
Các thuật toán Machine Learning là hệ thống các quy trình tính toán và phương pháp thống kê cho phép máy tính tối ưu hóa hiệu suất thực hiện tác vụ thông qua dữ liệu lịch sử. Thay vì được lập trình bằng các quy tắc cố định, các hệ thống này xây dựng mô hình dựa trên dữ liệu mẫu để đưa ra dự đoán hoặc quyết định. Bài viết dưới đây phân tích chi tiết cơ chế, phân loại và ứng dụng thực tế của chúng.
1. Cơ Chế Hoạt Động Của Thuật Toán Machine Learning
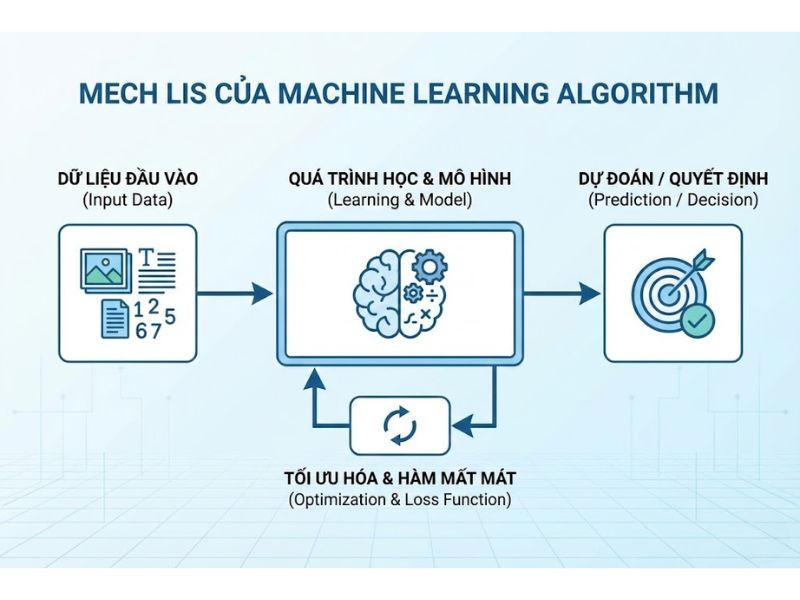
Trong khoa học máy tính, các thuật toán Machine Learning vận hành dựa trên việc tìm kiếm các quy luật toán học hoặc thống kê từ dữ liệu. Khác với lập trình truyền thống (nơi lập trình viên xác định rõ mối quan hệ Input-Output), Machine Learning tập trung vào việc ước lượng hàm số mô tả mối quan hệ giữa dữ liệu đầu vào và kết quả đầu ra.
Quy trình kỹ thuật bao gồm ba thành phần chính:
- Dữ liệu đầu vào (Input Data): Tập hợp các biến số hoặc đặc trưng (features) dùng để huấn luyện.
- Huấn luyện mô hình (Model Training): Quá trình thuật toán tối ưu hóa các tham số nội tại để giảm thiểu sai số dự đoán trên tập dữ liệu huấn luyện.
- Kết quả đầu ra (Output): Các giá trị dự báo hoặc nhãn phân loại được mô hình đưa ra khi tiếp nhận dữ liệu mới.
Việc hiểu sai bản chất thống kê này thường dẫn đến các lỗi kỹ thuật như Overfitting (Quá khớp – mô hình ghi nhớ cả nhiễu của dữ liệu huấn luyện) hoặc Underfitting (Không khớp – mô hình quá đơn giản để biểu diễn cấu trúc dữ liệu).
