
Hệ số Sig trong SPSS là gì là câu hỏi then chốt và là rào cản cốt lõi đối với tính hợp lệ của mọi mô hình phân tích dữ liệu định lượng. Bản chất của vấn đề này nằm ở việc đánh giá ý nghĩa thống kê thông qua giá trị xác suất (P-value). Nguyên nhân chính quyết định kết quả chấp nhận hay bác bỏ giả thuyết phụ thuộc vào mức ý nghĩa Alpha (α). Giải pháp nhanh nhất để diễn giải là: Nếu Sig < 0.05, bác bỏ giả thuyết Không (H0) và chấp nhận giả thuyết nghiên cứu; nếu Sig > 0.05, thực hiện quy trình ngược lại.

Giới thiệu tổng quan về hệ số Sig trong phân tích dữ liệu
Trong bất kỳ công trình nghiên cứu định lượng nào, việc đánh giá độ tin cậy của dữ liệu mẫu so với tổng thể là bước bắt buộc. Các nhà nghiên cứu sử dụng phần mềm SPSS để thực hiện các phép thử thống kê nhằm chứng minh mối quan hệ tác động, sự tương quan hoặc sự khác biệt giữa các biến số.
Dữ liệu thu thập được từ khảo sát mẫu luôn tiềm ẩn sai số lấy mẫu (sampling error). Tại đây, hệ số Sig đóng vai trò là thước đo định lượng khách quan nhất để kết luận liệu kết quả thu được là do bản chất thực sự của dữ liệu hay chỉ là do sai số ngẫu nhiên. Việc hiểu rõ hệ số này giúp loại bỏ hoàn toàn sự chủ quan trong quá trình ra quyết định, đảm bảo tính chặt chẽ và học thuật cho bài nghiên cứu.
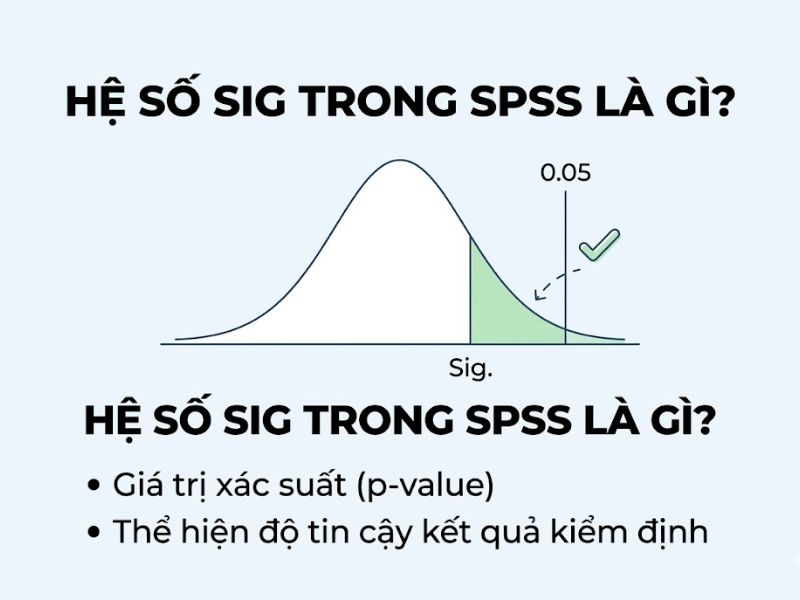
Hệ số Sig trong SPSS là gì?
Khái niệm Hệ số Sig trong SPSS là gì thường được các học giả và nhà nghiên cứu tiếp cận qua lăng kính của lý thuyết xác suất thống kê. Trong phần mềm phân tích thống kê SPSS, ký hiệu “Sig.” là viết tắt của thuật ngữ “Significance” (Ý nghĩa thống kê).
Bản chất thống kê của hệ số Sig (P-value)
Về mặt học thuật chuyên sâu, hệ số Sig chính là giá trị P-value (Probability value). Giá trị này đại diện cho xác suất xảy ra của kết quả dữ liệu mẫu thu được trong điều kiện Giả thuyết Không (H0 – Null Hypothesis) là đúng.
