
Sai lệch dữ liệu thống kê trong đánh giá định lượng là một vấn đề nghiêm trọng, làm giảm trực tiếp hệ số tin cậy của mô hình phân tích. Lấy mẫu phân tầng là kỹ thuật lấy mẫu xác suất phân chia tổng thể thành các nhóm đồng nhất (tầng) và trích xuất ngẫu nhiên từ mỗi nhóm. Nguyên nhân chính dẫn đến sai số nghiên cứu là sự thiếu hụt đại diện của các nhóm thiểu số (nhóm yếu thế) khi thu thập dữ liệu. Giải pháp nhanh nhất là phân bổ kích thước mẫu theo tỷ lệ tương ứng của các tầng để đảm bảo độ chính xác cho toàn bộ dự án.

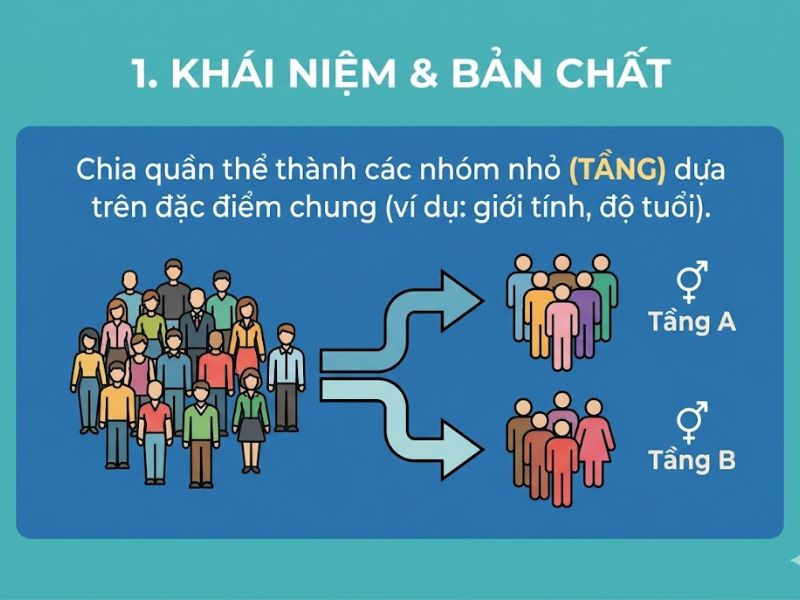
1. Khái niệm và Bản chất của Lấy mẫu phân tầng
1.1. Lấy mẫu phân tầng (Stratified Sampling) là gì?
Lấy mẫu phân tầng là một phương pháp lấy mẫu xác suất nền tảng trong lĩnh vực thống kê học và nghiên cứu định lượng. Kỹ thuật này yêu cầu nhà nghiên cứu tiến hành chia toàn bộ đối tượng khảo sát thành các phân nhóm con riêng biệt, hoàn toàn không trùng lặp (được gọi là các tầng). Ngay sau khi phân chia, một quy trình chọn mẫu ngẫu nhiên sẽ được thực thi độc lập bên trong từng tầng. Mục đích cốt lõi của việc lấy mẫu phân tầng là đảm bảo tất cả các phân nhóm, đặc biệt là các nhóm có tỷ trọng thấp, đều có cơ hội xuất hiện trong mẫu đo lường cuối cùng một cách công bằng, có hệ thống và đúng với cấu trúc thực tế.
1.2. Các thuật ngữ cốt lõi (Tổng thể, Tầng/Strata, Mẫu)
Để áp dụng cấu trúc phương pháp luận này một cách chính xác, nhà nghiên cứu cần nắm vững các thuật ngữ học thuật cơ bản sau:
- Tổng thể nghiên cứu (Population): Tập hợp bao gồm toàn bộ các phần tử, cá nhân hoặc đơn vị đo lường đáp ứng đầy đủ các tiêu chuẩn sàng lọc của đề tài nghiên cứu.
- Tầng (Strata): Các nhóm con được tách ra từ tổng thể. Nguyên tắc phân chia bắt buộc là các đơn vị bên trong một tầng phải đạt độ đồng nhất cao (Homogeneous) về một đặc điểm cụ thể, trong khi các tầng khác nhau phải có tính dị chất rõ rệt (Heterogeneous).
- Mẫu (Sample): Tập hợp các phần tử cuối cùng được trích xuất từ tất cả các tầng. Đây là nguồn dữ liệu trực tiếp để tiến hành thu thập, đo lường và đưa vào phần mềm xử lý thống kê.
