bao gồm cả các cấu trúc tiềm ẩn (constructs). Nguyên nhân chính của sự sai lệch trong phân tích dữ liệu thực nghiệm thường bắt nguồn từ việc áp dụng sai phương pháp ước lượng khi biểu diễn sai cấu trúc (nhầm lẫn cơ bản giữa mô hình đại diện bằng nhân tố và mô hình đại diện bằng thành phần). Giải pháp nhanh nhất và an toàn nhất về mặt thống kê hiện nay là sử dụng phương pháp Phân tích thành phần cấu trúc tổng quát (GSCA), vì thực nghiệm Monte Carlo đã chứng minh phương pháp này bền vững nhất khi đối mặt với rủi ro chỉ định sai cấu trúc trong nghiên cứu.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: A comparative evaluation of factor- and component-based structural equation modelling approaches under (in) correct construct representations
- Tiêu đề tiếng Việt: Đánh giá so sánh các phương pháp tiếp cận mô hình phương trình cấu trúc dựa trên yếu tố và thành phần dưới các đại diện cấu trúc (không) chính xác
- Tác giả: Gyeongcheol Cho, Marko Sarstedt, Heungsun Hwang
- Tạp chí: British Journal of Mathematical and Statistical Psychology (2022), 75, 220-251
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Trong thực tiễn nghiên cứu khoa học, mô hình phương trình cấu trúc (SEM) đã phát triển thành hai lĩnh vực riêng biệt: dựa trên yếu tố (factor-based SEM) và dựa trên thành phần (component-based SEM). Khoảng trống nghiên cứu lớn nhất hiện nay là các phương pháp SEM thống kê thường chỉ được đánh giá và so sánh dưới giả định của các mô hình yếu tố quần thể. Điều này đưa ra những kết luận sai lệch về hiệu suất tương đối của chúng, đặc biệt là tạo ra quan niệm sai lầm cho rằng các công cụ ước lượng dựa trên thành phần (như GSCA hay PLSPM) bị chệch (biased) hoặc không nhất quán. Trên thực tế, các nhà nghiên cứu thường thiếu các lý thuyết chuyên sâu rõ ràng (ví dụ: thiếu cơ sở để chọn giữa thuyết g về trí thông minh hay thuyết tương hỗ) để xác định xem một yếu tố hay thành phần mang tính đại diện tốt hơn cho một cấu trúc nhất định.
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Lý thuyết nền tảng của bài báo phân tách rõ hai bản thể học đại diện cấu trúc, đòi hỏi người làm nghiên cứu phải nắm vững để không chọn sai thuật toán:
- Lý thuyết dựa trên yếu tố (Factor-based Theory): Giả định rằng mỗi cấu trúc tương ứng với một thực thể độc lập bên ngoài, có trước và tạo ra mô hình tương quan của các biến quan sát (Borsboom, 2008). Trong mô hình này, cấu trúc là nguyên nhân sinh ra dữ liệu.
- Lý thuyết dựa trên thành phần (Component-based Theory): Giả định rằng cấu trúc có thể không phải là một thực thể độc lập mà hoàn toàn là sự tổng hợp (hoặc hỗn hợp có trọng số tuyến tính) của các biến quan sát. Tại đây, sự biến thiên của các biến quan sát tạo ra và định hình cấu trúc.
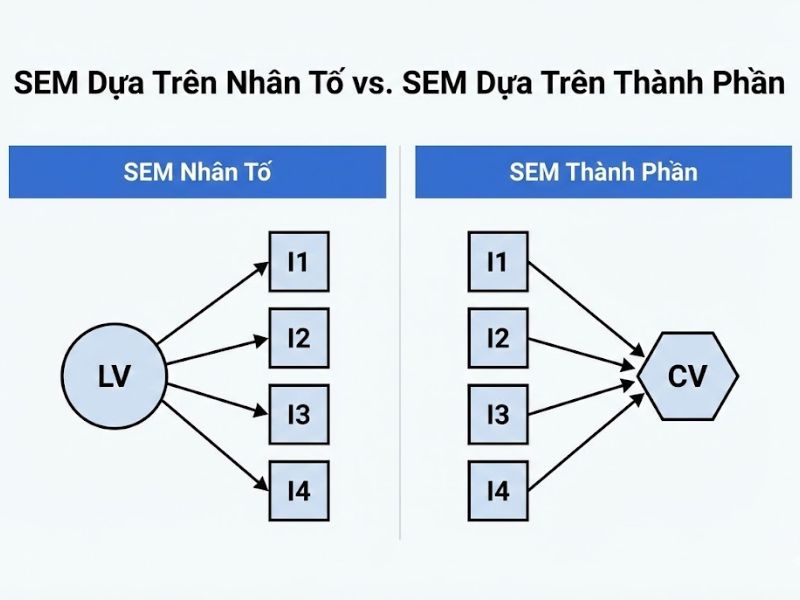
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Việc khái niệm hóa quyết định toàn bộ phương pháp ước lượng và cách đọc các chỉ số R², Q² hay GoF trong phân tích đa biến:
- Đại diện bằng Yếu tố (Factor Representation): Một cấu trúc trừu tượng mô tả một hiện tượng nhất định (ví dụ: Trí thông minh, Tính cách) được coi là nguyên nhân gây ra sự biến thiên của các chỉ báo (gọi là effect indicators). Các chỉ báo này có tính thay thế cho nhau và phải có độ tương quan rất cao. Nếu cấu trúc này bị chỉ định sai, mô hình sẽ phản ánh sai bản chất dữ liệu, dẫn đến ma trận hiệp phương sai không xác định.