Giả thuyết Không (H0) luôn được phát biểu theo hướng phủ định: không có sự khác biệt, không có mối tương quan hoặc không có tác động giữa các biến đang xem xét. Khi giá trị Sig càng nhỏ, xác suất để H0 đúng càng thấp, đồng nghĩa với việc bằng chứng dữ liệu thực tế để bác bỏ Giả thuyết Không càng mạnh mẽ.
Mối liên hệ giữa hệ số Sig và mức độ tin cậy (Confidence Level)
Hệ số Sig không đứng độc lập mà luôn hoạt động dựa trên sự đối sánh trực tiếp với mức ý nghĩa (ký hiệu là Alpha – α). Mức ý nghĩa α là ngưỡng rủi ro tối đa về sai lầm loại I (tức là rủi ro bác bỏ H0 khi thực tế H0 đúng) mà nhà nghiên cứu chấp nhận trước khi tiến hành phân tích.
- Mức ý nghĩa phổ biến nhất: α = 0.05. Đây là tiêu chuẩn chung cho hầu hết các nghiên cứu kinh tế, xã hội học và quản trị kinh doanh.
- Độ tin cậy tương ứng: Mức ý nghĩa α = 0.05 tương đương với độ tin cậy (Confidence Level) là 95%. Điều này khẳng định nhà nghiên cứu tin tưởng 95% rằng kết quả không phải do ngẫu nhiên.
- Các mức ý nghĩa khác: Tùy thuộc vào tiêu chuẩn khắt khe của từng ngành, α có thể được thiết lập ở mức 0.01 (độ tin cậy 99% – thường dùng trong y tế, sinh học) hoặc 0.10 (độ tin cậy 90% – dùng trong các nghiên cứu khám phá ban đầu).
Quy tắc diễn giải hệ số Sig trong kiểm định giả thuyết
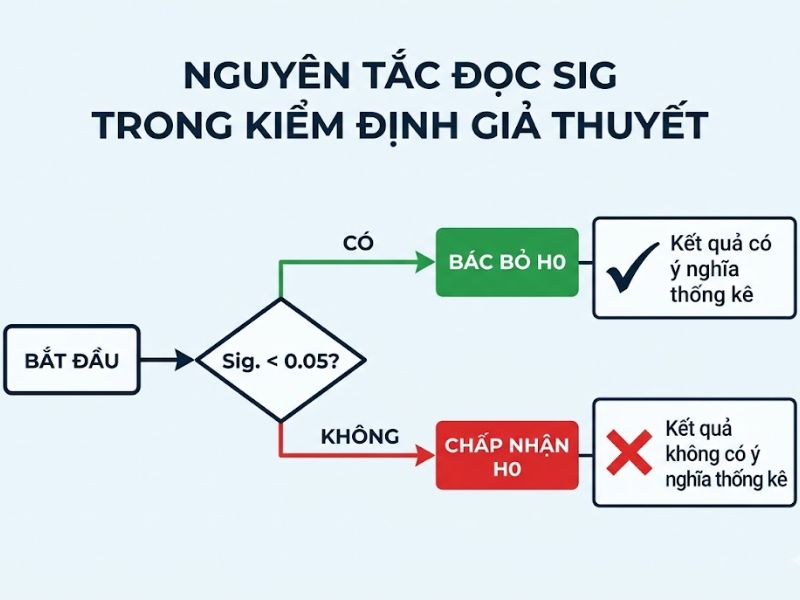
Để đảm bảo tính nhất quán trong phân tích định lượng, các nhà thống kê học áp dụng quy tắc ra quyết định (rule of thumb) dứt khoát dựa trên sự so sánh toán học giữa Hệ số Sig và mức ý nghĩa α (mặc định phổ biến là 0.05).