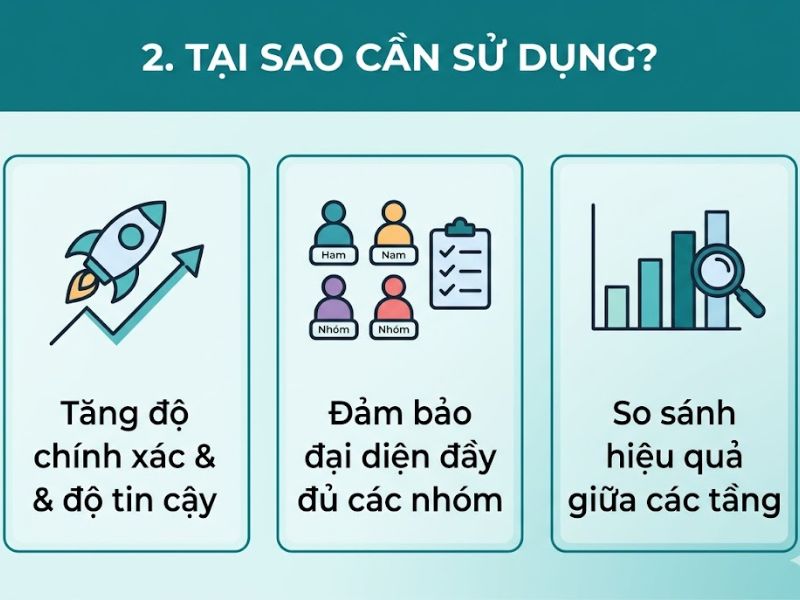
2. Tại sao cần sử dụng phương pháp Lấy mẫu phân tầng?
2.1. Đảm bảo tính đại diện cho các nhóm thiểu số (Nhóm yếu thế)
Trong một quần thể không đồng nhất, các nhóm yếu thế hoặc nhóm có tỷ trọng thấp rất dễ bị loại bỏ hoàn toàn nếu nhà nghiên cứu chỉ áp dụng kỹ thuật lấy mẫu ngẫu nhiên đơn giản (Simple Random Sampling). Lấy mẫu phân tầng giải quyết triệt để vấn đề này bằng cách thiết lập một hạn mức thu thập bắt buộc cho từng nhóm cấu thành. Khung phân tích này giúp cấu trúc mẫu phản ánh chính xác cấu trúc vi mô của tổng thể thực tế, ngăn chặn tình trạng dữ liệu bị chi phối hoàn toàn bởi nhóm chiếm đa số.
2.2. Giảm thiểu sai số chọn mẫu (Sampling Error)
Do sự phân chia các phần tử thành các tầng đồng nhất, phương sai bên trong từng nhóm được kiểm soát và giảm xuống mức thấp nhất. Sự đồng nhất cao trong nội bộ tầng giúp giảm thiểu sai số chọn mẫu một cách đáng kể. Dữ liệu có tính đại diện cao sẽ làm nền tảng vững chắc cho các bước đánh giá mô hình phía sau. Cụ thể, trong các kiểm định thống kê chuyên sâu, các chỉ số đánh giá độ phù hợp của mô hình như R², mức độ phù hợp tổng thể (GoF), Q², hoặc các bộ chỉ số đo lường khắt khe như SRMR ≤ 0.08 và GFI ≥ 0.90 sẽ đạt được mức độ tin cậy thực tế cao hơn, tránh hiện tượng phù hợp giả tạo do thiên lệch dữ liệu.
