
Xử lý dữ liệu bị thiếu (Missing Data) là quy trình điều chỉnh các ô giá trị bị trống trong tập dữ liệu nghiên cứu định lượng. Nguyên nhân chính là do người tham gia bỏ qua câu hỏi hoặc hệ thống lưu trữ phát sinh lỗi. Giải pháp nhanh nhất là phân tích cơ chế MCAR/MAR/MNAR để chọn phương pháp toán học phù hợp nhằm làm sạch dữ liệu khảo sát.

1. Giới Thiệu Ngắn Gọn Về Vấn Đề Xử Lý Dữ Liệu Bị Thiếu (Missing Data)
1.1. Tầm quan trọng của tính toàn vẹn dữ liệu đối với độ tin cậy của mô hình định lượng.
Tính toàn vẹn dữ liệu là nền tảng cốt lõi của bất kỳ phân tích định lượng nào. Sự thiếu hụt dữ liệu làm giảm kích thước mẫu thực tế, dẫn đến sự suy giảm độ chính xác của các ước lượng thống kê. Quá trình Xử lý dữ liệu bị thiếu (Missing Data) một cách khoa học giúp duy trì cấu trúc phương sai và hiệp phương sai ban đầu, đảm bảo tính đại diện của mẫu nghiên cứu và nâng cao độ tin cậy của các kết luận rút ra từ mô hình phân tích.
1.2. Mục tiêu của bài tổng quan tài liệu: Thiết lập tiêu chuẩn ra quyết định khi người tham gia không điền hết bảng hỏi.
Bài viết này cung cấp khung lý luận học thuật nhằm thiết lập tiêu chuẩn ra quyết định trong quá trình phân tích dữ liệu. Mục tiêu cốt lõi là hướng dẫn nhà nghiên cứu lựa chọn kỹ thuật phù hợp giữa việc loại bỏ hay quy kết dữ liệu dựa trên đặc tính toán học của mẫu, thay vì xử lý cảm tính.

2. Khái Niệm Chính Và Các Cơ Chế Cốt Lõi Của Hiện Tượng Khuyết Dữ Liệu
2.1. Định nghĩa hàn lâm về hiện tượng khuyết dữ liệu trong thiết kế nghiên cứu.
Trong khoa học thống kê, khuyết dữ liệu xảy ra khi không có giá trị nào được ghi nhận cho một hoặc nhiều biến số quan sát đối với một đơn vị phân tích cụ thể. Sự thiếu hụt này tạo ra các lỗ hổng trong ma trận dữ liệu, làm sai lệch cấu trúc thông tin và cản trở việc thực thi các thuật toán tính toán tiêu chuẩn.
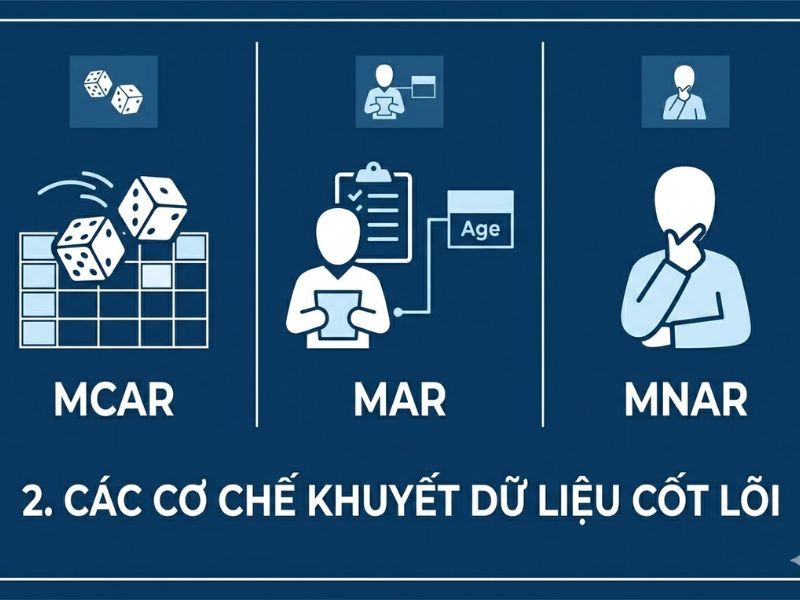
2.2. Phân loại cơ chế thiếu hụt (Missing Data Mechanisms)
Việc xác định cơ chế thiếu hụt là bước bắt buộc trước khi thực hiện Xử lý dữ liệu bị thiếu (Missing Data). Phân loại này được định nghĩa bởi nhà thống kê Donald Rubin.
