
Vấn đề đánh giá mối quan hệ tuyến tính là cốt lõi trong phân tích định lượng. Trong các nghiên cứu học thuật và ứng dụng thực tiễn, Hệ số tương quan Pearson là thước đo thống kê mức độ liên hệ tuyến tính giữa hai biến định lượng. Nguyên nhân chính dẫn đến sai lệch đo lường là dữ liệu không có phân phối chuẩn hoặc chứa các giá trị ngoại lệ. Giải pháp nhanh nhất là phân tích ma trận tương quan kết hợp giá trị p-value, và chuyển sang sử dụng hệ số Spearman nếu dữ liệu vi phạm giả định chuẩn.

1. Hệ số tương quan Pearson là gì?
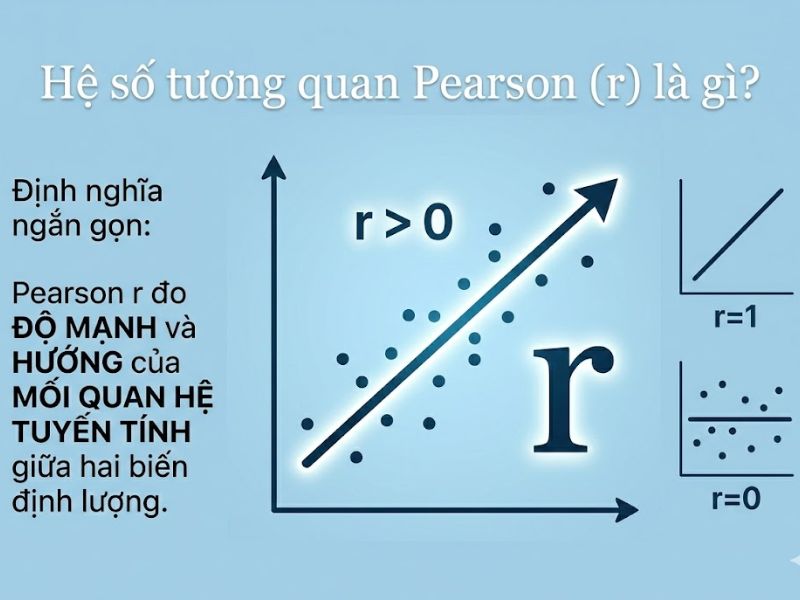
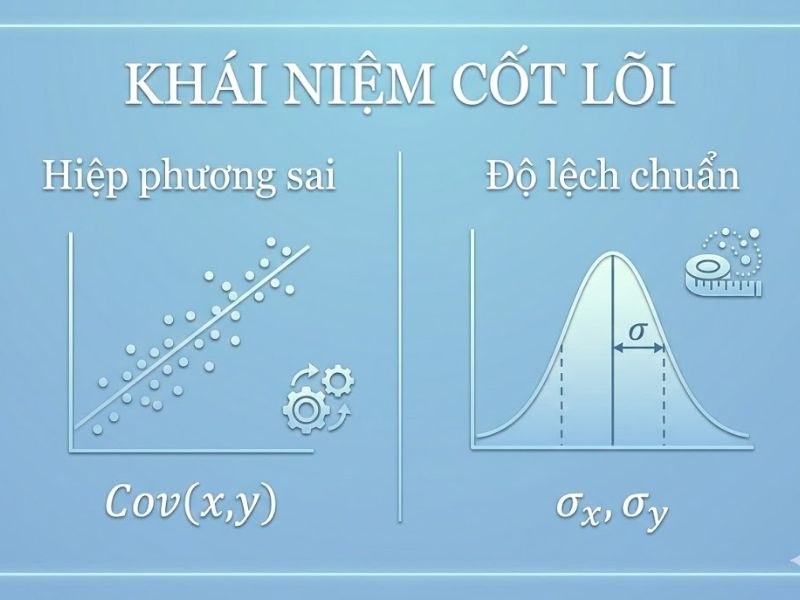
Định nghĩa chi tiết: Hệ số tương quan Pearson (Pearson Correlation Coefficient, ký hiệu là r) là một chỉ số thống kê thuộc lĩnh vực thống kê suy diễn. Khái niệm này được sử dụng để định lượng cường độ và chiều hướng của mối quan hệ tuyến tính giữa hai biến định lượng liên tục. Về mặt toán học, hệ số tương quan Pearson được tính bằng tỷ số giữa hiệp phương sai của hai biến và tích của hai độ lệch chuẩn của chúng.
