
Mô hình phương trình cấu trúc dựa trên thành phần là một phương pháp thống kê cốt lõi được sử dụng để phân tích các mối quan hệ phức tạp giữa các khái niệm không quan sát trực tiếp được trong nghiên cứu kinh doanh. Nguyên nhân chính của sự thiếu đồng nhất trong việc áp dụng là các nhà nghiên cứu chưa đánh giá một cách có hệ thống hiệu suất dự báo của các thuật toán khác nhau. Giải pháp tối ưu và nhanh nhất cho việc xây dựng mô hình có sức mạnh dự báo cao là sử dụng phương pháp Phân tích thành phần có cấu trúc tổng quát kết hợp với chỉ báo phản ánh (ký hiệu là GSCA-R), nhờ tính linh hoạt trong đặc tả mô hình và độ chính xác dự báo toàn cục cao nhất.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: A comparative study of the predictive power of component-based approaches to structural equation modeling.
- Tiêu đề tiếng Việt: Nghiên cứu so sánh về sức mạnh dự đoán của các phương pháp tiếp cận dựa trên thành phần đối với mô hình phương trình cấu trúc.
- Tác giả & Đơn vị công tác: Gyeongcheol Cho & Heungsun Hwang (Khoa Tâm lý học, Đại học McGill, Canada).
- Sunmee Kim (Khoa Tâm lý học, Đại học Manitoba, Canada).
- Jonathan Lee (Trường Kinh doanh và Quản lý Công, Đại học La Verne, Mỹ).
- Marko Sarstedt (Trường Quản lý Munich, Đức & Đại học Babeş-Bolyai, Romania).
- Christian M. Ringle (Khoa Khoa học Quản lý và Công nghệ, Đại học Công nghệ Hamburg, Đức).
- Tạp chí: European Journal of Marketing (2023).
- Loại bài viết: Bài nghiên cứu khoa học (Research paper).
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Trong lĩnh vực nghiên cứu kinh doanh và tiếp thị, các khái niệm trọng tâm thường là các biến tiềm ẩn (không thể quan sát trực tiếp) và bắt buộc phải được đo lường gián tiếp thông qua một hệ thống các biến quan sát (items/indicators). Các khái niệm này được phân loại thành hai nhóm chính:
- Nhóm nhận thức và thái độ cá nhân: Bao gồm chất lượng sản phẩm cảm nhận (perceived product quality), chất lượng dịch vụ (service quality), và cam kết thương hiệu (brand commitment).
- Nhóm đặc điểm hệ thống tổ chức: Bao gồm định hướng thương hiệu (brand orientation), truyền thông tiếp thị tích hợp toàn công ty (firm-wide integrated marketing communication), và tính minh bạch trong tiếp thị doanh nghiệp (transparency in corporate marketing).
Để lượng hóa các khái niệm trên, giới học thuật sử dụng mô hình phương trình cấu trúc dựa trên thành phần như GSCA (Phân tích thành phần có cấu trúc tổng quát) và PLSPM (Mô hình đường dẫn bình phương tối thiểu một phần). Trước đây, phần lớn tài liệu học thuật chỉ tập trung vào khả năng “phục hồi tham số” (parameter recovery – xác định tính không chệch của các ước lượng). Tuy nhiên, nền tảng cốt lõi của tính ứng dụng thực tiễn và tính có thể bác bỏ của lý thuyết (theoretical falsifiability – Popper, 1962) lại nằm ở “sức mạnh dự báo” (predictive power). Việc thiếu vắng các nghiên cứu so sánh có hệ thống về hiệu suất dự báo giữa GSCA và PLSPM chính là một khoảng trống lớn. Nghiên cứu này thiết lập một khung mô phỏng để giải quyết triệt để vấn đề đó.
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Mô hình phương trình cấu trúc dựa trên thành phần tiếp cận dữ liệu bằng cách sử dụng các thành phần (components) dưới dạng tổ hợp tuyến tính có trọng số để làm đại diện cho các cấu trúc tiềm ẩn. Sự khác biệt nền tảng giữa GSCA và PLSPM nằm ở cơ chế tối ưu hóa:
- Lý thuyết tối ưu hóa toàn cục (Global Optimization) của GSCA: GSCA tích hợp ba mô hình phụ (mô hình cấu trúc, mô hình đo lường, và mô hình quan hệ có trọng số) vào một phương trình đại số duy nhất. Hệ thống này sử dụng thuật toán bình phương tối thiểu luân phiên (Alternating Least Squares – ALS), hội tụ khi sự chênh lệch trong hàm tối ưu hóa toàn cục giảm xuống dưới một mức dung sai quy định. Điều này cho phép GSCA tính toán được độ phù hợp của mô hình tổng thể (Global model fit).
- Lý thuyết tối ưu hóa cục bộ (Local Optimization) của PLSPM: PLSPM không có mô hình quan hệ có trọng số một cách rõ ràng và giải quyết mô hình đo lường, mô hình cấu trúc một cách riêng biệt. Hệ thống này dựa trên thuật toán điểm cố định (fixed-point least squares) thông qua chuỗi các phân tích hồi quy cục bộ. Thuật toán hội tụ khi các trọng số của chỉ báo không thay đổi đáng kể. Khuyết điểm lý thuyết của PLSPM là không có hàm tối ưu hóa toàn cục.
