
Vấn đề khó khăn khi khảo sát một tổng thể nghiên cứu quá rộng là sự hao tổn chi phí và thời gian thu thập dữ liệu. Lấy mẫu cụm là phương pháp chia tổng thể thành các nhóm (cụm) tự nhiên, sau đó chọn ngẫu nhiên một số cụm để tiến hành khảo sát toàn bộ phần tử bên trong. Nguyên nhân chính gây lãng phí nguồn lực là sự phân tán về mặt địa lý của dân số. Giải pháp hiệu quả nhất là áp dụng phương pháp lấy mẫu cụm nhằm tối ưu hóa chi phí trong khi vẫn duy trì được tính chính xác của mẫu đại diện. Quá trình này đòi hỏi sự am hiểu sâu sắc về phương pháp luận để đảm bảo các suy luận thống kê sau đó không bị chệch hướng.
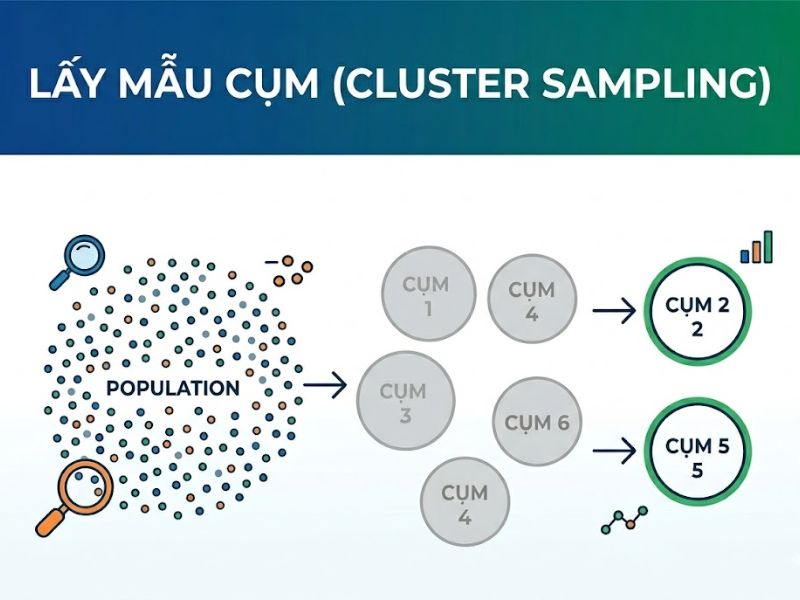
1. Giới Thiệu Tổng Quan Về Lấy Mẫu Cụm Trong Nghiên Cứu Khoa Học
Khi tiến hành khảo sát trên một tổng thể nghiên cứu (Population) có quy mô dân số rộng, các nhà nghiên cứu thường đối mặt với thách thức lớn về việc phân bổ ngân sách và nhân sự. Đặc biệt trong các nghiên cứu cấp quốc gia hoặc khu vực, việc xây dựng một khung lấy mẫu (sampling frame) chi tiết đến từng cá nhân là điều gần như bất khả thi. Nếu áp dụng lấy mẫu ngẫu nhiên đơn giản, các cá thể được chọn có thể nằm rải rác ở nhiều khu vực địa lý cách xa nhau, gây cản trở cho quá trình thu thập số liệu thực tế. Điều này không chỉ làm tăng độ trễ của dự án mà còn tạo ra rào cản lớn về mặt quản trị rủi ro thực địa.
Trong các phương pháp nghiên cứu khoa học, lấy mẫu cụm (Cluster sampling) được phát triển để giải quyết trực tiếp bài toán này. Phương pháp này tập trung vào việc khoanh vùng các đơn vị địa lý hoặc tổ chức thành các nhóm có sẵn, qua đó giúp nhà nghiên cứu tiếp cận dữ liệu một cách tập trung, tiết kiệm chi phí di chuyển và thời gian thực địa. Bằng cách thao tác trên các đơn vị cụm thay vì đơn vị cá thể, nhà quản trị dự án có thể phân bổ nguồn lực đồng đều và dễ dàng kiểm soát chất lượng bảng hỏi. Bài viết này sẽ phân tích chi tiết khái niệm lấy mẫu cụm, quy trình thực hiện, đồng thời phân biệt lấy mẫu cụm và lấy mẫu phân tầng một cách rõ ràng dựa trên các tiêu chí thống kê học.