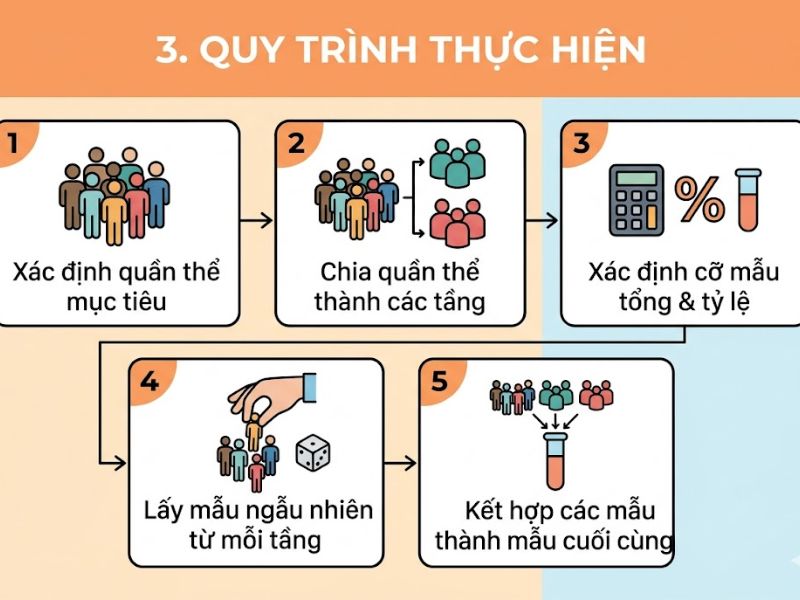
3. Quy trình thực hiện Lấy mẫu phân tầng chuẩn khoa học
3.1. Bước 1: Xác định tổng thể nghiên cứu và tiêu chí phân tầng
Xác định chính xác quy mô, ranh giới và khung lấy mẫu của đối tượng mục tiêu. Tiêu chí để phân tầng phải là các biến số có mối tương quan logic và tác động mạnh mẽ nhất đến mục tiêu nghiên cứu. Ví dụ, trong nghiên cứu hành vi tiêu dùng, biến số phân tầng thường là giới tính, phân khúc độ tuổi, mức thu nhập hàng tháng hoặc khu vực địa lý sinh sống.
3.2. Bước 2: Phân chia tổng thể thành các tầng (Strata) độc lập
Tiến hành phân loại toàn bộ danh sách phần tử của tổng thể vào các tầng đã xác định. Nguyên tắc toán học bắt buộc là các tầng phải bao quát toàn bộ tổng thể (Collectively Exhaustive) và tuyệt đối không có sự giao thoa (Mutually Exclusive). Một phần tử chỉ được phép xuất hiện tại một tầng duy nhất để tránh tình trạng trùng lặp dữ liệu (Double counting).
3.3. Bước 3: Xác định kích thước mẫu và phương pháp phân bổ (Tỷ lệ vs. Không tỷ lệ)
- Phân bổ theo tỷ lệ (Proportionate allocation): Kích thước mẫu của từng tầng được tính toán dựa trên tỷ trọng thực tế của tầng đó trong cấu trúc tổng thể nghiên cứu. Đây là phương pháp phổ biến nhất giúp tối ưu hóa tính đại diện.
- Phân bổ không theo tỷ lệ (Disproportionate allocation): Được áp dụng khi một tầng cụ thể có quy mô quá nhỏ nhưng lại đóng vai trò là trọng tâm nghiên cứu. Nhà phân tích sẽ chủ động tăng kích thước mẫu của tầng này để đảm bảo dữ liệu đủ lớn cho các phép kiểm định thống kê độc lập, sau đó sử dụng các hệ số trọng số (Weighting) để điều chỉnh lại khi phân tích chung toàn mô hình.
3.4. Bước 4: Trích xuất ngẫu nhiên trong từng tầng
Sau khi chốt được số lượng phần tử cần lấy ở mỗi tầng (chỉ tiêu mẫu), nhà nghiên cứu tiến hành bốc thăm ngẫu nhiên. Trong nghiên cứu hiện đại, bước này thường được thực hiện thông qua hàm tạo số ngẫu nhiên (Random Number Generator) trên các phần mềm thống kê như SPSS, R, hoặc Python để loại bỏ hoàn toàn yếu tố chủ quan của người thu thập.
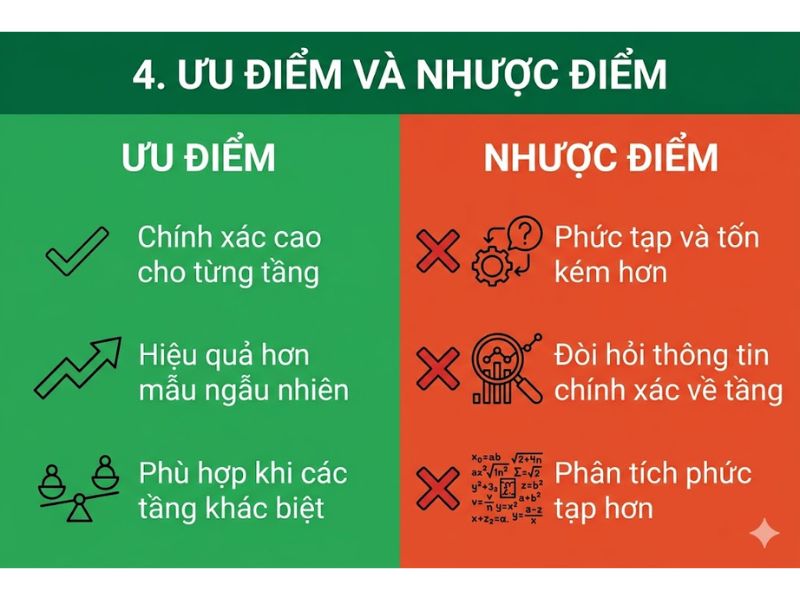
4. Đánh giá Ưu điểm và Nhược điểm của Lấy mẫu phân tầng
4.1. Ưu điểm trong phân tích thống kê
- Tối ưu hóa tính đại diện: Cung cấp tính đại diện hoàn hảo cho các tổng thể có cấu trúc phân mảnh phức tạp, đảm bảo không bỏ sót các nhóm dữ liệu hẹp.