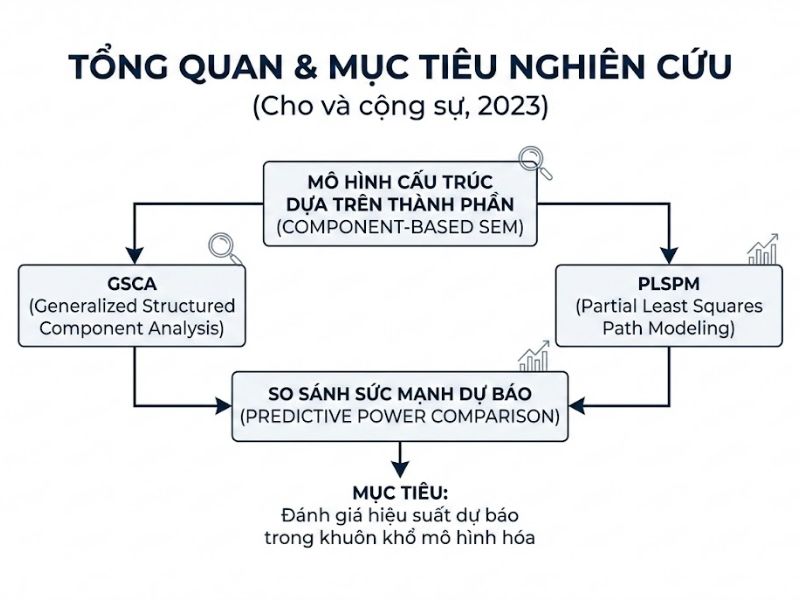
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Cấu trúc khái niệm “Sức mạnh dự báo” (Predictive Power) trong nghiên cứu này không phải là một thang đo tâm lý, mà là một đại lượng thống kê nhằm đánh giá khả năng áp dụng các thông số mô hình được ước lượng từ một mẫu huấn luyện (training sample) để tạo ra các dự báo trên tập dữ liệu mới chưa từng quan sát (out-of-sample). Cấu trúc này được vận hành hóa qua hai biến số độc lập:
- Dự đoán quan sát (Observed prediction): Khả năng sử dụng các điểm số thành phần (component scores) để dự báo trực tiếp các chỉ báo đo lường cấu thành nên chính thành phần đó. Dự đoán này đánh giá chất lượng cấu trúc nội bộ của thành phần.
- Dự đoán vận hành (Operative prediction): Khả năng sử dụng toàn bộ hệ thống ước lượng tham số (bao gồm tất cả các hệ số đường dẫn của mô hình cấu trúc) để dự báo các chỉ báo của thành phần phụ thuộc (dependent components) dựa trên dữ liệu đầu vào là các chỉ báo của thành phần độc lập (independent components). Đây là dạng dự báo mang tính ứng dụng thực tiễn cao nhất.

3. Quy Trình Phát Triển Thiết Kế Mô Phỏng (Simulation Design Process)
Nghiên cứu ứng dụng phương pháp mô phỏng Monte Carlo toàn diện để so sánh 4 kỹ thuật cốt lõi: GSCA-R (GSCA với chỉ báo phản ánh), GSCA-F (GSCA với chỉ báo hình thành), PLS-A (PLSPM Mode A), và PLS-B (PLSPM Mode B). Quy trình tạo ra tổng cộng 108 kịch bản sinh dữ liệu theo các biến số sau:
- Số lượng chỉ báo (Indicators per component): Phân bổ 3, 6, hoặc 9 chỉ báo cho mỗi thành phần.
- Tỷ lệ chênh lệch trọng số (Ratio of weight differences): Thao tác ở mức 0.1, 0.2, 0.3. Việc kiểm soát tỷ lệ này hợp lý hơn là kiểm soát độ lớn tuyệt đối, vì số lượng chỉ báo tác động trực tiếp đến kích thước trọng số.
- Độ phức tạp của mô hình cấu trúc (Structural complexity):
- Đơn giản: 4 thành phần, 3 đường dẫn, 1 tương quan ngoại sinh.
- Trung bình: 5 thành phần.
- Phức tạp: 7 thành phần, 10 đường dẫn, 3 tương quan ngoại sinh.
- Tương quan thành phần ngoại sinh: Mức độ 0.1 và 0.3.
- Loại thành phần: Thành phần theo quy luật (Nomological components – tối đa hóa phương sai giải thích cho cả chỉ báo và thành phần phụ thuộc) và Thành phần chính tắc (Canonical components – chỉ tối đa hóa phương sai giải thích cho thành phần phụ thuộc).
- Thiết lập mẫu (Sample settings): Mỗi kịch bản tạo 1.000 tập huấn luyện (Kích thước N = 100, 200, 500, 1.000) và 1 tập kiểm tra tiêu chuẩn với N = 10.000 để đo lường sai số.