- Đại diện bằng Thành phần (Component Representation): Cấu trúc được định nghĩa như một chỉ số gộp (composite indicators). Sự thay đổi của thành phần bị dẫn dắt bởi chỉ báo, do đó các chỉ báo không nhất thiết phải tương quan cao. Ở dạng tổng quát nhất của mô hình GSCA, đây không hẳn là một mô hình cấu trúc mà là một mô hình tạo chỉ số (index-generating model), tối thiểu hóa tổng phương sai sai số dựa trên một tiêu chí tối ưu hóa toàn cục mà không phụ thuộc hoàn toàn vào các giả định phân phối chuẩn.
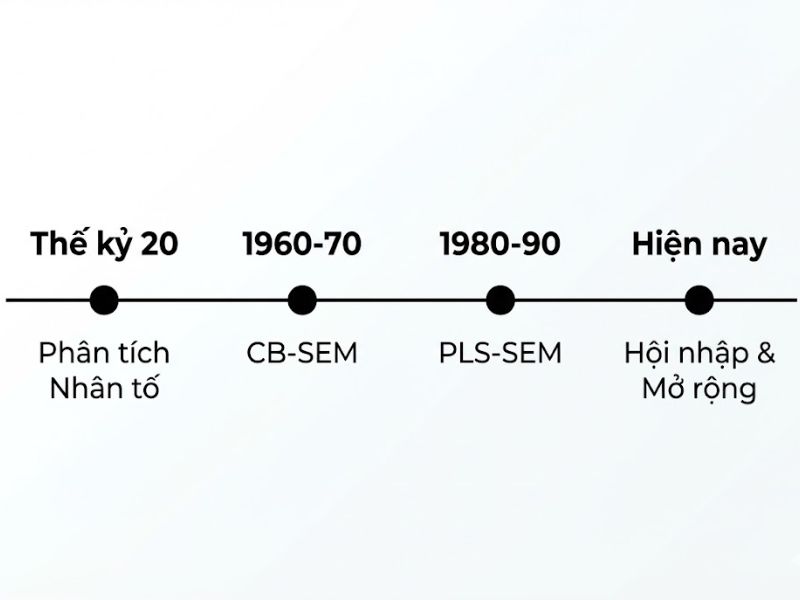
3. Lịch Sử Hình Thành Và Phát Triển Của Lý Thuyết
Sự phát triển của mô hình phương trình cấu trúc gắn liền với các học giả lớn trong việc tách biệt hai trường phái thống kê:
- Giai đoạn Khởi nguồn (Mô hình Yếu tố): Các công trình nền tảng của Jöreskog (1970a, 1970b, 1978) đã định hình phương pháp hợp lý cực đại (ML_F) là tiêu chuẩn thực tế và chuẩn mực vàng cho SEM dựa trên yếu tố. Sau đó, các phương pháp thông tin hạn chế như Hồi quy điểm yếu tố (FSR) được Croon (2002) phát triển để khắc phục độ chệch.
- Giai đoạn Hoàn thiện (Mô hình Thành phần): Wold (1966, 1973, 1982a, 1982b) tiên phong phát triển mô hình hóa đường dẫn bình phương tối thiểu một phần (PLSPM/NIPALS). Sau đó, Hwang và Takane (2004, 2014) phát triển Phân tích thành phần cấu trúc tổng quát (GSCA) như một giải pháp “toàn thông tin” (full-information) vượt trội hơn. Gần đây, Dijkstra (2011, 2013a, 2017) và Cho & Choi (2020) đã hoàn thiện mô tả toán học chặt chẽ cho mô hình thành phần quần thể.