2. Phân Loại Các Thuật Toán Machine Learning
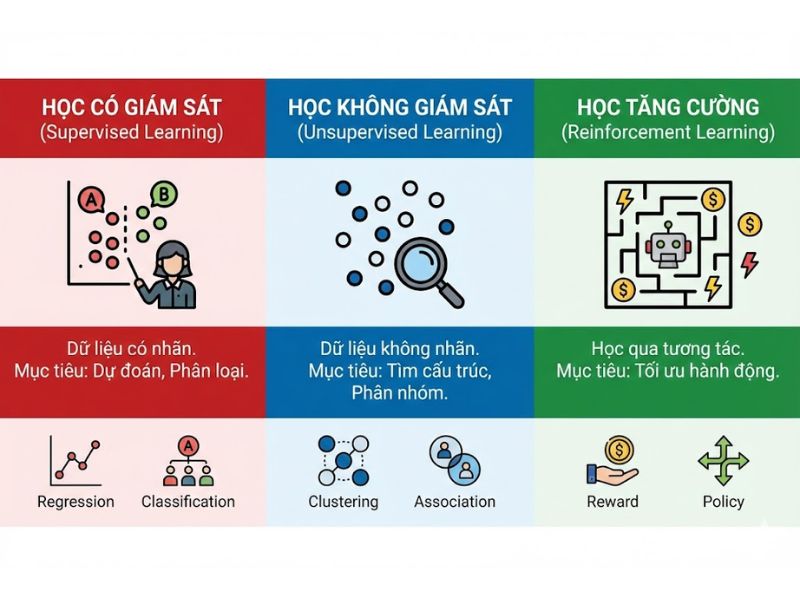
Dựa trên phương thức học và sự hiện diện của nhãn dữ liệu, các thuật toán Machine Learning được chia thành ba nhóm kỹ thuật chính.
2.1. Học Có Giám Sát (Supervised Learning)
Phương pháp này sử dụng tập dữ liệu đã được gán nhãn (labeled data). Thuật toán sẽ học cách ánh xạ từ biến đầu vào (x) sang biến đầu ra (y).
Các thuật toán tiêu biểu:
- Hồi quy tuyến tính (Linear Regression): Mô hình hóa mối quan hệ giữa biến phụ thuộc và biến độc lập dưới dạng đường thẳng. Ứng dụng để dự báo các giá trị liên tục (ví dụ: doanh thu, nhiệt độ).
- Hồi quy Logistic (Logistic Regression): Sử dụng hàm Sigmoid để ước lượng xác suất của một sự kiện. Ứng dụng trong bài toán phân loại nhị phân (ví dụ: Có/Không, Đạt/Không đạt).
- Cây quyết định (Decision Tree): Mô hình phân cấp dạng cây, chia nhỏ dữ liệu dựa trên các quy tắc điều kiện.
- Support Vector Machine (SVM): Tìm kiếm siêu phẳng tối ưu trong không gian nhiều chiều để phân tách các lớp dữ liệu.
2.2. Học Không Giám Sát (Unsupervised Learning)
Phương pháp này làm việc với dữ liệu chưa gán nhãn. Mục tiêu của các thuật toán Machine Learning trong nhóm này là phát hiện cấu trúc, quy luật phân bố hoặc mối liên kết ẩn trong dữ liệu.
Các thuật toán tiêu biểu:
- K-Means Clustering: Phân chia tập dữ liệu thành K nhóm dựa trên khoảng cách Euclide hoặc các độ đo tương tự, sao cho các điểm dữ liệu trong cùng một nhóm có tính chất tương đồng cao nhất.
- Principal Component Analysis (PCA): Kỹ thuật giảm số chiều của dữ liệu bằng cách biến đổi sang hệ tọa độ mới, giữ lại các thành phần chứa phương sai lớn nhất (thông tin quan trọng nhất).
- Association Rules (Luật kết hợp): Phát hiện mối quan hệ xác suất giữa các biến trong cơ sở dữ liệu lớn (ví dụ: Thuật toán Apriori).
2.3. Học Bán Giám Sát và Học Tăng Cường
- Học bán giám sát (Semi-supervised Learning): Sử dụng kết hợp lượng nhỏ dữ liệu có nhãn và lượng lớn dữ liệu không nhãn để cải thiện độ chính xác của mô hình.
- Học tăng cường (Reinforcement Learning): Thuật toán học thông qua cơ chế phản hồi từ môi trường. Hệ thống thực hiện hành động và nhận tín hiệu thưởng hoặc phạt, từ đó điều chỉnh chiến lược để tối đa hóa phần thưởng tích lũy.
