
Hệ số Skewness và Kurtosis là hai đại lượng thống kê mô tả dùng để đánh giá hình dáng phân phối của một tập dữ liệu định lượng. Nguyên nhân chính khiến dữ liệu vi phạm giả định phân phối chuẩn là do sai số trong chọn mẫu hoặc đặc thù của tổng thể. Giải pháp nhanh nhất để kiểm định là đối chiếu hai giá trị này được trích xuất từ phần mềm SPSS với khoảng tiêu chuẩn từ -2 đến +2. Việc đảm bảo tính chuẩn của dữ liệu là tiền đề cốt lõi để các mô hình định lượng đạt được độ khít sát (Goodness of Fit – GoF) tối ưu, cũng như đảm bảo các chỉ số đánh giá mô hình như R² và Q² phản ánh chính xác thực tế biến thiên của dữ liệu.
1. Tổng quan về Hệ số Skewness và Kurtosis trong Thống kê mô tả
Trong phân tích dữ liệu định lượng, việc xác định hình dáng phân phối của bộ dữ liệu là bước bắt buộc trước khi tiến hành các suy luận thống kê phức tạp. Việc đánh giá này giúp nhà nghiên cứu xác định phương pháp kiểm định phù hợp nhất với bản chất của bộ số liệu thực tế.
1.1. Hệ số Skewness (Độ lệch) là gì?
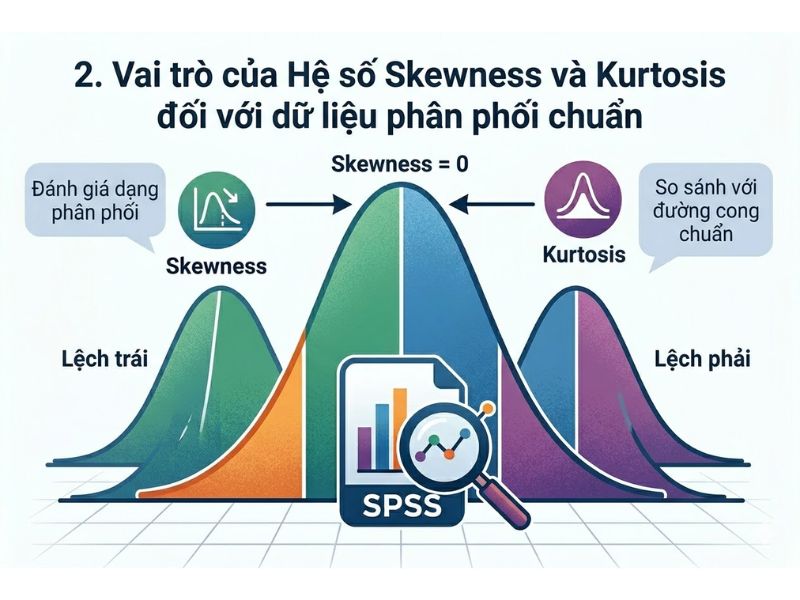
Hệ số Skewness (độ lệch) là thước đo mức độ bất đối xứng của một phân phối xác suất xung quanh giá trị trung bình (Mean) của nó. Trong toán học thống kê, Skewness phản ánh chiều hướng và mức độ chênh lệch trọng tâm của dữ liệu so với phân phối hình chuông lý tưởng. Trong một phân phối chuẩn hoàn hảo, giá trị Skewness bằng 0.
- Skewness > 0 (Lệch phải / Positive Skew): Đuôi của biểu đồ phân phối kéo dài về phía bên phải. Giá trị trung bình (Mean) > Trung vị (Median) > Yếu vị (Mode). Sự xuất hiện của các giá trị ngoại lai dương lớn đã kéo trung bình cộng lệch về phía bên phải.
- Skewness < 0 (Lệch trái / Negative Skew): Đuôi của biểu đồ phân phối kéo dài về phía bên trái. Giá trị trung bình (Mean) < Trung vị (Median) < Yếu vị (Mode). Hiện tượng này xảy ra khi tập dữ liệu bị tập trung quá nhiều ở các giá trị cao, kèm theo một số ít giá trị cực thấp ở đuôi trái.
1.2. Hệ số Kurtosis (Độ nhọn) là gì?
Hệ số Kurtosis (độ nhọn) là đại lượng đo lường độ tập trung của dữ liệu ở vùng trung tâm và vùng đuôi so với phân phối chuẩn. Đặc tính này cho biết xác suất xuất hiện các giá trị cực đoan (outliers) trong tập dữ liệu. Lưu ý rằng trên phần mềm SPSS, giá trị được tính toán tự động thường là “Excess Kurtosis” (Độ nhọn vượt trội), tức là đã lấy giá trị Kurtosis tuyệt đối trừ đi 3 để quy chiếu về mốc 0.
- Mesokurtic (Kurtosis = 0): Phân phối có độ nhọn tương đương với phân phối chuẩn. Mật độ phân bổ dữ liệu ở vùng trung bình và vùng đuôi đạt mức cân bằng lý tưởng.