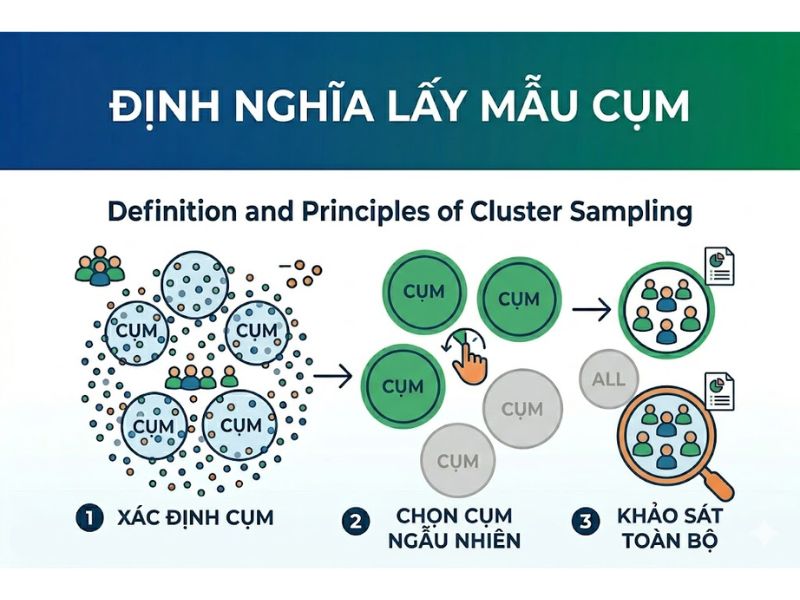
2. Định Nghĩa Và Nguyên Tắc Của Phương Pháp Lấy Mẫu Cụm (Cluster Sampling)
2.1. Khái niệm cốt lõi về lấy mẫu cụm
Lấy mẫu cụm là một kỹ thuật lấy mẫu xác suất, trong đó toàn bộ tổng thể nghiên cứu được chia thành nhiều nhóm nhỏ lẻ, được gọi là các “cụm” (clusters). Các cụm này thường được hình thành dựa trên các ranh giới tự nhiên đã tồn tại, chẳng hạn như khu vực địa lý (quận, huyện, tỉnh thành), trường học, hoặc bệnh viện. Sau khi phân chia, nhà nghiên cứu sẽ sử dụng kỹ thuật lấy mẫu ngẫu nhiên (Random sampling) để chọn ra một số lượng cụm nhất định và tiến hành khảo sát toàn bộ các cá thể thuộc các cụm đã được chọn đó. Khác với các kỹ thuật phi xác suất, mỗi cụm trong danh sách khung lấy mẫu đều có một xác suất được chọn khác không (non-zero probability), đảm bảo tính minh bạch của phương pháp khoa học.
2.2. Đặc điểm của một cụm tiêu chuẩn
Theo nguyên tắc của thống kê, một cụm tiêu chuẩn trong phương pháp lấy mẫu cụm phải đáp ứng các tính chất sau:
- Tính không đồng nhất bên trong cụm (Heterogeneous within): Mỗi cụm phải là một hình ảnh thu nhỏ của toàn bộ tổng thể nghiên cứu. Điều này có nghĩa là các phần tử bên trong một cụm phải có sự đa dạng hóa cao, mang đầy đủ các đặc điểm của dân số mục tiêu. Sự phân tán dữ liệu bên trong cụm càng lớn thì cụm đó càng phản ánh chân thực hình ảnh của tổng thể.
- Tính đồng nhất giữa các cụm (Homogeneous between): Các cụm phải có cấu trúc và đặc điểm tương đương nhau. Cụm A và Cụm B phải có sự phân bổ đặc tính nội tại tương đối giống nhau, tạo thành các cụm đồng nhất về mặt quy mô và cơ cấu chung. Nếu các cụm có sự chênh lệch quá lớn về phương sai, tính đại diện của mẫu sẽ bị suy giảm nghiêm trọng.
