
Sai lệch mô hình phân tích là một rủi ro nghiêm trọng trong thống kê và thiết kế nghiên cứu. Biến nhiễu (Confounding Variable) là yếu tố ngoại lai tác động đồng thời lên cả biến độc lập và biến phụ thuộc, tạo ra một mối liên kết không có thực. Nguyên nhân chính sinh ra hiện tượng này là sự thiếu sót trong thiết kế thực nghiệm hoặc quá trình thu thập dữ liệu không toàn diện. Giải pháp nhanh nhất và chuẩn xác nhất là áp dụng các kỹ thuật ngẫu nhiên hóa trong giai đoạn thiết kế, hoặc sử dụng phương pháp ghép cặp, phân tầng thống kê trong giai đoạn phân tích dữ liệu.
1. Biến nhiễu là gì?
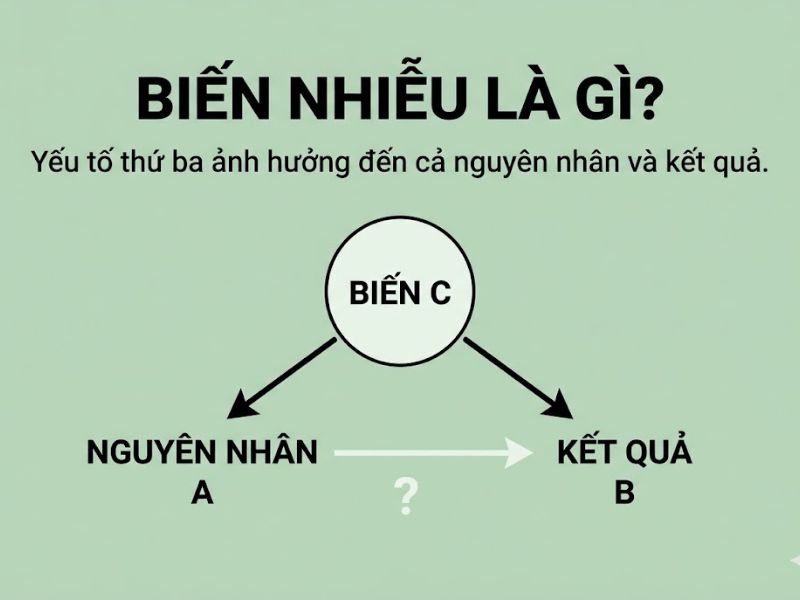
Biến nhiễu thuộc lĩnh vực phương pháp nghiên cứu khoa học, kinh tế lượng và thống kê học. Đây là một biến số thứ ba (third variable) không nằm trong giả thuyết nghiên cứu ban đầu của mô hình, nhưng lại có mối tương quan tuyến tính hoặc phi tuyến tính với cả biến độc lập (Independent Variable) và biến phụ thuộc (Dependent Variable). Sự tồn tại của biến nhiễu gây ra hiện tượng tương quan giả mạo (Spurious correlation), làm sai lệch hoàn toàn kết quả ước lượng về mối quan hệ nhân quả thực sự giữa các đối tượng đang được phân tích.
So với các lý thuyết phân tích biến số khác trong thống kê, biến nhiễu có sự khác biệt rõ rệt về bản chất cấu trúc:
- Khác với biến trung gian (Mediating Variable): Biến trung gian nằm trên chuỗi nhân quả trực tiếp (A -> B -> C), đóng vai trò giải thích cơ chế, cách thức hoặc lý do tại sao biến độc lập có thể tác động lên biến phụ thuộc. Ngược lại, biến nhiễu hoàn toàn nằm ngoài chuỗi nhân quả này và tạo ra một “ảo giác” về sự kết nối.
- Khác với biến điều tiết (Moderating Variable): Biến điều tiết là yếu tố làm thay đổi cường độ (mạnh lên/yếu đi) hoặc chiều hướng (tích cực/tiêu cực) của một mối quan hệ nhân quả đã có thực. Trong khi đó, biến nhiễu tạo ra một mối quan hệ ảo không hề tồn tại trong thực tế.