- Leptokurtic (Kurtosis > 0): Phân phối nhọn hơn phân phối chuẩn, dữ liệu tập trung nhiều ở giá trị trung bình và có đuôi dày (nhiều giá trị ngoại lai). Biểu đồ có đỉnh rất cao và hẹp.
- Platykurtic (Kurtosis < 0): Phân phối bẹt hoặc tù hơn phân phối chuẩn, dữ liệu phân tán rộng và đuôi mỏng. Biểu đồ có dạng dẹt, chứng tỏ các quan sát phân tán đều đặn ra các giá trị xung quanh thay vì tụ hội ở giữa.
2. Vai trò của Hệ số Skewness và Kurtosis đối với dữ liệu phân phối chuẩn
Việc kiểm tra Hệ số Skewness và Kurtosis đóng vai trò tiên quyết trong phân tích định lượng. Các kiểm định tham số (Parametric tests) phổ biến như kiểm định T-test, phân tích phương sai ANOVA, hay hồi quy tuyến tính đều yêu cầu một giả định bắt buộc: Dữ liệu đầu vào phải có phân phối chuẩn hoặc xấp xỉ chuẩn.
Nếu bỏ qua bước đánh giá độ lệch và độ nhọn, nhà nghiên cứu có thể sử dụng sai phương pháp kiểm định, dẫn đến sai lệch trong kết quả ước lượng, làm giảm độ tin cậy của toàn bộ mô hình và bác bỏ sai các giả thuyết thống kê. Cụ thể, việc vi phạm giả định này làm gia tăng sai lầm loại I (Type I error) và sai lầm loại II (Type II error). Điều này đặc biệt nghiêm trọng trong các mô hình phương trình cấu trúc dựa trên hiệp phương sai (CB-SEM), nơi yêu cầu khắt khe về phân phối chuẩn đa biến để đạt được các chỉ số độ khít sát đạt yêu cầu (ví dụ: SRMR ≤ 0.08 và GFI ≥ 0.90).
3. Tiêu chuẩn đọc Hệ số Skewness và Kurtosis trên phần mềm SPSS
3.1. Tiêu chuẩn đánh giá ngưỡng chấp nhận (từ -2 đến +2)
Theo các tiêu chuẩn học thuật hiện hành (Hair et al., 2010; Byrne, 2010; George & Mallery, 2010), một bộ dữ liệu được coi là có phân phối xấp xỉ chuẩn khi giá trị của Hệ số Skewness và Kurtosis nằm trong khoảng giới hạn cụ thể. Việc xác định ngưỡng phụ thuộc nhiều vào quy mô mẫu khảo sát thực tế.
Bảng Tiêu chuẩn Đánh giá Phân phối Dữ liệu qua Skewness và Kurtosis
| Tiêu chí | Ngưỡng giá trị lý tưởng (Khuyên dùng) | Ngưỡng chấp nhận (Cỡ mẫu lớn N > 300) | Ý nghĩa thống kê trong nghiên cứu |
| Hệ số Skewness | Từ -1 đến +1 | Từ -2 đến +2 | Dữ liệu đối xứng, không bị lệch đuôi nghiêm trọng. Giá trị trung bình đại diện tốt cho tập mẫu. |
| Hệ số Kurtosis | Từ -1 đến +1 | Từ -2 đến +2 | Dữ liệu có độ nhọn vừa phải, ít bị ảnh hưởng bởi giá trị ngoại lai. Phương sai của mẫu mang tính ổn định cao. |
Lưu ý: Đối với các nghiên cứu có cỡ mẫu (sample size) rất lớn (N > 300) kết hợp với Định lý giới hạn trung tâm (Central Limit Theorem), một số hội đồng khoa học và học giả (như Kline, 2015) có thể chấp nhận ngưỡng nới lỏng từ -3 đến +3 đối với hệ số Skewness và Kurtosis.
3.2. Quy trình trích xuất hệ số trên phần mềm SPSS
Để tính toán và trích xuất hai hệ số này trên SPSS phục vụ cho việc biện luận báo cáo, hãy thực hiện theo quy trình thao tác chuẩn xác sau:
- Mở bộ dữ liệu cần phân tích trên phần mềm SPSS. Tiến hành kiểm tra nhanh việc khai báo biến (Variable View) để đảm bảo định dạng dữ liệu là Scale.
- Trên thanh công cụ, chọn Analyze > Descriptive Statistics > Descriptives (hoặc Explore nếu cần xem thêm biểu đồ Histogram và chỉ số Shapiro-Wilk).
- Đưa các biến định lượng cần kiểm định vào ô Variable(s).
- Nhấp vào nút Options, tích chọn vào hai ô Kurtosis và Skewness trong mục Distribution.
- Nhấn Continue và OK để phần mềm xuất bảng kết quả (Output Viewer).