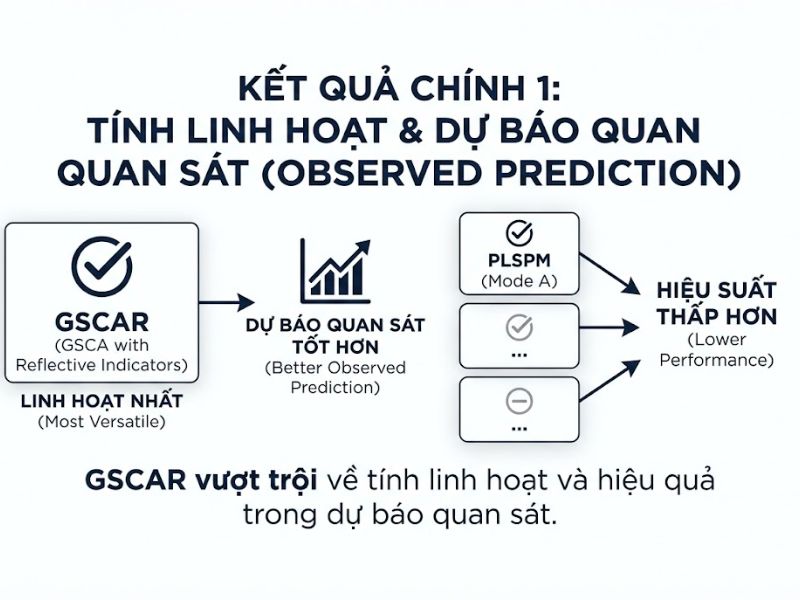

4. Thang Đo Lường Chính Thức (Measurement Scale)
Khái niệm sức mạnh dự báo được lượng hóa thông qua phương sai của đại lượng Lỗi bình phương trung bình (MSE – Mean Squared Error) trên tập dữ liệu kiểm tra. Phương pháp có MSE càng nhỏ thì khả năng khái quát hóa (generalizability) càng cao.
- Công thức lượng hóa Dự đoán quan sát: Tính bằng tổng bình phương phần dư (Sum of Squares) giữa ma trận chỉ báo thực tế và ma trận dự đoán: SS(Z_test – Z_test * W_hat * C_hat)
- Công thức lượng hóa Dự đoán vận hành: Tích hợp ma trận hệ số đường dẫn (B): SS(Z_test – Z_test * W_hat * B_hat * C_hat)
Bảng 1: Phân tích so sánh đặc tính toán học và cấu trúc của GSCA và PLSPM
| Tiêu chí nền tảng | Kỹ thuật GSCA | Kỹ thuật PLSPM |
| Hệ thống mô hình phụ | Mô hình cấu trúc, Quan hệ có trọng số, Đo lường | Mô hình cấu trúc, Mô hình đo lường |
| Tiêu chí tối ưu hóa toàn cục | Có (Hội tụ thành một phương trình duy nhất) | Không (Tối ưu hóa cục bộ riêng rẽ) |
| Thuật toán ước lượng cốt lõi | Bình phương tối thiểu luân phiên (ALS) | Chuỗi bình phương tối thiểu điểm cố định |
| Phân bổ chỉ báo chéo (Cross-loadings) | Cho phép một chỉ báo gán nhiều thành phần | Giới hạn mỗi chỉ báo thuộc một thành phần |
| Mối quan hệ không đệ quy (Reciprocal) | Cho phép các vòng lặp giữa các thành phần | Chỉ hỗ trợ mối quan hệ đệ quy tuyến tính |
| Kiểm định độ phù hợp toàn cục | Hỗ trợ tính toán (Ví dụ: GoF, SRMR) | Không hỗ trợ hợp lệ theo chuẩn toán học |
5. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
- Tiền tố (Antecedents) định hình sức mạnh dự báo: * Số lượng chỉ báo (Number of indicators): Có tác động tiêu cực đến dự đoán quan sát. Khi mô hình sở hữu quá nhiều chỉ báo, giá trị MSE tăng lên do tính nhiễu của dữ liệu. Cả 4 phương pháp đều dự báo tốt nhất ở mô hình đo lường tinh gọn (3 chỉ báo).
- Chênh lệch trọng số (Weight difference): Có tác động tích cực. Các chỉ báo đóng góp với mức độ khác biệt càng lớn (0.3) thì mô hình càng dễ dàng tinh chỉnh tham số để dự đoán chính xác dữ liệu mới.
- Kích thước mẫu (Sample size): Tác động trực tiếp đến nhóm yếu thế. Với kích thước mẫu cực lớn (N=1.000), mô hình GSCA-F và PLS-B cải thiện năng lực dự đoán rõ rệt và bắt kịp hiệu suất của GSCA-R và PLS-A.
- Sai lệch đặc tả mô hình (Misspecification): Yếu tố này mang lại một kết luận ngược trực giác nhưng chuẩn xác theo lý thuyết thống kê. Việc mô hình bị đặc tả sai (thêm đường dẫn thừa) hầu như không làm giảm dự đoán quan sát và chỉ ảnh hưởng cực nhỏ đến dự đoán vận hành. Cơ chế cốt lõi là sự đánh đổi giữa độ lệch và phương sai (Bias-Variance Tradeoff). Việc giảm phương sai có thể bù đắp cho việc tăng độ lệch, giúp mô hình sai đặc tả có kết quả dự báo thực nghiệm tốt hơn mô hình đúng bản chất lý thuyết.