2.3. Các phân loại cơ bản
Ứng dụng lấy mẫu cụm trong thực tiễn được chia thành ba loại hình cơ bản dựa trên số lượng giai đoạn chọn lọc nhằm đáp ứng các bài toán nghiên cứu có mức độ phức tạp khác nhau:
- Lấy mẫu cụm một giai đoạn (Single-stage cluster sampling): Chọn ngẫu nhiên một số cụm và tiến hành khảo sát tất cả các phần tử bên trong cụm đó. Phương pháp này phù hợp khi quy mô của mỗi cụm không quá lớn và chi phí khảo sát trên mỗi cá thể ở mức thấp.
- Lấy mẫu cụm hai giai đoạn (Two-stage cluster sampling): Sau khi chọn ra các cụm ngẫu nhiên, nhà nghiên cứu tiếp tục thực hiện lấy mẫu ngẫu nhiên đơn giản đối với các phần tử bên trong cụm đó, thay vì khảo sát toàn bộ. Điều này giúp tối ưu hóa thêm một bước nữa nếu số lượng phần tử trong một cụm được chọn vượt quá năng lực khảo sát.
- Lấy mẫu cụm đa giai đoạn (Multi-stage cluster sampling): Quy trình phân chia cụm lặp lại nhiều lần. Ví dụ: Từ Quốc gia -> Chọn Tỉnh -> Chọn Huyện -> Chọn Xã -> Lấy mẫu ngẫu nhiên cá nhân tại các xã đã chọn. Kỹ thuật này là tiêu chuẩn vàng trong các cuộc tổng điều tra dân số quốc gia.
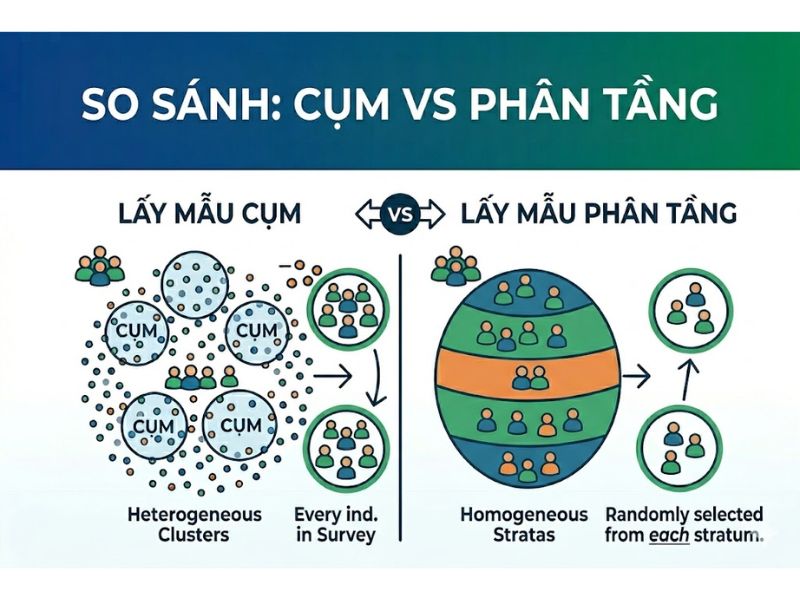
3. Phân Biệt Lấy Mẫu Cụm Và Lấy Mẫu Phân Tầng (Stratified Sampling)
Việc nhầm lẫn giữa hai kỹ thuật này thường xuyên xảy ra do cả hai đều yêu cầu chia nhỏ tổng thể nghiên cứu. Bảng cấu trúc dưới đây trực tiếp phân biệt lấy mẫu cụm và lấy mẫu phân tầng thông qua các biến số đo lường học thuật, giúp các nghiên cứu sinh có cái nhìn hệ thống và chính xác nhất:
| Tiêu chí phân tích | Lấy mẫu cụm (Cluster Sampling) | Lấy mẫu phân tầng (Stratified Sampling) |
| Cơ sở phân chia nhóm | Dựa trên ranh giới tự nhiên có sẵn (địa lý, tổ chức). | Dựa trên đặc điểm nhận dạng chủ đích (giới tính, thu nhập). |
| Tính chất bên trong nhóm | Không đồng nhất (Đa dạng đặc điểm). | Đồng nhất (Có chung một đặc điểm cụ thể). |
| Tính chất giữa các nhóm | Cụm đồng nhất (Các cụm giống nhau về cấu trúc). | Phân tầng không đồng nhất (Các tầng khác biệt nhau). |
| Cách thức chọn mẫu | Chọn một số cụm ngẫu nhiên -> Khảo sát toàn bộ hoặc một phần cụm đó. | Chọn ngẫu nhiên một số phần tử từ tất cả các tầng. |
| Mục tiêu tối ưu | Tối ưu hóa chi phí và nguồn lực triển khai. | Nâng cao độ chính xác và tính đại diện của từng nhóm phụ. |
