
Sự nhầm lẫn giữa Độ lệch chuẩn và Sai số chuẩn là một lỗi phương pháp luận rất phổ biến trong phân tích dữ liệu. Nguyên nhân chính là do hai khái niệm này có sự tương đồng lớn về tên gọi, ký hiệu và mối liên hệ toán học chặt chẽ. Giải pháp nhanh nhất để khắc phục là ghi nhớ nguyên tắc cốt lõi: Độ lệch chuẩn (SD) dùng để mô tả mức độ phân tán của một mẫu dữ liệu cụ thể, trong khi Sai số chuẩn (SE) dùng để đánh giá độ chính xác của giá trị trung bình mẫu khi ước lượng cho toàn bộ quần thể. Việc chọn sai chỉ số sẽ dẫn đến những diễn giải sai lệch về độ tin cậy của kết quả nghiên cứu.

1. Giới thiệu tổng quan về các đại lượng phân tán trong thống kê
Trong nghiên cứu khoa học, đặc biệt là thống kê định lượng, việc chỉ sử dụng các đại lượng đo lường xu hướng tập trung như giá trị trung bình (mean), trung vị (median) hay yếu vị (mode) là hoàn toàn không đủ để phản ánh toàn diện bản chất của một bộ dữ liệu. Các nhà nghiên cứu bắt buộc phải kết hợp với các đại lượng phân tán để đánh giá mức độ biến thiên, sự đồng đều hay tính đa dạng của các giá trị quan sát.
Hai đại lượng đo lường sự phân tán đóng vai trò nền tảng và được ứng dụng rộng rãi nhất chính là Độ lệch chuẩn và Sai số chuẩn. Nếu như phương sai (variance) thường khó diễn giải trực quan do đơn vị đo lường bị bình phương, thì cả SD và SE đều đưa dữ liệu về lại cùng đơn vị đo lường gốc của biến số, giúp nhà phân tích dễ dàng biểu diễn trên các biểu đồ, bảng biểu và diễn giải ý nghĩa thực tiễn. Tuy nhiên, bản chất thống kê của chúng thuộc về hai trường phái hoàn toàn khác biệt: một bên thuộc về thống kê mô tả, bên còn lại thuộc về thống kê suy diễn. Việc hiểu đúng nội hàm của từng đại lượng là yêu cầu bắt buộc để đảm bảo tính toàn vẹn (integrity) của dữ liệu công bố.
2. Độ lệch chuẩn (Standard Deviation – SD) là gì?
2.1. Khái niệm và ý nghĩa trong thống kê mô tả (Descriptive Statistics)
Độ lệch chuẩn (Standard Deviation – thường được ký hiệu là SD hoặc σ đối với quần thể, và s đối với mẫu) là một đại lượng thống kê mô tả cơ bản. Khái niệm này được dùng để đo lường mức độ phân tán, hay khoảng cách trung bình của các điểm dữ liệu cụ thể so với giá trị trung bình (mean) của chính tập dữ liệu đó.
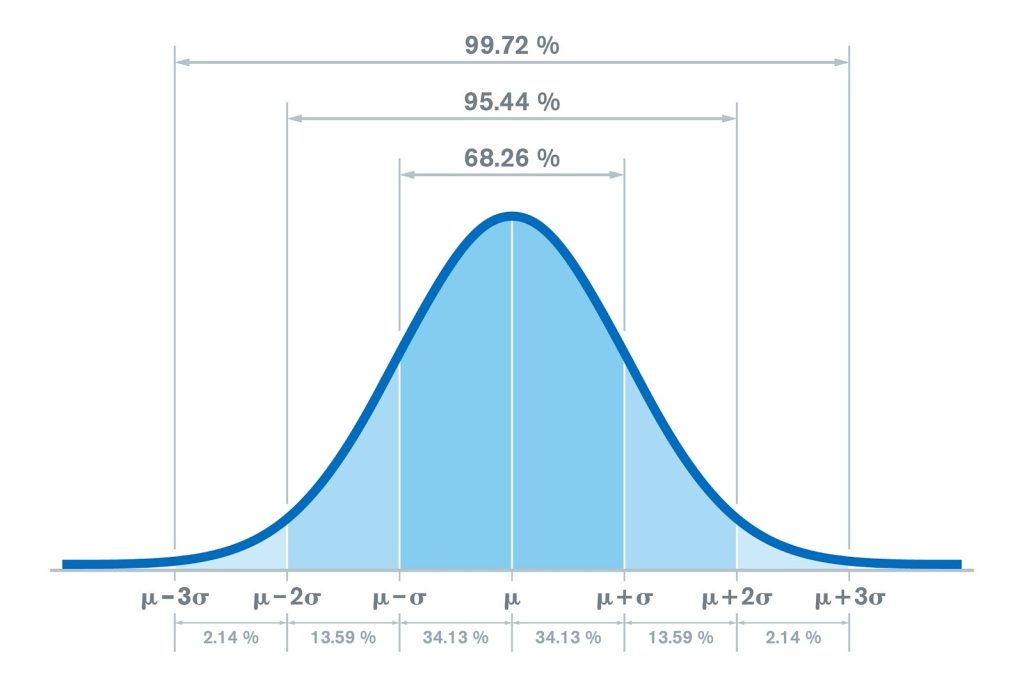
Ý nghĩa của Độ lệch chuẩn được thể hiện rõ nhất qua phân phối chuẩn (Normal Distribution) với quy tắc thực nghiệm 68-95-99.7:
- Khoảng 68.2% các giá trị quan sát sẽ rơi vào khoảng ±1 SD tính từ giá trị trung bình.
