
Hiện tượng quá khớp (Overfitting) trong phân tích dữ liệu là tình trạng mô hình thống kê bị sai lệch do thêm quá nhiều biến không có ý nghĩa. R bình phương hiệu chỉnh (Adjusted R-square) là chỉ số thống kê đo lường độ phù hợp mô hình có tính đến số lượng biến độc lập. Nguyên nhân chính của sự sai lệch trong nghiên cứu là do R bình phương thông thường luôn tăng giả tạo khi thêm biến mới. Giải pháp tiêu chuẩn và bắt buộc là sử dụng R bình phương hiệu chỉnh để phạt các biến rác, đảm bảo tính khách quan cho kết quả phân tích. Việc hiểu rõ bản chất của chỉ số này giúp các nhà nghiên cứu bảo vệ thành công phương pháp luận trước những hội đồng khoa học khắt khe nhất.
Khái Niệm Cốt Lõi Về Độ Phù Hợp Của Mô Hình Hồi Quy
Độ phù hợp mô hình (Model fit hay Goodness of Fit – GoF) là tiêu chí tiên quyết để đánh giá tính hợp lệ của một phương trình thống kê. Trong phân tích định lượng phức tạp, GoF được đo lường qua nhiều chỉ số khác nhau (ví dụ: trong cấu trúc tuyến tính SEM thường có yêu cầu SRMR ≤ 0.08 và GFI ≥ 0.90). Tuy nhiên, đối với hồi quy tuyến tính, việc đo lường tỷ lệ phương sai của biến phụ thuộc được giải thích bởi các biến độc lập lại đóng vai trò trung tâm.
R bình phương thông thường (R-square) là gì?
R bình phương thông thường (R-square) là một đại lượng thống kê biểu diễn tỷ lệ phương sai của biến phụ thuộc được giải thích bởi biến độc lập trong mô hình. Giá trị R-square dao động từ 0 đến 1. Khi R-square càng tiến gần về 1, mô hình hồi quy giải thích dữ liệu thực tế càng tốt. Tuy nhiên, chỉ số này có một điểm yếu cơ bản toán học: nó không bao giờ giảm xuống, ngay cả khi các biến độc lập được thêm vào hoàn toàn không có cơ sở lý thuyết logic. Sự gia tăng liên tục này tạo ra một “ảo giác thống kê”, khiến nhà nghiên cứu dễ dàng lầm tưởng rằng phương trình của mình đang hoạt động hiệu quả, trong khi thực tế mô hình chỉ đang cố gắng khớp với các nhiễu ngẫu nhiên trong mẫu dữ liệu cụ thể.
R bình phương hiệu chỉnh (Adjusted R-square) là gì?
R bình phương hiệu chỉnh (Adjusted R-square) là phiên bản điều chỉnh toán học của R-square, được thiết kế đặc biệt cho mô hình hồi quy đa biến. Chỉ số này tính toán lại tỷ lệ phương sai được giải thích dựa trên số lượng biến độc lập và kích thước mẫu. Khác với R-square, R bình phương hiệu chỉnh (Adjusted R-square) chỉ tăng lên khi biến độc lập mới thêm vào thực sự cải thiện khả năng dự báo của mô hình lớn hơn mức kỳ vọng ngẫu nhiên. Nếu biến mới được thêm vào không mang lại giá trị giải thích cốt lõi nào, chỉ số này sẽ tự động giảm xuống. Điều này khiến R bình phương hiệu chỉnh trở thành một bộ lọc an toàn, ngăn chặn việc lạm dụng quá mức các biến không cần thiết nhằm thổi phồng chất lượng của báo cáo.
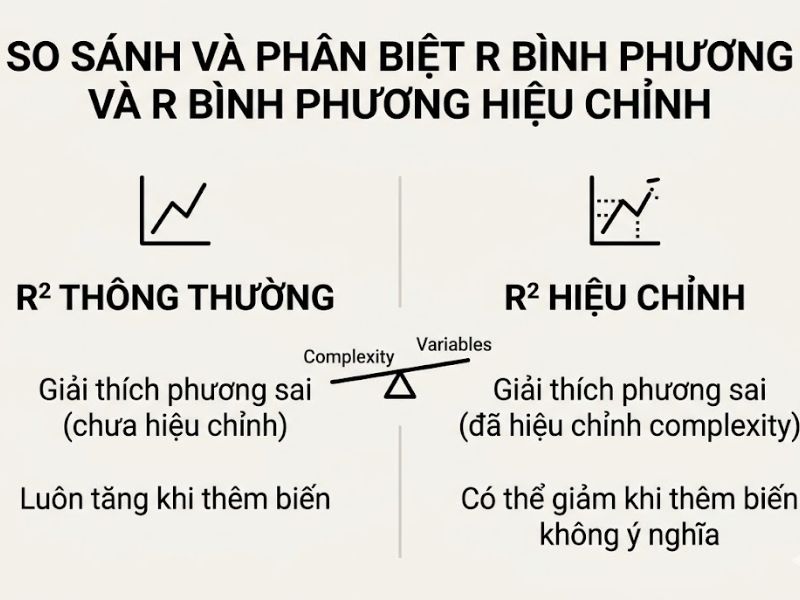
So Sánh Và Phân Biệt R Bình Phương Thông Thường Và R Bình Phương Hiệu Chỉnh
Để bảo vệ thành công phương pháp luận trước hội đồng khoa học, nhà nghiên cứu cần nắm vững sự khác biệt toán học và hành vi của hai chỉ số này trong các điều kiện kiểm định khác nhau.
