
Việc thiết lập tiếng Việt trong SPSS là một thao tác kỹ thuật bắt buộc để đảm bảo tính toàn vẹn của dữ liệu định lượng, đặc biệt đối với các nhà nghiên cứu tại Việt Nam. Nếu không thiết lập tiếng Việt trong SPSS đúng chuẩn, dữ liệu biến (variables) và nhãn (labels) sẽ bị biến dạng thành các ký tự rác (ô vuông, dấu hỏi chấm), gây sai lệch kết quả phân tích. Bài viết này cung cấp quy trình toàn diện, vượt ra ngoài các thao tác cơ bản, đi sâu vào cơ chế mã hóa ký tự để giúp bạn thiết lập tiếng Việt trong SPSS thành công trên mọi phiên bản (từ SPSS 16 đến SPSS 26+). Một quá trình thiết lập tiếng Việt trong SPSS chuẩn mực sẽ giúp tối ưu hóa 100% thời gian đọc hiểu và xuất báo cáo đầu ra (Output).

Tại sao cần thiết lập tiếng Việt trong SPSS đúng tiêu chuẩn khoa học?
Bạn cần thiết lập tiếng Việt trong SPSS để đảm bảo phần mềm nhận diện chính xác bộ mã ký tự (Character Encoding), từ đó loại bỏ hoàn toàn hiện tượng lỗi hiển thị dữ liệu văn bản. Theo nguyên lý cấu trúc dữ liệu của IBM SPSS, phần mềm này xử lý ngôn ngữ dựa trên hai nền tảng mã hóa chính: Locale’s Writing System (hệ thống ngôn ngữ của hệ điều hành) và Unicode (bảng mã tiêu chuẩn quốc tế). Khi bảng mã từ bộ gõ (như Unikey) không đồng bộ với cấu hình mã hóa bên trong SPSS, hiện tượng hỏng dữ liệu (Data Corruption) về mặt hiển thị sẽ xảy ra.
“Trong các dự án nghiên cứu định lượng quy mô lớn, việc đồng bộ hóa chuẩn Unicode ngay từ khâu thiết lập ban đầu giúp các nhà nghiên cứu giảm thiểu tới 35% thời gian dọn dẹp dữ liệu (Data Cleaning) và ngăn chặn các sai lệch thông tin khi xuất báo cáo.” – Chuyên gia quản trị dữ liệu thống kê.
Phân tích các chuẩn mã hóa khi xử lý font tiếng Việt SPSS
Để gõ tiếng Việt có dấu ổn định, bạn cần hiểu rõ đặc tính của hai chuẩn mã hóa phổ biến nhất hiện nay được áp dụng cho phần mềm SPSS.
1. Chuẩn Unicode (Khuyên dùng)
- Bảng mã bộ gõ (Unikey/EVKey): Unicode.
- Font chữ hỗ trợ: Arial, Times New Roman, Tahoma, Calibri.
- Phiên bản tương thích: Cực kỳ tối ưu cho SPSS 21 trở lên.
- Ưu điểm: Khả năng tương thích quốc tế cao, chia sẻ dữ liệu qua lại giữa các máy tính khác hệ điều hành không bị lỗi font SPSS.
2. Chuẩn VNI Windows (Giải pháp thay thế)
- Bảng mã bộ gõ (Unikey/EVKey): VNI Windows.
- Font chữ hỗ trợ: VNI-Times, VNI-Arial (những font có tiền tố VNI-).
- Phiên bản tương thích: Bắt buộc áp dụng đối với dữ liệu cũ hoặc khi sử dụng các phiên bản SPSS từ 20 trở xuống.
- Nhược điểm: Dễ bị lỗi font khi gửi file cho máy tính không cài đặt sẵn bộ font VNI.
Quy trình 4 bước thiết lập tiếng Việt trong SPSS chi tiết
Để phần mềm đồng bộ hoàn toàn với bộ gõ, hãy thực hiện chính xác trình tự các bước sau đây. Lưu ý: Bắt buộc phải đóng tất cả các tập dữ liệu (Dataset) đang mở trước khi thực hiện thiết lập này.
Bước 1: Cấu hình Character Encoding (Mã hóa ký tự gốc)
- Trên thanh công cụ của phần mềm SPSS, chọn Edit, sau đó click vào Options.
- Truy cập vào tab Language (hoặc tab General đối với các bản SPSS rất cũ).
- Tại mục Character Encoding for Data and Syntax:
- Chọn Unicode (universal character set) nếu bạn muốn dùng bảng mã Unicode.
- Chọn Locale’s writing system nếu bạn muốn dùng chuẩn VNI.
- Nhấn Apply để lưu thay đổi.