2.2.1. Thiếu hoàn toàn ngẫu nhiên (MCAR – Missing Completely At Random).
MCAR xảy ra khi xác suất một điểm dữ liệu bị thiếu hoàn toàn độc lập với cả các biến quan sát được và các biến không quan sát được.
- Dấu hiệu: Sự vắng mặt của dữ liệu giống như việc tung đồng xu.
- Kiểm định: Nhà nghiên cứu thường sử dụng kiểm định Little (Little’s MCAR test) để xác nhận giả định này.
2.2.2. Thiếu ngẫu nhiên (MAR – Missing At Random).
MAR xuất hiện khi xác suất dữ liệu bị thiếu có liên quan đến các biến đã được thu thập đầy đủ trong tập dữ liệu, nhưng không phụ thuộc vào giá trị của chính biến bị thiếu đó.
- Ví dụ: Nam giới có xu hướng ít trả lời câu hỏi về thu nhập hơn nữ giới, nhưng trong nhóm nam giới, người thu nhập cao hay thấp đều có tỷ lệ bỏ trống câu hỏi như nhau.
2.2.3. Thiếu không ngẫu nhiên (MNAR – Missing Not At Random).
MNAR là cơ chế phức tạp nhất, xảy ra khi xác suất bị thiếu phụ thuộc trực tiếp vào giá trị của biến đang bị thiếu.
- Ví dụ: Những người có thu nhập rất cao chủ động không khai báo mức thu nhập thật của họ. Việc bỏ qua điều này sẽ gây ra sai số nghiêm trọng.
3. Phân Tích Chi Tiết Tác Động Thực Nghiệm Của Việc Không Xử Lý Dữ Liệu Bị Thiếu (Missing Data)
3.1. Hiện tượng sai lệch trong ước lượng tham số (Parameter Estimation Bias).
Nếu không áp dụng phương pháp xử lý chuẩn xác, dữ liệu thu được sẽ mang tính thiên lệch. Hiện tượng sai lệch ước lượng xảy ra khi mẫu phân tích cuối cùng không còn phản ánh đúng tổng thể ban đầu. Điều này làm cho hệ số hồi quy (Beta), giá trị trung bình (Mean) và độ lệch chuẩn (Standard Deviation) bị bóp méo, dẫn đến kết quả nghiên cứu bị sai lệch hoàn toàn so với thực tế.
3.2. Sự suy giảm độ mạnh thống kê (Statistical Power) do giảm kích thước mẫu.
Sức mạnh thống kê bị ảnh hưởng trực tiếp bởi kích thước mẫu. Khi bỏ qua các bản ghi chứa dữ liệu thiếu, số lượng quan sát (N) giảm xuống. N càng nhỏ, sai số chuẩn (Standard Error) càng lớn, làm giảm khả năng phát hiện ra các mối quan hệ thực sự giữa các biến, dẫn đến sai lầm loại II (Type II error) trong kiểm định giả thuyết.