Công thức toán học và sự khác biệt về tham số
Sự khác biệt căn bản nằm ở việc đưa tham số bậc tự do (Degrees of freedom) vào công thức tính toán:
- Công thức Adjusted R-square: 1 – [((1 – R²) * (n – 1)) / (n – k – 1)]
- Trong đó: n là tổng số quan sát (cỡ mẫu), k là số lượng biến độc lập.
Tham số khác biệt: Sự xuất hiện của k trong mẫu số đại diện cho một hình phạt toán học. Khi k tăng (thêm biến độc lập), mẫu số (n – k – 1) giảm, dẫn đến giá trị R bình phương hiệu chỉnh có xu hướng bị kéo xuống nếu giá trị R² ban đầu không tăng đủ lớn để bù đắp. Cụ thể, yếu tố (n – 1) / (n – k – 1) chính là hệ số hiệu chỉnh. Khi kích thước mẫu (n) rất lớn so với số lượng biến (k), hệ số này tiến gần về 1, làm cho sự chênh lệch giữa hai chỉ số không đáng kể. Tuy nhiên, với các mẫu dữ liệu nhỏ hoặc mô hình có cấu trúc cồng kềnh, hình phạt toán học này sẽ phát huy tác dụng đo lường mạnh mẽ nhất.
Chiều hướng biến thiên khi thêm biến độc lập mới
Hành vi biến thiên của hai chỉ số khi cấu trúc mô hình thay đổi được tóm tắt qua bảng dữ liệu có cấu trúc sau:
| Tiêu chí Đánh giá | R bình phương thông thường (R-square) | R bình phương hiệu chỉnh (Adjusted R-square) |
| Khi thêm biến độc lập có ý nghĩa thống kê | Tăng lên | Tăng lên |
| Khi thêm biến độc lập rác (không có ý nghĩa) | Tăng lên (hoặc giữ nguyên) | Giảm xuống |
| Ngưỡng giá trị tối thiểu | Luôn luôn ≥ 0 | Có thể nhận giá trị âm |
| Môi trường ứng dụng tối ưu | Hồi quy đơn biến (1 biến độc lập) | Hồi quy đa biến (≥ 2 biến độc lập) |
Bảng phân tích trên khẳng định rõ ràng rằng, việc sử dụng đơn lẻ R-square trong môi trường có nhiều biến số là hoàn toàn không đủ tiêu chuẩn về độ tin cậy khoa học.
Tại Sao Hội Đồng Yêu Cầu Đọc R Bình Phương Hiệu Chỉnh Trong Hồi Quy Đa Biến?
Trong các buổi bảo vệ luận án, hội đồng khoa học luôn bác bỏ việc sử dụng R-square đơn thuần cho mô hình có nhiều hơn một biến giải thích. Quyết định này dựa trên ba nguyên lý thống kê cốt lõi sau.
Lỗ hổng thao túng dữ liệu của R bình phương thông thường
Bản chất toán học của R-square tạo ra lỗ hổng cho việc “thao túng” độ phù hợp mô hình. Một nhà nghiên cứu thiếu kinh nghiệm có thể liên tục đẩy thêm các biến độc lập không liên quan vào phương trình để cố tình làm tăng R-square, tạo ra ảo giác rằng mô hình rất hoàn hảo. Sự gia tăng này là hệ quả của các nhiễu ngẫu nhiên (random noise) trùng khớp với dữ liệu mẫu, chứ không đại diện cho mối quan hệ nhân quả thực tế. Khi công bố kết quả, hành vi thao túng này sẽ làm suy giảm nghiêm trọng độ tin cậy của toàn bộ công trình, khiến các đề xuất quản trị được rút ra từ mô hình trở nên vô căn cứ và có rủi ro rất cao khi áp dụng vào thực tiễn doanh nghiệp.
