
Sai lầm loại 1 và Sai lầm loại 2 là hai rủi ro cơ bản trong kiểm định giả thuyết thống kê. Nguyên nhân chính là do tính giới hạn của dữ liệu mẫu so với tổng thể. Giải pháp nhanh nhất để tối ưu hóa độ tin cậy của quyết định là kiểm soát mức ý nghĩa Alpha (5%) và tối ưu hóa cỡ mẫu nghiên cứu.
1. Tổng quan về Kiểm định giả thuyết thống kê (Hypothesis Testing)
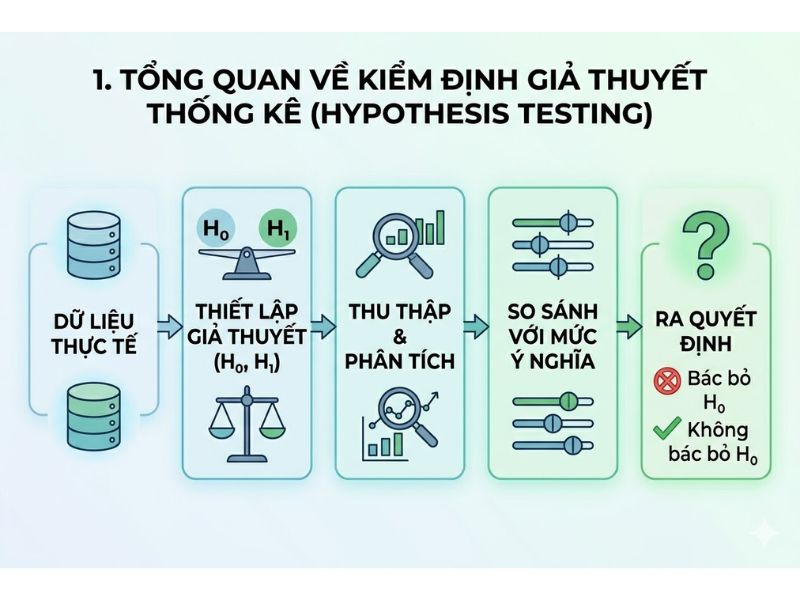
Kiểm định giả thuyết thống kê (Hypothesis Testing) là một phương pháp suy luận phân tích, sử dụng dữ liệu từ một mẫu (sample) để đưa ra các kết luận về đặc tính của toàn bộ tổng thể (population). Phương pháp này đóng vai trò cốt lõi trong nghiên cứu định lượng.
1.1. Giả thuyết không (H0) và Giả thuyết đối (H1)
Trong mọi quy trình kiểm định, nhà nghiên cứu phải thiết lập hai giả thuyết đối lập nhau:
- Giả thuyết không (H0 – Null Hypothesis): Thường là giả thuyết cho rằng không có sự khác biệt, không có mối liên hệ, hoặc không có tác động giữa các biến số đang xét.
- Giả thuyết đối (H1 – Alternative Hypothesis): Là giả thuyết phủ định lại H0, cho rằng thực sự tồn tại một sự khác biệt hoặc một mối liên hệ có ý nghĩa thống kê.
Mục đích chính của quá trình kiểm định là sử dụng các bằng chứng từ dữ liệu thu thập được để quyết định xem có đủ cơ sở để bác bỏ H0 hay không.