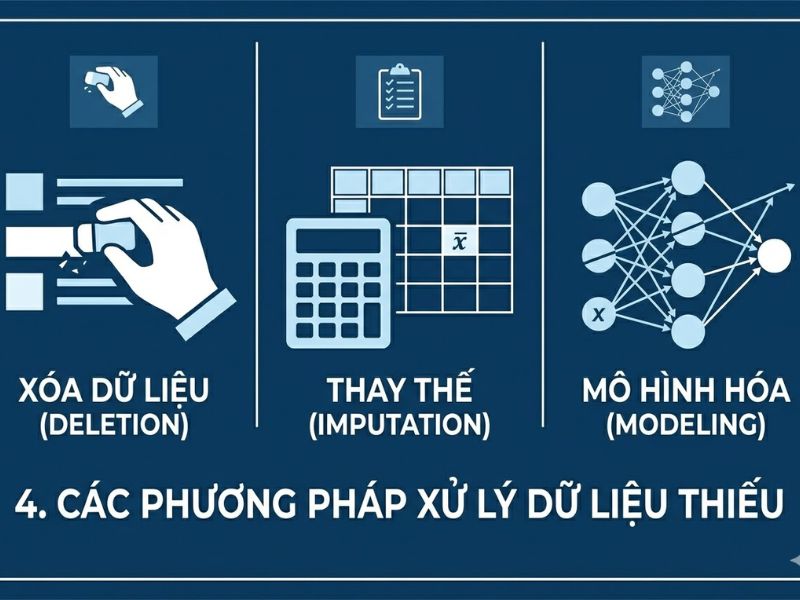
4. Các Phương Pháp Và Giải Pháp Xử Lý Khi Người Tham Gia Không Điền Hết Bảng Hỏi
4.1. Kỹ thuật loại bỏ dữ liệu (Deletion Methods)
4.1.1. Phương pháp xóa toàn bộ (Listwise Deletion / Complete Case Analysis)
- Cơ sở lý luận và giới hạn áp dụng: Phương pháp này loại bỏ hoàn toàn một đối tượng (case) ra khỏi phân tích nếu có bất kỳ biến nào bị trống. Điều kiện bắt buộc để áp dụng là dữ liệu phải thỏa mãn giả định MCAR.
- Ưu điểm: Duy trì tính đồng nhất của mẫu trên tất cả các phép phân tích; dễ thực hiện trên các phần mềm.
- Hạn chế: Gây mất mát thông tin nghiêm trọng, làm giảm mạnh sức mạnh thống kê nếu tỷ lệ trống vượt quá 5%.
4.1.2. Phương pháp xóa từng phần (Pairwise Deletion / Available Case Analysis)
- Nguyên lý bảo toàn tối đa: Thuật toán tính toán ma trận hiệp phương sai bằng cách sử dụng tất cả các dữ liệu có sẵn cho từng cặp biến cụ thể. Đối tượng chỉ bị loại trừ ở các cặp biến mà nó bị thiếu dữ liệu.
- Rủi ro: Gây ra hiện tượng ma trận không xác định dương (Non-positive definite matrices), khiến các mô hình phức tạp như cấu trúc tuyến tính (SEM) không thể chạy được hoặc cho ra các hệ số hồi quy vượt quá giới hạn lý thuyết.
4.2. Kỹ thuật quy kết/thay thế dữ liệu (Imputation Methods)
4.2.1. Thay thế bằng giá trị trung bình (Mean Imputation)
- Quy trình: Kỹ thuật thay thế bằng mean (Mean Imputation) nội suy các giá trị trống bằng giá trị trung bình cộng của toàn bộ các quan sát hợp lệ trong cùng một biến số.
- Điểm yếu học thuật: Phương pháp này làm triệt tiêu phương sai của biến, thu hẹp sai số chuẩn một cách giả tạo và làm méo mó nghiêm trọng hệ số tương quan giữa các biến. Hầu hết các tạp chí khoa học hiện nay không khuyến khích sử dụng cách này.
4.2.2. Tổng quan về các giải pháp thay thế bậc cao (Multiple Imputation, Expectation-Maximization) nhằm tối ưu hóa sai số.
- Expectation-Maximization (EM): Sử dụng thuật toán lặp để tìm ra ước lượng hợp lý cực đại cho các giá trị bị thiếu.
- Multiple Imputation (MI): Tạo ra nhiều bộ dữ liệu thay thế dựa trên phân phối xác suất, sau đó phân tích từng bộ và gộp kết quả lại. Phương pháp này bảo toàn cấu trúc sai số và được xem là tiêu chuẩn vàng trong phân tích định lượng hiện đại.
