
Phân tích gộp (Meta-analysis) là phương pháp thống kê định lượng nhằm tổng hợp và phân tích dữ liệu từ nhiều nghiên cứu độc lập về cùng một chủ đề. Vấn đề cốt lõi trong nghiên cứu là sự mâu thuẫn kết quả giữa các bài báo riêng lẻ. Giải pháp chính xác nhất là tiến hành Phân tích gộp (Meta-analysis) để tính toán Kích cỡ hiệu ứng (Effect size) chung, từ đó cung cấp bằng chứng khoa học có mức độ tin cậy cao nhất.

1. Giới thiệu tổng quan về Phân tích gộp (Meta-analysis) trong nghiên cứu khoa học
Trong tháp bằng chứng khoa học, hệ thống dữ liệu được chắt lọc qua nhiều lớp. Tầm quan trọng của việc tổng hợp bằng chứng định lượng từ nhiều nghiên cứu độc lập giúp các nhà nghiên cứu loại bỏ những sai lệch nhỏ lẻ, cung cấp một bức tranh toàn cảnh và chính xác. Bài viết này tập trung vào quy trình sử dụng Phân tích gộp (Meta-analysis) để xử lý đầu ra của quá trình Tổng quan tài liệu hệ thống (SLR – Systematic Literature Review), biến đổi các số liệu phân tán thành một chỉ số kết luận duy nhất.

2. Định nghĩa và Khái niệm Cốt lõi về Phân tích gộp và Kích cỡ hiệu ứng
2.1. Phân tích gộp (Meta-analysis) là gì?
Theo tiêu chuẩn quốc tế Cochrane, Phân tích gộp (Meta-analysis) là kỹ thuật thống kê dùng để kết hợp kết quả từ hai hay nhiều nghiên cứu độc lập lại với nhau nhằm tạo ra một ước lượng gộp chung. Khác biệt bản chất giữa Tổng quan tài liệu hệ thống (SLR) và Phân tích gộp nằm ở tính chất dữ liệu:
- SLR: Đánh giá và tổng hợp thông tin mang tính định tính.
- Phân tích gộp: Xử lý và chạy mô hình trên dữ liệu định lượng.
2.2. Kích cỡ hiệu ứng (Effect size) là gì?
Kích cỡ hiệu ứng (Effect size) là một chỉ số thống kê đo lường độ lớn của mối quan hệ giữa hai biến số hoặc sự khác biệt giữa hai nhóm. Các loại Effect size phổ biến bao gồm: Cohen’s d, Tỷ số chênh (Odds Ratio – OR), và Nguy cơ tương đối (Relative Risk – RR). Vai trò của Effect size chung là đánh giá thực chất mức độ tác động của một biến độc lập, thay vì chỉ phụ thuộc vào ý nghĩa thống kê của giá trị p-value.
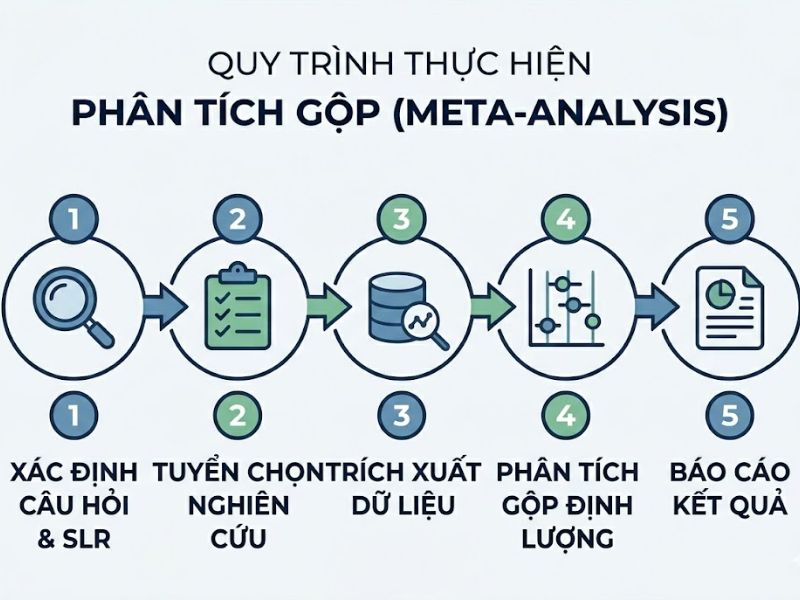
3. Phân tích chi tiết: Quy trình thực hiện Phân tích gộp (Meta-analysis) từ dữ liệu SLR
3.1. Trích xuất và chuẩn hóa dữ liệu từ hàng trăm bài báo
Quy trình lập bảng mã hóa (coding sheet) từ kết quả SLR đòi hỏi sự chính xác tuyệt đối. Các bước trích xuất bao gồm:
- Xác định biến số: Cỡ mẫu (N), Giá trị trung bình (Mean), Độ lệch chuẩn (SD), và Số sự kiện (Events).