Khái niệm biến nhiễu lập luận rằng: Hai biến số (X và Y) có thể thể hiện sự tương quan thống kê vô cùng mạnh mẽ (thông qua hệ số tương quan Pearson hoặc Spearman cao) không phải vì chúng có quan hệ nhân quả trực tiếp với nhau, mà vì cả X và Y đều đang bị chi phối và định hình bởi một yếu tố chung (Z) chưa được kiểm soát trong mô hình.
Các thành phần cốt lõi của hiện tượng biến nhiễu
- Yếu tố tác động trực tiếp lên biến nguyên nhân (Biến độc lập).
- Yếu tố tác động trực tiếp lên biến kết quả (Biến phụ thuộc).
- Yếu tố hoàn toàn không nằm trên con đường nhân quả logic giữa nguyên nhân và kết quả.
Mục đích của việc nghiên cứu sâu về lý thuyết biến nhiễu là nhằm nhận diện sớm, đo lường chính xác và loại bỏ triệt để các sai số hệ thống (Systematic error). Quá trình này giúp giảm thiểu tối đa độ chệch (bias) trong các hệ số hồi quy, từ đó đảm bảo độ tin cậy (Reliability) và độ giá trị (Validity) của mọi kết luận khoa học trước khi công bố.
2. Lịch sử hình thành và phát triển của lý thuyết
Sự phát triển của phương pháp luận về việc kiểm soát biến nhiễu gắn liền với những nhà thống kê học và khoa học máy tính lỗi lạc qua các thời kỳ.
- Giai đoạn Khởi nguồn: Khái niệm này được định hình mạnh mẽ bởi Ronald A. Fisher (1935) thông qua tác phẩm kinh điển The Design of Experiments. Fisher đã đặt ra câu hỏi nền tảng: “Làm thế nào để xác định chính xác tác động thực sự của một loại phân bón lên năng suất cây trồng khi các điều kiện đất đai, độ ẩm và khí hậu liên tục khác nhau?”. Câu trả lời của ông đã tạo ra nền tảng của phương pháp “Ngẫu nhiên hóa” (Randomization). Bằng cách phân bổ ngẫu nhiên các mẫu, Fisher chứng minh rằng các biến nhiễu tiềm ẩn sẽ được chia đều vào các nhóm thử nghiệm và nhóm chứng, qua đó triệt tiêu tác động làm sai lệch của chúng.
- Giai đoạn Hoàn thiện/Phát triển: Tiến bộ vượt bậc tiếp theo thuộc về Judea Pearl (1995) với công trình Causal Diagrams for Empirical Research. Pearl đã đóng góp khung phân tích nhân quả hiện đại thông qua Biểu đồ nhân quả có hướng (Directed Acyclic Graphs – DAGs). Khung lý thuyết này cung cấp một bộ công cụ toán học và đồ thị hoàn chỉnh để nhà nghiên cứu xác định chính xác biến nào thực sự là biến nhiễu cần phải kiểm soát, và biến nào tuyệt đối không được phép kiểm soát (nhằm tránh sai lệch do kiểm soát quá mức – over-adjustment bias).
3. Các miền nội dung khái niệm cốt lõi (Core Concepts)
Để hiểu sâu về cơ chế hoạt động của biến nhiễu, các nhà nghiên cứu cần nắm vững các giả định nền tảng trong thiết lập mô hình định lượng.
Các giả định nền tảng (Nguyên lý hoạt động):
- Giả định 1: Sự tồn tại của sai số hệ thống. Lý thuyết giả định rằng trong mọi môi trường thực nghiệm hoặc quan sát, luôn tồn tại các yếu tố ngoại cảnh tác động lên dữ liệu. Nếu nhà nghiên cứu không chủ động nhận diện và kiểm soát, các yếu tố này sẽ không phân bổ ngẫu nhiên. Thay vào đó, chúng tạo ra một phương sai sai số có hướng, làm lệch hệ số hồi quy (regression coefficients) và dẫn đến kết luận sai lầm về sự tồn tại của hiệu ứng.
- Giả định 2: Tính độc lập tuyệt đối của phần dư. Trong các mô hình hồi quy chuẩn (ví dụ OLS), phần dư (Residuals – đại diện cho các yếu tố không được đưa vào mô hình) bắt buộc phải độc lập với biến độc lập. Khi xuất hiện một biến nhiễu chưa được đưa vào mô hình (hiện tượng Omitted Variable Bias), biến nhiễu đó sẽ nằm trong phần dư. Điều này khiến phần dư có tương quan trực tiếp với biến độc lập, làm cho giả định này bị vi phạm nghiêm trọng và phá vỡ toàn bộ tính hợp lệ của mô hình.
