
Phân tích Thành phần chính (PCA) là một kỹ thuật biến đổi toán học trực giao nhằm giảm số lượng biến quan sát có tương quan thành một tập hợp ít hơn các biến độc lập tuyến tính. Khi đi sâu tìm hiểu về Phân tích Thành phần chính (PCA) (Principal Component Analysis khác gì với EFA? Tại sao máy học (Machine Learning) thích dùng PCA để giảm chiều dữ liệu?), người học thường nhầm lẫn giữa việc thu gọn dữ liệu thuần túy và khám phá nhân tố tiềm ẩn. Nguyên nhân chính của sự nhầm lẫn này là do cả hai phương pháp đều sử dụng chung nền tảng ma trận tương quan ở đầu vào. Giải pháp nhanh nhất để phân biệt là xác định rõ mục tiêu phân tích: sử dụng PCA khi cần nén thông tin để tối ưu hóa hiệu suất thuật toán, và sử dụng EFA khi cần giải thích cấu trúc lý thuyết ẩn bên dưới các biến số.

1. Tổng quan: Khái niệm Phân tích Thành phần chính (PCA) trong Thống kê học
1.1 Bản chất toán học của Principal Component Analysis
Dưới góc độ đại số tuyến tính, Phân tích Thành phần chính (PCA) là một phép biến đổi tuyến tính trực giao. Thuật toán này chuyển đổi một tập hợp các biến quan sát (Observed variables) có khả năng tương quan với nhau thành một hệ tọa độ mới. Các trục của hệ tọa độ này đại diện cho các thành phần chính (Principal Components), được thiết lập sao cho thành phần đầu tiên giải thích được phần lớn nhất của phương sai trong dữ liệu gốc, và các thành phần tiếp theo giải thích phần phương sai còn lại theo thứ tự giảm dần, đồng thời phải trực giao (không tương quan) với các thành phần trước đó.
1.2 Cơ chế giữ lại Phương sai (Variance)
PCA hoạt động dựa trên việc phân tích Ma trận hiệp phương sai (Covariance Matrix) hoặc Ma trận tương quan. Cơ chế cốt lõi bao gồm:
- Trị riêng (Eigenvalues): Đo lường lượng phương sai (Variance) của dữ liệu gốc được giữ lại bởi mỗi thành phần chính. Trị riêng càng lớn, thành phần đó càng mang nhiều thông tin.
- Vectơ riêng (Eigenvectors): Xác định hướng của không gian đặc trưng mới (hệ tọa độ mới). Chúng cung cấp trọng số tuyến tính để kết hợp các biến gốc thành các thành phần chính.