- Khoảng 95.4% các giá trị quan sát sẽ rơi vào khoảng ±2 SD.
- Khoảng 99.7% các giá trị quan sát sẽ rơi vào khoảng ±3 SD.
Phân tích độ lớn của SD:
- SD thấp (nhỏ): Chỉ ra rằng các điểm dữ liệu có xu hướng quần tụ rất sát với giá trị trung bình. Dữ liệu có tính đồng nhất cao, ít sự khác biệt giữa các đối tượng trong mẫu.
- SD cao (lớn): Chỉ ra rằng các điểm dữ liệu trải rộng trên một biên độ giá trị lớn. Điều này phản ánh sự biến thiên tự nhiên mạnh mẽ và tính đa dạng cao của các đối tượng được quan sát.
Trong thống kê mô tả, báo cáo giá trị trung bình kèm theo SD cung cấp cho người đọc một bức tranh toàn cảnh, chân thực về sự đa dạng của đối tượng nghiên cứu thay vì chỉ nhìn vào một con số đại diện duy nhất.
2.2. Công thức tính toán Độ lệch chuẩn
Độ lệch chuẩn về mặt toán học chính là căn bậc hai của phương sai. Để tính toán chính xác, công thức sẽ có sự khác biệt rõ rệt tùy thuộc vào việc dữ liệu đang phân tích đại diện cho toàn bộ quần thể (population) hay chỉ là một mẫu (sample) được rút ra từ quần thể đó. Khi trình bày trong các phần mềm soạn thảo như Google Docs hay Word, các ký hiệu dưới đây hoàn toàn tương thích và không bị lỗi định dạng:
- Công thức SD của quần thể (σ):
σ = √[ Σ(xi – μ)² / N ]
(Trong đó: xi là từng giá trị quan sát thực tế; μ là giá trị trung bình của toàn quần thể; N là tổng số lượng phần tử của quần thể; Σ là tổng của các giá trị). - Công thức SD của mẫu (s):
s = √[ Σ(xi – x̄)² / (n – 1) ]
(Trong đó: xi là từng giá trị quan sát; x̄ là giá trị trung bình của mẫu; n là cỡ mẫu thực tế; n – 1 được gọi là hiệu chỉnh Bessel – Bessel’s correction).
Lý do sử dụng (n – 1) thay vì n trong mẫu: Hiệu chỉnh Bessel được áp dụng để triệt tiêu sự thiên lệch (bias) khi chúng ta dùng một mẫu nhỏ để ước lượng sự phân tán của một quần thể lớn. Nếu chỉ chia cho n, độ lệch chuẩn của mẫu sẽ luôn có xu hướng nhỏ hơn độ lệch chuẩn thực sự của quần thể.
