
Vấn đề phân tích biến phụ thuộc nhị phân là một rào cản lớn trong dữ liệu định lượng. Hồi quy Logistic là mô hình thống kê chuyên dụng để lập mô hình và ước lượng xác suất của một sự kiện. Nguyên nhân chính gây sai lệch phân tích là việc sử dụng sai mô hình tuyến tính cho dữ liệu phân loại. Giải pháp nhanh nhất và tối ưu nhất là áp dụng cấu trúc phương trình Logit trên phần mềm SPSS để tính toán chính xác tỷ số Odds Ratio.
Tổng quan về Hồi quy Logistic trong nghiên cứu định lượng
Trong lĩnh vực nghiên cứu định lượng, việc lựa chọn mô hình phân tích phụ thuộc hoàn toàn vào đặc tính của dữ liệu. Trong khi hồi quy tuyến tính (Linear Regression) được thiết kế để dự báo các giá trị liên tục, Hồi quy Logistic (Logistic Regression) lại là phương pháp tối ưu để dự báo xác suất xảy ra của một sự kiện nhất định, với dải giá trị giới hạn nghiêm ngặt từ 0 đến 1. Mô hình này đóng vai trò nền tảng trong các bài toán phân loại (classification tasks) và đặc biệt quan trọng trong các thiết kế nghiên cứu đặc thù như nghiên cứu thuần tập (Cohort study) để theo dõi biến đổi hành vi hoặc tỷ lệ mắc bệnh theo thời gian.
Hồi quy Logistic (Logistic Regression) là gì?
Dưới góc độ học thuật, Hồi quy Logistic là một mô hình thống kê phân tích mối quan hệ giữa một biến phụ thuộc phân loại và một hoặc nhiều biến độc lập, thông qua việc lập mô hình log-odds (logarit tự nhiên của tỷ lệ chênh lệch) của xác suất xảy ra sự kiện.
Phương trình toán học cốt lõi biểu diễn xác suất p của sự kiện được viết dưới dạng chuẩn như sau:
p = 1 / [1 + e^-(β0 + β1x1 + … + βkxk)]
Trong đó, β0 là hằng số chặn, và β1, …, βk là các hệ số hồi quy tương ứng với các biến độc lập x1, …, xk.
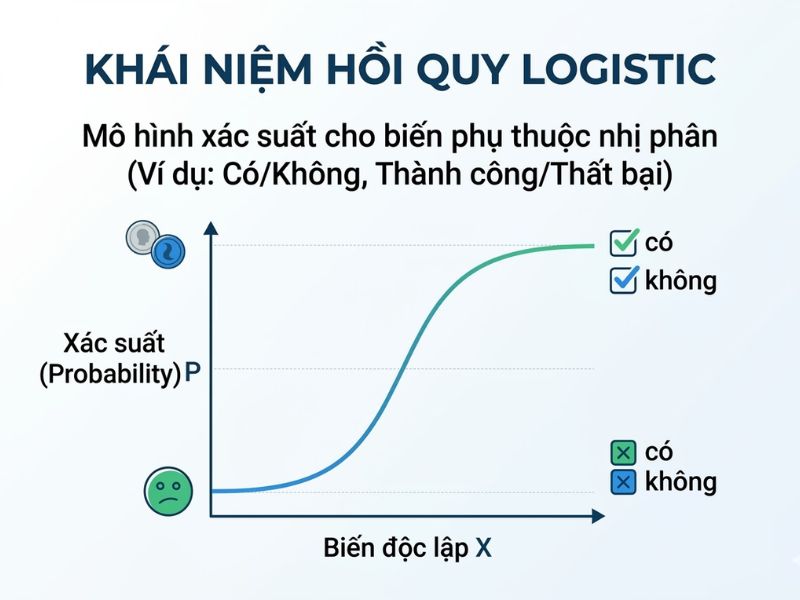
Khi nào dùng Hồi quy Logistic?
Điều kiện tiên quyết và bắt buộc để áp dụng mô hình này là biến phụ thuộc (Dependent variable) phải ở dạng Nhị phân (Binary – hay dichotomous). Các bối cảnh ứng dụng thực tiễn bao gồm:
- Y tế công cộng: Dự báo khả năng mắc bệnh (Có bệnh / Không có bệnh).
- Giáo dục học: Đánh giá kết quả đào tạo (Đạt / Trượt).
- Quản trị kinh doanh: Phân tích hành vi khách hàng (Rời bỏ dịch vụ / Tiếp tục sử dụng).
