
Trong quá trình nghiên cứu định lượng, tệp dữ liệu thô thu về từ khảo sát thường chứa nhiều khuyết điểm, làm sai lệch kết quả kiểm định các mô hình. Việc sửa số liệu lỗi chạy SPSS là thao tác kỹ thuật bắt buộc nhằm đảm bảo tính tuyến tính, độ tin cậy của thang đo và sự hội tụ của các nhân tố. Bài viết này cung cấp hệ thống giải pháp phân tích, nhận diện và khắc phục triệt để các vấn đề dữ liệu xấu dựa trên nền tảng thống kê thực nghiệm, giúp nhà nghiên cứu tối ưu hóa đầu ra một cách khoa học nhất.

Tại sao cần sửa số liệu lỗi chạy SPSS trước khi phân tích chuyên sâu?
Việc sửa số liệu lỗi chạy SPSS cần được thực hiện ngay lập tức để ngăn chặn sự sai lệch của các hệ số thống kê quan trọng như Cronbach’s Alpha, EFA và hồi quy tuyến tính. Dữ liệu lỗi (chứa giá trị khuyết, điểm dị biệt) sẽ làm biến dạng ma trận tương quan, giảm độ tin cậy của thang đo và dẫn đến việc các giả thuyết nghiên cứu bị bác bỏ một cách oan uổng.
Khi dữ liệu không được làm sạch, mô hình sẽ vi phạm các giả định thống kê cơ bản, dẫn đến hiện tượng sai số ngẫu nhiên lớn, phương sai sai số thay đổi và xuất hiện đa cộng tuyến. Việc xử lý số liệu ngay từ đầu giúp tiết kiệm thời gian chạy đi chạy lại các thuật toán và bảo vệ tính toàn vẹn của kết luận nghiên cứu.

Nhận diện các dấu hiệu cảnh báo cần xử lý dữ liệu
Để biết khi nào cần can thiệp, bạn phải dựa vào các chỉ số cảnh báo từ phần mềm thống kê thay vì cảm quan cá nhân. Các lỗi phổ biến nhất bao gồm:
- Lỗi Missing Values (Dữ liệu khuyết): Trạng thái ô trống trong Data View do người tham gia khảo sát bỏ qua câu hỏi.
- Lỗi Outliers (Điểm dị biệt): Các quan sát có giá trị quá cao hoặc quá thấp so với phần lớn mẫu, làm lệch phân phối chuẩn.
- Hệ số Cronbach’s Alpha < 0.6 hoặc bị âm: Cảnh báo thang đo không có độ tin cậy, các biến quan sát đang mâu thuẫn hoặc chưa được mã hóa ngược (Reverse Coding).
- KMO < 0.5 hoặc Sig. Bartlett’s Test > 0.05: Dữ liệu không đủ điều kiện để phân tích nhân tố khám phá EFA.
- Hệ số VIF > 10 (hoặc > 2 tùy tiêu chuẩn): Dấu hiệu vi phạm giả định đa cộng tuyến trong phân tích hồi quy tuyến tính đa biến.

Quy trình 5 bước làm sạch và sửa số liệu lỗi chạy SPSS tiêu chuẩn
Để giải quyết triệt để dữ liệu xấu, quy trình làm sạch cần được thực hiện theo trình tự tuyến tính nghiêm ngặt dưới đây:
- Mã hóa và định dạng biến (Variable Transformation): Đảm bảo tất cả các biến dạng chuỗi (String) đã được chuyển sang định dạng số (Numeric). Sử dụng lệnh Recode into Same/Different Variables để mã hóa lại các thang đo nghịch (Reverse-scored items).
- Khắc phục giá trị khuyết (Handling Missing Data): Thay vì xóa bỏ toàn bộ hàng dữ liệu (Listwise deletion) làm giảm cỡ mẫu (N), hãy sử dụng chức năng Replace Missing Values của SPSS. Phương pháp nội suy tuyến tính (Linear Interpolation) hoặc thay thế bằng giá trị trung bình (Series Mean) là tối ưu nhất cho thang đo Likert.
- Loại bỏ điểm dị biệt (Detecting Outliers): Sử dụng biểu đồ Boxplot hoặc chuẩn hóa biến về giá trị Z-score. Bất kỳ quan sát nào có giá trị |Z| > 3.29 đều được xếp vào nhóm ngoại lai cần được xem xét loại bỏ để không làm méo mó đường hồi quy.