4. Các Miền Nội Dung Khái Niệm Cốt Lõi (Core Concepts & Equations)
Để hiểu sâu về sự khác biệt nhằm tránh lỗi phần mềm khi chạy phân tích, cần nắm vững các giả định và đặc tính toán học của các mô hình quần thể (population models). Các phương trình dưới đây được định dạng chuẩn để dễ dàng sao chép vào các báo cáo khoa học:
- Mô hình yếu tố quần thể: Mô hình cấu trúc biểu diễn mối quan hệ nhân quả: η_y = B_y * η_y + B_x * η_x + ζ. Mô hình đo lường thể hiện mối quan hệ giữa các yếu tố và chỉ báo qua phương trình: z_x = Λ_x * η_x + ε_x và z_y = Λ_y * η_y + ε_y.
- Mô hình thành phần của Dijkstra: Bổ sung mô hình quan hệ có trọng số: γ_p = w_p’ * z_p, cho thấy các chỉ báo hình thành nên thành phần một cách tất định. Mô hình cấu trúc là: γ_y = B_y * γ_y + B_x * γ_x + ζ và mô hình đo lường đơn thuần là mô tả sự liên kết: z_p = λ_p * γ_p + ε_p.
- Mô hình của Henseler et al. (2014): Tương đương với mô hình của Dijkstra nhưng sử dụng góc nhìn khác về tham số cấu trúc. Đặc biệt, nó được tác giả chứng minh bằng toán học là không bao hàm mô hình yếu tố như một trường hợp đặc biệt (các sai số đo lường buộc phải tương quan với nhau).
- Mô hình của Cho và Choi (2020): Bổ sung thêm mối quan hệ chức năng giữa trọng số w_p và ma trận hiệp phương sai Σ_p nhằm tối đa hóa phương sai được giải thích (cụ thể: w_p = Σ_p^(-1/2) * u_1).
Bảng Tổng Hợp Cấu Trúc Khái Niệm Toán Học:
| Loại Mô Hình Quần Thể | Đặc Điểm Phương Trình Đo Lường | Tính Chất Thuật Toán (Thu thập thông tin) | Phương Pháp Ước Lượng Tối Ưu | Khả năng hội tụ khi sai chỉ định cấu trúc |
| Mô hình Yếu tố | z = Λ*η + ε | Toàn thông tin (ML_F) / Hạn chế (FSR) | ML_F, FSR | Kém (Tỷ lệ lỗi > 34%) |
| Mô hình Dijkstra | z = λ*γ + ε (với γ = w’*z) | Thông tin hạn chế (Từng phần) | PLSPM (Mode B) | Hoàn hảo (0% lỗi) |
| Mô hình Cho & Choi | Tối đa hóa phương sai giải thích toàn cục | Toàn thông tin / Thông tin hạn chế | GSCA, PLSPM (Mode A/B) | Hoàn hảo (0% lỗi) |
| Mô hình GSCA | Lệnh tạo chỉ số (Index-generating: Vz = AW*z + e) | Toàn thông tin tối ưu hóa một hàm mục tiêu | GSCA | Hoàn hảo (0% lỗi) |
5. Quy Trình Phát Triển Thiết Kế Mô Phỏng (Simulation Design Process)
Nghiên cứu sử dụng phương pháp mô phỏng Monte Carlo nghiêm ngặt với 72.000 mô hình phương trình cấu trúc quần thể được tạo ra từ 5 yếu tố thực nghiệm:
- Đại diện cấu trúc: Dựa trên yếu tố (Factor) và dựa trên thành phần (Component).
- Độ phức tạp của mô hình cấu trúc: Ba mức độ mạng lưới (đơn giản, trung bình, phức tạp). Mô hình phức tạp có tới 10 hệ số đường dẫn giữa 7 yếu tố.
- Mức độ tương quan: Giữa các yếu tố/thành phần ngoại sinh (r = 0, 0.2, 0.4) nhằm đánh giá tác động của đa cộng tuyến.
- Độ phức tạp của mô hình đo lường: Số lượng chỉ báo dao động là 3, 5, 7, và 9.
- Giá trị tham số mô hình: Các mức tham số ngẫu nhiên được chỉ định chặt chẽ (dao động từ -0.6 đến 0.6) và rút trích 4 kích thước mẫu (N = 100, 200, 500, 1000) để kiểm tra tính bền vững, tạo ra 288.000 tệp mẫu dữ liệu để phân tích.