- Lập bảng dữ liệu: Chuẩn hóa các đơn vị đo lường khác nhau về cùng một hệ quy chiếu để tính toán.
3.2. Đánh giá tính không đồng nhất (Heterogeneity) giữa các nghiên cứu
Khái niệm Heterogeneity thống kê đề cập đến sự biến thiên của kết quả giữa các nghiên cứu khác nhau. Để lượng hóa mức độ biến thiên dữ liệu, các nhà khoa học sử dụng:
- Chỉ số Q của Cochran: Đánh giá xem sự khác biệt có ý nghĩa thống kê hay không.
- Chỉ số I-squared (I²): Đo lường tỷ lệ phần trăm sự biến thiên là do sự khác biệt thực sự thay vì yếu tố ngẫu nhiên.
3.3. Lựa chọn mô hình phân tích: Fixed-effect model vs. Random-effects model
Việc lựa chọn mô hình phụ thuộc chặt chẽ vào chỉ số I².
| Tiêu chí | Mô hình Tác động cố định (Fixed-effect model) | Mô hình Tác động ngẫu nhiên (Random-effects model) |
| Giả định nền tảng | Tồn tại một Kích cỡ hiệu ứng thực duy nhất (True effect size) cho mọi nghiên cứu. | Có một phân phối các Kích cỡ hiệu ứng thực khác nhau giữa các nghiên cứu. |
| Tính không đồng nhất | I² thấp (Gần 0%). Các nghiên cứu có sự tương đồng cao. | I² cao (Thường > 50%). Các nghiên cứu có sự khác biệt về mẫu, phương pháp. |
| Trọng số (Weighting) | Phụ thuộc hoàn toàn vào phương sai nội bộ (Within-study variance). | Phụ thuộc vào phương sai nội bộ và phương sai giữa các nghiên cứu (Between-study variance). |
| Khoảng tin cậy (95% CI) | Hẹp hơn, độ chính xác cao đối với quần thể cụ thể. | Rộng hơn, bao quát được sự biến thiên của nhiều bối cảnh nghiên cứu. |
3.4. Chạy dữ liệu và tính toán Kích cỡ hiệu ứng (Effect size) chung
Bước tiếp theo là thuật toán gán trọng số (Weighting) dựa trên phương sai nghịch đảo (Inverse Variance), nghĩa là nghiên cứu nào có phương sai nhỏ (độ chính xác cao, mẫu lớn) sẽ được gán trọng số lớn hơn. Cuối cùng, hệ thống sẽ thiết lập khoảng tin cậy 95% (95% Confidence Interval) cho Effect size chung, xác định biên độ dao động của giá trị thực tế trong tổng thể.
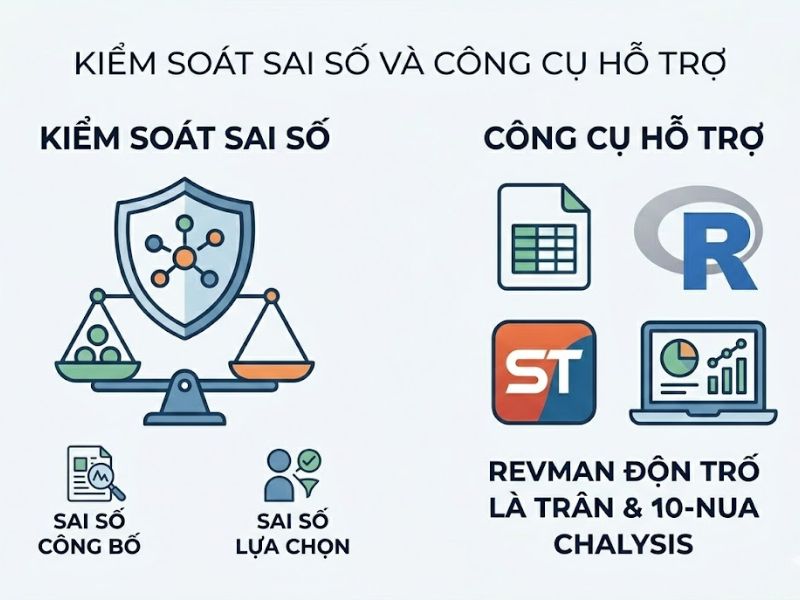
4. Các giải pháp kiểm soát sai số và công cụ hỗ trợ
4.1. Giải pháp phát hiện và kiểm soát Sai số xuất bản (Publication Bias)
Sai số xuất bản xảy ra khi các bài báo có kết quả tích cực dễ được công bố hơn. Để phát hiện vấn đề này:
- Biểu đồ hình phễu (Funnel plot): Sử dụng đồ thị phân tán để đánh giá tính đối xứng của dữ liệu gộp. Nếu biểu đồ mất đối xứng, có thể tồn tại bias.