- Hậu tố (Consequences): Năng lực dự báo chính xác đóng vai trò là chứng cứ thực chứng (empirical evidence) mạnh mẽ nhất để chấp nhận một lý thuyết quản trị. Việc ứng dụng thuật toán có sai số thấp nhất sẽ định hình trực tiếp tính hợp lệ của các quyết định thực tiễn được đưa ra bởi nhà quản trị.
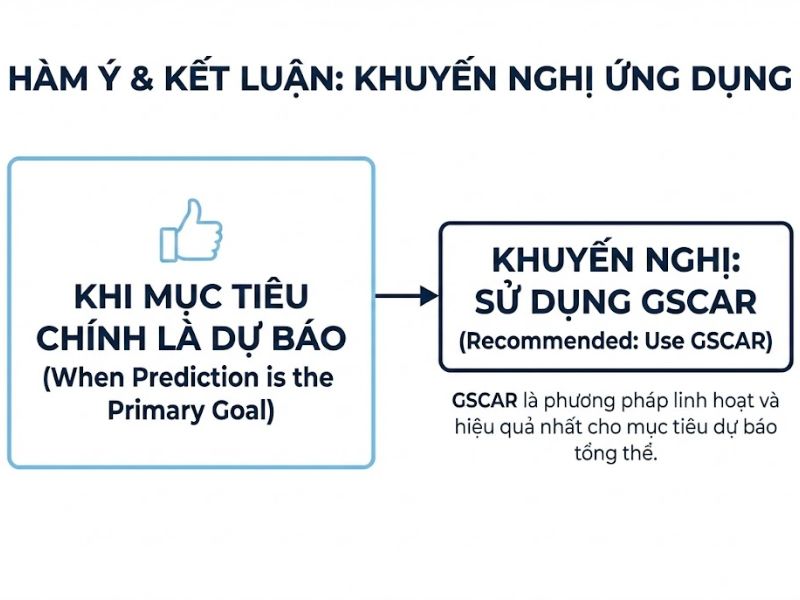
6. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Dành cho nghiên cứu sinh, giảng viên và các nhà khoa học đang phân tích dữ liệu bằng mô hình phương trình cấu trúc dựa trên thành phần:
- Luôn thiết lập GSCA-R làm ưu tiên hàng đầu: Nếu nghiên cứu của bạn đặt mục tiêu giải thích và dự báo ngang bằng nhau, hãy sử dụng phân tích GSCA với cấu trúc chỉ báo phản ánh. GSCA-R vượt trội nhẹ so với PLS-A trong dự đoán quan sát và tương đương tuyệt đối trong dự đoán vận hành. Quan trọng hơn, GSCA-R cho phép bạn tính toán các chỉ số phù hợp toàn cục (overall model fit) để chứng minh độ tin cậy của mô hình, điều mà thuật toán PLSPM không làm được.
- Quy trình báo cáo sức mạnh dự báo: Không được dừng lại ở việc báo cáo độ chệch tham số hay hệ số R². Đối với GSCA, học giả bắt buộc phải tính toán chỉ số Lỗi dự đoán ngoài túi (Out-of-bag Prediction Error – OPE) bao gồm OPE_M (cho dự đoán quan sát) và OPE_S (cho dự đoán vận hành). Đối với PLSPM, hãy sử dụng chỉ số Q² thông qua quy trình mù hóa (blindfolding) để đo lường tính dư thừa được xác thực chéo (cross-validated redundancy).
- Tránh rủi ro khi dùng thành phần Canonical: Ngay cả khi mô hình của bạn sử dụng thành phần chính tắc (Canonical components – vốn được sinh ra để tối đa hóa phương sai cấu trúc thay vì đo lường), thì cặp phương pháp GSCA-R và PLS-A vẫn mang lại sức mạnh dự báo tốt hơn hẳn cặp GSCA-F và PLS-B. Đừng nhầm tưởng rằng thành phần Canonical bắt buộc phải đi với đo lường hình thành (Formative).
