
Phân tích nhân tố khám phá EFA (Exploratory Factor Analysis) là phương pháp thống kê định lượng được sử dụng để rút gọn một tập hợp gồm nhiều biến quan sát phụ thuộc lẫn nhau thành một số ít các cấu trúc cơ bản (nhân tố) mà vẫn giữ được tối đa thông tin của dữ liệu gốc. Mục đích chính của kỹ thuật này là xác định cấu trúc của thang đo, kiểm định giá trị hội tụ và giá trị phân biệt của các biến trong mô hình nghiên cứu.

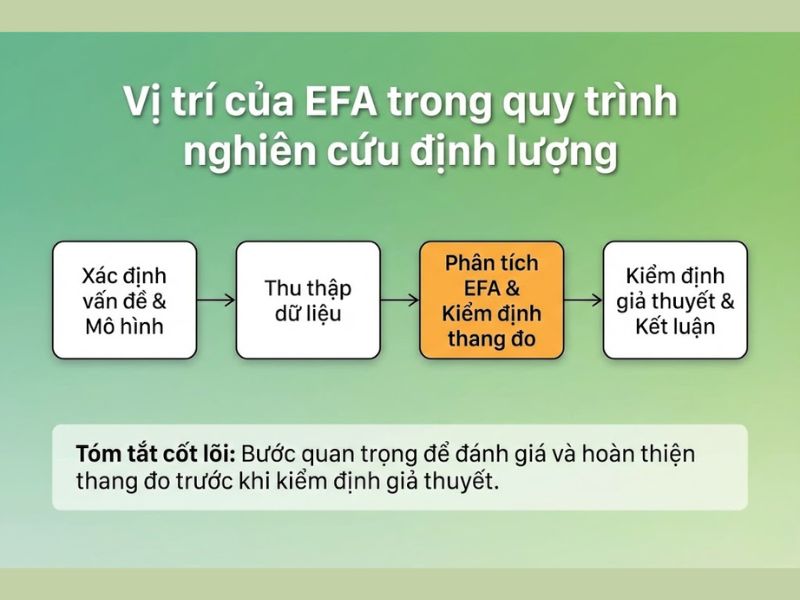
Vị trí của EFA trong quy trình nghiên cứu định lượng
Trong một quy trình xử lý dữ liệu chuẩn mực (đặc biệt là với phần mềm SPSS hoặc AMOS), phân tích nhân tố khám phá EFA đóng vai trò là “bộ lọc” quan trọng thứ hai, ngay sau bước kiểm định độ tin cậy thang đo (Cronbach’s Alpha).
Nếu Cronbach’s Alpha giúp loại bỏ các biến “rác” không đảm bảo tính nhất quán nội tại, thì EFA sẽ sắp xếp lại các biến còn lại vào các nhóm nhân tố phù hợp dựa trên mối tương quan giữa chúng. Chỉ khi thang đo đạt yêu cầu tại bước này, nhà nghiên cứu mới có đủ cơ sở dữ liệu sạch để tiến hành các phân tích cao cấp hơn như Phân tích nhân tố khẳng định (CFA), Mô hình cấu trúc tuyến tính (SEM) hoặc Hồi quy tuyến tính đa biến. Việc bỏ qua EFA có thể dẫn đến hiện tượng đa cộng tuyến nghiêm trọng trong các bước phân tích sau.
Điều kiện cần để thực hiện phân tích
Để kết quả phân tích nhân tố khám phá EFA có ý nghĩa thống kê và phản ánh đúng thực tế dữ liệu, nghiên cứu cần thỏa mãn các điều kiện tiên quyết sau về kích thước mẫu và mối quan hệ biến:
- Kích thước mẫu (Sample Size): Theo nhà nghiên cứu Hair và cộng sự (2014), kích thước mẫu tối thiểu để chạy EFA là 50, nhưng tốt nhất là từ 100 trở lên. Tỷ lệ quan sát trên biến đo lường (observation/variable ratio) tối ưu là 5:1, nghĩa là cứ 1 biến quan sát cần tối thiểu 5 mẫu khảo sát. Ví dụ: Thang đo có 20 câu hỏi thì cần tối thiểu 100 mẫu.
- Tính tương quan: Giữa các biến quan sát phải có mối tương quan với nhau. Nếu các biến độc lập hoàn toàn (ma trận đơn vị), việc phân tích nhân tố sẽ không có giá trị. Điều này được kiểm định thông qua chỉ số KMO và kiểm định Bartlett.