- Đọc kết quả tại hai cột tương ứng là Skewness Statistic và Kurtosis Statistic để đối chiếu với khoảng giá trị -2 đến +2.
(Ghi chú học thuật: Các chuyên gia dữ liệu thường thực hiện thêm một bước kiểm tra độ chuẩn xác bằng cách lấy điểm Statistic chia cho điểm Std. Error để tính ra Z-score. Nếu trị tuyệt đối của Z-score < 1.96, dữ liệu đáp ứng phân phối chuẩn ở mức ý nghĩa 5%).

4. Giải pháp xử lý khi dữ liệu vi phạm giả định phân phối chuẩn
Khi kết quả kiểm tra cho thấy hệ số vượt ra khỏi ngưỡng an toàn (ví dụ: Skewness = 3.5), dữ liệu đã vi phạm giả định phân phối chuẩn. Nhà nghiên cứu cần áp dụng các giải pháp sau để đảm bảo tính khoa học cho mô hình:
- Làm sạch dữ liệu (Data Cleaning): Kiểm tra và loại bỏ các giá trị ngoại lai (Outliers) cực đoan đang làm méo mó phân phối. Sử dụng biểu đồ Boxplot trên SPSS để khoanh vùng các điểm dữ liệu bất thường.
- Chuyển đổi dữ liệu (Data Transformation): Thực hiện các phép biến đổi toán học lên biến số như lấy Logarit tự nhiên (Log transformation – áp dụng tốt cho dữ liệu lệch phải dương), lấy căn bậc hai (Square root), hoặc nghịch đảo (Inverse) để kéo dữ liệu về dạng chuẩn.
- Sử dụng kiểm định phi tham số (Non-parametric tests): Nếu dữ liệu không thể chuyển đổi, bắt buộc phải thay thế các kiểm định tham số bằng các kiểm định phi tham số tương ứng (ví dụ: dùng Mann-Whitney U thay cho Independent T-test; dùng Kruskal-Wallis thay cho One-way ANOVA).
- Kỹ thuật Bootstrapping (Lấy mẫu lại): Trong các trường hợp muốn giữ nguyên phương pháp phân tích tham số, nhà nghiên cứu có thể sử dụng kỹ thuật Bootstrapping (tạo ra hàng ngàn mẫu con từ mẫu gốc) để ước lượng các khoảng tin cậy chắc chắn (Robust Standard Errors), khắc phục nhược điểm của dữ liệu không chuẩn.
5. Kết luận
Tóm lại, Hệ số Skewness và Kurtosis là hai công cụ thống kê mô tả đắc lực giúp xác định tính chuẩn xác của dữ liệu. Bằng cách áp dụng quy trình trích xuất trên SPSS và tuân thủ chặt chẽ ngưỡng tiêu chuẩn từ -2 đến +2, các nhà phân tích có thể đảm bảo mô hình định lượng đáp ứng các giả định khắt khe nhất. Đây là bước kiểm định tính chuẩn mực không thể thiếu, góp phần nâng cao tính thực chứng và sự chặt chẽ cho bất kỳ bài nghiên cứu khoa học nào.
6. Câu hỏi thường gặp (FAQ)
Hệ số Skewness và Kurtosis bằng 0 có ý nghĩa gì?
Hệ số bằng 0 chứng minh bộ dữ liệu có phân phối chuẩn hoàn hảo (Normal distribution). Khi đó, đồ thị phân phối hoàn toàn đối xứng, không bị lệch về bên nào và có độ nhọn chuẩn mực hình quả chuông, với giá trị Trung bình bằng đúng Trung vị và Yếu vị.
Cỡ mẫu (Sample size) ảnh hưởng thế nào đến sự sai lệch của Skewness và Kurtosis?
Cỡ mẫu càng lớn, sai số chuẩn (Standard Error) của Skewness và Kurtosis càng nhỏ. Điều này làm cho các giá trị thống kê có xu hướng tiệm cận về 0 nhanh hơn, giúp dữ liệu dễ dàng đạt được giả định phân phối chuẩn theo định lý giới hạn trung tâm. Với các cỡ mẫu nhỏ (N < 50), hai hệ số này rất nhạy cảm và dễ bị thổi phồng bởi chỉ một hoặc hai giá trị ngoại lai.
Ngoài Skewness và Kurtosis, còn phương pháp nào kiểm tra phân phối chuẩn trên SPSS?
Nhà nghiên cứu có thể sử dụng kiểm định Shapiro-Wilk (cho mẫu < 50) hoặc Kolmogorov-Smirnov (cho mẫu > 50). Ngoài ra, việc quan sát trực quan qua biểu đồ Histogram kèm đường cong chuẩn (Normal curve) hoặc biểu đồ Q-Q Plot (Quantile-Quantile plot) cũng là phương pháp đối chiếu độ chuẩn xác thực tế mang tính trực quan cao. Học giả được khuyến nghị nên kết hợp cả phân tích hệ số và quan sát biểu đồ để đưa ra kết luận khách quan nhất.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