Bảng 2: Ma trận hướng dẫn ra quyết định lựa chọn phương pháp dựa trên mục tiêu dự báo
| Hệ thống Phương pháp | Dự đoán quan sát (Nomological & Canonical) | Dự đoán vận hành (Nomological & Canonical) | Khuyến nghị ứng dụng |
| Thuật toán GSCA-R | Rất tốt (Mức hiệu suất cao nhất) | Rất tốt (Cân bằng Bias-Variance) | Ưu tiên số 1. Tốt nhất cho việc kiểm định lý thuyết và dự báo thực tiễn. |
| Thuật toán PLS-A | Tốt (Độ trễ sai số nhỏ) | Rất tốt (Tương đương GSCA-R) | Ưu tiên số 2. Sử dụng khi hệ sinh thái phần mềm bị giới hạn ở họ PLS. |
| Thuật toán GSCA-F | Khá đến Yếu (Biến động theo mẫu) | Yếu (Tụt hậu trong dự báo) | Chỉ dùng khi mẫu cực lớn (N > 1000) và lý thuyết bắt buộc dùng đo lường hình thành. |
| Thuật toán PLS-B | Rất yếu (Sai số MSE lớn nhất) | Rất yếu (Thiếu tính khái quát hóa) | Khuyến cáo không dùng nếu mục tiêu là dự đoán trên các mẫu quan sát mới. |
7. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Nghiên cứu mang lại bộ khung tư duy chiến lược cho các Giám đốc Marketing (CMO) và chuyên gia phân tích dữ liệu:
- Khoa học hóa các tuyên bố quản trị: Hầu hết các kết luận dạng “Công ty nên cải thiện hệ thống CRM vì nó làm tăng sự trung thành” thực chất là các tuyên bố mang tính dự đoán (prescriptive statements). Để đảm bảo lời khuyên này đúng khi áp dụng vào một tệp khách hàng hoàn toàn mới (ngoài mẫu khảo sát), chuyên gia phân tích dữ liệu phải sử dụng thuật toán có MSE thấp nhất (GSCA-R). Việc dùng sai thuật toán sẽ dẫn đến chiến lược kinh doanh thất bại trên thực địa dù số liệu trên giấy tờ rất đẹp.
- Tối ưu hóa các hệ thống đo lường: Khi thiết kế bảng hỏi khảo sát thị trường (ví dụ: đo lường nhận thức thương hiệu), doanh nghiệp nên giữ số lượng câu hỏi (items) cho mỗi nhân tố ở mức tinh gọn (khoảng 3 câu). Nghiên cứu chứng minh rằng càng nhồi nhét nhiều chỉ báo đo lường, sai số dự báo quan sát càng tăng, làm lãng phí chi phí thu thập dữ liệu và giảm độ chính xác của chiến lược.
- Sử dụng linh hoạt lý thuyết đánh đổi: Trong kinh doanh thực tế, một mô hình dự báo hành vi người dùng không cần thiết phải tuân theo 100% các nguyên tắc lý thuyết học thuật cứng nhắc. Đôi khi việc chấp nhận một mô hình có một chút sai lệch nhỏ về mặt khái niệm (misspecification) lại tạo ra một hệ thống dự báo tỷ lệ chuyển đổi (Conversion Rate) có độ chính xác cao hơn do kiểm soát tốt phương sai dữ liệu.
8. Các Câu Hỏi Thường Gặp (FAQ)
Sự khác biệt cốt lõi về mặt ứng dụng giữa “Dự đoán quan sát” và “Dự đoán vận hành” trong hệ thống SEM dựa trên thành phần là gì?
Dự đoán quan sát chủ yếu dùng để kiểm tra độ vững chắc của thang đo (sử dụng điểm số tổng hợp của một nhân tố để dự báo ngược lại các câu hỏi khảo sát tạo ra nó). Ngược lại, Dự đoán vận hành mang tính chiến lược cao hơn vì nó sử dụng toàn bộ chuỗi quan hệ nguyên nhân – kết quả (biến độc lập dự đoán biến phụ thuộc) để ước tính các kết quả đầu ra. Trong nghiên cứu quản trị, dự đoán vận hành là tiêu chuẩn vàng.
Tại sao bài báo kết luận GSCA-R là phương pháp toàn diện nhất dù hiệu suất dự đoán vận hành của nó chỉ tương đương với PLS-A?
Lý do nằm ở cơ sở toán học của thuật toán. GSCA-R áp dụng cơ chế tối ưu hóa toàn cục, cho phép nhà nghiên cứu chiết xuất các chỉ số mức độ phù hợp toàn mô hình (Global model fit như GoF, SRMR). Khả năng này giúp đánh giá đồng thời cả sức mạnh dự báo lẫn tính chính xác của lý thuyết gốc, mang lại tính minh bạch học thuật cao hơn so với tính toán cục bộ của PLS-A.
Khái niệm sự đánh đổi giữa độ lệch và phương sai (Bias-Variance Tradeoff) ảnh hưởng thế nào đến việc xử lý mô hình sai đặc tả?
Trong mục tiêu giải thích, việc mô hình bị sai đặc tả (chứa các đường dẫn sai hoặc bỏ sót biến) là một lỗi nghiêm trọng. Tuy nhiên, trong mục tiêu dự báo, tổng sai số bằng tổng của Độ lệch (Bias) và Phương sai (Variance). Việc một mô hình bị sai đặc tả có thể làm tăng nhẹ Bias nhưng lại làm giảm đáng kể Variance. Kết quả là tổng sai số (MSE) giảm xuống, giúp mô hình áp dụng chính xác hơn lên các dữ liệu mới trong tương lai.
9. Tài Liệu Tham Khảo (References)
- Areskoug, B. (1982), “The first canonical correlation: theoretical PLS analysis and simulation experiments”, in Wold, H. and Jöreskog, K.G. (Eds), Systems under Indirect Observation: Causality, Structure, Prediction, North Holland, Amsterdam, Netherlands, pp. 95-118.
- Bandalos, D.L. and Gagné, P. (2012), “Simulation methods in structural equation modeling”, in Hoyle, R.H. (Ed.), Handbook of Structural Equation Modeling, Guilford Press, New York, NY, pp. 92-108.