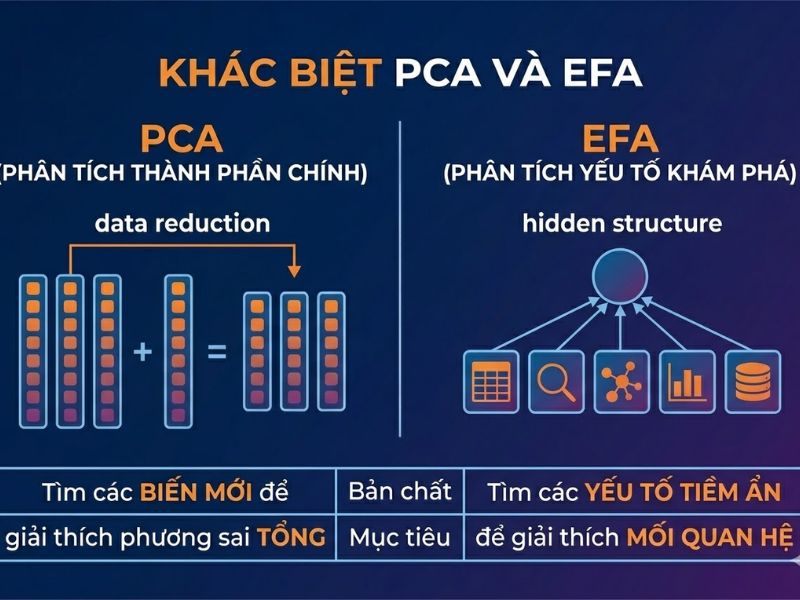
2. Phân tích Thành phần chính (PCA) khác gì với EFA?
Để làm rõ chủ đề Phân tích Thành phần chính (PCA) (Principal Component Analysis khác gì với EFA? Tại sao máy học (Machine Learning) thích dùng PCA để giảm chiều dữ liệu?), chúng ta cần phân tách bản chất của hai phương pháp này dưới góc nhìn thống kê đa biến.
2.1 Khác biệt về Mục tiêu phân tích (Định hướng mô hình)
- PCA (Principal Component Analysis): Định hướng theo cấu trúc dữ liệu. Mục tiêu tối thượng là giảm chiều dữ liệu (Dimensionality Reduction) và tối đa hóa tổng phương sai được trích xuất. PCA không giả định có một cấu trúc lý thuyết hay các nhân tố ẩn nào đứng sau dữ liệu.
- EFA (Exploratory Factor Analysis – Phân tích Nhân tố Khám phá): Định hướng theo lý thuyết. Mục tiêu là khám phá cấu trúc tiềm ẩn (Latent variables/factors) giải thích lý do tại sao các biến quan sát lại tương quan với nhau.
2.2 Khác biệt về Xử lý Phương sai (Tổng phương sai vs. Phương sai chung)
- Xử lý trong PCA: Thuật toán phân tích toàn bộ phương sai (Total Variance), bao gồm phương sai chung, phương sai đặc thù của từng biến và sai số đo lường. Hệ số tải (Loadings) trong PCA phản ánh sự kết hợp tuyến tính của tất cả các nguồn phương sai này.
- Xử lý trong EFA: Thuật toán chỉ phân tích phương sai chung (Shared Variance / Communality) giữa các biến và nỗ lực tách biệt phần sai số (Error variance) ra khỏi mô hình.
2.3 Bảng so sánh tổng quan PCA và EFA
| Tiêu chí phân tích | Phân tích Thành phần chính (PCA) | Phân tích Nhân tố Khám phá (EFA) |
| Bản chất toán học | Phép biến đổi tuyến tính trực giao | Mô hình cấu trúc phương sai |
| Mục tiêu cốt lõi | Giảm chiều dữ liệu, tóm tắt thông tin | Khám phá biến tiềm ẩn (Latent variables) |
| Loại phương sai xử lý | Tổng phương sai (Total Variance) | Phương sai chung (Shared Variance) |
| Giả định nhân quả | Các biến quan sát tạo ra Thành phần chính | Nhân tố tiềm ẩn gây ra các biến quan sát |
| Ứng dụng chủ đạo | Tiền xử lý dữ liệu cho Machine Learning | Phát triển thang đo trong nghiên cứu xã hội |
3. Tại sao máy học (Machine Learning) thích dùng PCA để giảm chiều dữ liệu?
3.1 Tối ưu hóa hiệu suất tính toán và bộ nhớ
Trong môi trường dữ liệu lớn (Big Data), thuật toán học máy thường xuyên đối mặt với “Lời nguyền của số chiều” (Curse of Dimensionality). Số lượng đặc trưng (features) quá lớn làm tăng độ phức tạp tính toán theo cấp số nhân. PCA nén dữ liệu bằng cách chiếu chúng xuống không gian có số chiều thấp hơn, giúp giảm đáng kể thời gian huấn luyện (train) mô hình và tiết kiệm tài nguyên bộ nhớ mà vẫn bảo toàn đến 90% – 95% thông tin gốc.