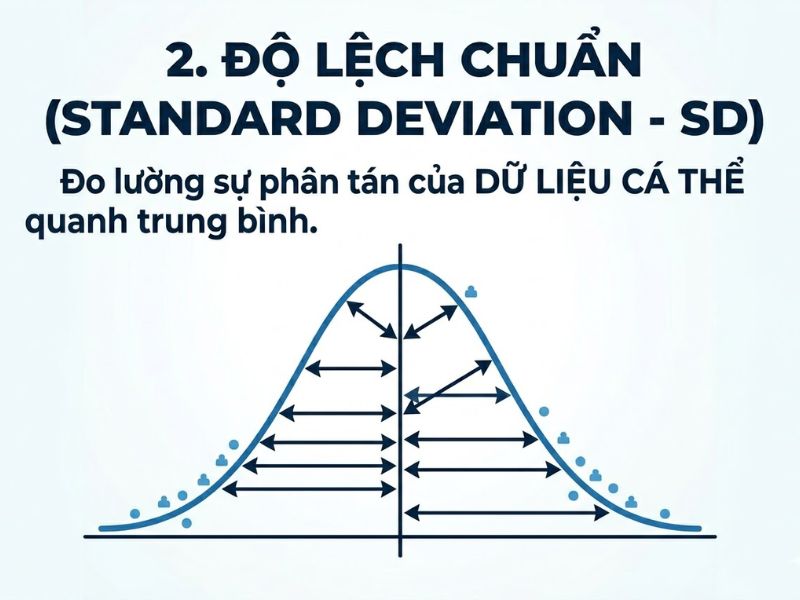
3. Sai số chuẩn (Standard Error – SE) là gì?
3.1. Khái niệm và ý nghĩa trong thống kê suy diễn (Inferential Statistics)
Sai số chuẩn (Standard Error – ký hiệu là SE, hoặc cụ thể hơn là SEM – Standard Error of the Mean) là một đại lượng trọng yếu thuộc về thống kê suy diễn. Khác với SD đo lường sự phân tán của các cá thể, SE đo lường mức độ biến thiên của chính các giá trị trung bình mẫu (sample means) nếu nhà nghiên cứu tiến hành lặp đi lặp lại việc rút ra vô số các mẫu ngẫu nhiên khác nhau từ cùng một quần thể gốc.
Nói một cách chính xác, SE là thước đo định lượng cho độ tin cậy và mức độ chính xác của mẫu nghiên cứu. Nó trả lời cho câu hỏi: “Giá trị trung bình của mẫu mà chúng ta đang cầm trên tay (x̄) ước lượng chính xác đến mức nào so với giá trị trung bình thực sự của toàn bộ quần thể khổng lồ ngoài kia (μ)?”.
- SE nhỏ: Cho thấy nếu bạn lấy nhiều mẫu khác nhau, trung bình của các mẫu này sẽ rất gần nhau và rất gần với trung bình thực của quần thể. Khả năng đại diện của mẫu là rất cao.
- SE lớn: Cho thấy việc lấy mẫu mang tính rủi ro cao, trung bình mẫu có thể chênh lệch rất xa so với thực tế quần thể.
3.2. Mối liên hệ toán học: Công thức tính Sai số chuẩn (SE = SD / √n)
Sai số chuẩn không được tính trực tiếp từ từng điểm dữ liệu thô ban đầu, mà được tính toán dựa trên Độ lệch chuẩn (SD) và quy mô của cỡ mẫu (n). Công thức tiêu chuẩn được quy định như sau:
SE = SD / √n
(Hoặc có thể viết là: SE = s / √n đối với dữ liệu mẫu).
Từ nền tảng công thức này, định lý giới hạn trung tâm (Central Limit Theorem) và quy luật số lớn (Law of Large Numbers) đã chỉ ra hai hệ quả toán học cực kỳ quan trọng:
- Giá trị của SE luôn luôn nhỏ hơn hoặc bằng giá trị SD của cùng một tập dữ liệu (vì mẫu số √n luôn ≥ 1).
- Khi quy mô cỡ mẫu (n) càng tăng lên, giá trị mẫu số (√n) càng lớn, kéo theo giá trị SE sẽ càng giảm xuống một cách đáng kể. Điều này minh chứng cho nguyên lý cơ bản trong nghiên cứu: Cỡ mẫu càng lớn, sai số ước lượng càng nhỏ, độ chính xác của suy diễn thống kê càng cao.