3. Bảng So Sánh Thông Số Kỹ Thuật
Bảng dưới đây tổng hợp sự khác biệt về đặc tính kỹ thuật giữa hai nhóm thuật toán phổ biến nhất để hỗ trợ việc ra quyết định lựa chọn mô hình.
| Tiêu Chí Kỹ Thuật | Học Có Giám Sát (Supervised) | Học Không Giám Sát (Unsupervised) |
| Dữ liệu đầu vào | Dữ liệu có nhãn (Input + Output mong muốn) | Dữ liệu không nhãn (Chỉ có Input) |
| Mục tiêu tính toán | Giảm thiểu sai số giữa dự đoán và thực tế | Tối đa hóa sự tương đồng nội nhóm hoặc tách biệt ngoại nhóm |
| Độ phức tạp tính toán | Tăng tuyến tính theo số lượng tham số | Thường yêu cầu tài nguyên tính toán lớn để hội tụ |
| Đánh giá hiệu suất | Dùng các chỉ số chính xác (Accuracy, MSE, F1-Score) | Khó đánh giá định lượng, thường dùng chỉ số Silhouette hoặc Davies-Bouldin |
| Ứng dụng | Dự báo, Phân loại | Phân cụm, Giảm chiều dữ liệu, Phát hiện bất thường |
4. Quy Trình Lựa Chọn Thuật Toán
Theo định lý “No Free Lunch” trong khoa học dữ liệu, không tồn tại một thuật toán tối ưu cho mọi bài toán. Việc lựa chọn các thuật toán Machine Learning cần tuân theo quy trình phân tích sau:
- Xác định loại bài toán:
- Dự báo giá trị số: Sử dụng các thuật toán Hồi quy (Regression).
- Phân loại đối tượng vào các nhóm định sẵn: Sử dụng Phân loại (Classification).
- Gom nhóm dữ liệu chưa biết trước: Sử dụng Phân cụm (Clustering).
- Phân tích đặc tính dữ liệu:
- Kích thước dữ liệu: Các thuật toán như Deep Learning yêu cầu lượng dữ liệu lớn, trong khi Naive Bayes hoạt động hiệu quả với dữ liệu nhỏ.
- Tính tuyến tính: Kiểm tra xem dữ liệu có phân bố tuyến tính hay phi tuyến tính để chọn Kernel phù hợp (đối với SVM) hoặc độ sâu của cây (đối với Decision Tree).
- Yêu cầu về tài nguyên và tốc độ: Cân nhắc giữa độ chính xác và thời gian huấn luyện/thời gian suy diễn (inference time).

5. Các Câu Hỏi Thường Gặp (FAQ)
Sự khác biệt về mặt cấu trúc giữa Deep Learning và Machine Learning là gì?
Deep Learning là tập con của Machine Learning, sử dụng mạng nơ-ron nhân tạo nhiều lớp (Multi-layer Neural Networks) để tự động trích xuất đặc trưng từ dữ liệu, trong khi Machine Learning truyền thống thường yêu cầu trích xuất đặc trưng thủ công.
Thuật toán nào phù hợp nhất cho bài toán có dữ liệu đầu vào dạng văn bản?
Naive Bayes và Support Vector Machine (SVM) thường đạt hiệu suất cao trong các tác vụ phân loại văn bản nhờ khả năng xử lý tốt không gian dữ liệu nhiều chiều và thưa.
Làm thế nào để xử lý hiện tượng Overfitting trong các thuật toán Machine Learning?
Có thể áp dụng các kỹ thuật: tăng kích thước tập dữ liệu huấn luyện, sử dụng Regularization (L1, L2), giảm bớt số lượng đặc trưng đầu vào (Feature Selection) hoặc sử dụng phương pháp Cross-validation.
Tiền xử lý dữ liệu có vai trò gì đối với kết quả của thuật toán?
Tiền xử lý dữ liệu (làm sạch, chuẩn hóa, mã hóa) giúp loại bỏ nhiễu và đưa dữ liệu về định dạng chuẩn, đảm bảo thuật toán hội tụ nhanh hơn và đạt độ chính xác cao hơn.
Việc nắm vững cơ sở lý thuyết và đặc điểm kỹ thuật của các thuật toán Machine Learning là yêu cầu bắt buộc trong quy trình khai phá dữ liệu và xây dựng hệ thống trí tuệ nhân tạo. Sự lựa chọn chính xác thuật toán dựa trên đặc thù dữ liệu sẽ quyết định trực tiếp đến hiệu suất và tính khả thi của dự án công nghệ.
Để tham khảo thêm các nghiên cứu chuyên sâu về khoa học dữ liệu và phương pháp luận nghiên cứu, bạn có thể truy cập tài liệu từ giảng viên Nguyễn Thanh Phương.