- Becker, J.-M., Rai, A. and Rigdon, E. (2013), “Predictive validity and formative measurement in structural equation modeling embracing practical relevance”, in Baskerville, R.L. and Chau, M. (Eds), Proceedings of the International Conference on Information Systems, ICIS 2013, Milano, Italy.
- Borsboom, D., Mellenbergh, G.J. and van Heerden, J. (2003), “The theoretical status of latent variables”, Psychological Review, Vol. 110 No. 2, pp. 203-219.
- Cepeda Carrión, G., Henseler, J., Ringle, C.M. and Roldán, J.L. (2016), “Prediction-oriented modeling in business research by means of PLS path modeling: introduction to a JBR special section”, Journal of Business Research, Vol. 69 No. 10, pp. 4545-4551.
- Ceridwyn, K. and Debra, G. (2012), “Examining the antecedents of positive employee brand-related attitudes and behaviours”, European Journal of Marketing, Vol. 46 Nos 3/4, pp. 469-488.
- Chica, M. and Rand, W. (2017), “Building agent-based decision support systems for word-of-mouth programs: a freemium application”, Journal of Marketing Research, Vol. 54 No. 5, pp. 752-767.
- Chin, W.W. (1998), “The partial least squares approach for structural equation modeling”, in Marcoulides, G.A. (Ed.), Modern Methods for Business Research, Erlbaum, Mahwah, NJ, pp. 295-336.
- Chin, W.W. (2010), “Bootstrap cross-validation indices for PLS path model assessment”, in Esposito Vinzi, V., Chin, W.W., Henseler, J. and Wang, H. (Eds), Handbook of Partial Least Squares: Concepts, Methods and Applications, Springer, Berlin, Heidelberg, pp. 83-97.
- Chin, W., Cheah, J.-H., Liu, Y., Ting, H., Lim, X.-J. and Cham, T.H. (2020), “Demystifying the role of causal-predictive modeling using partial least squares structural equation modeling in information systems research”, Industrial Management and Data Systems, Vol. 120 No. 12, pp. 2161-2209.
- Cho, G. and Choi, J.Y. (2020), “An empirical comparison of generalized structured component analysis and partial least squares path modeling under variance-based structural equation models”, Behaviormetrika, Vol. 47 No. 1, pp. 243-272.
- Cho, G., Sarstedt, M. and Hwang, H. (2021), “A comparison of covariance structure analysis, partial least squares path modeling and generalized structured component analysis in factor-and composite models”, British Journal of Mathematical and Statistical Psychology.
- Cho, G., Jung, K. and Hwang, H. (2019), “Out-of-bag prediction error: a cross validation index for generalized structured component analysis”, Multivariate Behavioral Research, Vol. 54 No. 4, pp. 505-513.
- Cho, G., Hwang, H., Sarstedt, M. and Ringle, C.M. (2020), “Cutoff criteria for overall model fit indexes in generalized structured component analysis”, Journal of Marketing Analytics, Vol. 8 No. 4, pp. 189-202.
- Cole, D.A. and Preacher, K.J. (2014), “Manifest variable path analysis: potentially serious and misleading consequences due to uncorrected measurement error”, Psychological Methods, Vol. 19 No. 2, pp. 300-315.
- Cuong, P.H., Nguyen, O.D.Y., Ngo, L.V. and Nguyen, N.P. (2020), “Not all experiential consumers are created equals: the interplay of customer equity drivers on brand loyalty”, European Journal of Marketing, Vol. 54 No. 9, pp. 2257-2286.
- Diamantopoulos, A. (2006), “The error term in formative measurement models: interpretation and modeling implications”, Journal of Modelling in Management, Vol. 1 No. 1, pp. 7-17.
- Dijkstra, T.K. (2017), “A perfect match between a model and a mode”, in Latan, H. and Noonan, R. (Eds), Partial Least Squares Path Modeling: Basic Concepts, Methodological Issues and Applications, Springer, Berlin, Germany, pp. 55-80.
- Evermann, J. and Tate, M. (2016), “Assessing the predictive performance of structural equation model estimators”, Journal of Business Research, Vol. 69 No. 10, pp. 4565-4582.
- Franke, G. and Sarstedt, M. (2019), “Heuristics versus statistics in discriminant validity testing: a comparison of four procedures”, Internet Research, Vol. 29 No. 3, pp. 430-447.
- Goodhue, D.L., Lewis, W. and Thompson, R. (2006), “PLS, small sample size, and statistical power in MIS research”, Proceedings of the 39th Annual HI International Conference on System Sciences (HICSS’06).
- Hair, J.F. and Sarstedt, M. (2021), “Explanation plus prediction the logical focus of project management research”, Project Management Journal, Vol. 52 No. 4, pp. 319-322.
- Hair, J.F., Howard, M.C. and Nitzl, C. (2020), “Assessing measurement model quality in PLS-SEM using confirmatory composite analysis”, Journal of Business Research, Vol. 109, pp. 101-110.