Trường hợp Hệ số Sig < 0.05: Chấp nhận giả thuyết nghiên cứu
Khi phần mềm SPSS xuất ra kết quả giá trị Sig nhỏ hơn 0.05, xác suất để Giả thuyết Không (H0) xảy ra là rất thấp (dưới mức rủi ro 5% cho phép).
- Nguyên tắc ra quyết định: Bác bỏ giả thuyết H0, đồng thời chấp nhận Giả thuyết Đối (H1 – Giả thuyết nghiên cứu hoặc Giả thuyết thay thế).
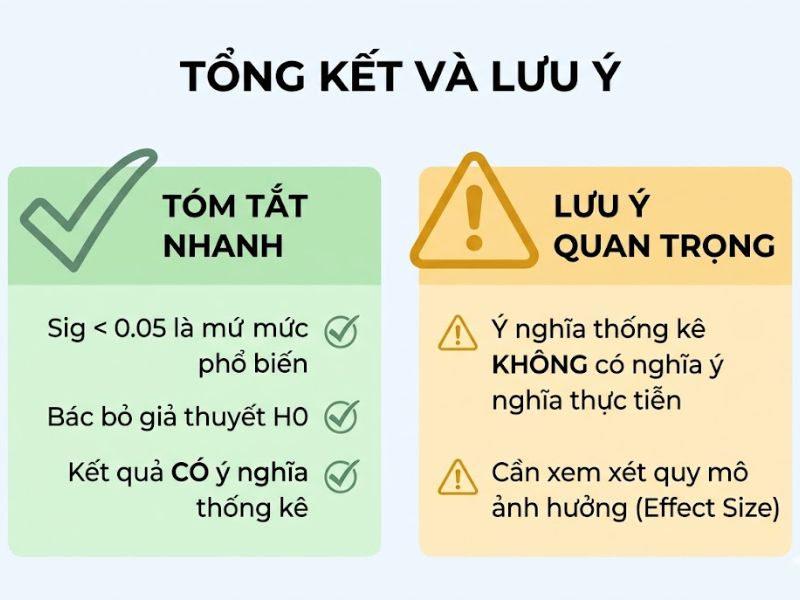
- Kết luận thống kê: Dữ liệu có ý nghĩa thống kê (Statistical Significance). Trong các mô hình phân tích, điều này chứng minh biến độc lập có tác động rõ rệt đến biến phụ thuộc, hoặc thực sự tồn tại sự tương quan/khác biệt giữa các nhóm đối tượng nghiên cứu.
Trường hợp Hệ số Sig > 0.05: Loại bỏ giả thuyết nghiên cứu
Khi giá trị Sig lớn hơn 0.05, xác suất xảy ra sai số ngẫu nhiên vượt quá ngưỡng 5% cho phép.
- Nguyên tắc ra quyết định: Hệ thống dữ liệu chưa đủ bằng chứng để bác bỏ H0, do đó bắt buộc phải chấp nhận H0 và bác bỏ Giả thuyết Đối (H1).
- Kết luận thống kê: Dữ liệu không có ý nghĩa thống kê. Biến độc lập không có tác động thực sự đến biến phụ thuộc. Trong các phân tích hồi quy, biến này bắt buộc phải bị loại khỏi mô hình để không làm sai lệch kết quả dự báo.
Bảng Tổng hợp Quy tắc Diễn giải Hệ số Sig (với α = 0.05):
| Tiêu chí phân tích | Trường hợp Hệ số Sig < 0.05 | Trường hợp Hệ số Sig > 0.05 |
| Giả thuyết Không (H0) | Bác bỏ H0 | Chấp nhận H0 |
| Giả thuyết Đối (H1) | Chấp nhận H1 | Bác bỏ H1 |
| Đánh giá tính hợp lệ | Dữ liệu có ý nghĩa thống kê (Statistical Significance) | Dữ liệu không có ý nghĩa thống kê |
| Kết luận mô hình hồi quy | Biến độc lập có tác động, được phép giữ lại trong mô hình | Biến độc lập không có tác động, bắt buộc phải loại bỏ khỏi mô hình |
Hướng dẫn đọc hệ số Sig trong các kiểm định SPSS phổ biến
Việc ứng dụng Hệ số Sig trong SPSS là gì sẽ thay đổi tùy thuộc vào loại hình kiểm định cụ thể và mục tiêu mà nhà nghiên cứu đang thực hiện. Dưới đây là quy trình phân tích cho 3 nhóm kiểm định cốt lõi.