6. Đánh Giá Hiệu Suất Và Hành Vi Hội Tụ (Performance and Convergence Behavior)
Việc đánh giá độ bền vững trước sự biểu diễn sai cấu trúc mang lại kết quả khác biệt rõ rệt giữa các thuật toán:
- Hành vi hội tụ (Convergence Behavior): Thuật toán đóng vai trò then chốt. GSCA và PLSPM không gặp vấn đề về hội tụ trong mọi điều kiện thực nghiệm. Ngược lại, ML_F và FSR gặp các vấn đề hội tụ nghiêm trọng (như ma trận không xác định dương, phương sai âm) khi áp dụng cho dữ liệu từ mô hình thành phần. Tỉ lệ lỗi hội tụ trung bình lên tới 36.1% đối với ML_F và 34.8% đối với FSR. Đáng chú ý, việc tăng kích thước mẫu lên N=1000 vẫn duy trì mức lỗi trên 30%. Điều này khẳng định việc biểu diễn sai cấu trúc là nguyên nhân chính gây ra lỗi hội tụ trong SEM dựa trên yếu tố.
- Phục hồi tham số (Parameter Recovery): Được đánh giá qua chỉ số sai số tuyệt đối trung bình (MAE).
- Dưới mô hình yếu tố: ML_F và FSR có sai số tuyệt đối trung bình (MAE) nhỏ hơn, phục hồi tham số tốt hơn.
- Dưới mô hình thành phần: GSCA và PLSPM có MAE nhỏ hơn nhiều so với ML_F và FSR.
- Khi tổng hợp rủi ro biểu diễn sai: GSCA và PLSPM ước lượng các tham số chính xác hơn so với ML_F và FSR khi cấu trúc có thể bị chỉ định sai. Đáng chú ý, phương pháp GSCA cho thấy giá trị MAE nhỏ nhất khi so sánh tổng thể, đồng thời phục hồi hệ số tải (loadings) tốt hơn hẳn PLSPM.
7. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
Trong cấu trúc của mô hình phương trình cấu trúc, mạng lưới được xác định và kiểm định tính hợp lệ thông qua:
- Tiền tố ngoại sinh (Exogenous Antecedents): Ký hiệu là η_x (đối với yếu tố) hoặc γ_x (đối với thành phần). Đây là cấu trúc khởi tạo mối quan hệ nhân quả trong mô hình cấu trúc. Bất kỳ sự thay đổi nào ở tiền tố đều truyền dẫn thông tin qua các đường dẫn (path coefficients).
- Hậu tố nội sinh (Endogenous Consequences): Ký hiệu là η_y hoặc γ_y. Biến nội sinh chịu sự tác động trực tiếp từ biến ngoại sinh cộng với một mức sai số ζ (zeta) nhất định. Khả năng giải thích của mạng lưới này thường được đo lường bằng R², và năng lực dự đoán ra ngoài mẫu được kiểm định bằng chỉ số Q².
8. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Với tư cách là người hướng dẫn phương pháp luận, các nghiên cứu sinh cần lưu ý các nguyên tắc thiết kế nghiên cứu định lượng sau:
- Không có phương pháp nào là ưu việt tuyệt đối trong mọi trường hợp. Các phương pháp SEM dựa trên yếu tố (ML_F, FSR) nên được ưu tiên để ước lượng các mô hình yếu tố truyền thống (như tâm lý học hành vi). Các phương pháp SEM dựa trên thành phần nên được chọn cho các mô hình thành phần (chỉ số sinh học, tổng hợp dữ liệu thứ cấp).
- Lựa chọn an toàn khi thiếu cơ sở lý thuyết: Trong môi trường học thuật, nếu nhà nghiên cứu thiếu cơ sở lý thuyết vững chắc để quyết định mô hình của mình (dễ bị biểu diễn sai cấu trúc), thì phương pháp GSCA được khuyến nghị sử dụng. Trong số các phương pháp dựa trên thành phần, GSCA tối ưu hóa hàm mục tiêu toàn cục nên được chọn thay vì PLSPM, bất kể cấu trúc có bị biểu diễn sai hay không.
9. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Trong nghiên cứu quản trị và kinh doanh thực tiễn, các chỉ số thường mang tính thiết kế (artefacts / design constructs) thay vì là các biến tiềm ẩn thuộc tính tâm lý thuần túy.
- Ưu tiên mô hình tổng hợp: Doanh nghiệp nên ưu tiên sử dụng GSCA hoặc PLSPM khi tạo lập các chỉ số KPI tổng hợp (như điểm số sức khỏe thương hiệu, điểm mức độ hài lòng dịch vụ, giá trị vòng đời khách hàng LTV) vì các mô hình này bản chất là mô hình tạo chỉ số (index-generating).
- Phân bổ ngân sách chính xác: Việc sử dụng ML_F cho các tệp dữ liệu KPI nội bộ thường dẫn đến việc không hội tụ (phần mềm báo lỗi hoặc ma trận không xác định dương), gây đình trệ quá trình phân tích dữ liệu quyết định chiến lược. Hơn nữa, ước lượng chệch từ thuật toán nhân tố sẽ làm sai lệch tỷ trọng tác động của các chiến dịch marketing, dẫn đến việc phân bổ sai ngân sách doanh nghiệp (CAC/ROI bị tính toán lệch).