So sánh sự khác biệt: Khác với phân tích hồi quy (vốn có mục tiêu chỉ ra mối quan hệ nhân quả và dự báo sự phụ thuộc của một biến vào biến khác), hệ số tương quan Pearson hoàn toàn không khẳng định tính nhân quả. Chỉ số này chỉ đo lường mức độ biến thiên đồng thời của hai biến số trên một bình diện không gian định lượng, không phân biệt rạch ròi đâu là biến nguyên nhân và đâu là biến kết quả.
Luận điểm chính: Sự thay đổi của một biến số sẽ kéo theo sự thay đổi đồng biến (tăng cùng tăng) hoặc nghịch biến (tăng làm giảm) với biến số còn lại theo một tỷ lệ tuyến tính cố định. Nghĩa là, nếu biểu diễn trên đồ thị phân tán (Scatter plot), các điểm dữ liệu sẽ có xu hướng hội tụ xung quanh một đường thẳng.
Các thành phần cốt lõi cấu trúc nên hệ số bao gồm:
- Biến số khảo sát: Bao gồm biến độc lập (Independent variable) và biến phụ thuộc (Dependent variable). Hai biến này bắt buộc phải được thu thập dưới dạng dữ liệu liên tục.
- Hiệp phương sai (Covariance): Đo lường sự biến thiên cùng nhau của hai biến. Nếu hiệp phương sai dương, hai biến di chuyển cùng chiều; nếu âm, hai biến di chuyển ngược chiều.
- Độ lệch chuẩn (Standard deviation): Thước đo mức độ phân tán của từng tập dữ liệu riêng biệt. Việc chia hiệp phương sai cho tích độ lệch chuẩn giúp chuẩn hóa hệ số tương quan Pearson về dải giá trị từ -1 đến +1.
Mục tiêu cốt lõi: Mục đích cuối cùng của việc sử dụng hệ số tương quan Pearson là xác định xem hai biến số có mối quan hệ thống kê có ý nghĩa hay không, qua đó làm cơ sở đầu vào để tiến hành các mô hình phân tích bậc cao hơn như hồi quy tuyến tính, phân tích nhân tố (EFA) hoặc mô hình phương trình cấu trúc (SEM). Đặc biệt trong mô hình SEM, ma trận tương quan chính là dữ liệu đầu vào cốt lõi để phần mềm (như AMOS, SmartPLS) tính toán các chỉ số độ phù hợp của mô hình (Model Fit) như mức độ phù hợp tổng thể GoF, đảm bảo các chỉ tiêu khắt khe như SRMR ≤ 0.08 và GFI ≥ 0.90, cũng như đánh giá năng lực dự báo Q² của toàn bộ hệ thống.
2. Lịch sử hình thành và phát triển của lý thuyết
Sự phát triển của hệ số này gắn liền với các học giả đặt nền móng cho thống kê hiện đại, tạo ra một bước ngoặt lớn trong việc lượng hóa các nghiên cứu khoa học.
- Giai đoạn Khởi nguồn: Francis Galton (thập niên 1880) – Trong các nghiên cứu về di truyền học và sự thoái hóa kích thước hạt đậu, Galton đã phát hiện ra hiện tượng “hồi quy về mức trung bình” và đặt nền móng khái niệm đầu tiên về “tương quan” (correlation) để đo lường mức độ giống nhau giữa các thế hệ. Tuy nhiên, công trình của Galton lúc bấy giờ chỉ mới dừng lại ở các phác thảo đồ thị trực quan và lý luận sinh học.
- Giai đoạn Hoàn thiện/Phát triển: Karl Pearson (1896) – Thông qua tác phẩm kinh điển “Mathematical Contributions to the Theory of Evolution”, Pearson đã chính thức công thức hóa nền tảng toán học của Galton. Ông xây dựng phương trình chuẩn mực cho hệ số tương quan Pearson (ký hiệu r), sử dụng phương pháp tích-mômen (product-moment), biến ý tưởng sơ khai thành một khung phân tích hoàn chỉnh được ứng dụng toàn cầu cho đến ngày nay.