Các đặc tính và biến số quan trọng quyết định cấu trúc mô hình:
- Biến độc lập (X): Yếu tố nguyên nhân cốt lõi được nhà nghiên cứu chủ động can thiệp (trong thực nghiệm) hoặc quan sát thu thập dữ liệu (trong nghiên cứu tương quan).
- Biến phụ thuộc (Y): Kết quả trực tiếp chịu tác động, đại diện cho hiện tượng cần được giải thích.
- Biến nhiễu (Z): Yếu tố ngoại lai, nguồn gốc của sai lệch, có khả năng tác động và làm thay đổi giá trị của cả X và Y một cách có hệ thống.
Bảng so sánh: Phân biệt các loại biến số trong mô hình nghiên cứu khoa học
| Tiêu chí phân tích | Biến Nhiễu (Confounding Variable) | Biến Trung Gian (Mediating Variable) | Biến Điều Tiết (Moderating Variable) |
| Vị trí chuỗi nhân quả | Nằm hoàn toàn bên ngoài chuỗi nhân quả chính thức | Nằm trực tiếp ở giữa chuỗi nhân quả (X -> M -> Y) | Tương tác chéo với biến độc lập trong quá trình tác động |
| Bản chất tác động | Gây ra tương quan giả mạo, đánh lừa nhà phân tích | Giải thích lý thuyết “tại sao” và “như thế nào” X tạo ra Y | Làm thay đổi “mức độ mạnh/yếu” hoặc “chiều hướng âm/dương” |
| Mục tiêu xử lý dữ liệu | Phải loại bỏ bằng ngẫu nhiên hóa hoặc kiểm soát chặt chẽ bằng thống kê | Bắt buộc đưa vào mô hình để đo lường và đánh giá hiệu ứng gián tiếp | Cần thiết lập mô hình tương tác (Interaction terms) để đo lường |
| Phương pháp thống kê áp dụng | Phân tầng dữ liệu, Ngẫu nhiên hóa mẫu, Ghép cặp xu hướng (Propensity Score Matching) | Phân tích đường dẫn (Path Analysis), Bootstrapping | Phân tích phương sai ANOVA, Hồi quy đa biến với biến tương tác |

4. Nội hàm các khái niệm và Thang đo các biến (Measurement Scales)
Trong nghiên cứu định lượng, việc thiết kế thang đo để đo lường các yếu tố nhiễu đòi hỏi sự chính xác tuyệt đối nhằm đưa vào phương trình kiểm soát.
- Đo lường biến nhiễu trực tiếp (Direct Measurement): Đối với các biến nhiễu mang tính nhân khẩu học hoặc có thể quan sát trực quan được (như Tuổi tác, Giới tính, Mức thu nhập, Trình độ học vấn), nhà nghiên cứu thường đo lường thông qua Thang đo định danh (Nominal Scale) hoặc Thang đo tỷ lệ (Ratio Scale). Ví dụ: Mức thu nhập được đo lường bằng con số tỷ lệ chính xác (VNĐ/USD); Giới tính được mã hóa nhị phân (0-1) theo danh mục.
- Đo lường gián tiếp thông qua biến đại diện (Proxy Variables): Đối với các biến nhiễu tiềm ẩn, không thể quan sát trực tiếp được (Ví dụ: Mức độ tự tin, Định kiến xã hội, Áp lực công việc), nhà nghiên cứu phải sử dụng các Thang đo khoảng (Interval Scale) như Likert 5 điểm hoặc 7 điểm thông qua bảng hỏi chuẩn hóa. Các chỉ số Cronbach’s Alpha của thang đo biến nhiễu cũng phải đạt chuẩn > 0.7 để đảm bảo độ tin cậy trước khi đưa vào mô hình làm biến kiểm soát (Control Variable).