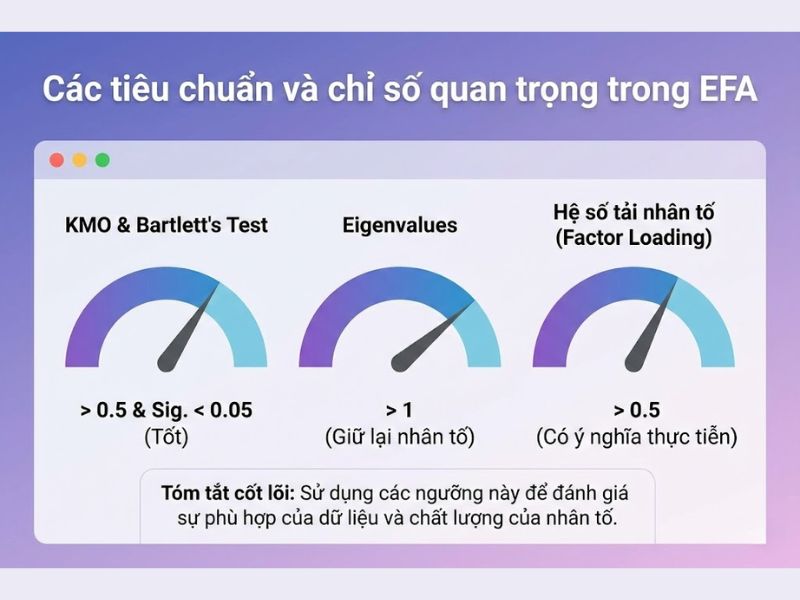
Các tiêu chuẩn và chỉ số quan trọng trong EFA
Để tối ưu hóa việc đọc kết quả và giúp các nhà nghiên cứu dễ dàng tra cứu, dưới đây là bảng tổng hợp các tiêu chuẩn kiểm định bắt buộc phải thông qua khi thực hiện EFA.
| Chỉ số (Index) | Tiêu chuẩn đạt (Condition) | Ý nghĩa (Meaning) |
| KMO (Kaiser-Meyer-Olkin) | 0.5 ≤ KMO ≤ 1 | Chỉ số dùng để xem xét sự thích hợp của phân tích nhân tố. KMO < 0.5 cho thấy EFA không phù hợp với dữ liệu. |
| Kiểm định Bartlett (Sig.) | Sig. < 0.05 | Kiểm định giả thuyết H0: Ma trận tương quan là ma trận đơn vị. Sig < 0.05 chứng tỏ các biến có tương quan với nhau. |
| Giá trị riêng (Eigenvalue) | Eigenvalue > 1 | Chỉ những nhân tố có Eigenvalue > 1 mới được giữ lại trong mô hình phân tích. |
| Tổng phương sai trích (Total Variance Explained) | ≥ 50% | Mô hình EFA giải thích được ít nhất 50% sự biến thiên của dữ liệu quan sát. |
| Hệ số tải nhân tố (Factor Loading) | ≥ 0.5 | Biểu thị mối quan hệ tương quan giữa biến quan sát với nhân tố. Biến có hệ số tải < 0.5 được xem là biến rác và cần loại bỏ. |
Quy trình thực hiện Phân tích nhân tố khám phá EFA
Việc thực hiện phân tích nhân tố khám phá EFA trên các phần mềm thống kê như SPSS cần tuân thủ quy trình kỹ thuật nghiêm ngặt để đảm bảo tính khách quan của dữ liệu. Dưới đây là các bước tiêu chuẩn:
- Thiết lập phương pháp trích (Extraction Method): Phương pháp phổ biến nhất là Principal Component Analysis. Phương pháp này giúp rút trích các nhân tố sao cho chúng giải thích được nhiều nhất sự biến thiên của dữ liệu gốc.
- Lựa chọn phép xoay (Rotation Method):
- Varimax: Phép xoay vuông góc. Thường dùng khi giả định các nhân tố không có tương quan với nhau. Đây là phép xoay phổ biến nhất giúp tối thiểu hóa số lượng biến có hệ số tải lớn tại cùng một nhân tố, giúp việc giải thích nhân tố dễ dàng hơn.
- Promax: Phép xoay không vuông góc. Dùng khi các nhân tố có sự tương quan với nhau.
