
Hệ số bất đối xứng, hay Skewness, là một thước đo thống kê quan trọng dùng để mô tả mức độ lệch của phân phối dữ liệu so với phân phối chuẩn đối xứng. Trong thống kê mô tả, việc xác định hệ số bất đối xứng giúp nhà phân tích hiểu rõ cấu trúc, tính chất của tập dữ liệu, từ đó hỗ trợ việc đưa ra các dự báo và xây dựng mô hình kiểm định có độ chính xác cao hơn.

Hệ số bất đối xứng trong thống kê là gì?
Hệ số bất đối xứng trong thống kê là đại lượng định lượng sự thiếu cân đối của phân phối xác suất. Nếu một phân phối dữ liệu là đối xứng hoàn hảo, độ lệch phân phối sẽ bằng 0. Khi các giá trị dữ liệu tập trung nhiều về một phía thay vì phân tán đều xung quanh giá trị trung tâm (trung bình), phân phối đó được gọi là phân phối bất đối xứng. Việc nhận diện đúng trạng thái bất đối xứng này là bước nền tảng để nhà nghiên cứu áp dụng các phương pháp thống kê phù hợp, đặc biệt trong các lĩnh vực phức tạp như tài chính và nghiên cứu khoa học.

Skewness là gì và tại sao lại quan trọng trong phân tích dữ liệu?
Skewness là chỉ số định lượng độ lệch của phần “đuôi” trong một phân phối dữ liệu. Trong phân tích dữ liệu, Skewness giữ vai trò thiết yếu trong việc xác định liệu tập dữ liệu có chứa các giá trị cực đoan (outliers) hay không – những giá trị này thường có xu hướng kéo lệch giá trị trung bình ra khỏi trung vị. Khi hiểu rõ Skewness, bạn có thể nhận biết được sự bất thường trong tập hợp mẫu. Từ đó, bạn sẽ quyết định được xem liệu tập dữ liệu có đáp ứng được các giả định của kiểm định tham số (như t-test hay ANOVA, vốn yêu cầu tính đối xứng) hay không, hay cần chuyển sang các kiểm định phi tham số để đảm bảo tính khách quan.
Phân phối đối xứng là gì?
Phân phối đối xứng (Symmetric Distribution) là trạng thái lý tưởng mà tại đó độ lệch phân phối bằng 0. Trong tình trạng này, phân phối dữ liệu hình thành một đường cong cân đối giống như hình chiếc chuông (đường cong Gaussian). Tại điểm cân bằng này, ba đại lượng cơ bản là giá trị trung bình (Mean), trung vị (Median) và yếu vị (Mode) đều trùng nhau tại cùng một điểm trung tâm. Sự đối xứng này phản ánh tính ổn định của dữ liệu, nơi xác suất xuất hiện các giá trị lớn hơn hoặc nhỏ hơn giá trị trung bình là ngang bằng nhau.
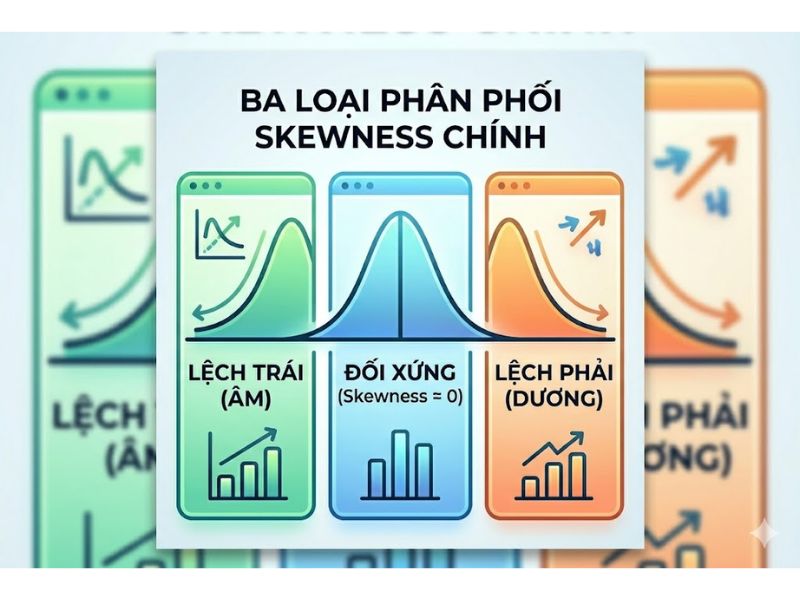
Phân loại hệ số bất đối xứng
Để đánh giá chính xác độ lệch phân phối, nhà phân tích cần phân biệt giữa các loại Skewness dựa trên vị trí của đuôi phân phối so với khối dữ liệu chính:
- Phân phối lệch phải (Positive Skewness): Đây là trường hợp hệ số Skewness dương. Trong hình dạng phân phối, đuôi của phân phối kéo dài sang bên phải. Trong tình huống này, các giá trị ngoại lai lớn xuất hiện nhiều, khiến giá trị trung bình bị kéo theo và trở nên lớn hơn giá trị trung vị (Mean > Median).