- Hair, F.J., Sarstedt, M. and Ringle, M.C. (2019), “Rethinking some of the rethinking of partial least squares”, European Journal of Marketing, Vol. 53 No. 4, pp. 566-584.
- Hair, J.F., Hult, G.T.M., Ringle, C.M. and Sarstedt, M. (2022), A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), 3rd ed., Sage, Thousand Oaks, CA.
- Hair, J.F., Risher, J.J., Sarstedt, M. and Ringle, C.M. (2019), “When to use and how to report the results of PLS-SEM”, European Business Review, Vol. 31 No. 1, pp. 2-24.
- Hair, J.F., Hult, G.T.M., Ringle, C.M., Sarstedt, M. and Thiele, K.O. (2017), “Mirror, mirror on the wall: a comparative evaluation of composite-based structural equation modeling methods”, Journal of the Academy of Marketing Science, Vol. 45 No. 5, pp. 616-632.
- Hastie, T., Tibshirani, R. and Friedman, J. (2001), The Elements of Statistical Learning, Springer, New York, NY.
- Henseler, J., Ringle, C.M. and Sarstedt, M. (2015), “A new criterion for assessing discriminant validity in variance-based structural equation modeling”, Journal of the Academy of Marketing Science, Vol. 43 No. 1, pp. 115-135.
- Hofman, J.M., Sharma, A. and Watts, D.J. (2017), “Prediction and explanation in social systems”, Science, Vol. 355 No. 6324, pp. 486-488.
- Hwang, H. and Takane, Y. (2004), “Generalized structured component analysis”, Psychometrika, Vol. 69 No. 1, pp. 81-99.
- Hwang, H. and Takane, Y. (2014), Generalized Structured Component Analysis: A Component-Based Approach to Structural Equation Modeling, Chapman and Hall/CRC Press, New York, NY.
- Hwang, H., Sarstedt, M., Cheah, J.H. and Ringle, C.M. (2020), “A concept analysis of methodological research on composite-based structural equation modeling: bridging PLSPM and GSCA”, Behaviormetrika, Vol. 47 No. 1, pp. 219-241.
- Hwang, H., Malhotra, N.K., Kim, Y., Tomiuk, M.A. and Hong, S. (2010), “A comparative study on parameter recovery of three approaches to structural equation modeling”, Journal of Marketing Research, Vol. 47 No. 4, pp. 699-712.
- Hwang, H., Cho, G., Jung, K., Falk, C., Flake, J. and Jin, M. (2021), “An approach to structural equation modeling with both factors and components: integrated generalized structured component analysis”, Psychological Methods, Vol. 26 No. 3, pp. 273-294.
- Kaplan, A. (1964), The Conduct of Inquiry: Methodology for Behavioral Science, Chandler Publishing, San Francisco, CA.
- Leitch, S.R. (2017), “The transparency construct in corporate marketing”, European Journal of Marketing, Vol. 51 No. 9/10, pp. 1503-1509.
- Liengaard, B., Sharma, P.N., Hult, G.T.M., Jensen, M.B., Sarstedt, M., Hair, J.F. and Ringle, C.M. (2021), “Prediction: coveted, yet forsaken? Introducing a cross-validated predictive ability test in partial least squares path modeling”, Decision Sciences, Vol. 52 No. 2, pp. 362-392.
- Lohmöller, J.-B. (1989), Latent Variable Path Modeling with Partial Least Squares, Physica, Heidelberg, Germany.
- Morel, P. (2018), “Gramm: grammar of graphics plotting in MATLAB”, The Journal of Open Source Software, Vol. 3 No. 23, p. 568.
- Nau, R. (2016), “Statistical forecasting: notes on regression and time series analysis”.
- Paxton, P., Curran, P.J., Bollen, K.A., Kirby, J. and Chen, F. (2001), “Monte Carlo experiments: Design and implementation”, Structural Equation Modeling: A Multidisciplinary Journal, Vol. 8 No. 2, pp. 287-312.
- Popper, K. (1962), Conjectures and Refutations: The Growth of Scientific Knowledge, Basic Books, New York, NY.
- Porcu, L., Del Barrio-Garcia, S. and Kitchen, P.J. (2017), “Measuring integrated marketing communication by taking a broad organisational approach: the firm-wide IMC scale”, European Journal of Marketing, Vol. 51 No. 3, pp. 692-718.
- Praveen, S., Alexander, R. and Rakesh, R.K. (2018), “Toward a conceptualization of perceived complaint handling quality in social media and traditional service channels”, European Journal of Marketing, Vol. 52 Nos 5/6, pp. 973-1006.
- Rego, L.L., Morgan, N.A. and Fornell, C. (2013), “Reexamining the market share-customer satisfaction relationship”, Journal of Marketing, Vol. 77 No. 5, pp. 1-20.
- Richter, N.F., Carrión, G.C., Roldán, J.L. and Ringle, C.M. (2016), “European management research using partial least squares structural equation modeling (PLS-SEM)”, European Management Journal, Vol. 34 No. 6, pp. 589-597.
- Rigdon, E.E., Becker, J.-M. and Sarstedt, M. (2019), “Factor indeterminacy as metrological uncertainty: implications for advancing psychological measurement”, Multivariate Behavioral Research, Vol. 54 No. 3, pp. 429-443.