10. Các Câu Hỏi Thường Gặp (FAQ)
Khái niệm “biểu diễn sai cấu trúc” (construct misrepresentation) trong mô hình phương trình cấu trúc là gì?
Bất kể bạn dùng AMOS, SmartPLS hay GSCA Pro, biểu diễn sai cấu trúc là việc sử dụng sai giả định đại diện thống kê cho bản chất của dữ liệu. Ví dụ, bản chất dữ liệu là một thành phần tổng hợp (Composite) nhưng nhà nghiên cứu lại áp đặt mô hình yếu tố chung (Factor) để chạy phân tích, hoặc ngược lại, dẫn đến sai lệch nghiêm trọng về hệ số tải, hệ số đường dẫn và các chỉ số độ phù hợp mô hình (GoF).
Tại sao mô hình yếu tố không phải là một trường hợp đặc biệt của mô hình thành phần như nhiều tài liệu PLS trước đây khẳng định?
Mô hình của Henseler et al. (2014) và Dijkstra chứng minh bằng nền tảng toán học rằng không thể bao hàm mô hình yếu tố vào mô hình thành phần vì mô hình thành phần luôn đòi hỏi một số ràng buộc hiệp phương sai sai số đo lường (measurement errors) phải có tương quan nhất định để tối ưu hóa trọng số. Đây là điều mà phương trình ma trận của mô hình yếu tố cơ bản không cho phép (do vấn đề nhận dạng mô hình).
Phương pháp nào chịu rủi ro cao nhất gây ra lỗi phần mềm khi phân tích dữ liệu mà không rõ lý thuyết nền tảng?
Phương pháp hợp lý cực đại (ML_F) và FSR chịu rủi ro cao nhất. Khi áp dụng sai vào mô hình thành phần, chúng có thể gặp tỷ lệ lỗi hội tụ lên tới hơn 34% (lỗi ma trận không xác định, biến thể âm). Trong khi đó, hệ thống phân tích thành phần cấu trúc tổng quát (GSCA) và PLSPM xử lý hoàn hảo mà không gặp vấn đề hội tụ.
11. Tài Liệu Tham Khảo (References)
- Antonakis, J., Bendahan, S., Jacquart, P., & Lalive, R. (2010). On making causal claims… The Leadership Quarterly, 21, 1086-1120.
- Areskoug, B. (1982). The first canonical correlation… In H. Wold & K. G. Jöreskog (Eds.).
- Bandalos, D. L., & Gagné, P. (2012). Simulation methods in structural equation modeling.
- Bentler, P. M. (1982). Confirmatory factor analysis via noniterative estimation… Journal of Marketing Research, 19(4), 417-424.
- Bollen, K. A. (1989). Structural equations with latent variables. New York, NY: Wiley.
- Bollen, K. A. (1996). An alternative two stage least squares (2SLS) estimator… Psychometrika, 61(1), 109-121.
- Bollen, K. A. (2011). Evaluating effect, composite, and causal indicators… MIS Quarterly, 35(2), 359-372.
- Bollen, K. A. (2019). Model implied instrumental variables (MIIVs)… Multivariate Behavioral Research, 54(1), 31-46.
- Bollen, K. A., & Bauldry, S. (2011). Three Cs in measurement models… Psychological Methods, 16(3), 265-284.
- Bollen, K. A., Fisher, Z. F., Giordano, M. L., Lilly, A. G., Luo, L., & Ye, A. (2021). An introduction to model implied instrumental variables… Psychological Methods.
- Bollen, K. A., & Lennox, R. (1991). Conventional wisdom on measurement… Psychological Bulletin, 110(2), 305-314.
- Borsboom, D. (2006). The attack of the psychometricians. Psychometrika, 71(3), 425-440.
- Borsboom, D. (2008). Latent variable theory. Measurement, 6(1-2), 25-53.
- Borsboom, D., Mellenbergh, G. J., & van Heerden, J. (2003). The theoretical status of latent variables. Psychological Review, 110(2), 203-219.
- Browne, M. W. (1984). Asymptotically distribution-free methods… British Journal of Mathematical and Statistical Psychology, 37(1), 62-83.
- Campbell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation… Psychological Bulletin, 56, 81-105.
- Carroll, J. D. (1968). Generalization of canonical correlation analysis… Proceedings of the 76th Annual Convention of the APA, 3, 227-228.
- Cassel, C., Hackl, P., & Westlund, A. H. (1999). Robustness of partial least-squares method… Journal of Applied Statistics, 26(4), 435-446.