- Đánh giá kiểm soát thông qua độ phù hợp của cấu trúc: Đặc biệt, khi sử dụng Mô hình phương trình cấu trúc (SEM – Structural Equation Modeling) để đánh giá tổng thể mối quan hệ và kiểm soát nhiễu, hệ thống đòi hỏi phải kiểm tra độ phù hợp của mô hình (GoF – Goodness of Fit). Để chứng minh mô hình dữ liệu không bị sai lệch quá mức bởi nhiễu, các chỉ số bắt buộc cần đạt chuẩn bao gồm giá trị SRMR ≤ 0.08, và chỉ số GFI ≥ 0.90. Đồng thời, mô hình phải duy trì mức R² (Hệ số xác định) và Q² (Khả năng dự báo) ở các ngưỡng có ý nghĩa thống kê nhằm khẳng định năng lực giải thích của các biến độc lập cốt lõi sau khi đã tách bạch ảnh hưởng của biến nhiễu.
5. Các nghiên cứu liên quan tiêu biểu (Related Studies)
Dưới đây là các công trình khoa học nền tảng cung cấp bằng chứng thực chứng về sự ảnh hưởng của biến nhiễu và cách xử lý chúng:
- Nhóm 1 – Các bài báo nền tảng (Foundational Works): * Fisher, R. A. (1935). The Design of Experiments. Đây là công trình khai sinh ra phương pháp thiết kế thực nghiệm chuẩn mực. Fisher đã thiết lập tiêu chuẩn cốt lõi về ngẫu nhiên hóa (Randomized Controlled Trials – RCTs), biến nó thành tiêu chuẩn vàng (gold standard) trong nghiên cứu nhằm triệt tiêu biến nhiễu từ gốc, trước cả khi thu thập số liệu.
- Nhóm 2 – Ứng dụng trong Y tế dự phòng và Hành vi con người: * Breslow, N. E., & Day, N. E. (1980). Statistical Methods in Cancer Research. Công trình này phân tích một loạt dữ liệu khổng lồ về mối liên hệ giữa việc uống cà phê và bệnh ung thư tuyến tụy. Các tác giả đã chỉ ra một cách thuyết phục rằng “Hút thuốc lá” chính là một biến nhiễu kinh điển. Những người uống nhiều cà phê thường có xu hướng hút nhiều thuốc lá. Khi đưa biến “hút thuốc lá” vào kiểm soát, mối tương quan giữa cà phê và ung thư biến mất hoàn toàn, chứng minh sự nguy hiểm của tương quan giả mạo.
- Nhóm 3 – Phân tích tổng hợp (Meta-Analysis) hoặc Đánh giá hệ thống: * Egger, M., et al. (1997). Bias in meta-analysis detected by a simple, graphical test. Nghiên cứu thiết lập cách nhận diện các sai lệch hệ thống (bias) và nhiễu trong các bài đánh giá hệ thống quy mô lớn. Công trình củng cố độ tin cậy của việc áp dụng các phễu sai lệch để kiểm tra tính đồng nhất của dữ liệu, qua đó loại bỏ tác động nhiễu từ các nghiên cứu chất lượng thấp.

6. Những mặt hạn chế và khoảng trống nghiên cứu (Limitations)
Không có lý thuyết thống kê hay phương pháp luận nào là hoàn hảo. Việc kiểm soát tuyệt đối yếu tố nhiễu đối mặt với những giới hạn khắc nghiệt trong thực tế:
- Hạn chế về bối cảnh (Contextual Limitations): Trong các nghiên cứu quan sát (Observational studies) hoặc trong lĩnh vực kinh tế học vĩ mô, việc thực hiện can thiệp ngẫu nhiên hóa đối tượng là điều bất khả thi về mặt đạo đức, thời gian và tài chính. Nhà nghiên cứu bị giới hạn trong việc chỉ có thể thu thập dữ liệu lịch sử có sẵn. Điều này khiến cấu trúc dữ liệu bản chất đã chứa đựng sự thiên lệch, dẫn đến rủi ro bỏ sót biến nhiễu luôn tồn tại dai dẳng.
- Hạn chế về đo lường (Measurement Limits): Khoảng trống lớn nhất nằm ở vấn đề biến nhiễu chưa được đo lường (Unmeasured Confounders). Các biến số mang tính tâm lý cá nhân phức tạp, chuẩn mực văn hóa ngầm, hoặc các yếu tố di truyền chưa được y học phát hiện thường bị bỏ qua hoàn toàn trong bộ câu hỏi. Hậu quả là, tác động của chúng bị gộp chung vào phần dư, dẫn đến sai lệch hệ số góc trong phương trình hồi quy.
