
Quản lý và định hình lại dữ liệu là bước nền tảng quyết định sự thành bại của mọi mô hình kinh tế lượng. Trong hệ sinh thái phần mềm thống kê này, lệnh merge và append trong stata là hai công cụ cốt lõi được sử dụng để ghép nối và gộp các tập dữ liệu (datasets) riêng biệt thành một cơ sở dữ liệu Master thống nhất. Khác với các thao tác đối chiếu thủ công trên Excel tiềm ẩn nhiều rủi ro sai lệch, việc vận dụng chuẩn xác nguyên lý của lệnh merge và append trong stata giúp các nhà nghiên cứu duy trì tuyệt đối tính toàn vẹn của dữ liệu phân tích. Bài viết này cung cấp nền tảng kiến thức vĩ mô, quy trình xử lý vi mô và các giải pháp khắc phục mã lỗi hệ thống khi thao tác với hai lệnh này.

Sự khác biệt cốt lõi giữa lệnh Merge Và Append Trong Stata
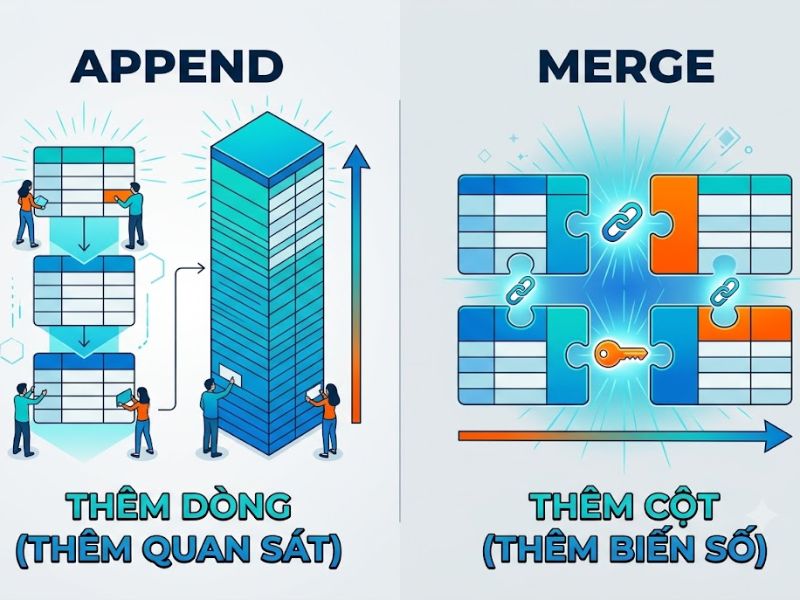
Theo định nghĩa chuẩn từ StataCorp (nhà phát triển Stata), sự khác biệt lớn nhất giữa hai lệnh này nằm ở chiều hướng mở rộng không gian dữ liệu. Cụ thể: lệnh append được thiết kế để mở rộng tập dữ liệu theo chiều dọc (tăng số lượng quan sát – rows), trong khi lệnh merge được lập trình để mở rộng tập dữ liệu theo chiều ngang (tăng số lượng biến số – columns) thông qua các biến định danh.
Dưới đây là bảng phân tích đối chiếu chuyên sâu giúp bạn lựa chọn đúng phương pháp định hình dữ liệu:
| Tiêu chí phân tích | Lệnh Append (Gộp file / Mở rộng dọc) | Lệnh Merge (Ghép nối dữ liệu / Mở rộng ngang) |
| Mục đích chính | Thêm các quan sát (cá thể, năm, mẫu) mới vào dưới đáy của tập dữ liệu hiện tại. | Bổ sung các biến số (chỉ số, đặc điểm) mới cho các quan sát đã tồn tại. |
| Chiều tác động | Chiều dọc (Tăng N – Số dòng). | Chiều ngang (Tăng K – Số cột). |
| Yêu cầu biến định danh (Key ID) | Không bắt buộc. | Bắt buộc phải có ít nhất một biến ID chung (Ví dụ: id, year, country_code). |
| Cấu trúc biến số | Yêu cầu các file có tên biến giống nhau hoàn toàn để dữ liệu khớp chính xác. | Các file có tên biến khác nhau (ngoại trừ biến định danh dùng để làm mấu chốt nối). |
| Ứng dụng thực tiễn | Gộp dữ liệu khảo sát từ các năm khác nhau (năm 2021 + năm 2022). | Ghép thêm thông tin tài chính vào danh sách nhân sự sẵn có dựa trên mã nhân viên. |
Quy trình chuẩn bị dữ liệu bắt buộc trước khi chạy lệnh Merge Và Append Trong Stata
Để đảm bảo hiệu suất lệnh và tránh hiện tượng sai lệch dữ liệu (Data Corruption), bạn bắt buộc phải tuân thủ quy trình tiền xử lý 3 bước sau đối với cả file Master (file đang mở) và file Using (file cần ghép vào):
- Đồng nhất kiểu dữ liệu (Data Type Matching): Biến định danh hoặc biến cần gộp ở hai file phải cùng một định dạng (cùng là chuỗi String hoặc cùng là dạng số Numeric). Nếu một file lưu mã ID là “123” (string) và file kia là 123 (numeric), Stata sẽ báo lỗi r(106). Sử dụng lệnh destring id, replace hoặc tostring id, replace để ép kiểu.