- Kiểm định phân phối chuẩn (Normality Test): Chạy kiểm định Kolmogorov-Smirnov hoặc Shapiro-Wilk. Nếu dữ liệu vi phạm phân phối chuẩn, cần thực hiện biến đổi dữ liệu (Data Transformation) bằng cách lấy Logarit tự nhiên hoặc khai căn bậc hai.
- Tối ưu hóa ma trận tương quan: Loại bỏ dần các biến độc lập có tương quan Pearson với biến phụ thuộc quá thấp (r < 0.2) hoặc tương quan với biến độc lập khác quá cao (r > 0.8) để ngăn chặn đa cộng tuyến sớm.
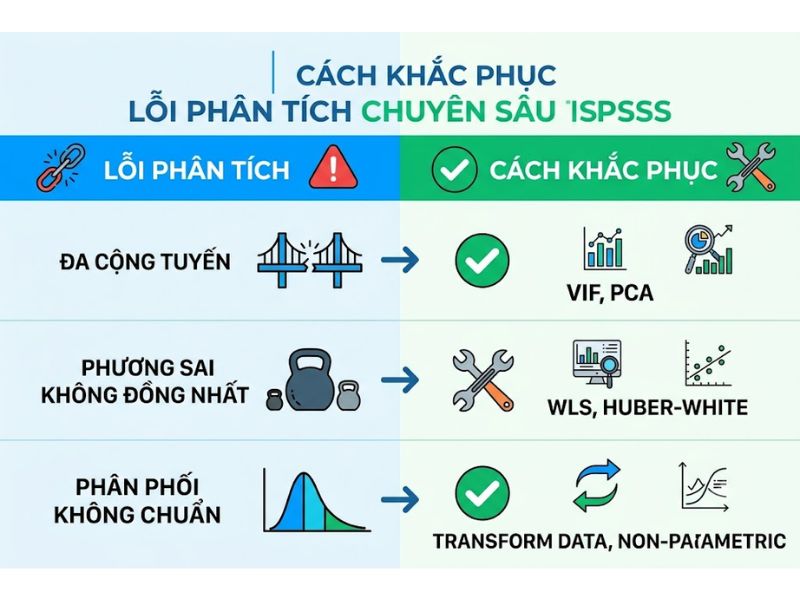
So sánh các kỹ thuật xử lý dữ liệu lỗi phổ biến
Việc lựa chọn kỹ thuật khắc phục phụ thuộc vào quy mô mẫu và bản chất của lỗi. Bảng dưới đây đối chiếu các phương pháp thường được sử dụng trong SPSS:
| Kỹ thuật xử lý | Ưu điểm | Nhược điểm | Khuyến nghị áp dụng |
| Xóa quan sát (Listwise Deletion) | Giữ nguyên độ tự nhiên của dữ liệu, không can thiệp nhân tạo. | Giảm mạnh cỡ mẫu (N), có thể làm giảm ý nghĩa thống kê (Power of Test). | Khi dữ liệu khuyết hoặc dị biệt chiếm tỷ lệ dưới 5% tổng cỡ mẫu. |
| Thay thế Mean/Median | Duy trì quy mô mẫu nguyên vẹn, thực hiện nhanh chóng trên phần mềm. | Có thể làm giảm phương sai tự nhiên của biến, ảnh hưởng nhẹ đến phân phối. | Khi tỷ lệ Missing Values từ 5% – 10% và dữ liệu phân phối tương đối chuẩn. |
| Thuật toán nội suy (Interpolation) | Giữ được cấu trúc tương quan và xu hướng của dữ liệu đa chiều. | Đòi hỏi thao tác phức tạp, khó giải thích với hội đồng phản biện. | Dữ liệu chuỗi thời gian (Time-series) hoặc dữ liệu có quy luật tuyến tính mạnh. |
Các lỗi phân tích dữ liệu chuyên sâu và cách khắc phục mới
Lỗi ma trận xoay EFA không hội tụ hoặc lộn xộn
Đây là tình trạng các biến quan sát (items) tải lên nhiều nhân tố cùng lúc với hệ số Factor Loading sát nhau, hoặc một nhân tố chỉ có duy nhất 1-2 biến quan sát.