Cơ chế “Hình phạt bậc tự do” (Penalty for Degrees of Freedom)
Để khắc phục lỗ hổng trên, R bình phương hiệu chỉnh (Adjusted R-square) áp dụng cơ chế “hình phạt bậc tự do”. Cụ thể:
- Mỗi biến độc lập thêm vào phương trình sẽ tiêu tốn một bậc tự do (df).
- Chỉ số này sẽ tính toán chi phí (sự mất mát bậc tự do) so với lợi ích (sự gia tăng độ giải thích).
- Nếu biến mới không mang lại năng lực dự báo vượt trội để bù đắp cho chi phí bậc tự do đã mất, hệ thống sẽ tự động trừ điểm, khiến giá trị hiệu chỉnh sụt giảm.
Cơ chế hình phạt toán học này tuân thủ chặt chẽ nguyên tắc “Dao cạo Ockham” (Occam’s razor) trong triết học khoa học: giữa hai mô hình có khả năng giải thích tương đương nhau, hội đồng khoa học sẽ luôn ưu tiên mô hình đơn giản hơn, tức là ít biến hơn. R bình phương hiệu chỉnh chính là công cụ định lượng hóa triết lý này.
Ngăn chặn hiện tượng quá khớp (Overfitting) trong mô hình
Hiện tượng overfitting xảy ra khi phương trình toán học khớp quá khít với dữ liệu mẫu hiện tại nhưng thất bại hoàn toàn khi dự báo trên một tập dữ liệu mới. Bằng cách sử dụng R bình phương hiệu chỉnh, nhà nghiên cứu thiết lập một bộ lọc kiểm soát nghiêm ngặt, tự động loại bỏ các biến làm tăng độ phức tạp của mô hình mà không đóng góp giá trị thông tin thực chất. Điều này đảm bảo tính tổng quát hóa (generalizability) của kết quả phân tích. Ngoài ra, để đánh giá năng lực dự báo ngoại mẫu của mô hình, bên cạnh độ phù hợp mô hình trong tập mẫu, các nhà phân tích nâng cao còn thường kết hợp thêm chỉ số Q² (Predictive Relevance). Sự kết hợp đồng bộ giữa việc tránh overfitting ở cấp độ mẫu và đảm bảo khả năng dự báo sẽ tạo nên một báo cáo phân tích hoàn hảo.

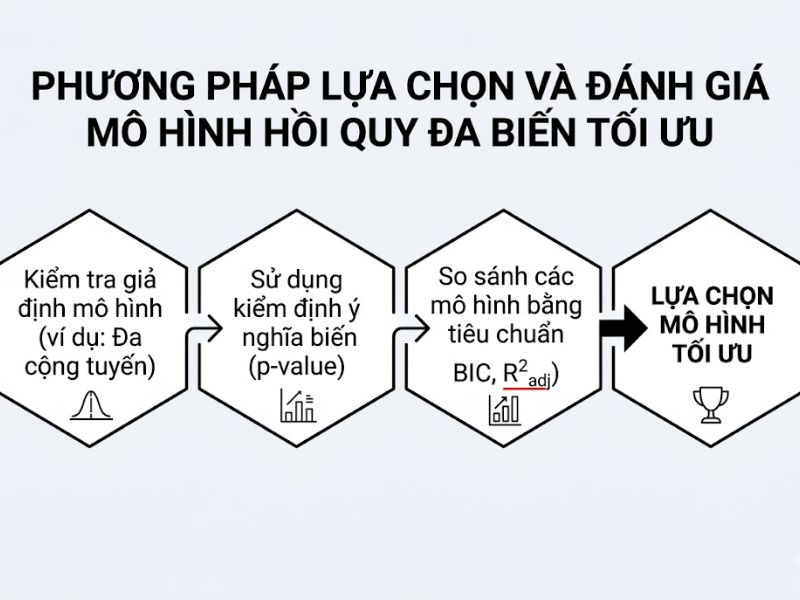
Phương Pháp Lựa Chọn Và Đánh Giá Mô Hình Hồi Quy Đa Biến Tối Ưu
Việc chỉ dựa vào R bình phương hiệu chỉnh (Adjusted R-square) là chưa đủ để khẳng định tính tối ưu của phương trình. Quy trình chuẩn khoa học yêu cầu kết hợp các chỉ số sau:
Kết hợp R bình phương hiệu chỉnh với kiểm định F (F-test)
- Chức năng của Kiểm định F: Đánh giá xem mô hình tổng thể có ý nghĩa thống kê hay không (liệu ít nhất một biến độc lập có ảnh hưởng khác 0 tới biến phụ thuộc).