3. Các miền nội dung khái niệm cốt lõi (Core Concepts)
Để ứng dụng đúng thuật toán trên các phần mềm như SPSS, nhà nghiên cứu cần nắm vững các giả định và đặc tính cơ bản của lý thuyết. Việc bỏ qua các kiểm định này sẽ dẫn đến kết quả phân tích thống kê vô giá trị.
Các giả định nền tảng (Nguyên lý hoạt động):
- Giả định 1 (Tính tuyến tính): Mối quan hệ giữa hai biến khảo sát phải là một đường thẳng. Nếu tỷ lệ thay đổi không ổn định (ví dụ dạng hình parabol hay đường cong bậc hai), chỉ số r sẽ không phản ánh đúng bản chất mối quan hệ, trả về giá trị xấp xỉ 0 dù hai biến thực sự có liên hệ mật thiết.
- Giả định 2 (Phân phối chuẩn): Dữ liệu của các biến định lượng phải tuân theo phân phối chuẩn (Normal distribution). Mọi sự sai lệch lớn khỏi hình chuông phân phối chuẩn đều làm giảm độ tin cậy của thuật toán. Sự phân phối chuẩn này cần được kiểm định chéo bằng biểu đồ Histogram hoặc phép thử Shapiro-Wilk trước khi chạy ma trận tương quan.
Các đặc tính/biến số quan trọng:
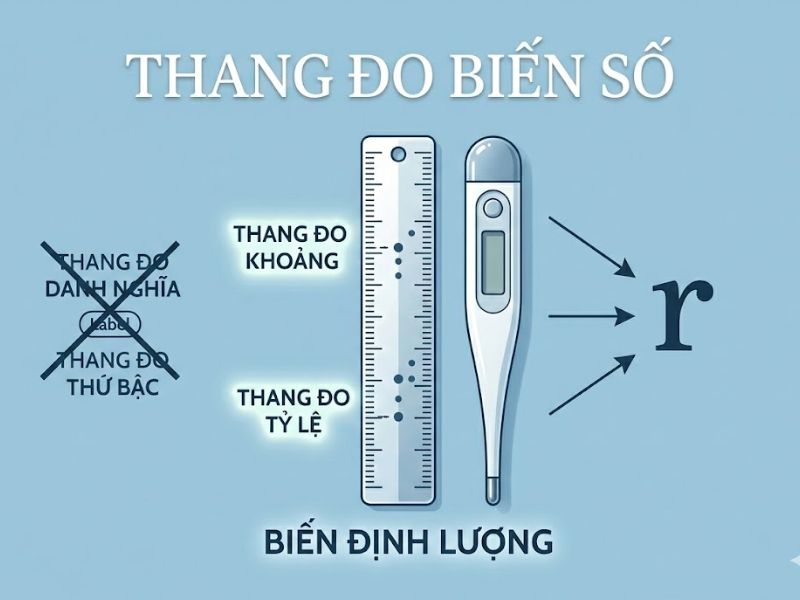
- Biến liên tục (Continuous variables): Dữ liệu phải được đo lường trên thang đo khoảng (interval) hoặc thang đo tỷ lệ (ratio). Hệ số tương quan Pearson không thể áp dụng cho các biến danh nghĩa (nominal) như giới tính hay nghề nghiệp.
- Giá trị ngoại lệ (Outliers): Dữ liệu không được chứa các điểm dị biệt quá lớn, do hệ số này sử dụng giá trị trung bình trong phương trình tính toán, khiến nó rất nhạy cảm với các nhiễu loạn cục bộ. Một vài giá trị outlier cực đoan có thể bóp méo hoàn toàn phương chiều và độ lớn của r.