- Chen, F., Bollen, K. A., Paxton, P., Curran, P. J., & Kirby, J. B. (2001). Improper solutions in structural equation models… Sociological Methods and Research, 29(4), 468-508.
- Cho, G., & Choi, J. Y. (2020). An empirical comparison of generalized structured component analysis… Behaviormetrika, 47(1), 243-272.
- Cho, G., Hwang, H., Sarstedt, M., & Ringle, C. M. (2020). Cutoff criteria for overall model fit indexes… Journal of Marketing Analytics, 8, 189-202.
- Cho, G., Kim, S., Lee, J., Hwang, H., Sarstedt, M., & Ringle, C. M. (in press). A comparative study of the predictive power… European Journal of Marketing.
- Cole, D. A., & Preacher, K. J. (2014). Manifest variable path analysis… Psychological Methods, 19(2), 300-315.
- Crawford, J. A., & Kelder, J.-A. (2019). Do we measure leadership effectively?… The Leadership Quarterly, 30(1), 133-144.
- Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52, 281-302.
- Croon, M. (2002). Using predicted latent scores in general latent structure models. In G. A. Marcoulides & I. Moustaki (Eds.).
- Deng, L., Yang, M., & Marcoulides, K. M. (2018). Structural equation modeling with many variables… Frontiers in Psychology, 9, 580.
- Devlieger, I., Mayer, A., & Rosseel, Y. (2016). Hypothesis testing using factor score regression… Educational and Psychological Measurement, 76, 741-770.
- Devlieger, I., & Rosseel, Y. (2017). Factor score path analysis… Methodology, 13(Suppl 1), 31-38.
- Dijkstra, T. K. (1981). Latent variables in linear stochastic models… PhD thesis. Groningen University.
- Dijkstra, T. K. (2011). Consistent partial least squares estimators…
- Dijkstra, T. K. (2013a). Composites as factors, generalized canonical variables revisited.
- Dijkstra, T. K. (2013b). The simplest possible factor model estimator.
- Dijkstra, T. K. (2017). A perfect match between a model and a mode. In H. Latan & R. Noonan (Eds.).
- Dijkstra, T. K., & Henseler, J. (2015). Consistent partial least squares path modeling. MIS Quarterly, 39(2), 297-316.
- Duncan, T. E., Duncan, S. C., & Strycker, L. A. (2006). An introduction to latent variable growth curve modeling…
- Edwards, J. R., & Bagozzi, R. P. (2000). On the nature and direction of relationships between constructs and measures. Psychological Methods, 5(2), 155-174.
- Goodhue, D. L., Lewis, W., & Thompson, R. (2006, 2012). PLS, small sample size, and statistical power in MIS research. MIS Quarterly, 36, 981-1001.
- Grace, J. B., & Bollen, K. A. (2008). Representing general theoretical concepts in structural equation models… Environmental and Ecological Statistics, 15(2), 191-213.
- Haile, P. (2020). ‘Structural vs. Reduced Form’… [Pdf slides].
- Hair, J. F., Howard, M. C., & Nitzl, C. (2020). Assessing measurement model quality in PLS-SEM… Journal of Business Research, 109, 101-110.
- Hair, J. F., Hult, G. T. M., Ringle, C. M., Sarstedt, M., & Thiele, K. O. (2017). Mirror, mirror on the wall… Journal of the Academy of Marketing Science, 45(5), 616-632.
- Hair, J. F., Sarstedt, M., Pieper, T. M., & Ringle, C. M. (2012). The use of partial least squares structural equation modeling… Long Range Planning, 45, 320-340.
- Hair, J. F., Sarstedt, M., Ringle, C. M., Sharma, P. N., & Liengaard, B. D. (in press). A comment on ‘Marketing or methodology?’…
- Henseler, J. (2012). Why generalized structured component analysis is not universally preferable… Journal of the Academy of Marketing Science, 40(3), 402-413.
- Henseler, J. (2017, 2021). Bridging design and behavioral research… Journal of Advertising / Composite-based structural equation modeling.
- Henseler, J., Dijkstra, T. K., Sarstedt, M., Ringle, C. M., Diamantopoulos, A., Straub, D. W., Calantone, R. J. (2014). Common beliefs and reality about PLS… Organizational Research Methods, 17(2), 182-209.
- Henseler, J., Hubona, G., & Ray, P. A. (2016). Using PLS path modeling in new technology research… Industrial Management and Data Systems.
- Henseler, J., & Schuberth, F. (2020). Using confirmatory composite analysis… Journal of Business Research, 120, 147-156.
- Holzinger, K. J., & Swineford, F. (1937). The Bi-factor method. Psychometrika, 2(1), 41-54.