3.1. Điểm khác biệt về cơ sở phân chia nhóm
Trong khi lấy mẫu cụm phụ thuộc vào các ranh giới tự nhiên (như cấu trúc hành chính), lấy mẫu phân tầng yêu cầu nhà nghiên cứu tự thiết lập các tầng dựa trên các biến số nhân khẩu học cụ thể. Do đó, việc thiết lập cụm tốn ít thời gian xử lý dữ liệu đầu vào hơn so với thiết lập tầng. Sự phân định tự nhiên này làm giảm bớt gánh nặng về việc phải thu thập thông tin cá nhân của toàn bộ dân số trước khi tiến hành chọn mẫu.
3.2. Điểm khác biệt về tính chất bên trong và bên ngoài nhóm
Lấy mẫu cụm đòi hỏi sự đa dạng hóa cá thể ở bên trong mỗi nhóm, trong khi lấy mẫu phân tầng tập hợp các cá thể có đặc điểm tương đồng vào chung một nhóm. Lấy mẫu phân tầng tạo ra sự phân tầng không đồng nhất giữa các nhóm (ví dụ: nhóm thu nhập cao khác biệt hoàn toàn với nhóm thu nhập thấp). Chính sự trái ngược về lý thuyết tổ chức nội bộ này quyết định tính ứng dụng riêng biệt của từng phương pháp.
3.3. Điểm khác biệt về cách thức chọn mẫu cuối cùng
Lấy mẫu cụm chỉ thực hiện khảo sát trên một số lượng nhóm hữu hạn được bốc thăm. Ngược lại, lấy mẫu phân tầng bắt buộc phải trích xuất mẫu từ 100% các nhóm đã được phân chia, đảm bảo không có bất kỳ nhóm đặc thù nào bị bỏ sót trong mẫu đại diện cuối cùng. Việc bỏ qua bất kỳ một tầng nào trong lấy mẫu phân tầng sẽ làm hỏng hoàn toàn thiết kế nghiên cứu, trong khi lấy mẫu cụm xem việc bỏ qua các cụm không được chọn là điều hiển nhiên của xác suất.
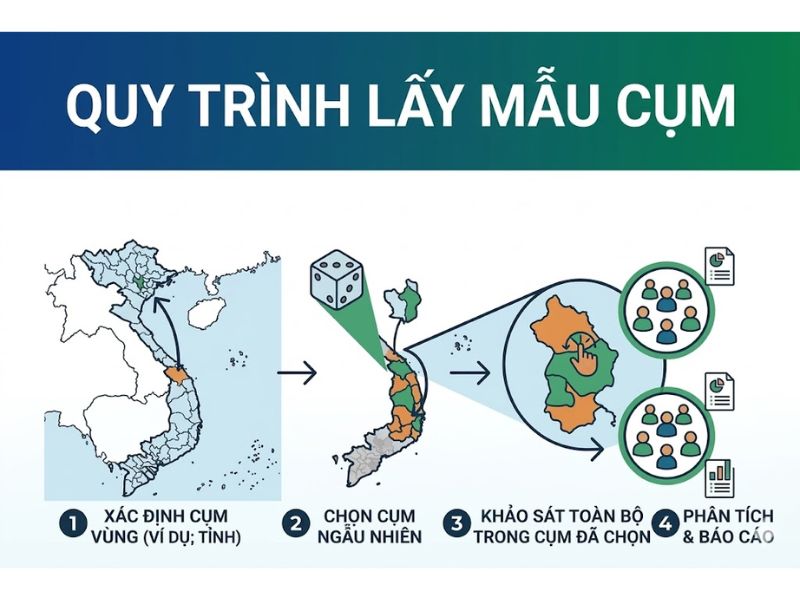
4. Phương Pháp Và Quy Trình Áp Dụng Lấy Mẫu Cụm Khi Dân Số Quá Rộng
Khi tiến hành khảo sát hành vi tiêu dùng của toàn bộ cư dân tại một khu vực có dân số rộng (ví dụ: Thành phố Hồ Chí Minh), quy trình thiết lập ứng dụng lấy mẫu cụm được thực hiện theo nguyên tắc chuẩn hóa như sau:
4.1. Bước 1: Xác định tổng thể và định nghĩa các cụm địa lý
Nhà nghiên cứu xác định khung lấy mẫu là danh sách 22 Quận/Huyện tự nhiên của Thành phố. Mỗi Quận/Huyện được định nghĩa là một “cụm”. Mỗi cụm này chứa đựng sự đa dạng về nhân khẩu học, thu nhập và tuổi tác (tính không đồng nhất bên trong cụm). Khâu định nghĩa này phải dựa trên cơ sở dữ liệu hành chính hiện hành để tránh tình trạng các cụm bị trùng lặp phần tử (mutually exclusive) hoặc bỏ sót phần tử (collectively exhaustive).