Phương trình Logit và tỷ số Odds (Odds Ratio – OR)
Khái niệm Odds (Tỷ số chênh lệch) thể hiện xác suất sự kiện xảy ra chia cho xác suất sự kiện không xảy ra (Odds = p / (1 – p)). Trong phương trình Logit, tỷ số Odds Ratio (OR) được tính bằng hàm mũ cơ số e của hệ số hồi quy (OR = e^β).
Ý nghĩa của giá trị OR được diễn giải chuẩn xác như sau:
- OR > 1: Tồn tại mối tương quan thuận. Khi biến độc lập tăng, xác suất xảy ra sự kiện ở nhóm khảo sát cao hơn nhóm tham chiếu.
- OR < 1: Tồn tại mối tương quan nghịch. Khi biến độc lập tăng, xác suất xảy ra sự kiện giảm.
- OR = 1: Không tồn tại mối tương quan thống kê giữa biến độc lập và biến phụ thuộc.
Ưu điểm và Điều kiện áp dụng (Assumptions) của mô hình
Việc suy diễn thống kê (statistical inference) chỉ đảm bảo tính khách quan và khoa học khi dữ liệu thỏa mãn các điều kiện tiên quyết của mô hình, giúp triệt tiêu các sai số ước lượng.
Sự khác biệt giữa Hồi quy Logistic và Hồi quy Tuyến tính (Linear Regression)
Việc sử dụng hồi quy tuyến tính cho biến nhị phân sẽ dẫn đến vi phạm nghiêm trọng giả định về phân phối chuẩn và phương sai sai số không đổi. Bảng dưới đây hệ thống hóa sự khác biệt cốt lõi:
| Tiêu chí phân tích | Hồi quy Tuyến tính (Linear Regression) | Hồi quy Logistic (Logistic Regression) |
| Đặc tính Biến phụ thuộc | Biến định lượng (Dữ liệu liên tục) | Biến định tính (Dữ liệu phân loại/Nhị phân) |
| Giả định Phân phối | Phân phối chuẩn (Normal Distribution) | Phân phối nhị thức (Binomial Distribution) |
| Kết quả dự báo (Output) | Giá trị cụ thể (Ví dụ: Doanh thu, Cân nặng) | Xác suất xảy ra sự kiện (Giá trị từ 0 đến 1) |
Các giả định thống kê cần thỏa mãn
Để đảm bảo kết quả Hồi quy Logistic có độ tin cậy cao, bộ dữ liệu phải đáp ứng 4 giả định sau:
- Tính độc lập của các quan sát (Independence of observations): Các trường hợp nghiên cứu không được lặp lại hoặc phụ thuộc lẫn nhau.
- Không có hiện tượng Đa cộng tuyến (Multicollinearity): Các biến độc lập không được có mức độ tương quan tuyến tính quá mạnh (thường kiểm tra qua hệ số VIF trong chẩn đoán tuyến tính).
- Quan hệ tuyến tính của Log-odds: Phải tồn tại mối quan hệ tuyến tính giữa biến độc lập liên tục và logarit của tỷ số odds (log-odds).
- Kích thước mẫu đủ lớn: Tuân thủ quy tắc tối thiểu 10 quan sát có sự kiện ít phổ biến nhất trên mỗi một biến độc lập được đưa vào mô hình.

Hướng dẫn chạy Binary Logistic trên SPSS chi tiết
Phần mềm SPSS cung cấp một thuật toán mạnh mẽ và giao diện chuẩn xác để thực thi mô hình phân tích Hồi quy Logistic, đồng thời tự động trích xuất các chỉ số kiểm định hệ số phức tạp.
Bước 1: Thiết lập biến và nhập liệu vào SPSS
- Mã hóa biến phụ thuộc: Định dạng biến phụ thuộc bắt buộc ở dạng số học, mã hóa với hai giá trị 0 (Nhóm tham chiếu/Kết quả âm tính) và 1 (Nhóm mục tiêu/Kết quả dương tính).
- Thiết lập biến độc lập: Các biến định tính (Categorical) đưa vào mô hình cần được gán mã hóa rõ ràng. Khi chạy SPSS, chuyên viên cần khai báo chính xác đặc tính này trong mục “Categorical” covariates.
Bước 2: Thao tác lệnh Analyze trong SPSS
- Truy cập theo đường dẫn thuật toán: Chọn Analyze > Regression > Binary Logistic.
- Chuyển biến nhị phân mục tiêu vào ô Dependent.
- Chuyển các biến độc lập dự báo vào ô Covariates.
- Tùy chỉnh phương pháp đưa biến vào mô hình (Ví dụ: Phương pháp Enter để đưa đồng loạt tất cả các biến, hoặc Forward: LR để phần mềm chọn lọc các biến có ý nghĩa).