- Horst, P. (1961). Relations among m sets of measures. Psychometrika, 26(2), 129-149.
- Hui, B. S., & Wold, H. (1982). Consistency and consistency at large of partial least squares estimates. In K. G. Jöreskog & H. Wold (Eds.).
- Hwang, H., & Cho, G. (2020). Global least squares path modeling… Psychometrika, 85, 947-972.
- Hwang, H., Cho, G., & Choo, H. (2021a). Manual for GSCA Pro 1.0.
- Hwang, H., Cho, G., Jin, M. J., Ryoo, J. H., Choi, Y., & Lee, S. H. (2021). A knowledge-based multivariate statistical method… PLoS One, 16(3), e0247592.
- Hwang, H., Cho, G., Jung, K., Falk, C. F., Flake, J. K., Jin, M. J., & Lee, S. H. (2020). An approach to structural equation modeling with both factors and components… Psychological Methods, 26(3), 273-294.
- Hwang, H., Malhotra, N. K., Kim, Y., Tomiuk, M. A., & Hong, S. (2010). A comparative study on parameter recovery… Journal of Marketing Research, 47, 699-712.
- Hwang, H., & Takane, Y. (2004, 2014). Generalized structured component analysis. Psychometrika, 69(1), 81-99. / New York, NY: Chapman and Hall/CRC Press.
- Hwang, H., Takane, Y., & Jung, K. (2017). Generalized structured component analysis with uniqueness terms… Frontiers in Psychology, 8, 2137.
- Hwang, H., Takane, Y., & Tenenhaus, A. (2015). An alternative estimation procedure for partial least squares… Behaviormetrika, 42(1), 63-78.
- Iacobucci, D. (2009). Everything you always wanted to know about SEM… Journal of Consumer Psychology, 19, 673-680.
- Ihara, M., & Kano, Y. (1986). A new estimator of the uniqueness in factor analysis. Psychometrika, 51(4), 563-566.
- Jensen, A. R. (1998). The g factor: The science of mental ability. Westport, CT: Praeger Publishers.
- Jöreskog, K. G. (1970a, 1970b, 1978). A general method for analysis of covariance structures… Biometrika / British Journal of Mathematical and Statistical Psychology / Psychometrika.
- Jöreskog, K. G., Andersen, E. B., Laake, P., Cox, D. R., & Schweder, T. (1981). Analysis of covariance structures… Scandinavian Journal of Statistics, 8, 65-92.
- Jung, K., Takane, Y., Hwang, H., & Woodward, T. S. (2012). Dynamic GSCA… Psychometrika, 77, 827-848.
- Kettenring, J. R. (1971). Canonical analysis of several sets of variables. Biometrika, 58(3), 433-451.
- Kiers, H. A. L., Takane, Y., & ten Berge, J. M. F. (1996). The analysis of multitrait-multimethod matrices… Psychometrika, 61, 601-628.
- Lee, S., Choi, S., Kim, Y. J., Kim, B. J., Hwang, H., & Park, T. (2016). Pathway-based approach using hierarchical components… Bioinformatics, 32, 1586-1594.
- Lohmöller, J.-B. (1989). Latent variable path modeling with partial least squares. Heidelberg, Germany: Physica.
- Lu, I. R. R., Kwan, E., Thomas, D. R., & Cedzynski, M. (2011). Two new methods for estimating structural equation models… International Journal of Research in Marketing, 28(3), 258-268.
- Lu, I. R. R., & Thomas, D. R. (2008). Avoiding and correcting bias in score-based latent variable regression… Structural Equation Modeling, 15(3), 462-490.
- Marcoulides, G. A., Chin, W. W., & Saunders, C. (2012). When imprecise statistical statements become problematic… MIS Quarterly, 36, 717-728.
- Marcoulides, G. A., & Saunders, C. (2006). Editor’s comments: PLS: A silver bullet? MIS Quarterly, 30, 3-9.
- Maydeu-Olivares, A., & Coffman, D. L. (2006). Random intercept item factor analysis. Psychological Methods, 11(4), 344-362.
- Meredith, W., & Tisak, J. (1990). Latent curve analysis. Psychometrika, 55(1), 107-122.
- Mortimer, G., Fazal e Hasan, S., Andrews, L., & Martin, J. (2016). Online grocery shopping… The International Review of Retail, Distribution and Consumer Research.
- Nunnally, J. C. (1978). An overview of psychological measurement.
- Olsson, U. H., Foss, T., Troye, S. V., & Howell, R. D. (2000). The performance of ML, GLS, and WLS estimation… Structural Equation Modeling.
- Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., & Chen, F. (2001). Monte Carlo experiments: Design and implementation. Structural Equation Modeling.