- Hỗ trợ phân tích chéo: Cho phép nhà quản trị hoặc nhà nghiên cứu thực hiện các phép kiểm định trung bình (T-test, ANOVA) giữa các tầng với độ tin cậy và sự toàn vẹn dữ liệu cao.
- Nâng cao độ chính xác: Cải thiện phương sai và độ tin cậy của kết quả định lượng so với các kỹ thuật lấy mẫu xác suất khác khi sử dụng cùng một mức kích thước mẫu.
4.2. Hạn chế và tính phức tạp trong triển khai thực tế
- Đòi hỏi dữ liệu nền tảng: Yêu cầu nhà nghiên cứu bắt buộc phải có thông tin phân loại và khung lấy mẫu (Sampling frame) hoàn chỉnh của toàn bộ tổng thể trước khi thực hiện chia tầng.
- Tiêu hao nguồn lực: Tiêu tốn chi phí và thời gian thiết kế công cụ đo lường lớn hơn, đặc biệt trong khâu tiếp cận chính xác đối tượng thuộc các tầng khó tìm.
- Xử lý hậu kỳ phức tạp: Gây ra sự phức tạp lớn trong việc phân tích trọng số dữ liệu nếu thiết kế nghiên cứu bắt buộc phải áp dụng phương pháp phân bổ không theo tỷ lệ.
5. So sánh Lấy mẫu phân tầng và Lấy mẫu ngẫu nhiên đơn giản
Để làm rõ sự khác biệt về mặt bản chất phương pháp luận và hiệu quả thu thập, dưới đây là bảng so sánh phân tích chi tiết:
| Tiêu chí phân tích | Lấy mẫu phân tầng (Stratified Sampling) | Lấy mẫu ngẫu nhiên đơn giản (Simple Random Sampling) |
| Bản chất kỹ thuật | Phân chia tổng thể thành các tầng đồng nhất, sau đó rút ngẫu nhiên phần tử từ nội bộ mỗi tầng. | Rút ngẫu nhiên các phần tử trực tiếp từ toàn bộ danh sách tổng thể nghiên cứu. |
| Tính đại diện dữ liệu | Đảm bảo tính đại diện tuyệt đối cho mọi phân nhóm, triệt tiêu rủi ro bỏ sót nhóm thiểu số. | Phụ thuộc hoàn toàn vào xác suất, rủi ro cao trong việc bỏ sót các nhóm nhỏ nếu quy mô mẫu hạn chế. |
| Yêu cầu dữ liệu đầu vào | Bắt buộc phải có thông tin nhân khẩu học/phân loại chi tiết của toàn bộ danh sách phần tử. | Chỉ cần danh sách định danh hoặc số thứ tự tổng hợp của các phần tử là đủ điều kiện thực hiện. |
| Kiểm soát sai số (Error) | Sai số chọn mẫu được đưa về mức thấp nhất do triệt tiêu phương sai giữa các nhóm (chỉ còn phương sai nội tầng). | Sai số chọn mẫu thường cao hơn khi áp dụng cho các tổng thể mang tính dị chất lớn. |
| Mức độ phức tạp thực thi | Mức độ phức tạp cao, yêu cầu tính toán logic tỷ lệ, gán trọng số và quản lý ranh giới phân tầng khắt khe. | Mức độ phức tạp thấp, tốc độ thực thi nhanh chóng thông qua các phần mềm chọn số ngẫu nhiên. |
6. Ví dụ ứng dụng Lấy mẫu phân tầng trong thực tiễn
Một ban quản lý trường đại học cần thực hiện khảo sát đánh giá mức độ hài lòng về chất lượng cơ sở vật chất từ tổng thể 10.000 sinh viên. Cấu trúc tổng thể này được phân bổ không đồng đều theo khóa học: 4.000 sinh viên năm nhất, 3.000 sinh viên năm hai, 2.000 sinh viên năm ba và 1.000 sinh viên năm cuối.