- Phương pháp thống kê Egger’s test: Phân tích hồi quy tuyến tính để kiểm định độ lệch của biểu đồ phễu bằng định lượng.
4.2. Các phần mềm chuyên dụng hỗ trợ Phân tích gộp
Có nhiều công cụ thống kê mạnh mẽ hỗ trợ xử lý dữ liệu chuẩn xác:
- R (gói meta, metafor): Cung cấp mã nguồn mở linh hoạt, thích hợp cho các mô hình phức tạp.
- Stata: Phần mềm thương mại với các lệnh phân tích trực quan, chuyên nghiệp.
- RevMan (Review Manager): Công cụ chuẩn mực do tổ chức Cochrane phát triển, cực kỳ hữu ích cho lĩnh vực y sinh học.
5. Câu hỏi thường gặp (FAQ) về Phân tích gộp (Meta-analysis)
Điều kiện tiên quyết nào từ quá trình SLR để có thể thực hiện Phân tích gộp (Meta-analysis)?
Các nghiên cứu được chọn lọc từ SLR bắt buộc phải có tính đồng nhất nhất định về câu hỏi nghiên cứu (PICO), có thiết kế nghiên cứu tương đồng và phải báo cáo đủ các dữ liệu thống kê định lượng cần thiết (Mean, SD, N hoặc OR, RR) để có thể tính toán trọng số.
Làm thế nào để xử lý dữ liệu bị thiếu (missing data) trong quá trình tính toán Effect size chung?
Khi gặp dữ liệu bị thiếu, nhà nghiên cứu có thể liên hệ trực tiếp với tác giả bài báo gốc. Nếu không thể thu thập, cần áp dụng các phương pháp nội suy thống kê (imputation) hoặc sử dụng các công thức chuyển đổi chuẩn mực (ví dụ: chuyển từ p-value hoặc t-value sang độ lệch chuẩn) trước khi chạy mô hình.
Nếu I-squared (I²) quá lớn (>75%), có nên tiếp tục chạy mô hình gộp dữ liệu không?
Trả lời: Khi I² > 75%, tính không đồng nhất là rất nghiêm trọng. Không nên mù quáng gộp dữ liệu. Thay vào đó, phải sử dụng Mô hình tác động ngẫu nhiên (Random-effects model) và bắt buộc tiến hành Phân tích phân nhóm (Subgroup analysis) hoặc Hồi quy meta (Meta-regression) để tìm ra nguyên nhân gây ra sự biến thiên này.
6. Vai trò của Phân tích gộp (Meta-analysis)
Tóm lại, Phân tích gộp (Meta-analysis) đóng vai trò tối quan trọng trong việc nâng cao độ tin cậy của các kết luận khoa học. Thay vì dựa vào kết quả đơn lẻ mang tính cục bộ, phương pháp này tổng hợp sức mạnh dữ liệu của toàn bộ hệ thống tài liệu. Việc định lượng và xác định Kích cỡ hiệu ứng (Effect size) chung cung cấp nền tảng vững chắc nhất cho quy trình ra quyết định dựa trên bằng chứng (Evidence-based decision making), ứng dụng rộng rãi từ quản trị doanh nghiệp, kinh tế học đến y khoa.
Bài viết được biên soạn và tổng hợp dựa trên góc nhìn học thuật chuyên sâu. Mọi thắc mắc và nhu cầu tư vấn nghiên cứu khoa học định lượng, vui lòng tham khảo và liên hệ thầy giáo Nguyễn Thanh Phương để được hỗ trợ hệ thống hóa dữ liệu chuẩn mực nhất.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