- Phân phối lệch trái (Negative Skewness): Đây là trường hợp hệ số Skewness âm. Đuôi của phân phối kéo dài sang bên trái. Khi đó, các giá trị ngoại lai nhỏ kéo giá trị trung bình xuống, dẫn đến giá trị trung bình thường nhỏ hơn trung vị (Mean < Median).
Bảng so sánh đặc điểm các loại phân phối
| Đặc điểm | Phân phối lệch trái (Negative) | Phân phối đối xứng (Symmetric) | Phân phối lệch phải (Positive) |
| Hệ số Skewness | < 0 | = 0 | > 0 |
| Mean vs Median | Mean < Median | Mean = Median | Mean > Median |
| Đuôi phân phối | Kéo dài về phía trái | Không có đuôi nổi bật | Kéo dài về phía phải |
Cách xác định và công thức tính hệ số bất đối xứng
Hệ số bất đối xứng thường được tính toán dựa trên mô-men bậc ba của dữ liệu. Công thức tổng quát cho hệ số Skewness của một tập dữ liệu có n giá trị là:
Skewness = [ Tổng (xi – x_trung_bình)^3 / n ] / s^3
Trong đó:
- x_trung_bình: Đại diện cho giá trị trung bình của tập dữ liệu.
- s: Đại diện cho độ lệch chuẩn (standard deviation) của mẫu.
Giá trị Skewness được chuẩn hóa để phản ánh mức độ lệch theo đơn vị độ lệch chuẩn.

Hệ số bất đối xứng Pearson và Fisher
Trong thực tiễn tính toán, có hai phương pháp tiếp cận phổ biến để đo lường độ lệch:
- Hệ số bất đối xứng Pearson: Sử dụng mô-men chuẩn hóa để xác định độ lệch dựa trên sự khác biệt giữa giá trị trung bình (Mean) và yếu vị (Mode). Phương pháp này rất hữu ích cho các lý thuyết thống kê cơ bản.
- Hệ số bất đối xứng Fisher: Đây là tiêu chuẩn được các phần mềm thống kê hiện đại (như SPSS, Excel, Python/Pandas) sử dụng. Công thức này có điều chỉnh để đảm bảo tính không chệch (unbiased) cho các mẫu dữ liệu nhỏ, giúp kết quả đáng tin cậy hơn khi quy mô mẫu hạn chế.
Hướng dẫn tính hệ số bất đối xứng trong Excel
Việc tính toán Skewness trong Excel được thực hiện nhanh chóng thông qua các hàm có sẵn:
- Chọn một ô trống mà bạn muốn hiển thị kết quả.
- Nhập công thức: =SKEW(dải_dữ_liệu)
- Nhấn Enter.
Ví dụ: Nếu tập dữ liệu nằm từ ô A1 đến A20, hãy nhập =SKEW(A1:A20). Hàm này sẽ tự động trả về giá trị Skewness dựa trên công thức của Fisher, hỗ trợ tối đa cho việc xử lý dữ liệu nhanh chóng.