4.2. Bước 2: Lựa chọn ngẫu nhiên các cụm đại diện
Sử dụng phần mềm thống kê hoặc bảng số ngẫu nhiên để tiến hành lấy mẫu ngẫu nhiên (Random sampling). Thay vì phải di chuyển khắp 22 quận, nhà nghiên cứu quyết định chọn ngẫu nhiên đúng 3 Quận (ví dụ: Quận 1, Quận 7, Huyện Bình Chánh) để làm mẫu đại diện cho tổng thể nghiên cứu. Trong thực tế hàn lâm, người ta thường áp dụng kỹ thuật lấy mẫu tỷ lệ thuận với quy mô (Probability Proportional to Size – PPS) để đảm bảo các cụm có dân số đông hơn sẽ có cơ hội được chọn cao hơn.
4.3. Bước 3: Thu thập dữ liệu toàn bộ phần tử
Tại 3 quận đã được lựa chọn, đội ngũ nghiên cứu tiến hành phân phát bảng hỏi hoặc phỏng vấn toàn bộ các hộ gia đình nằm trong danh sách mẫu (nếu áp dụng lấy mẫu cụm một giai đoạn), hoặc tiếp tục lấy mẫu ngẫu nhiên cấp phường/xã bên trong 3 quận này (nếu áp dụng lấy mẫu cụm hai giai đoạn). Quy trình này cung cấp bộ dữ liệu đầy đủ mà vẫn cắt giảm được 80% quãng đường di chuyển. Số liệu thô sau đó sẽ được làm sạch, mã hóa và đưa vào các phần mềm như SPSS hoặc AMOS để chuẩn bị cho giai đoạn kiểm định mô hình.
5. Ưu Điểm Và Hạn Chế Của Lấy Mẫu Cụm (Cluster Sampling)
5.1. Lợi ích về tối ưu hóa nguồn lực
Lấy mẫu cụm là phương án giải quyết trực tiếp bài toán kinh tế trong phương pháp nghiên cứu khoa học. Bằng việc giới hạn phạm vi thu thập dữ liệu tại một số cụm địa lý nhất định, nghiên cứu sinh tiết kiệm đáng kể chi phí logistics, thời gian tổ chức khảo sát và ngân sách quản trị thực địa. Phương pháp này cung cấp tính khả thi cao nhất cho các dự án nghiên cứu có nguồn tài trợ hạn hẹp nhưng yêu cầu dữ liệu quy mô vùng.
5.2. Rủi ro về sai số chọn mẫu (Sampling Error) và Xử lý Dữ liệu
Hạn chế lớn nhất của lấy mẫu cụm là nguy cơ gia tăng sai số chọn mẫu (Sampling error) so với lấy mẫu ngẫu nhiên đơn giản hoặc phân tầng. Hiện tượng này thường được đo lường bằng hệ số hiệu ứng thiết kế (Design Effect – Deff). Nếu các cụm được chọn ngẫu nhiên có đặc thù quá khác biệt và không mang đủ tính chất của tổng thể (ví dụ: vô tình chọn trúng 3 cụm đều là khu đô thị cao cấp, bỏ sót khu vực nông thôn), kết quả dữ liệu sẽ bị chệch, làm giảm giá trị của mẫu đại diện.