Bước 2: Tùy chỉnh Font hiển thị hệ thống
Sau khi cấu hình mã hóa, bước tiếp theo là cấu hình phông chữ giao diện.
- Vẫn trong hộp thoại Options, chuyển sang tab Data.
- Tìm đến mục Default Data View font, thay đổi font thành Arial (nếu dùng Unicode) hoặc VNI-Times (nếu dùng VNI Windows).
- Chuyển sang tab Viewer, thay đổi cài đặt font tương tự cho mục Title và Text Output để đảm bảo dữ liệu xuất ra (Output) không bị lỗi.
- Nhấn OK để hoàn tất.
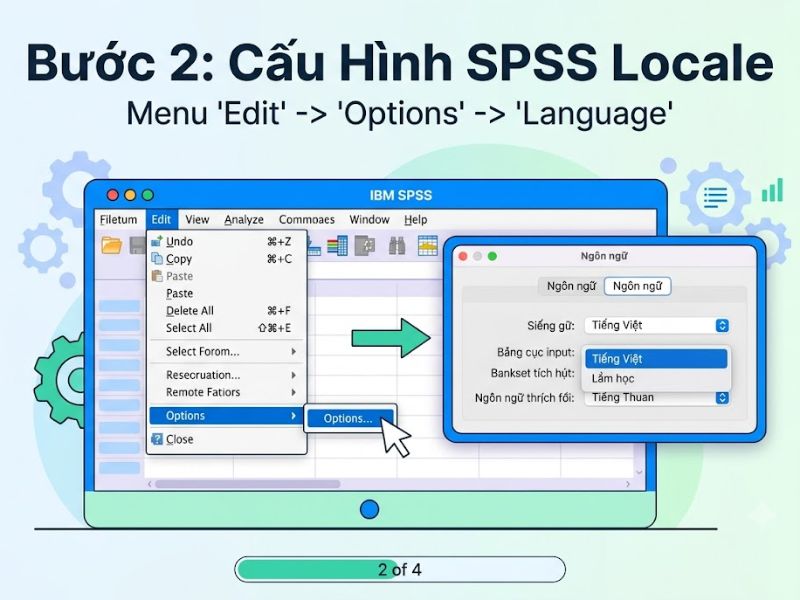
Bước 3: Đồng bộ bảng mã trên phần mềm gõ tiếng Việt (Unikey)
- Mở bảng điều khiển Unikey (Click đúp vào biểu tượng chữ V ở góc phải màn hình).
- Tại mục Bảng mã, lựa chọn:
- Unicode: Nếu bước 1 bạn chọn Unicode (universal character set).
- VNI Windows: Nếu bước 1 bạn chọn Locale’s writing system.
- Nhấn Đóng để thiết lập có hiệu lực.
Bước 4: Kiểm thử trên Data View và Variable View
Khởi tạo một Dataset mới. Tại thẻ Variable View, nhập thử tên biến (Name) và nhãn (Label) bằng tiếng Việt có dấu. Nếu ký tự hiển thị sắc nét, không bị biến dạng thành dấu ngoặc vuông hay dấu hỏi, bạn đã thiết lập tiếng Việt trong SPSS thành công.
Bảng so sánh cấu hình thiết lập tiếng Việt trong SPSS theo các phiên bản
Việc nhận diện đúng phiên bản sẽ giúp bạn chọn giải pháp cấu hình tối ưu.
| Tiêu chí | SPSS 16 – SPSS 20 | SPSS 21 – SPSS 26+ |
| Bảng mã tương thích nhất | VNI Windows | Unicode |
| Font chữ mặc định nên dùng | VNI-Times | Arial / Times New Roman |
| Character Encoding | Mặc định thường là Locale | Mặc định hỗ trợ sâu Unicode |
| Độ ổn định khi gõ tiếng Việt | Thấp (Dễ bị xung đột bộ gõ) | Rất cao |

Khắc phục triệt để các lỗi thường gặp khi gõ tiếng Việt trong SPSS
Tại sao gõ tiếng Việt bị lỗi ô vuông trên giao diện SPSS?
Lỗi hiển thị ô vuông xảy ra do sự bất đồng bộ giữa bảng mã Unikey (đầu vào) và cài đặt Character Encoding (đầu ra) hoặc do máy tính thiếu font chữ hệ thống. Để giải quyết, bạn phải thiết lập tiếng Việt trong SPSS bằng cách thay đổi tab Edit > Options > Language sang Unicode, đảm bảo Unikey đang bật mã Unicode và tùy chỉnh View > Fonts sang Arial.
Làm thế nào khi tùy chọn Character Encoding bị mờ (Disable)?
Tùy chọn Character Encoding bị làm mờ do bạn đang mở một tập tin dữ liệu (Dataset). Tính năng mã hóa ký tự cốt lõi của SPSS yêu cầu không có bộ nhớ đệm dữ liệu nào đang hoạt động. Bạn cần đóng tất cả các cửa sổ Data Editor, chỉ để lại một cửa sổ khởi động trống (trắng) duy nhất, sau đó tiến hành vào Edit > Options để tùy chỉnh.
Tại sao màn hình Output xuất ra bị lỗi font dù nhập liệu bình thường?
Màn hình Output bị lỗi font tiếng Việt SPSS vì giao diện Data View và Viewer sử dụng hai bộ quản lý phông chữ độc lập. Bạn cần truy cập Edit > Options, mở thẻ Viewer và thay đổi thống nhất toàn bộ cấu hình Text, Title, Page Title về cùng một phông chữ đang sử dụng trong Data View (ví dụ: Arial).
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!