Bảng so sánh cơ sở phân tích cấu trúc dữ liệu:
| Tiêu chí phân tích | Hệ số tương quan Pearson | Hệ số tương quan Spearman |
| Loại dữ liệu (Data Type) | Thang đo khoảng (Interval), Tỷ lệ (Ratio) | Thang đo thứ bậc (Ordinal), Khoảng, Tỷ lệ |
| Giả định phân phối | Bắt buộc có phân phối chuẩn | Phi tham số (Không yêu cầu phân phối chuẩn) |
| Mối quan hệ đo lường | Tuyến tính (Linear) | Đơn điệu (Monotonic) |
| Độ nhạy cảm ngoại lệ | Rất cao | Thấp (do sử dụng thứ hạng – Rank) |
| Bản chất toán học | Dựa trên giá trị thực tế của tập dữ liệu | Dựa trên hạng (rank) của các giá trị dữ liệu |
4. Nội hàm các khái niệm và Thang đo các biến (Measurement Scales)
Dành cho hoạt động nghiên cứu định lượng trên các phần mềm thống kê như SPSS, R, hoặc STATA. Khi đọc ma trận tương quan, có hai thông số sinh tử cần phải diễn giải đồng thời.
- Đo lường Biến số 1 (Giá trị r): Đại diện cho cường độ và chiều hướng. Thang đo giá trị nằm trong khoảng [-1, 1]. Bình phương của r (r²) sẽ tạo ra hệ số xác định R², cho biết tỷ lệ phương sai của biến này được giải thích bởi biến kia.
- r > 0: Tương quan thuận (Đồng biến). Nghĩa là X tăng thì Y tăng.
- r < 0: Tương quan nghịch (Nghịch biến). Nghĩa là X tăng thì Y giảm.
- Mức độ: Yếu (|r| < 0.3), Trung bình (0.3 ≤ |r| ≤ 0.5), Mạnh (|r| > 0.5). Nếu r = 1 hoặc r = -1, đó là tương quan hoàn hảo tuyệt đối.
- Đo lường Biến số 2 (Độ tin cậy P-value): Đại diện cho mức ý nghĩa thống kê (Statistical significance). Đo lường trực tiếp thông qua kiểm định giả thuyết với H0 (giả thuyết không) cho rằng r = 0 (không có tương quan trong tổng thể). Nếu giá trị p ≤ 0.05 (mức ý nghĩa 5%), mối tương quan được khẳng định là có ý nghĩa thống kê, bác bỏ giả thuyết không (H0). Nếu p > 0.05, mọi giá trị của r thu được đều không có giá trị suy diễn cho tổng thể.
5. Các nghiên cứu liên quan tiêu biểu (Related Studies)
Hệ số tương quan Pearson đã được minh chứng tính hiệu quả qua hàng triệu công trình học thuật trên nhiều khía cạnh khác nhau.
- Nhóm 1 – Các bài báo nền tảng (Foundational Works): Pearson, K. (1896). “Mathematical Contributions to the Theory of Evolution. III. Regression, Heredity, and Panmixia”, Philosophical Transactions of the Royal Society. Công trình này khai sinh ra hệ số r dựa trên hiệp phương sai mẫu. Nó thiết lập nguyên lý cơ bản nhất về sự biến thiên đồng thời trong toán thống kê.
- Nhóm 2 – Ứng dụng trong nghiên cứu khoa học hành vi: Thường được áp dụng trong giáo dục và tâm lý học để đo lường. Ví dụ: Các nghiên cứu đánh giá mối tương quan giữa số giờ tự học (thang đo tỷ lệ) và điểm GPA trung bình của sinh viên đại học. Nhờ chỉ số Pearson, các nhà quản lý giáo dục chứng minh được sự đồng biến chặt chẽ giữa thời lượng nỗ lực và kết quả học thuật.
- Nhóm 3 – Phân tích tổng hợp (Meta-Analysis) và đánh giá: Các nghiên cứu (ví dụ của Bishara & Hittner, 2012) chuyên đánh giá hệ thống về sai số thống kê, chứng minh rằng việc lạm dụng hệ số tương quan Pearson trong các dữ liệu vi phạm giả định chuẩn hoặc chứa thang đo thứ bậc (ordinal data) sẽ dẫn đến kết quả phân tích thiên lệch (biased). Điều này nhắc nhở giới nghiên cứu phải rà soát chặt chẽ tiền đề dữ liệu.