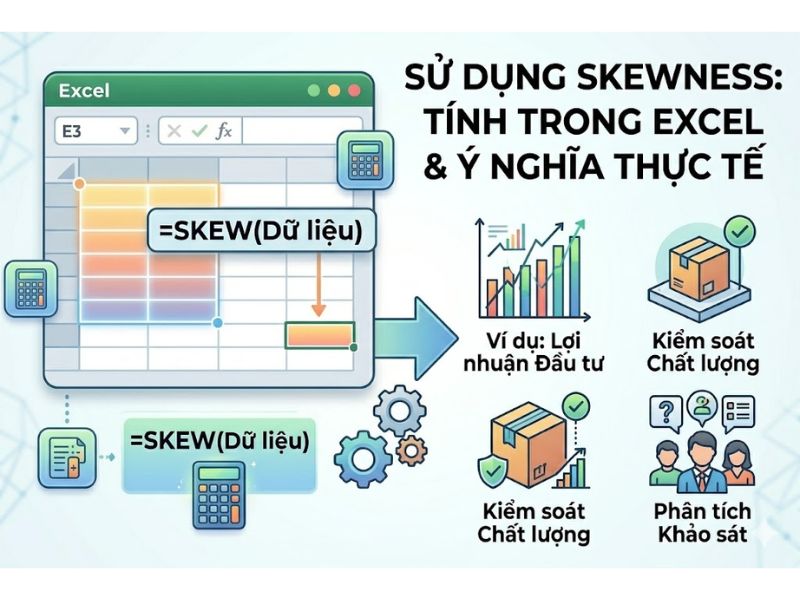
Ý nghĩa hệ số bất đối xứng trong thực tiễn
Độ lệch phân phối mang lại những thông tin quan trọng trong các lĩnh vực cụ thể:
- Tài chính: Skewness là công cụ dự báo rủi ro thiết yếu. Một danh mục đầu tư có Skewness âm thể hiện nguy cơ tiềm ẩn về những khoản thua lỗ lớn bất thường. Ngược lại, một danh mục có Skewness dương thường gợi ý khả năng đạt được lợi nhuận đột biến.
- Nghiên cứu thị trường: Việc đo lường Skewness giúp hiểu hành vi người tiêu dùng qua các tập dữ liệu như thu nhập hay chi tiêu – những dữ liệu thường không tuân theo phân phối chuẩn mà bị lệch phải, từ đó giúp doanh nghiệp nhắm mục tiêu phân khúc khách hàng chính xác hơn.
Các câu hỏi thường gặp về Skewness và độ lệch phân phối
Giá trị Skewness bao nhiêu là chấp nhận được cho phân phối chuẩn?
Trong thống kê ứng dụng, nếu giá trị Skewness nằm trong khoảng từ -1 đến 1, dữ liệu được coi là có độ lệch thấp và xấp xỉ phân phối chuẩn. Nếu Skewness nằm ngoài khoảng từ -2 đến 2, dữ liệu đó được coi là lệch đáng kể, đòi hỏi các phương pháp xử lý dữ liệu đặc biệt trước khi đưa vào mô hình hóa.
Mối quan hệ giữa Skewness và Kurtosis là gì?
Trong khi Skewness đo lường độ lệch (sự bất đối xứng) của phân phối, thì Kurtosis đo lường “độ nhọn” của đỉnh phân phối và độ dày của các đuôi (sự tập trung của dữ liệu quanh trung tâm). Cả hai đều là chỉ số quan trọng để kiểm định phân phối chuẩn.
Skewness có bị ảnh hưởng bởi giá trị ngoại lai (outlier) không?
Có, hệ số Skewness rất nhạy cảm với các giá trị ngoại lai. Một vài giá trị cực đoan có thể làm thay đổi đáng kể hệ số bất đối xứng của tập dữ liệu, dẫn đến những kết luận sai lệch về hình dạng phân phối. Việc làm sạch dữ liệu là bước cần thiết trước khi tính toán.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