- Rademaker, M. E., Schuberth, F., & Dijkstra, T. K. (2019). Measurement error correlation within blocks of indicators… Internet Research.
- Reddy, S. K. (1992). Effects of ignoring correlated measurement error in structural equation models. Educational and Psychological Measurement.
- Reinartz, W., Haenlein, M., & Henseler, J. (2009). An empirical comparison of the efficacy of covariance-based and variance-based SEM. International Journal of Research in Marketing.
- Reiss, P. C., & Wolak, F. A. (2007). Chapter 64 structural econometric modeling… Amsterdam, Netherlands: Elsevier.
- Rhemtulla, M., van Bork, R., & Borsboom, D. (2020). Worse than measurement error… Psychological Methods.
- Rigdon, E. E. (2012). Rethinking partial least squares path modeling… Long Range Planning.
- Rigdon, E. E., Sarstedt, M., & Ringle, C. M. (2017). On comparing results from CB-SEM and PLS-SEM… Marketing ZFP.
- Ringle, C. M., Wende, S., & Becker, J. M. (2015). SmartPLS 3. Bönningstedt, Germany.
- Romdhani, H., Hwang, H., Paradis, G., Roy-Gagnon, M. H., & Labbe, A. (2015). Pathway-based association study… Genetic Epidemiology.
- Rönkkö, M. (2014). Methodological myths in management research… (Aalto University).
- Rönkkö, M., & Evermann, J. (2013). A critical examination of common beliefs about partial least squares path modeling. Organizational Research Methods.
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software.
- Sarstedt, M., Hair, J. F., Ringle, C. M., Thiele, K. O., & Gudergan, S. P. (2016). Estimation issues with PLS and CBSEM: Where the bias lies! Journal of Business Research.
- Schuberth, F. (2021). Confirmatory composite analysis using partial least squares… Review of Managerial Science.
- Schuberth, F., Henseler, J., & Dijkstra, T. K. (2018). Confirmatory composite analysis. Frontiers in Psychology, 9, 2541.
- Schwab, D. (1980). Construct validity in organizational behavior. In Research in organizational behavior (Vol. 2, pp. 3-43).
- Sherman, J., & Morrison, W. J. (1950). Adjustment of an inverse matrix… The Annals of Mathematical Statistics.
- Skrondal, A., & Laake, P. (2001). Regression among factor scores. Psychometrika, 66(4), 563-575.
- Takane, Y., & Hwang, H. (2018). Comparisons among several consistent estimators of structural equation models. Behaviormetrika.
- Takane, Y., Kiers, H. A. L., & de Leeuw, J. (1995). Component analysis with different sets of constraints… Psychometrika.
- ten Berge, J. M. F. (1993). Least squares optimization in multivariate analysis. Leiden, Netherlands: DSWO Press.
- Tenenhaus, M. (2008). Component-based structural equation modelling. Total Quality Management and Business Excellence.
- Thomson, G. H. (1934). The meaning of ‘i’ in the estimate of ‘g’. British Journal of Psychology.
- van der Aa, Z., Bloemer, J., & Henseler, J. (2015). Using customer contact centres as relationship marketing instruments. Service Business.
- Van Der Maas, H. L. J., Dolan, C. V., Grasman, R. P. P. P., Wicherts, J. M., Huizenga, H. M., & Raijmakers, M. E. J. (2006). A dynamical model of general intelligence… Psychological Review.
- van der Maas, H. L. J., Kan, K.-J., & Borsboom, D. (2014). Intelligence is what the intelligence test measures. Seriously. Journal of Intelligence.
- Wold, H. (1966, 1973, 1982a, 1982b). Các bài báo nền tảng về PLS và mô hình hóa phi tuyến.
- Yang, Y. (2018). Structural equation modelling. In P. Brough (Ed.), Advanced research methods for applied psychology.
- Yuan, K.-H., Wen, Y., & Tang, J. (2019). Regression analysis with latent variables by partial least squares… Structural Equation Modeling.
12. Lời Kêu Gọi Hành Động (CTA)
Việc nắm vững bản chất toán học của mô hình phương trình cấu trúc sẽ hỗ trợ mạnh mẽ cho các nhà nghiên cứu trong việc tránh các lỗi sai chỉ định mô hình cơ bản và chọn được phương pháp ước lượng chuẩn xác nhất. Để tiếp cận trực tiếp cấu trúc của các mô hình giả lập và quy trình thực nghiệm Monte Carlo một cách sâu sắc hơn, hãy tham khảo tài liệu chi tiết.
[Hair, J. F., Howard, M. C., & Nitzl, C. (2020). Assessing measurement model quality in PLS-SEM using confirmatory composite analysis. Journal of Business Research, 109, 101-110.]