Đặc biệt, khi sử dụng dữ liệu từ lấy mẫu cụm để đánh giá các mô hình phương trình cấu trúc (SEM), nhà nghiên cứu cần chú ý đến mức độ phù hợp của mô hình (Goodness of Fit – GoF). Dữ liệu thu thập cần đáp ứng các ngưỡng tiêu chuẩn khắt khe để được công nhận tính hợp lệ. Cụ thể, khi biểu diễn qua các chỉ số thống kê (được chuẩn hóa mã Unicode để tương thích tuyệt đối mọi nền tảng tài liệu), các giá trị như hệ số xác định R², giá trị năng lực dự báo Q² cần đạt ngưỡng tiêu chuẩn của ngành. Đồng thời, các chỉ số độ chênh lệch mô hình cần đảm bảo như SRMR ≤ 0.08 và chỉ số mức độ phù hợp GFI ≥ 0.90. Nếu sai số chọn mẫu do chia cụm quá lớn, dữ liệu sẽ bị nhiễu, làm cho R² sụt giảm và SRMR vượt quá ngưỡng 0.08, dẫn đến việc mô hình lý thuyết bị bác bỏ.
6. Kết Luận Về Vai Trò Của Lấy Mẫu Cụm Trong Ra Quyết Định Khoa Học
Lấy mẫu cụm (Cluster sampling) đóng vai trò thiết yếu trong việc thiết kế phương pháp luận đối với các quần thể dân cư quy mô lớn. Phương pháp này cung cấp một công cụ thực tế giúp cân bằng giữa độ chính xác của dữ liệu và giới hạn về nguồn lực ngân sách. Khi nhà nghiên cứu nắm vững các nguyên tắc cốt lõi để duy trì sự đa dạng hóa bên trong cụm, rủi ro về sai số thống kê sẽ được kiểm soát ở mức tối thiểu. Việc phân định rạch ròi quy trình ứng dụng và am hiểu cặn kẽ bản chất phương pháp học thuật này chính là cơ sở vững chắc để xây dựng các bài toán phân tích định lượng chuẩn xác và nâng cao hàm lượng tri thức trongnghiên cứu khoa học. Sự chặt chẽ trong khâu chọn mẫu là tiền đề bắt buộc để mọi chỉ số kiểm định (từ R² đến GFI) sau này phản ánh đúng thực trạng khách quan.
7. Câu Hỏi Thường Gặp (FAQ) Về Khái Niệm Lấy Mẫu Cụm
Khi nào nên ưu tiên lấy mẫu cụm thay vì lấy mẫu ngẫu nhiên đơn giản?
Nên ưu tiên sử dụng lấy mẫu cụm khi tổng thể nghiên cứu có quy mô quá lớn và phân tán trên một khu vực địa lý diện rộng, khiến việc tiếp cận từng cá thể theo cách ngẫu nhiên đơn giản trở nên bất khả thi về mặt chi phí và thời gian. Sự tập trung về mặt không gian của cụm là giải pháp duy nhất để hiện thực hóa việc lấy mẫu diện rộng mà không làm gián đoạn tiến độ dự án.
Việc chọn sai cụm đại diện sẽ ảnh hưởng thế nào đến kết quả phân tích thống kê?
Việc chọn các cụm không mang tính đại diện sẽ tạo ra sai số chọn mẫu lớn, dẫn đến hiện tượng chệch dữ liệu (data bias). Điều này làm suy giảm nghiêm trọng độ tin cậy của các suy luận thống kê, khiến các kết luận nghiên cứu không thể áp dụng chính xác cho toàn bộ tổng thể. Trong phân tích định lượng chuyên sâu, dữ liệu chệch sẽ trực tiếp làm sai lệch các thông số ước lượng, khiến các chỉ số đánh giá mô hình (như Q² hay SRMR) không còn giá trị khoa học thực tiễn.