Bảng Tổng Hợp So Sánh Các Phương Pháp Xử Lý Dữ Liệu Bị Thiếu
| Phương pháp | Loại kỹ thuật | Ưu điểm cốt lõi | Nhược điểm lớn nhất | Điều kiện áp dụng tối ưu |
| Xóa listwise | Loại bỏ (Deletion) | Dễ thực hiện, tập dữ liệu đồng nhất. | Mất mát dữ liệu lớn, giảm sức mạnh thống kê. | Dữ liệu đạt chuẩn MCAR, tỷ lệ thiếu < 5%. |
| Xóa pairwise | Loại bỏ (Deletion) | Tận dụng tối đa dữ liệu hiện có. | Gây lỗi ma trận không xác định dương trong SEM. | Phân tích tương quan đơn giản, MCAR/MAR. |
| Thay thế bằng mean | Quy kết (Imputation) | Tránh giảm kích thước mẫu nhanh chóng. | Bóp méo phương sai, thay đổi độ lệch chuẩn. | Rất ít được khuyên dùng trong khoa học. |
| Multiple Imputation | Quy kết (Imputation) | Tối ưu hóa sai số, ước lượng khách quan. | Phức tạp trong tính toán, yêu cầu phần mềm hỗ trợ. | Dữ liệu thuộc cơ chế MAR, mô hình phức tạp. |
5. Khuyến Nghị Khoa Học Trong Đánh Giá Và Xử Lý Dữ Liệu Bị Thiếu (Missing Data)
5.1. Nguyên tắc lựa chọn phương pháp dựa trên tỷ lệ thiếu hụt và kiểm định phân phối.
Việc lựa chọn phương pháp không dựa trên sự tiện lợi mà phải căn cứ vào kết quả kiểm định Little và tỷ lệ dữ liệu khuyết. Nếu tỷ lệ thiếu dưới 5% và đạt MCAR, xóa listwise là giải pháp an toàn. Ngược lại, đối với tỷ lệ cao hơn hoặc dữ liệu rơi vào MAR, các kỹ thuật thay thế bậc cao như Multiple Imputation bắt buộc phải được áp dụng.
5.2. Yêu cầu minh bạch thông tin trong báo cáo phương pháp luận.
Trong các công bố học thuật, nhà nghiên cứu phải báo cáo minh bạch về tỷ lệ thiếu, cơ chế thiếu hụt đã được kiểm định và luận giải rõ ràng lý do chọn phương pháp xử lý đó nhằm đảm bảo tính tái lập của nghiên cứu.
6. FAQ – Câu Hỏi Thường Gặp Về Quản Trị Dữ Liệu Khuyết Khảo Sát
6.1. Tỷ lệ Missing Data tối đa cho phép để áp dụng Listwise Deletion mà không làm sai lệch mẫu là bao nhiêu?
Tỷ lệ an toàn được chấp nhận trong giới học thuật là dưới 5%, với điều kiện tiên quyết là dữ liệu phải vượt qua kiểm định MCAR. Vượt quá ngưỡng này, sức mạnh thống kê sẽ suy giảm đáng kể.
6.2. Kỹ thuật Mean Imputation có phá vỡ giả định phân phối chuẩn của dữ liệu hay không?
Có, phương pháp này phá vỡ phân phối chuẩn. Việc nhồi nhét cùng một giá trị trung bình vào dữ liệu sẽ tạo ra một đỉnh nhọn bất thường ở giữa phân phối, làm giảm độ lệch chuẩn giả tạo và ảnh hưởng đến tính hợp lệ của các kiểm định tham số.
6.3. Giải pháp nào được ưu tiên khi dữ liệu vi phạm giả định MCAR?
Multiple Imputation (MI) và Maximum Likelihood (ML) là hai giải pháp tối ưu. Khi dữ liệu vi phạm MCAR (tức là rơi vào MAR hoặc MNAR), các kỹ thuật này sử dụng mô hình xác suất để quy kết giá trị, giúp kiểm soát phương sai tốt hơn các phương pháp xóa truyền thống.
Kết luận tổng quan: Quy trình Xử lý dữ liệu bị thiếu (Missing Data) là một bước sàng lọc kỹ thuật mang tính quyết định đến sinh mệnh của một mô hình nghiên cứu. Từ việc nhận diện cơ chế MCAR/MAR/MNAR cho đến việc lựa chọn xóa listwise, xóa pairwise hay quy kết bậc cao, nhà nghiên cứu cần bám sát các nguyên lý toán học chặt chẽ. Bài viết được hệ thống hóa và biên tập bởi nhà nghiên cứu Nguyễn Thanh Phương, nhằm cung cấp nền tảng kiến thức thực chứng, hỗ trợ trực tiếp cho quá trình đánh giá và phân tích dữ liệu nghiên cứu khoa học.