- Hạn chế về giả định (Assumption Limits): Việc áp dụng lý thuyết biến nhiễu đòi hỏi người thực hiện phải thiết lập đúng sơ đồ lý thuyết. Nếu xác định sai cấu trúc Biểu đồ nhân quả (DAGs), nhà nghiên cứu có thể mắc phải lỗi “kiểm soát quá mức” (Over-adjustment bias). Tức là, họ vô tình đưa nhầm một biến trung gian vào mô hình và xử lý nó như một biến nhiễu. Hành động này sẽ khóa chặt cơ chế truyền dẫn, làm triệt tiêu hoàn toàn hiệu ứng thực sự của biến độc lập lên biến phụ thuộc.
7. Các hướng nghiên cứu (Research Applications)
Biến nhiễu không chỉ là một vấn đề cần giải quyết triệt để mà còn đóng vai trò mở ra nhiều hướng nghiên cứu tích hợp mang tính đột phá:
- Kết hợp với Machine Learning (Học máy) và Big Data: Ứng dụng các thuật toán học sâu (Deep Learning) hoặc rừng ngẫu nhiên (Random Forest) để tự động hóa quá trình trích xuất, phát hiện và nhận diện các mẫu (patterns) của biến nhiễu tiềm ẩn từ các tập dữ liệu phi cấu trúc khổng lồ. Cách tiếp cận này giúp vượt qua giới hạn của các phương pháp hồi quy tuyến tính truyền thống, vốn đòi hỏi con người phải chỉ định sẵn biến nhiễu.
- Ứng dụng Phương pháp Biến công cụ (Instrumental Variables – IV): Đẩy mạnh kết hợp lý thuyết kiểm soát nhiễu với kinh tế lượng hiện đại (Econometrics). Hướng nghiên cứu này tập trung vào việc tìm kiếm một biến công cụ (Z) có tác động mạnh đến biến độc lập (X), nhưng hoàn toàn độc lập với phần dư và không tác động trực tiếp lên biến phụ thuộc (Y). Phương pháp này giúp phân tách hoàn toàn phần biến thiên nội sinh do biến nhiễu gây ra, giải quyết triệt để rủi ro từ các biến nhiễu không quan sát được.
8. Cách ứng dụng lý thuyết vào thực tiễn doanh nghiệp (Practical Application)
Nhà quản trị cấp cao hoàn toàn có thể áp dụng trực tiếp nguyên lý kiểm soát biến nhiễu để xây dựng bộ công cụ tư duy, phục vụ cho quá trình ra quyết định chiến lược dựa trên dữ liệu thật (Data-driven decision making):
Ứng dụng trong việc ra quyết định chiến lược Marketing (A/B Testing)
Khi doanh nghiệp tiến hành thử nghiệm A/B để đánh giá hiệu quả của hai mẫu quảng cáo khác nhau, quản lý phải đảm bảo tệp khách hàng hiển thị được hệ thống phân bổ hoàn toàn ngẫu nhiên. Cần nghiêm ngặt loại bỏ các biến nhiễu như “Thời gian chạy quảng cáo”, “Khung giờ vàng” hoặc “Sự kiện lễ hội”. Nếu không kiểm soát, các yếu tố nhiễu này sẽ làm phình to tỷ lệ chuyển đổi (Conversion Rate) của một mẫu quảng cáo, khiến doanh nghiệp đốt ngân sách vào một chiến dịch thực tế không mang lại hiệu quả cấu trúc.
Ứng dụng trong quản trị rủi ro và đánh giá năng lực nhân sự (HR Performance)
Khi ban giám đốc đánh giá KPI định kỳ của đội ngũ nhân viên bán hàng, việc chỉ nhìn vào doanh thu là một sai lầm phân tích dữ liệu. Người quản lý cần đưa các biến nhiễu như “Đặc thù kinh tế của khu vực địa lý được giao”, “Mức độ cạnh tranh của đối thủ tại vùng đó” hoặc “Ngân sách Marketing hỗ trợ riêng cho khu vực” vào phương trình kiểm soát. Phân tầng dữ liệu hiệu suất theo từng cụm đặc tính giúp việc ra quyết định thưởng/phạt hoặc thăng tiến công bằng và khách quan hơn, phản ánh đúng năng lực thực sự của nhân viên.