3.2 Khắc phục hiện tượng Đa cộng tuyến (Multicollinearity)
Đa cộng tuyến xảy ra khi các biến độc lập có sự tương quan mạnh mẽ, gây mất ổn định cho các hệ số ước lượng trong các mô hình như Hồi quy tuyến tính (Linear Regression) hoặc Logistic Regression. Do các thành phần chính (PCs) sinh ra từ PCA hoàn toàn độc lập tuyến tính (trực giao) với nhau, phương pháp này loại bỏ triệt để hiện tượng đa cộng tuyến.
3.3 Giảm thiểu nhiễu và Overfitting (Quá khớp)
Trong tập dữ liệu thực tế luôn tồn tại nhiễu (noise). Các thành phần chính có trị riêng (Eigenvalues) thấp thường là những phần tử chứa nhiễu hoặc sai số ngẫu nhiên. Bằng cách giữ lại các thành phần chính có phương sai cao và loại bỏ các thành phần có phương sai thấp, PCA giúp thuật toán học máy tập trung vào các đặc trưng cốt lõi (tín hiệu chính). Từ đó, năng lực tổng quát hóa (Generalization) của mô hình trên tập dữ liệu mới (Test set) được cải thiện, giảm thiểu nguy cơ Overfitting (Quá khớp).
3.4 Trực quan hóa dữ liệu không gian đa chiều
Con người không thể quan sát dữ liệu có lớn hơn 3 chiều không gian. PCA cho phép chiếu tập dữ liệu n-chiều xuống không gian 2D hoặc 3D. Điều này giúp các kỹ sư dữ liệu và nhà nghiên cứu dễ dàng vẽ biểu đồ phân tán (Scatter plots), nhận diện các cụm dữ liệu (clusters) và phát hiện các mẫu (patterns) trước khi đưa vào mô hình học máy.
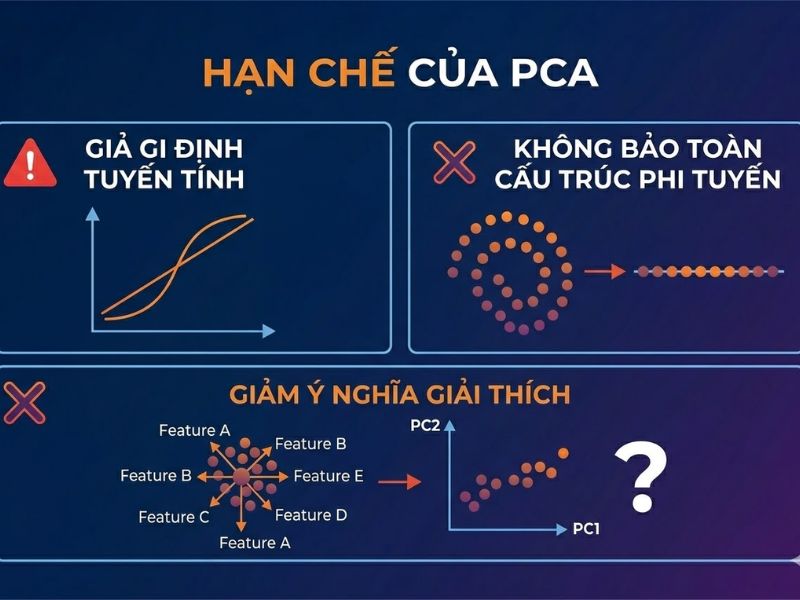
4. Hạn chế của PCA trong kỹ thuật trích xuất đặc trưng
Mặc dù mạnh mẽ về mặt toán học, PCA tồn tại những giới hạn cần lưu ý:
- Mất đi tính diễn giải (Interpretability): Các thành phần chính là sự kết hợp tuyến tính của hàng chục hoặc hàng trăm biến gốc. Việc giải thích ý nghĩa thực tế của “Thành phần 1” hay “Thành phần 2” trong ngữ cảnh kinh doanh thường bất khả thi.