6. Những mặt hạn chế và khoảng trống nghiên cứu (Limitations)
Không có lý thuyết thống kê nào là hoàn hảo và tuyệt đối. Việc nhận thức rõ ràng các giới hạn của hệ số tương quan Pearson giúp tránh được các diễn giải sai lầm trong báo cáo khoa học.
- Hạn chế về bối cảnh (Tính nhân quả): Một nguyên lý kinh điển là “Correlation does not imply causation” (Tương quan không đồng nghĩa với nhân quả). Hệ số này chỉ cho thấy hai biến di chuyển cùng nhau, hoàn toàn không chứng minh được biến này là nguyên nhân sinh ra biến kia. Sự tương quan đôi khi được tạo ra bởi một biến thứ ba (biến ẩn – lurking variable) tác động đồng thời lên cả hai biến đang khảo sát.
- Hạn chế về đo lường (Sự nhạy cảm với Outliers): Phương trình cấu tạo dựa trên giá trị trung bình (X̄, Ȳ). Chỉ cần 1-2 giá trị ngoại lệ cực lớn hoặc cực nhỏ xuất hiện trong tập mẫu, toàn bộ cấu trúc ma trận tương quan sẽ bị méo mó, dẫn đến các suy luận sai lầm (Type I hoặc Type II errors).
- Hạn chế về giả định (Bỏ qua cấu trúc phi tuyến tính): Nếu hai biến có mối quan hệ rất chặt chẽ nhưng theo hình nón hoặc parabol (ví dụ hiệu suất làm việc ban đầu tăng theo áp lực, nhưng khi áp lực quá lớn thì hiệu suất giảm đột ngột), chỉ số Pearson sẽ trả về kết quả xấp xỉ 0. Việc này tạo ra một “khoảng trống”, bỏ sót hoàn toàn các cấu trúc hình học phức tạp.
7. Các hướng nghiên cứu (Research Applications)
Trong bối cảnh khoa học dữ liệu hiện đại, hệ số tương quan Pearson không đứng độc lập mà được tích hợp làm công cụ sàng lọc cho các khung lý thuyết phức tạp hơn.
- Kết hợp với Lý thuyết Hồi quy đa biến (Multiple Regression): Ứng dụng hệ số này như một công cụ tầm soát đa cộng tuyến (Multicollinearity). Khi ma trận tương quan chỉ ra mức độ liên hệ giữa hai biến độc lập quá lớn (thường r > 0.8), nhà nghiên cứu cần loại bỏ hoặc cấu trúc lại biến trước khi chạy hồi quy. Việc không loại bỏ hiện tượng đa cộng tuyến sẽ làm sai lệch các hệ số beta trong phương trình hồi quy.
- Kết hợp trong Hệ thống Học máy (Machine Learning / AI): Trong giai đoạn tiền xử lý dữ liệu (Data Pre-processing), ma trận tương quan Pearson được ứng dụng mạnh mẽ vào kỹ thuật chọn đặc trưng (Feature Selection). Các thuật toán dùng nó để lọc bỏ các tính năng dư thừa, giảm chiều dữ liệu (Dimensionality reduction), giúp tối ưu hóa sức mạnh tính toán cho mô hình và ngăn chặn hiện tượng Overfitting (quá khớp).
8. Cách ứng dụng lý thuyết vào thực tiễn doanh nghiệp (Practical Application)
Việc nắm vững chỉ số thống kê này cung cấp một công cụ tư duy sắc bén cho nhà quản trị trong môi trường thực tế, biến dữ liệu thô thành thông tin hỗ trợ chiến lược.
- Ứng dụng 1: Hỗ trợ Quyết định Marketing & Nghiên cứu thị trường. Đo lường mối tương quan giữa chi phí quảng cáo (Ad Spend) và doanh thu mang lại (Revenue). Dựa vào chỉ số r và p-value, doanh nghiệp xác định tính hiệu quả của kênh phân phối để quyết định tăng hay cắt giảm ngân sách. Nếu r rất lớn và p ≤ 0.05, điều này chứng minh hiệu suất ROI từ hoạt động tiếp thị là rất khả quan.