1. Hệ số Sig trong phân tích tương quan Pearson
Phân tích tương quan Pearson (Pearson Correlation) đo lường mức độ liên hệ tuyến tính và chiều hướng tác động giữa hai biến định lượng.
- Kiểm tra Sig (2-tailed): Tại bảng Correlations, nếu Sig < 0.05, kết luận có mối tương quan tuyến tính giữa hai biến số. Nếu Sig > 0.05, hai biến không có mối tương quan thống kê, quá trình phân tích dừng lại ở cặp biến này.
- Quy trình tiếp theo: Chỉ sau khi điều kiện Sig < 0.05 được thỏa mãn, nhà nghiên cứu mới tiếp tục xem xét đến hệ số tương quan Pearson (ký hiệu là r) để đánh giá chiều hướng (tương quan thuận hay nghịch) và cường độ tương quan (mạnh hay yếu).
2. Hệ số Sig trong phân tích hồi quy tuyến tính đa biến
Trong hồi quy đa biến, hệ số Sig xuất hiện ở hai bảng kết quả quan trọng với hai vai trò hoàn toàn khác biệt:
- Kiểm định độ phù hợp của mô hình (Bảng ANOVA): Hệ số Sig tại bảng này dùng để kiểm định F (F-test) nhằm đánh giá sự phù hợp của toàn bộ cấu trúc mô hình. Nếu Sig < 0.05, mô hình hồi quy tuyến tính đa biến tồn tại, phù hợp với tập dữ liệu và có thể sử dụng để suy rộng ra tổng thể.
- Kiểm định ý nghĩa từng biến (Bảng Coefficients): Hệ số Sig tại cột “Sig.” trong bảng này đánh giá ý nghĩa tác động riêng lẻ của từng biến độc lập. Các biến có Sig < 0.05 được giữ lại vì chúng có tác động đến biến phụ thuộc. Các biến có Sig > 0.05 bị loại bỏ ngay lập tức vì sự biến thiên của chúng không đóng góp ý nghĩa thống kê vào mô hình.
3. Hệ số Sig trong kiểm định T-Test và ANOVA
Các kiểm định Independent Samples T-Test và One-Way ANOVA được thiết kế để so sánh giá trị trung bình giữa các phân nhóm nhân khẩu học hoặc danh mục.
- Kiểm định T-Test (So sánh 2 nhóm): Quy trình yêu cầu 2 bước. Bước 1: Xem xét hệ số Sig ở kiểm định Levene (Levene’s Test). Nếu Sig > 0.05, phương sai đồng nhất; nếu Sig < 0.05, phương sai không đồng nhất. Bước 2: Dựa vào kết quả Levene, đọc giá trị Sig (2-tailed) của kiểm định T-Test ở hàng tương ứng. Nếu Sig (2-tailed) < 0.05, chứng minh có sự khác biệt ý nghĩa về mặt thống kê giữa hai nhóm.
- Kiểm định ANOVA (So sánh từ 3 nhóm trở lên): Tương tự, nếu giá trị Sig tại bảng ANOVA < 0.05, chứng tỏ tồn tại sự khác biệt có ý nghĩa thống kê về mặt giá trị trung bình giữa ít nhất hai nhóm trong các biến quan sát.