- Sàng lọc biến (Variable Filtering): Dựa vào bảng Ma trận xoay (Rotated Component Matrix), nhà nghiên cứu tiến hành loại bỏ các biến có hệ số tải (Factor Loading) nhỏ hơn 0.5 hoặc các biến bị tải đôi (xem chi tiết ở phần dưới).
- Định danh nhân tố: Sau khi loại bỏ biến xấu, các biến còn lại sẽ hội tụ về các nhóm nhân tố. Nhà nghiên cứu cần dựa vào nội dung của các biến trong nhóm để đặt tên mới cho nhân tố đó, đảm bảo phản ánh đúng bản chất khái niệm.

Các lỗi thường gặp và cách xử lý
Trong quá trình chạy mô hình, không phải lúc nào dữ liệu cũng hội tụ hoàn hảo. Dưới đây là các vấn đề kỹ thuật thường gặp và giải pháp xử lý dựa trên kinh nghiệm thực tế:
- Hiện tượng biến tải đôi (Cross-loading): Đây là tình trạng một biến quan sát cùng lúc tải lên hai hoặc nhiều nhân tố với hệ số tải đều lớn hơn 0.5.
- Giải pháp: Tính hiệu số giữa hệ số tải lớn nhất và hệ số tải lớn thứ hai. Nếu hiệu số này < 0.3, biến đó cần bị loại bỏ vì nó không phân biệt được rõ ràng thuộc về nhân tố nào.
- Hệ số tải thấp: Các biến có Factor Loading < 0.5 chứng tỏ đóng góp của biến đó vào nhân tố là không đáng kể. Cần loại bỏ biến này để tăng độ giá trị cho thang đo.
- Tách nhóm sai kỳ vọng: Đôi khi các biến của khái niệm A lại nhảy sang nằm chung nhóm với khái niệm B. Điều này thường do bảng câu hỏi thiết kế không rõ ràng hoặc đối tượng khảo sát hiểu sai ý nghĩa câu hỏi. Cần xem xét lại nội dung câu hỏi hoặc chấp nhận cấu trúc mới nếu nó hợp lý về mặt logic thực tế.

Câu hỏi thường gặp (FAQ)
Khác biệt giữa EFA và CFA là gì?
EFA (Khám phá) được sử dụng khi nhà nghiên cứu chưa biết rõ cấu trúc dữ liệu hoặc muốn tìm kiếm cấu trúc mới từ dữ liệu thực tế. Ngược lại, CFA (Khẳng định) được dùng để kiểm định lại xem một cấu trúc lý thuyết đã có trước đó có phù hợp với dữ liệu thu thập được hay không. EFA là bước đi trước, CFA là bước kiểm định lại sau đó.
Khi nào dùng phép xoay Varimax và khi nào dùng Promax?
Sử dụng Varimax khi bạn muốn tách biệt rõ ràng các nhân tố và giả định chúng độc lập. Sử dụng Promax khi bạn tin rằng các nhân tố tâm lý/xã hội trong mô hình có sự tương tác, ảnh hưởng lẫn nhau. Trong nghiên cứu kinh tế, Varimax thường được ưu tiên hơn.
Tại sao chỉ số KMO lại thấp dưới 0.5?
KMO thấp cho thấy dữ liệu không phù hợp để phân tích nhân tố. Nguyên nhân có thể do cỡ mẫu quá nhỏ, hoặc các biến quan sát được thiết kế rời rạc, không cùng đo lường một khái niệm chung. Giải pháp là tăng kích thước mẫu hoặc kiểm tra lại bảng câu hỏi.
Phân tích nhân tố khám phá EFA là một bước không thể thiếu trong các nghiên cứu định lượng, giúp nhà nghiên cứu cô đọng dữ liệu và xây dựng các thang đo chuẩn xác. Việc nắm vững các chỉ số như KMO, Eigenvalue và Factor Loading sẽ giúp quá trình xử lý dữ liệu trở nên minh bạch và khoa học hơn. Một bộ dữ liệu được xử lý EFA tốt sẽ là nền tảng vững chắc cho các kiểm định mô hình phức tạp phía sau.
Để tìm hiểu sâu hơn về các phương pháp nghiên cứu khoa học và phát triển tư duy quản trị, bạn có thể tham khảo thêm các chia sẻ chuyên sâu từ nhà quản trị học Nguyễn Thanh Phương.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