Hội đồng nghiên cứu quyết định kích thước mẫu tối ưu cho mô hình là 1.000 sinh viên. Nếu áp dụng thuật toán lấy mẫu ngẫu nhiên đơn giản, có khả năng nhóm sinh viên năm cuối sẽ không được chọn đủ để mang ý nghĩa thống kê. Do đó, kỹ thuật lấy mẫu phân tầng theo tỷ lệ được áp dụng. Tính toán phân bổ số lượng mẫu tương ứng cần trích xuất sẽ là:
- Tầng sinh viên năm 1: (4.000 / 10.000) × 1.000 = 400 phần tử.
- Tầng sinh viên năm 2: (3.000 / 10.000) × 1.000 = 300 phần tử.
- Tầng sinh viên năm 3: (2.000 / 10.000) × 1.000 = 200 phần tử.
- Tầng sinh viên năm cuối: (1.000 / 10.000) × 1.000 = 100 phần tử.
Sau khi xác định hạn ngạch, ban quản lý dùng phần mềm quay số ngẫu nhiên mã sinh viên nội bộ trong từng khối lớp để chọn đúng số lượng trên. Cách làm này là minh chứng thực tế cho việc đảm bảo dữ liệu phản ánh chính xác cấu trúc sinh viên toàn trường, giúp báo cáo đánh giá cuối cùng đạt độ khách quan tối đa.
7. Kết luận
Lấy mẫu phân tầng đóng vai trò là một trong những cột mốc thiết kế phương pháp luận quan trọng nhất trong việc củng cố tính vững chắc của phân tích định lượng. Nó giải quyết bài toán sai lệch dữ liệu bằng cách ép buộc cấu trúc mẫu phải tuân thủ nghiêm ngặt tỷ trọng của tất cả các nhóm đặc thù trong thực tế. Khả năng thiết lập tính đại diện cao giúp các chỉ số kiểm định thống kê đạt được độ chuẩn xác, giảm thiểu sai số đo lường. Việc nắm vững từ khâu định vị tiêu chí phân tầng, tính toán kích thước mẫu, cho đến trích xuất dữ liệu là quy chuẩn bắt buộc đối với mọi quy trình thực thi nghiên cứu khoa học chuyên nghiệp và đáng tin cậy.
8. Câu hỏi thường gặp (FAQ)
Khi nào không nên sử dụng Lấy mẫu phân tầng?
Phương pháp này không nên áp dụng khi tổng thể nghiên cứu mang tính đồng nhất tuyệt đối về đặc tính khảo sát. Nếu các cá thể trong quần thể không có sự biến thiên lớn, việc ép buộc chia tầng không có ý nghĩa giảm sai số mà chỉ làm tiêu tốn thời gian, gia tăng chi phí thực địa và phức tạp hóa quá trình phân tích số liệu.
Tiêu chí nào dùng để chia “tầng” hiệu quả nhất?
Tiêu chí phân chia tầng hiệu quả nhất phải là biến độc lập có khả năng dự báo hoặc có mức độ ảnh hưởng mạnh mẽ nhất đến biến phụ thuộc trong mô hình định lượng. Tính hiệu quả được đo lường khi biến số đó chia tổng thể thành các tầng mà đặc tính bên trong mỗi tầng là đồng nhất nhất (phương sai nội bộ thấp), và sự khác biệt giữa các tầng là lớn nhất (phương sai giữa các nhóm cao).
Làm thế nào để xử lý khi một “tầng” có kích thước quá nhỏ trong thực tế?
Khi một tầng có quy mô tổng thể cực kỳ nhỏ nhưng mang tính chất trọng yếu (ví dụ: nhóm chuyên gia cấp cao trong công ty), nhà nghiên cứu cần sử dụng kỹ thuật phân bổ không theo tỷ lệ (Disproportionate Stratified Sampling). Bằng cách chủ động lấy toàn bộ (Over-sampling) hoặc lấy số lượng lớn hơn mức tỷ lệ tự nhiên của nhóm này, báo cáo sẽ có đủ lượng quan sát tối thiểu để chạy các kiểm định thống kê, sau đó áp dụng trọng số nghịch đảo (Inverse weighting) khi gộp dữ liệu chung.