Các sai lầm phổ biến khi phân tích hệ số Sig trong nghiên cứu
Trong thực hành phân tích định lượng, một sai lầm cực kỳ phổ biến của các nhà nghiên cứu là sự nhầm lẫn giữa “ý nghĩa thống kê” (Statistical significance) và “ý nghĩa thực tiễn” (Practical significance). Hệ số Sig < 0.05 chỉ chứng minh hiệu ứng quan sát được trên mẫu không phải do ngẫu nhiên, nhưng hoàn toàn không đảm bảo rằng cường độ hiệu ứng đó đủ lớn hoặc đủ mức độ quan trọng để ứng dụng vào thực tế quản trị kinh doanh.
Bên cạnh đó, việc chỉ chăm chăm nhìn vào hệ số Sig là chưa đủ để khẳng định một mô hình tốt. Khung phân tích chuẩn mực yêu cầu nhà nghiên cứu phải báo cáo kèm theo các chỉ số đo lường mức độ giải thích và độ phù hợp của mô hình (Goodness of Fit – GoF). Cụ thể, bên cạnh Sig < 0.05, các chỉ số như R² (Hệ số xác định), Q² (Năng lực dự báo), hoặc các chỉ số nâng cao như SRMR ≤ 0.08 và GFI ≥ 0.90 phải đạt chuẩn để chứng minh cấu trúc dữ liệu hoàn toàn vững chắc.
Cuối cùng, việc lạm dụng khai thác dữ liệu (P-hacking) – tức là cố tình thêm bớt biến, cắt xén dữ liệu hoặc thay đổi cấu trúc mô hình liên tục chỉ để ép giá trị Sig < 0.05 – là hành vi vi phạm nghiêm trọng đạo đức nghiên cứu học thuật.
Câu hỏi thường gặp (FAQ) về hệ số Sig trong SPSS
Sig bằng đúng 0.05 thì xử lý thế nào?
Khi hệ số Sig bằng chính xác 0.05, quyết định phụ thuộc vào tiêu chuẩn ngành và thiết kế nghiên cứu ban đầu. Tuy nhiên, theo quy tắc toán học nghiêm ngặt, Sig bắt buộc phải nhỏ hơn hẳn (<) 0.05 để đủ điều kiện bác bỏ H0. Để giải quyết ranh giới nhạy cảm này, nhà nghiên cứu nên xem xét tăng kích thước mẫu (sample size) để tăng độ chính xác, hoặc đối chiếu chéo với các chỉ số thống kê khác để đưa ra kết luận khách quan nhất.
Hệ số Sig bằng 0.000 có ý nghĩa gì?
Trên giao diện kết quả của phần mềm SPSS, khi hiển thị Sig = 0.000, điều này tuyệt đối không có nghĩa là xác suất xảy ra lỗi bằng không tuyệt đối. Nó chỉ biểu thị rằng giá trị P-value cực kỳ nhỏ (nhỏ hơn 0.001) và phần mềm làm tròn số theo định dạng hiển thị 3 chữ số thập phân. Kết quả này khẳng định mức độ tin cậy của kiểm định thống kê gần như đạt 100%, và cung cấp cơ sở dữ liệu vững chắc nhất để bác bỏ Giả thuyết Không (H0).
Kết luận về vai trò của hệ số Sig đối với tính hợp lệ của mô hình
Tóm lại, việc định nghĩa và nắm vững bản chất của Hệ số Sig trong SPSS là gì là nền tảng bắt buộc để thẩm định tính hợp lệ của mọi dự án định lượng. Chỉ số này cung cấp cơ sở toán học khách quan, đo lường xác suất sai số để nhà nghiên cứu đưa ra quyết định chấp nhận hay bác bỏ các giả thuyết học thuật. Một mô hình chỉ có giá trị khi các biến số vượt qua được bài kiểm tra khắt khe của mức ý nghĩa thống kê.
Để hiểu rõ hơn về cách xây dựng khung lý thuyết, quy trình thiết kế biến số và các tiêu chuẩn kiểm định mô hình, bạn có thể tham khảo chuyên sâu tại bài viết về phương pháp nghiên cứu khoa học nhằm tối ưu hóa chất lượng cho các công trình phân tích số liệu thực tiễn.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