- Rigdon, E.E., Sarstedt, M. and Ringle, C.M. (2017), “On comparing results from CB-SEM and PLS-SEM: five perspectives and five recommendations”, Marketing ZFP, Vol. 39 No. 3, pp. 4-16.
- Romdhani, H., Hwang, H., Paradis, G., Roy-Gagnon, M.H. and Labbe, A. (2015), “Pathway-based association study of multiple candidate genes and multiple traits using structural equation models”, Genetic Epidemiology, Vol. 39 No. 2, pp. 101-113.
- Roshan, D.G.R. and Marcel, P. (2020), “Customers’ experienced product quality: scale development and validation”, European Journal of Marketing, Vol. 54 No. 4, pp. 645-670.
- Sarstedt, M. and Danks, N.P. (2021), “Prediction in HRM research – a gap between rhetoric and reality”, Human Resource Management Journal.
- Sarstedt, M., Hair, J.F., Nitzl, C., Ringle, C.M. and Howard, M.C. (2020), “Beyond a tandem analysis of SEM and PROCESS: use of PLS-SEM for mediation analyses!”, International Journal of Market Research, Vol. 62 No. 3, pp. 288-299.
- Sarstedt, M., Hair, J.F., Ringle, C.M., Thiele, K.O. and Gudergan, S.P. (2016), “Estimation issues with PLS and CBSEM: where the bias lies!”, Journal of Business Research, Vol. 69 No. 10, pp. 3998-4010.
- Sharma, P.N., Shmueli, G., Sarstedt, M., Danks, N. and Ray, S. (2021), “Prediction-oriented model selection in partial least squares path modeling”, Decision Sciences, Vol. 52 No. 3, pp. 567-607.
- Shmueli, G. (2010), “To explain or to predict?”, Statistical Science, Vol. 25 No. 3, pp. 289-310.
- Shmueli, G. and Koppius, O.R. (2011), “Predictive analytics in information systems research”, MIS Quarterly, Vol. 35 No. 3, pp. 553-572.
- Shmueli, G., Ray, S., Velasquez Estrada, J.M. and Chatla, S.B. (2016), “The elephant in the room: predictive performance of PLS models”, Journal of Business Research, Vol. 69 No. 10, pp. 4552-4564.
- Shmueli, G., Sarstedt, M., Hair, J.F., Cheah, J.-H., Ting, H., Vaithilingam, S. and Ringle, C.M. (2019), “Predictive model assessment in PLS-SEM: guidelines for using PLSpredict”, European Journal of Marketing, Vol. 53 No. 11, pp. 2322-2347.
- Shugan, S. (2009), “Relevancy is robust prediction, not alleged realism”, Marketing Science, Vol. 28 No. 5, pp. 991-998.
- Tenenhaus, M., Tenenhaus, A. and Groenen, P.J.F. (2017), “Regularized generalized canonical correlation analysis: a framework for sequential multiblock component methods”, Psychometrika, Vol. 82 No. 3, pp. 737-777.
- Tenenhaus, M., Esposito Vinzi, V., Chatelin, Y.-M. and Lauro, C. (2005), “PLS path modeling”, Computational Statistics and Data Analysis, Vol. 48 No. 1, pp. 159-205.
- Wold, H. (1982), “Soft modeling: the basic design and some extensions”, in Jöreskog, K.G. and Wold, H. (Eds), Systems under Indirect Observation: Causality, Structure, Prediction, Part II, North Holland, Amsterdam, Netherlands, pp. 1-54.
- Yen-Tsung, H. and Ya-Ting, T. (2013), “Antecedents and consequences of brand-oriented companies”, European Journal of Marketing, Vol. 47 Nos 11/12, pp. 2020-2041.
- Danks, N.P., Sharma, P.N. and Sarstedt, M. (2020), “Model selection uncertainty and multimodel inference in partial least squares structural equation modeling (PLS-SEM)”, Journal of Business Research, Vol. 113, pp. 13-24.
- Reinartz, W., Haenlein, M. and Henseler, J. (2009), “An empirical comparison of the efficacy of covariance-based and variance-based SEM”, International Journal of Research in Marketing, Vol. 26 No. 4, pp. 332-344.
- Streukens, S. and Leroi-Werelds, S. (2016), “Bootstrapping and PLS-SEM: a step-by-step guide to get more out of your bootstrap results”, European Management Journal, Vol. 34 No. 6, pp. 618-632.
10. Lời kêu gọi hành động (CTA)
Để thấu hiểu sâu sắc hơn về các phép đo đại số của cấu trúc sai số, sơ đồ thiết kế mô phỏng chi tiết và cách áp dụng chuẩn xác hệ thống lý thuyết này vào mô hình phân tích kinh doanh của doanh nghiệp bạn, vui lòng tham khảo và phân tích kỹ văn bản nghiên cứu gốc.
Cho, G., Schlaegel, C., Hwang, H., Choi, Y., Sarstedt, M., & Ringle, C. M. (2022). Integrated generalized structured component analysis: On the use of model fit criteria in international management research. Management International Review, 62(4), 569–609.