Bước 3: Đọc và diễn giải kết quả Output (Interpretation)
Kết quả trích xuất (Output) từ SPSS yêu cầu nhà phân tích phải kiểm định tuần tự các bảng giá trị sau:
- Omnibus Tests of Model Coefficients: Đánh giá độ phù hợp tổng thể của mô hình so với mô hình cơ sở. Chỉ số P-value (Sig.) < 0.05 khẳng định mô hình có ý nghĩa thống kê.
- Model Summary: Bảng này cung cấp các chỉ số Pseudo R² (R-squared) như Cox & Snell R Square và Nagelkerke R Square, đại diện cho tỷ lệ phương sai của biến phụ thuộc được giải thích bởi các biến độc lập trong mô hình.
- Classification Table: Cung cấp Tỷ lệ dự báo chính xác tổng thể (Overall Percentage), cho biết mô hình phân loại đúng bao nhiêu phần trăm dữ liệu thực tế.
- Variables in the Equation: Đây là bảng quan trọng nhất để kết luận giả thuyết. Cần đọc hệ số B (Beta), mức ý nghĩa Sig. (kiểm định Wald với P-value < 0.05), và đặc biệt là hệ số Exp(B) – chính là giá trị Odds Ratio (OR) dùng để kết luận mức độ tác động của từng biến dự báo.
Tổng kết giá trị của Hồi quy Logistic đối với ra quyết định khoa học
Hồi quy Logistic (Logistic Regression) là một công cụ phân tích không thể thiếu trong khoa học dữ liệu và dịch tễ học học thuật. Bằng việc cung cấp các hệ số ước lượng xác suất chính xác cho các hiện tượng nhị phân, mô hình này hỗ trợ đắc lực cho các thiết kế như Cohort study hay phân tích rủi ro tín dụng. Việc nắm vững nền tảng toán học của log-odds kết hợp với năng lực vận hành SPSS giúp nhà nghiên cứu loại trừ sai số, từ đó đưa ra các kiến nghị mang tính hệ thống và có độ tin cậy tuyệt đối.
Câu hỏi thường gặp về mô hình Hồi quy Logistic
Có thể dùng biến phụ thuộc có 3 giá trị trở lên trong Hồi quy Logistic không?
Mô hình Binary Logistic chỉ xử lý đúng 2 giá trị. Nếu biến phụ thuộc có từ 3 giá trị trở lên ở dạng định danh không thứ bậc, giải pháp là sử dụng mô hình Hồi quy Logistic Đa thức (Multinomial Logistic Regression). Nếu các giá trị có tính thứ bậc (ví dụ: Kém, Khá, Tốt), cần áp dụng mô hình Ordinal Regression.
Kích thước mẫu (Sample size) bao nhiêu là đủ để chạy Binary Logistic trên SPSS?
Trong nghiên cứu hàn lâm, kích thước mẫu không chỉ tính bằng tổng N mà phải tuân theo quy tắc “Event per Variable” (EPV). Tối thiểu cần có 10 sự kiện (thuộc nhóm chiếm tỷ lệ thấp hơn của biến phụ thuộc) cho mỗi biến độc lập. Việc kích thước mẫu quá nhỏ sẽ gây ra hiện tượng sai số chuẩn (Standard Error) quá lớn, làm mất ý nghĩa của kiểm định Wald.
Làm thế nào để kiểm tra hiện tượng đa cộng tuyến trên SPSS cho Logistic?
Cửa sổ thiết lập lệnh Binary Logistic trong SPSS không cung cấp chỉ số VIF (Variance Inflation Factor). Giải pháp thực tế là chạy mô phỏng một lệnh hồi quy tuyến tính (Linear Regression) chứa toàn bộ các biến độc lập đó, bật tùy chọn Collinearity Diagnostics để kiểm tra hệ số VIF. Nếu VIF ≤ 10 (hoặc khắt khe hơn là < 5), dữ liệu thỏa mãn điều kiện không có đa cộng tuyến nghiêm trọng.
Tóm lại, Hồi quy Logistic là phương pháp phân tích cốt lõi giải quyết bài toán biến phụ thuộc nhị phân, chuyển đổi dữ liệu thô thành các chỉ số xác suất có tính ứng dụng cao. Đây là nền tảng vững chắc để thúc đẩy các bước tiến trong mọi công trình nghiên cứu khoa học, từ việc đo lường hành vi thị trường cho đến xác định rủi ro lâm sàng. Giới học thuật và các nhà quản trị cần tuân thủ nghiêm ngặt các giả định cấu trúc để trích xuất những luận điểm khoa học có tính chuẩn xác cao nhất.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