- Ứng dụng 2: Quản trị Nhân sự (HRM). Đo lường mối tương quan giữa cấu trúc lương thưởng (Mức lương cơ bản/KPI) và tỷ lệ giữ chân nhân tài hoặc mức độ gắn kết công việc. Dữ liệu này giúp định hình các chiến lược đãi ngộ bằng chứng thực tế thay vì cảm tính, giúp phòng nhân sự tập trung ngân sách vào đúng yếu tố có tương quan mạnh nhất với sự hài lòng của nhân viên.
- Ứng dụng 3: Quản trị Chuỗi cung ứng và Rủi ro. Phân tích tương quan giữa thời gian giao hàng (Lead time) và tỷ lệ lỗi sản phẩm để tối ưu hóa lại các khâu kiểm soát chất lượng nội bộ. Việc phát hiện ra các hệ số tương quan nghịch có giá trị lớn giúp các nhà quản trị điều chỉnh chuỗi quy trình nhằm chặn đứng các rủi ro vận hành.
9. Các câu hỏi thường gặp (FAQ)
Tại sao p-value ≤ 0.05 nhưng hệ số r lại quá thấp (dưới 0.2)?
Mức ý nghĩa p ≤ 0.05 chỉ xác nhận rằng mối tương quan giữa hai biến là “có tồn tại thực sự trong tổng thể” (không phải do sai số ngẫu nhiên của việc chọn mẫu). Tuy nhiên, r < 0.2 chứng tỏ mức độ liên hệ (cường độ) của chúng trong thực tế là cực kỳ yếu, gần như không có tác động đáng kể để sử dụng cho việc ra quyết định. Trong các mẫu dữ liệu lớn (N > 1000), p-value rất dễ đạt mức ý nghĩa dù r vô cùng nhỏ.
Khi nào bắt buộc phải dùng Spearman thay cho hệ số tương quan Pearson?
Bạn phải dùng hệ số Spearman khi phân tích kiểm định (như Shapiro-Wilk hoặc Kolmogorov-Smirnov) xác nhận dữ liệu của bạn không có phân phối chuẩn, hoặc tập dữ liệu có chứa quá nhiều giá trị ngoại lệ (outliers) không thể loại bỏ, hoặc khi biến đang đo lường thuộc thang đo thứ bậc (ordinal data – ví dụ: xếp hạng năng lực từ 1 đến 5). Spearman sử dụng thứ hạng thay vì giá trị thực tế nên loại trừ được sự sai lệch do hình dạng phân phối gây ra.
Làm sao để phát hiện dữ liệu vi phạm giả định tuyến tính trước khi chạy SPSS?
Cách trực quan và chính xác nhất là vẽ đồ thị phân tán (Scatter plot) giữa hai biến số. Nếu các điểm dữ liệu tụ tập thành một đường cong, đường parabol, hoặc một đám mây hình tròn không định hướng, dữ liệu đã vi phạm giả định tuyến tính. Lúc này, việc cố tình chạy ma trận tương quan Pearson sẽ cho ra những kết quả không phản ánh đúng sự thật khoa học.
10. Kết luận
Việc đánh giá mối liên hệ dữ liệu bằng hệ số tương quan Pearson không chỉ là một quy trình hàn lâm bắt buộc trong nghiên cứu định lượng mà còn là kim chỉ nam quan trọng hỗ trợ ra quyết định trong thực tiễn doanh nghiệp. Bằng cách định lượng hóa cường độ và chiều hướng bằng các chỉ số r và r², thuật toán này giảm thiểu các suy luận cảm tính, mang lại cơ sở vững chắc cho mọi phân tích nâng cao tiếp theo. Để đảm bảo tính chính xác khoa học, người thực hành bắt buộc phải rà soát chặt chẽ các giả định về phân phối chuẩn và tính tuyến tính trước khi thiết lập ma trận tương quan. Bất kỳ sự cẩu thả nào trong khâu làm sạch giá trị ngoại lệ đều có thể dẫn tới sự thất bại của toàn bộ hệ thống mô hình định lượng.
Bài viết được nghiên cứu, tổng hợp chuyên sâu và biên tập bởi giảng viên Nguyễn Thanh Phương. Hệ thống kiến thức này nhằm mang lại những góc nhìn khoa học chuẩn xác, ứng dụng thực chứng dành cho giới nghiên cứu sinh và các nhà quản trị điều hành.