- Giả định về mối quan hệ tuyến tính (Linearity): PCA chỉ có khả năng nắm bắt các cấu trúc tuyến tính. Nếu dữ liệu có cấu trúc phi tuyến phức tạp, các thuật toán như t-SNE hoặc Kernel PCA sẽ là sự lựa chọn tối ưu hơn.
- Nhạy cảm với các điểm dị biệt (Outliers): Thuật toán tối đa hóa phương sai, do đó các điểm ngoại lai có thể làm xoay trục của các vectơ riêng, dẫn đến kết quả sai lệch. Bắt buộc phải thực hiện chuẩn hóa dữ liệu (Data Standardization) trước khi chạy PCA.
5. Đánh giá tổng quan vai trò của PCA và EFA
Việc nắm vững kiến thức về Phân tích Thành phần chính (PCA) (Principal Component Analysis khác gì với EFA? Tại sao máy học (Machine Learning) thích dùng PCA để giảm chiều dữ liệu?) là nền tảng bắt buộc đối với các chuyên gia phân tích định lượng. PCA chứng minh được vị thế “tiêu chuẩn vàng” trong việc tối ưu hóa dữ liệu đầu vào, giảm chiều đặc trưng, chống nhiễu và ngăn chặn đa cộng tuyến cho các thuật toán Machine Learning. Ngược lại, EFA vẫn là công cụ không thể thay thế trong việc xây dựng và kiểm định các khái niệm học thuyết tâm lý, hành vi. Quá trình lựa chọn giữa PCA và EFA không phụ thuộc vào độ phức tạp toán học, mà hoàn toàn dựa trên mục tiêu cốt lõi của bài toán nghiên cứu thực tiễn.
Để hiểu rõ hơn về cách thiết lập các khung lý thuyết và phương pháp luận thống kê ứng dụng, độc giả có thể tham khảo chuyên mục nghiên cứu khoa học nhằm chuẩn hóa quy trình triển khai đề tài.
6. Câu hỏi thường gặp (FAQ) về thuật toán PCA và EFA
Khi nghiên cứu đề tài Phân tích Thành phần chính (PCA) (Principal Component Analysis khác gì với EFA? Tại sao máy học (Machine Learning) thích dùng PCA để giảm chiều dữ liệu?), liệu PCA có thể thay thế EFA trong nghiên cứu thiết kế thang đo không?
Không. PCA tối đa hóa tổng phương sai và trộn lẫn phương sai đặc thù, trong khi thiết kế thang đo yêu cầu cô lập phương sai chung để phản ánh biến tiềm ẩn. Do đó, EFA là bắt buộc đối với nghiên cứu thang đo xã hội học/tâm lý học.
Cần bao nhiêu thành phần chính (Principal Components) là đủ trong Machine Learning?
Tiêu chí phổ biến nhất là chọn số lượng thành phần chính sao cho tổng mức phương sai tích lũy (Cumulative Variance Explained) đạt từ 80% đến 95%. Nhà nghiên cứu cũng có thể dựa vào biểu đồ Scree Plot (điểm uốn khúc) hoặc tiêu chuẩn Kaiser (chỉ lấy Trị riêng > 1). (Lưu ý: Nếu dùng các chỉ số Fit Indices trong các mô hình SEM liên quan, tiêu chuẩn thường là R² lớn, Q² > 0, SRMR ≤ 0.08 và GFI ≥ 0.90).
Nên áp dụng PCA trước hay sau khi chuẩn hóa dữ liệu (Data Standardization)?
Bắt buộc phải áp dụng PCA sau khi chuẩn hóa dữ liệu (thường dùng Z-score standardization để đưa trung bình về 0 và phương sai về 1). Việc không chuẩn hóa sẽ khiến các biến có thang đo vật lý lớn lấn át hoàn toàn các biến có thang đo nhỏ trong kết quả tính toán thành phần chính.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