4. Bảng phân biệt rõ ràng Standard Deviation (SD) và Standard Error (SE)
Việc so sánh trực diện dựa trên các biến số cốt lõi sẽ giúp thiết lập ranh giới rõ ràng giữa Độ lệch chuẩn và Sai số chuẩn. Dưới đây là bảng tổng hợp các đặc tính kỹ thuật:
| Tiêu chí phân tích | Độ lệch chuẩn (Standard Deviation – SD / s) | Sai số chuẩn (Standard Error – SE / SEM) |
| Bản chất đo lường | Đo lường mức độ phân tán của các giá trị quan sát cá biệt xung quanh trung bình của một mẫu duy nhất. | Đo lường mức độ biến thiên của nhiều giá trị trung bình mẫu xung quanh trung bình thực của quần thể. |
| Phân loại thống kê | Thuộc nhóm Thống kê mô tả (Descriptive Statistics). | Thuộc nhóm Thống kê suy diễn (Inferential Statistics). |
| Sự phụ thuộc vào cỡ mẫu (n) | Khi n tăng lên, SD không thay đổi theo một hướng cố định (chỉ hội tụ chính xác hơn về giá trị σ của quần thể). | Khi n tăng lên, SE chắc chắn sẽ giảm xuống (tỷ lệ nghịch với căn bậc hai của cỡ mẫu). |
| Giới hạn toán học | Luôn lớn hơn hoặc bằng SE (SD ≥ SE). | Luôn nhỏ hơn hoặc bằng SD (SE ≤ SD). |
| Mục đích ứng dụng chính | Báo cáo đặc điểm nền (baseline characteristics), tính đa dạng tự nhiên của bộ dữ liệu nghiên cứu. | Tính toán khoảng tin cậy (CI), thực hiện kiểm định giả thuyết (t-test, ANOVA) và xác định giá trị P-value. |
5. Nguyên tắc thực hành: Khi nào trình bày SD, khi nào dùng SE trong bảng kết quả?
Trong việc công bố các bài báo khoa học chuẩn bình duyệt (peer-reviewed), việc lựa chọn hiển thị Độ lệch chuẩn và Sai số chuẩn trên bảng dữ liệu hoặc biểu đồ không phụ thuộc vào sở thích cá nhân, mà phải tuân thủ nghiêm ngặt mục tiêu của từng giai đoạn phân tích.
5.1. Các trường hợp bắt buộc sử dụng Độ lệch chuẩn (SD)
Nhà nghiên cứu bắt buộc sử dụng SD khi mục tiêu cốt lõi là trình bày sự biến thiên thực tế, đặc tính tự nhiên của tập dữ liệu mẫu đang có trong tay. Các ứng dụng cụ thể bao gồm:
- Bảng đặc điểm cơ sở của mẫu (Baseline Characteristics Table): Đây thường là Bảng 1 trong các bài báo khoa học. Khi bạn cần trình bày độ tuổi, chiều cao, huyết áp, hoặc thu nhập trung bình của nhóm đối tượng tham gia nghiên cứu. Định dạng tiêu chuẩn luôn là: Mean ± SD.
- Minh họa tính đại diện của dữ liệu: Khi muốn cho người đọc thấy khoảng giá trị mà phần lớn các quan sát trong mẫu rơi vào (áp dụng quy tắc 68-95-99.7). Nếu SD lớn bất thường so với Mean, điều đó cảnh báo dữ liệu có thể bị lệch (skewed) và cần xem xét dùng trung vị (Median) và khoảng tứ phân vị (IQR) để thay thế.
5.2. Các trường hợp tiêu chuẩn sử dụng Sai số chuẩn (SE)
Nhà nghiên cứu phải chuyển sang sử dụng SE khi bước vào giai đoạn đánh giá độ chính xác của ước lượng, so sánh các nhóm với nhau hoặc ngoại suy kết quả từ mẫu ra toàn bộ quần thể. Các tình huống cụ thể bao gồm:
- Tính toán Khoảng tin cậy (Confidence Interval – CI): Trong phân tích suy diễn, giá trị trung bình hiếm khi đứng độc lập mà đi kèm khoảng tin cậy. Ví dụ, khoảng tin cậy 95% (95% CI) được tính theo công thức: Giới hạn = Mean ± (1.96 × SE).
- So sánh giá trị trung bình giữa các nhóm can thiệp: Khi sử dụng kiểm định t-test hoặc ANOVA để so sánh hiệu quả giữa nhóm chứng và nhóm thử nghiệm, mức độ chênh lệch giữa các trung bình mẫu được chuẩn hóa bằng SE để tính toán ra giá trị t-statistic và P-value.
- Biểu diễn Thanh sai số (Error bars) cho ước lượng: Khi vẽ biểu đồ cột (bar chart) hoặc biểu đồ đường (line graph) so sánh các nhóm, thanh sai số biểu diễn SE giúp người đọc đánh giá bằng mắt thường mức độ không chắc chắn của ước lượng. Nếu các thanh sai số (của ±2 SE) giữa hai nhóm không giao nhau (overlap), có khả năng cao sự khác biệt đó mang ý nghĩa thống kê.