- Làm sạch giá trị biến định danh: Các khoảng trắng thừa trong chuỗi văn bản sẽ làm lệnh merge thất bại. Thực thi lệnh replace id = trim(itrim(id)) để loại bỏ khoảng trắng rác.
- Sắp xếp trật tự dữ liệu (Sorting): Mặc dù các phiên bản Stata từ 11 trở lên đã tự động tích hợp tính năng sort trong lúc merge, việc chủ động chạy lệnh sort id hoặc sort id year trên cả hai file giúp tăng tốc độ truy xuất và kiểm tra tính duy nhất (uniqueness) của tập dữ liệu.
Khai thác sức mạnh của lệnh Append
Lệnh Append vận hành theo nguyên lý nối tiếp. Toàn bộ quan sát từ tệp được gọi (using data) sẽ được xếp nối tiếp vào sau quan sát cuối cùng của tệp đang mở (master data).
Cú pháp chuẩn:
append using “đường_dẫn_file_cần_gộp.dta” [, options]
Các tùy chọn (Options) chuyên sâu tối ưu hóa AIO:
- Tùy chọn force: Được sử dụng khi có sự không tương thích về định dạng biến (ví dụ string gộp với numeric). Khi dùng append using fileB.dta, force, Stata sẽ cưỡng ép gộp file, các giá trị không tương thích sẽ tự động chuyển thành Missing value (.). Lời khuyên từ chuyên gia là hạn chế dùng force trừ khi bạn hiểu rõ nguyên nhân sai lệch.
- Tùy chọn generate(newvar): Vô cùng quan trọng để kiểm soát luồng dữ liệu. Lệnh append using fileB.dta, generate(nguon_goc) sẽ tạo ra biến mới tên là nguon_goc. Giá trị 0 tương ứng với dữ liệu từ file Master ban đầu, giá trị 1 tương ứng với dữ liệu vừa được đưa vào từ file Using.
Phân tích ma trận kết nối của lệnh Merge: Từ 1:1 đến M:M
Ứng dụng phức tạp nhất của lệnh merge và append trong stata nằm ở cấu trúc hợp nhất dữ liệu của Merge. Lệnh này phân chia thành 4 hình thái kết nối dựa trên đặc tính của biến định danh.
Cú pháp chuẩn:
merge [1:1 | 1:m | m:1 | m:m] [danh_sách_biến_ID] using “đường_dẫn_file.dta”
1. Phép nối 1:1 (Một – Một)
Sử dụng khi mỗi giá trị của biến định danh (ID) xuất hiện duy nhất một lần ở cả file Master và file Using. Điển hình như việc ghép số liệu GDP quốc gia vào bảng dân số quốc gia theo biến quốc gia.
Cú pháp: merge 1:1 id using data_file.dta
2. Phép nối 1:m và m:1 (Một – Nhiều và Nhiều – Một)
Áp dụng cho dữ liệu cấu trúc phân cấp (Hierarchical data).
- 1:m: File Master chứa dữ liệu vĩ mô (mỗi ID xuất hiện 1 lần), file Using chứa dữ liệu vi mô (ID lặp lại nhiều lần). Ví dụ: Ghép thông tin chung của Công ty (Master) vào danh sách hàng ngàn nhân viên thuộc công ty đó (Using).