Ứng dụng trong tối ưu hóa quy trình hệ thống sản xuất
Khi nhà máy ghi nhận tỷ lệ sản phẩm lỗi (Defect rate) tăng cao trên dây chuyền, các kỹ sư cần phân tích số liệu dựa trên mô hình đa biến. Các yếu tố thường bị xem nhẹ như “Độ ẩm môi trường không khí tại xưởng”, “Nhiệt độ ca làm việc” hay “Sự mệt mỏi của ca đêm” là những biến nhiễu kinh điển làm sai lệch kết luận. Bằng cách thiết lập mô hình hồi quy kiểm soát nhiễu, nhà máy sẽ xác định chính xác bộ phận máy móc nào mới là nguyên nhân gốc rễ (Root cause) gây ra lỗi, thay vì đổ lỗi sai cho vật liệu hoặc nhân công.
9. Các câu hỏi thường gặp (FAQ)
Làm thế nào để nhận biết một cách chuẩn xác một biến số có phải là biến nhiễu hay không?
Để được phân loại là biến nhiễu, yếu tố đó bắt buộc phải thỏa mãn đồng thời 3 điều kiện thống kê: Nó phải có sự tương quan toán học với biến độc lập; nó phải có sự tương quan với biến phụ thuộc (hiệu ứng này tồn tại ngay cả khi không có mặt biến độc lập); và tuyệt đối không được là hệ quả trực tiếp của biến độc lập (nghĩa là không nằm trên con đường nhân quả kết nối biến độc lập đến biến phụ thuộc).
Nếu mô hình nghiên cứu mắc phải biến nhiễu không đo lường được (Unmeasured Confounder) thì phải làm sao?
Đối với dữ liệu đã thu thập xong, giải pháp tối ưu nhất là sử dụng phương pháp Biến công cụ (Instrumental Variable) để bóc tách nhiễu. Nếu không tìm được biến công cụ phù hợp, nhà nghiên cứu bắt buộc phải tiến hành Phân tích độ nhạy (Sensitivity Analysis). Phân tích này sử dụng thuật toán mô phỏng để đánh giá xem một biến nhiễu giả định cần phải có sức mạnh tác động lớn đến mức nào mới đủ khả năng làm vô hiệu hóa các kết luận nhân quả hiện tại của nghiên cứu.
Hệ số R-squared (R²) đạt mức rất cao có đồng nghĩa với việc mô hình đã loại bỏ hoàn toàn rủi ro từ biến nhiễu?
Hoàn toàn không. Việc đạt được hệ số R² cao chỉ cung cấp thông tin toán học rằng các biến độc lập trong mô hình giải thích được một tỷ lệ phần trăm lớn sự biến thiên của biến phụ thuộc. Nó không cung cấp bất kỳ bằng chứng nào đảm bảo mối quan hệ đó là nhân quả thực sự. Một cấu trúc dữ liệu bị lỗi, chứa biến nhiễu tạo ra “tương quan giả mạo” cực mạnh, vẫn có khả năng đẩy giá trị R² lên mức rất cao, đánh lừa cả hệ thống thuật toán và người quan sát.
10. Kết luận
Biến nhiễu không chỉ đơn thuần là một thuật ngữ thống kê mang tính chất hàn lâm và lý thuyết, mà bản chất của nó chính là một lăng kính thực chứng quan trọng giúp nhà khoa học và nhà quản trị loại bỏ các ảo giác dữ liệu (Data illusion). Việc thiết lập một cấu trúc phân tích dữ liệu minh bạch, nhận diện sớm và áp dụng các mô hình kiểm soát chặt chẽ các yếu tố nhiễu đóng vai trò quyết định trực tiếp đến độ tin cậy của các chiến lược vận hành doanh nghiệp cũng như chất lượng của các kết luận học thuật. Hiểu rõ và làm chủ các phương pháp đo lường, phân tầng biến nhiễu là nền tảng cốt lõi không thể thiếu để triển khai và thực hiện các dự án nghiên cứu khoa học đạt tiêu chuẩn khắt khe, duy trì tính khách quan tuyệt đối và mang lại những giá trị ứng dụng bền vững cho xã hội.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