Cách xử lý: Bạn cần kiểm tra lại ma trận Component Matrix. Tiến hành loại bỏ từng biến có hệ số tải (Factor Loading) < 0.5 hoặc các biến tải lên 2 nhân tố mà mức chênh lệch hệ số tải < 0.3. Sau mỗi lần loại 1 biến, bắt buộc phải chạy lại lệnh EFA từ đầu cho đến khi ma trận xoay hội tụ sắc nét.
Lỗi R bình phương (R-square) quá thấp trong hồi quy
R bình phương thấp (ví dụ < 0.3) chứng tỏ các biến độc lập giải thích được rất ít sự biến thiên của biến phụ thuộc.
Cách xử lý:
Việc sửa số liệu lỗi chạy SPSS trong trường hợp này yêu cầu rà soát lại biến ngoại lai có điểm đòn bẩy (Leverage points) cao bằng khoảng cách Cook (Cook’s Distance). Đồng thời, xem xét việc thêm các biến kiểm soát (Control variables) hoặc chuyển đổi sang mô hình phi tuyến nếu biểu đồ Scatterplot cho thấy quan hệ giữa các biến không phải đường thẳng.
Nguyên tắc đạo đức và giới hạn trong việc điều chỉnh số liệu khoa học
“Trong phân tích thống kê định lượng, việc làm sạch và xử lý dữ liệu khác hoàn toàn với hành vi ngụy tạo số liệu (Data Fabrication) hay xào nấu dữ liệu (Data Manipulation). Việc loại bỏ các giá trị ngoại lai, thay thế giá trị khuyết phải được biện luận dựa trên cơ sở khoa học, tiêu chuẩn thống kê rõ ràng, không được tùy tiện cắt gọt chỉ để đạt được hệ số p-value < 0.05 bằng mọi giá.” – Theo chuẩn mực nghiên cứu thống kê quốc tế.
Nhà nghiên cứu cần ghi chép lại toàn bộ quy trình loại bỏ biến, làm sạch mẫu vào trong phụ lục của báo cáo nghiên cứu để minh bạch hóa dữ liệu.
Câu hỏi thường gặp (FAQ)
Sửa số liệu lỗi chạy SPSS có làm mất đi tính đại diện của mẫu khảo sát không?
Việc sửa số liệu lỗi chạy SPSS hoàn toàn không làm mất tính đại diện nếu tổng số dữ liệu bị cắt giảm hoặc thay thế nằm ở ngưỡng an toàn (thường dưới 5-10% tổng số mẫu). Nếu bạn phải loại bỏ quá 20% dữ liệu để đạt chuẩn, vấn đề nằm ở thang đo hoặc phương pháp lấy mẫu ban đầu, khi đó bạn buộc phải thu thập thêm dữ liệu thực tế.
Làm thế nào để xử lý dữ liệu chạy ra hệ số Cronbach’s Alpha bị âm?
Hệ số Cronbach’s Alpha âm xảy ra khi có sự hiệp phương sai âm giữa các biến quan sát. Hãy kiểm tra ngay lại bảng câu hỏi xem có câu hỏi đảo ngược (Reverse-worded questions) nào chưa được chạy lệnh Recode trên phần mềm SPSS hay không. Chỉ cần mã hóa ngược lại các biến này, hệ số Alpha sẽ trở lại mức dương tiêu chuẩn.
Có nên cố tình chỉnh sửa dữ liệu để hệ số tương quan đẹp hơn?
Tuyệt đối không. Việc can thiệp trực tiếp vào từng ô số liệu theo cách thủ công để “ép” hệ số tương quan tăng lên là hành vi vi phạm liêm chính học thuật. Bạn chỉ được phép sử dụng các thuật toán chuẩn hóa dữ liệu, xóa Outliers hoặc chuyển đổi đơn vị biến đổi (Log, SQRT) mà phần mềm hỗ trợ.
Kết luận
Kiểm định mô hình nghiên cứu không chỉ là việc đưa số liệu vào phần mềm và bấm nút tính toán. Thực hiện kỹ thuật sửa số liệu lỗi chạy SPSS bài bản là nền tảng cốt lõi giúp cải thiện các chỉ số đo lường, loại bỏ nhiễu và bảo vệ độ tin cậy tuyệt đối cho công trình khoa học của bạn. Hãy tuân thủ nghiêm ngặt 5 bước quy trình làm sạch dữ liệu và vận dụng linh hoạt các thuật toán khắc phục lỗi để cho ra được kết quả cuối cùng phản ánh đúng thực tế khách quan nhất.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!