6. Kết luận
Trong bối cảnh phân tích dữ liệu định lượng, việc hiểu sâu sắc bản chất và phân định rạch ròi Độ lệch chuẩn và Sai số chuẩn không chỉ là một quy tắc toán học, mà là tiêu chuẩn bắt buộc để đảm bảo tính minh bạch, sự khắt khe và độ tin cậy của các phát hiện khoa học. Độ lệch chuẩn (SD) làm nhiệm vụ phản ánh trung thực sự phân tán đa dạng của dữ liệu cấu thành nên mẫu, trong khi Sai số chuẩn (SE) đóng vai trò là lăng kính hội tụ, cung cấp thước đo định lượng về độ chính xác khi ngoại suy kết quả lên cấp độ quần thể. Việc tuân thủ tuyệt đối nguyên tắc “SD dùng cho mục tiêu mô tả, SE dùng cho mục tiêu suy diễn” sẽ giúp các nhà phân tích loại bỏ hoàn toàn các sai sót phương pháp luận sơ đẳng, từ đó thiết lập một nền tảng vững chắc và nâng tầm chất lượng tổng thể của quá trình nghiên cứu khoa học.
7. Câu hỏi thường gặp (FAQ)
Thanh sai số (Error bars) trên biểu đồ khoa học nên biểu diễn SD hay SE?
Việc thanh sai số biểu diễn đại lượng nào hoàn toàn phụ thuộc vào thông điệp bạn muốn truyền tải. Bạn sử dụng thanh sai số biểu diễn SD khi muốn hiển thị cho người xem thấy sự phân tán của dữ liệu trong mẫu thực tế (phù hợp cho biểu đồ mô tả). Ngược lại, bạn sử dụng thanh sai số biểu diễn SE (hoặc Khoảng tin cậy 95% CI) khi mục đích là so sánh giá trị trung bình giữa các nhóm khác nhau để trực quan hóa sự khác biệt có ý nghĩa thống kê hay không. Yêu cầu bắt buộc là luôn phải ghi chú thích rõ ràng (ví dụ: “Error bars đại diện cho ±1 SE” hoặc “Error bars đại diện cho ±1 SD”) ngay dưới chân biểu đồ.
Có thể tính toán ngược từ SE ra SD nếu bài báo không cung cấp không?
Hoàn toàn có thể. Nhờ vào mối liên hệ toán học cố định, nếu một báo cáo khoa học hoặc một phân tích tổng hợp (Meta-analysis) chỉ cung cấp giá trị Sai số chuẩn (SE) và thông tin về cỡ mẫu (n), bạn có thể dễ dàng phục hồi lại giá trị Độ lệch chuẩn (SD) ban đầu bằng công thức biến đổi nghịch đảo: SD = SE × √n.
Tại sao một số nhà nghiên cứu lại cố tình báo cáo SE thay vì SD trong bảng đặc điểm mẫu?
Đây thường được xem là một thủ thuật trình bày gây nhầm lẫn (misleading). Dựa trên công thức SE = SD / √n, do phải chia cho căn bậc hai của cỡ mẫu, giá trị SE luôn luôn nhỏ hơn SD rất nhiều (đặc biệt khi n lớn). Việc trình bày bằng SE sẽ làm cho các thanh sai số trông hẹp hơn và con số biên độ nhỏ hơn, tạo ra “ảo giác” đối với người đọc rằng tập dữ liệu có độ chính xác và tính đồng nhất rất cao. Tuy nhiên, việc sử dụng SE để mô tả đặc điểm phân tán cơ sở của mẫu là sai hoàn toàn về mặt nguyên lý thống kê mô tả.
Trong các báo cáo kiểm định mô hình (như PLS-SEM hay CB-SEM), ký hiệu SD và SE có ý nghĩa tương tự không?
Các chỉ số đo lường độ phù hợp mô hình như R², GoF, Q² hay các tiêu chuẩn đánh giá như SRMR ≤ 0.08 và GFI ≥ 0.90 thuộc về hệ thống đánh giá cấu trúc tổng thể. Tuy nhiên, khi phần mềm xuất ra bảng kết quả đường dẫn (Path Coefficients), cột SD hoặc SE đi kèm với các hệ số Beta (β) chính là Sai số chuẩn (Standard Error) của hệ số đường dẫn đó, được dùng để tính toán t-value (t = β / SE) nhằm đưa ra kết luận về mức độ ý nghĩa thống kê (P-value). Mọi ký hiệu toán học cần được trích xuất bằng chuẩn Unicode để đảm bảo giữ nguyên định dạng chính xác khi biên soạn trên các nền tảng văn bản trực tuyến.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