- Quy trình: Chỉ khi Sig. của kiểm định F < 0.05, nhà nghiên cứu mới tiếp tục đọc và phân tích giá trị của R bình phương hiệu chỉnh. Nếu Sig. của F ≥ 0.05, mô hình tổng thể bị bác bỏ, khi đó mọi thông số đo lường độ phù hợp khác bao gồm cả R-square đều trở nên vô nghĩa.
Đánh giá giá trị P-value của từng biến độc lập
- Sàng lọc biến: Xác định mức ý nghĩa (P-value) của từng hệ số hồi quy riêng lẻ.
- Tối ưu hóa: Loại bỏ lần lượt các biến có P-value > 0.05 và chạy lại mô hình. Theo dõi sự biến thiên của R bình phương hiệu chỉnh để chốt phương trình cuối cùng ngắn gọn nhất và có khả năng giải thích tốt nhất. Quá trình này được gọi là phương pháp loại bỏ dần (Backward elimination). Cứ mỗi lần loại bỏ một biến không đạt yêu cầu, giá trị hiệu chỉnh sẽ có xu hướng nhích lên do mô hình đã trút bỏ được gánh nặng từ các biến rác, đồng thời giải phóng lại bậc tự do cho hệ thống.
Vai Trò Của R Bình Phương Hiệu Chỉnh (Adjusted R-square) Trong Nghiên Cứu Khoa Học
Tóm lại, R bình phương hiệu chỉnh (Adjusted R-square) là công cụ đo lường bắt buộc nhằm đánh giá chính xác sức mạnh giải thích của mô hình hồi quy đa biến. Nó bảo vệ tính toàn vẹn của dữ liệu bằng cách kích hoạt cơ chế hình phạt toán học đối với các biến rác, qua đó ngăn chặn trực tiếp tình trạng overfitting. Việc hiểu và áp dụng chuẩn xác chỉ số này chứng minh năng lực tư duy định lượng nghiêm túc, khách quan và là tiêu chuẩn cơ bản trong nghiên cứu khoa học hiện đại.
FAQ – Câu Hỏi Thường Gặp Về R Bình Phương Hiệu Chỉnh
R bình phương hiệu chỉnh có thể mang giá trị âm không?
Có, R bình phương hiệu chỉnh hoàn toàn có thể mang giá trị âm. Điều này xảy ra khi R bình phương thông thường của mô hình cực kỳ thấp (gần bằng 0) và số lượng biến độc lập lại quá lớn so với cỡ mẫu. Giá trị âm khẳng định mô hình hiện tại hoàn toàn vô giá trị và thực hiện dự báo tệ hơn cả việc chỉ dùng giá trị trung bình của biến phụ thuộc. Trong trường hợp này, chuyên gia phân tích dữ liệu cần xây dựng lại toàn bộ khung lý thuyết thay vì cố gắng tinh chỉnh các biến số hiện tại.
Mức R bình phương hiệu chỉnh bao nhiêu là chấp nhận được trong nghiên cứu xã hội học?
Trong lĩnh vực khoa học xã hội và hành vi, mức từ 0.3 đến 0.5 (30% – 50%) thường được hội đồng chấp nhận. Lý do là hành vi con người chịu tác động của vô số yếu tố phi tuyến tính phức tạp không thể đo lường hết. Ngược lại, trong lĩnh vực khoa học tự nhiên hoặc kỹ thuật chính xác, chỉ số này thường được yêu cầu đạt trên 0.8. Điều này khẳng định rằng không có một ngưỡng chuẩn chung nào cho tất cả; tính hợp lệ của thông số này phụ thuộc hoàn toàn vào bối cảnh nghiên cứu.
Nếu R-square và Adjusted R-square chênh lệch nhau quá lớn thì chứng tỏ điều gì?
Độ chênh lệch lớn chứng tỏ phương trình đang chứa quá nhiều biến độc lập không có ý nghĩa thống kê (biến rác). Khoảng cách này phản ánh cường độ của “hình phạt bậc tự do” đang được áp dụng. Để khắc phục, nhà nghiên cứu phải kiểm tra lại P-value và tiến hành loại bỏ các biến không đạt chuẩn để thu hẹp khoảng cách này. Đồng thời, sự chênh lệch lớn cũng có thể là dấu hiệu cảnh báo kích thước mẫu (n) đang quá nhỏ so với số lượng biến số được đưa vào ước lượng. Việc tăng cỡ mẫu khảo sát là một giải pháp hữu hiệu trong tình huống này.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