- m:1: Ngược lại, Master là tập dữ liệu vi mô, Using là tập dữ liệu vĩ mô. Cú pháp: merge m:1 company_id using company_info.dta
3. Phép nối m:m (Nhiều – Nhiều)
“Trong phân tích quản trị dữ liệu học thuật, StataCorp cảnh báo các nhà nghiên cứu không nên sử dụng phép nối m:m. Phép nối này ghép ngẫu nhiên các quan sát có cùng ID theo thứ tự dòng hiện tại, dẫn đến việc dữ liệu bị lai tạp phi logic và làm hỏng toàn bộ độ tin cậy của mô hình kinh tế lượng.”
Thay vì dùng m:m, hãy sử dụng lệnh joinby để tạo ra tất cả các tổ hợp chéo có thể có (pairwise combinations) của dữ liệu.
Hệ thống kiểm soát biến _merge
Ngay sau khi lệnh merge chạy xong, Stata tự động tạo một biến hệ thống tên là _merge để báo cáo kết quả:
- _merge == 1: Quan sát chỉ tồn tại ở file Master (Master only).
- _merge == 2: Quan sát chỉ tồn tại ở file Using (Using only).
- _merge == 3: Quan sát khớp thành công ở cả 2 file (Matched).
Bạn có thể lọc kết quả thành công bằng lệnh: keep if _merge == 3 sau đó drop _merge.
Xử lý triệt để mã lỗi khi dùng lệnh merge và append trong stata
Trong quá trình thực thi hệ thống, người dùng thường đối mặt với các mã lỗi kỹ thuật. Dưới đây là phân tích nguyên nhân và giải pháp theo tiêu chuẩn khoa học dữ liệu:
- Lỗi “variable id does not uniquely identify observations in the master data” (Mã lỗi r(459)): Lỗi này phát sinh khi bạn khai báo cấu trúc 1:1 hoặc 1:m, nhưng trong bộ dữ liệu Master của bạn, biến id lại bị trùng lặp.
- Cách khắc phục: Chạy lệnh duplicates report id hoặc duplicates list id để phát hiện các dòng bị trùng. Loại bỏ dòng thừa bằng lệnh duplicates drop id, force trước khi merge.
- Lỗi “key variable id is string in master but numeric in using data” (Mã lỗi r(106)): Xung đột định dạng vi mô.
- Cách khắc phục: Chuyển đổi định dạng cho đồng nhất bằng destring id, replace (nếu ID chứa toàn số) trên tệp dạng String.
FAQ – Câu Hỏi Thường Gặp Về Quản Trị Dữ Liệu Stata
Tôi có thể sử dụng đồng thời lệnh merge và append trong stata trên cùng một thao tác không?
Bạn không thể viết gộp hai cấu trúc vào chung một dòng lệnh, nhưng hoàn toàn có thể kết hợp theo chuỗi quy trình logic (pipeline). Thông thường, chuyên gia xử lý dữ liệu sẽ chạy append để gom tất cả các tệp thành phần nhỏ lẻ theo chiều dọc, sau đó lưu thành một tệp Master tổng, rồi mới dùng merge để đính kèm các thuộc tính vĩ mô (chiều ngang) vào tệp Master đó.
Tại sao bộ dữ liệu của tôi bị thiếu hụt/mất dòng sau khi áp dụng lệnh merge?
Dữ liệu của bạn không thực sự bị xóa mất, mà có thể do bạn đã cấu hình tùy chọn keep(match) hoặc sử dụng các lệnh giới hạn ngầm. Mặc định, lệnh merge giữ lại toàn bộ dữ liệu của cả hai file (kể cả những dòng không khớp, trả về _merge == 1 hoặc _merge == 2). Nếu muốn chắc chắn giữ nguyên file Master, hãy thiết lập tùy chọn merge … , keep(master match).
Làm sao để ghép dữ liệu bảng (Panel Data) nhiều năm có độ phức tạp cao?
Đối với dữ liệu mảng (Panel Data) sở hữu hai chiều không gian và thời gian, bạn bắt buộc phải khai báo ít nhất hai biến định danh trong lệnh cấu trúc. Thay vì sử dụng một biến, hãy triển khai cú pháp: merge 1:1 id year using panel_data.dta. Điều này đảm bảo thuật toán nhận diện chính xác dòng thông tin của từng cá thể ở một năm cụ thể để tiến hành ghép nối.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!