1.2. Bản chất của sự sai số trong quyết định thống kê
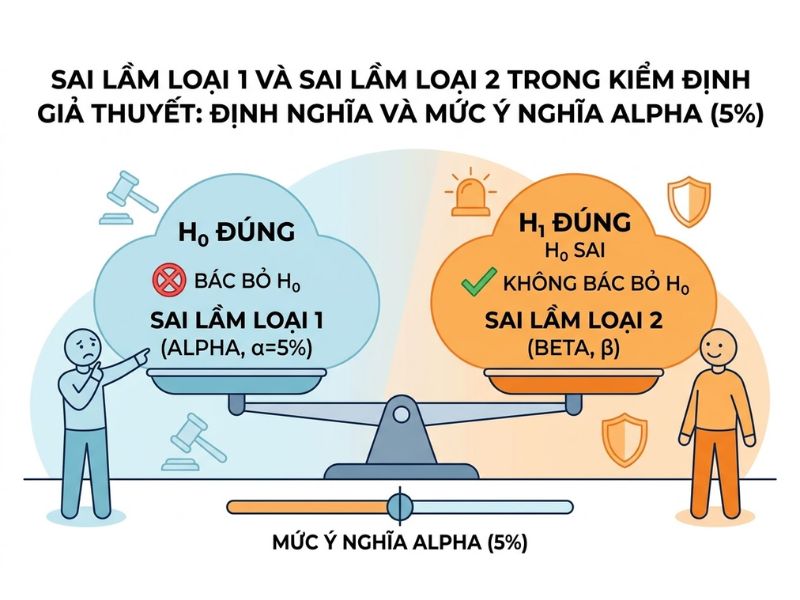
Bất kỳ quyết định thống kê nào dựa trên dữ liệu mẫu đều chứa đựng rủi ro xảy ra sai số. Do nhà nghiên cứu không thể đo lường toàn bộ tổng thể, họ phải chấp nhận một tỷ lệ xác suất sai lệch nhất định khi suy luận từ mẫu. Điều này trực tiếp dẫn đến việc hình thành hai loại sai số cơ bản là Sai lầm loại 1 và Sai lầm loại 2.
2. Sai lầm loại 1 (Type I Error) là gì?
2.1. Định nghĩa Sai lầm loại 1 (Bác bỏ giả thuyết đúng)
Sai lầm loại 1 (Type I Error) xảy ra khi kết quả kiểm định dẫn đến quyết định bác bỏ giả thuyết đúng. Cụ thể, nhà nghiên cứu bác bỏ Giả thuyết không (H0) trong khi thực tế trên tổng thể, H0 là hoàn toàn đúng.
Trong các mô hình phân loại, Sai lầm loại 1 tương đương với hiện tượng Dương tính giả (False Positive). Tức là hệ thống cảnh báo có một hiệu ứng hoặc sự khác biệt tồn tại, nhưng thực tế hiệu ứng đó hoàn toàn không có.
2.2. Khái niệm mức ý nghĩa Alpha (α) và tiêu chuẩn 5%
Xác suất tối đa cho phép xảy ra Sai lầm loại 1 được gọi là Xác suất Alpha (α). Trong hầu hết các nghiên cứu khoa học, mức ý nghĩa Alpha (5%), tức α = 0.05, được sử dụng làm tiêu chuẩn mặc định.
- Việc thiết lập α = 0.05 có nghĩa là nhà nghiên cứu chấp nhận 5% rủi ro kết luận sai rằng có sự tác động/khác biệt (bác bỏ H0) trong khi thực tế là không có.
- Chỉ số P-value được tính toán từ dữ liệu mẫu sẽ được so sánh trực tiếp với mức Alpha này. Nếu P-value < 0.05, nhà nghiên cứu có đủ bằng chứng để bác bỏ H0.

3. Sai lầm loại 2 (Type II Error) là gì?
3.1. Định nghĩa Sai lầm loại 2 (Chấp nhận giả thuyết sai)
Sai lầm loại 2 (Type II Error) xảy ra khi kết quả kiểm định dẫn đến quyết định chấp nhận giả thuyết sai (nói chính xác hơn là không thể bác bỏ H0). Tức là, nhà nghiên cứu giữ lại Giả thuyết không (H0) trong khi thực tế H0 sai và Giả thuyết đối (H1) mới là sự thật.
Hiện tượng này được gọi là Âm tính giả (False Negative). Hệ thống kết luận không có hiệu ứng hoặc sự khác biệt nào, nhưng thực tế sự khác biệt đó đang tồn tại trong tổng thể.
3.2. Xác suất Beta (β) và Lực kiểm định (Statistical Power)
Xác suất xảy ra Sai lầm loại 2 được ký hiệu là Xác suất Beta (β). Từ khái niệm Beta, giới thống kê xây dựng một thước đo quan trọng khác là Lực kiểm định (Statistical Power), được tính bằng công thức (1 – β).
- Lực kiểm định đại diện cho khả năng kiểm định phát hiện ra một hiệu ứng có thực (tức là khả năng bác bỏ chính xác một H0 sai).
- Mức Statistical Power tiêu chuẩn trong nghiên cứu thường được đặt ở mức 0.8 (80%), tương đương với việc chấp nhận rủi ro mắc Sai lầm loại 2 (β) là 20%.

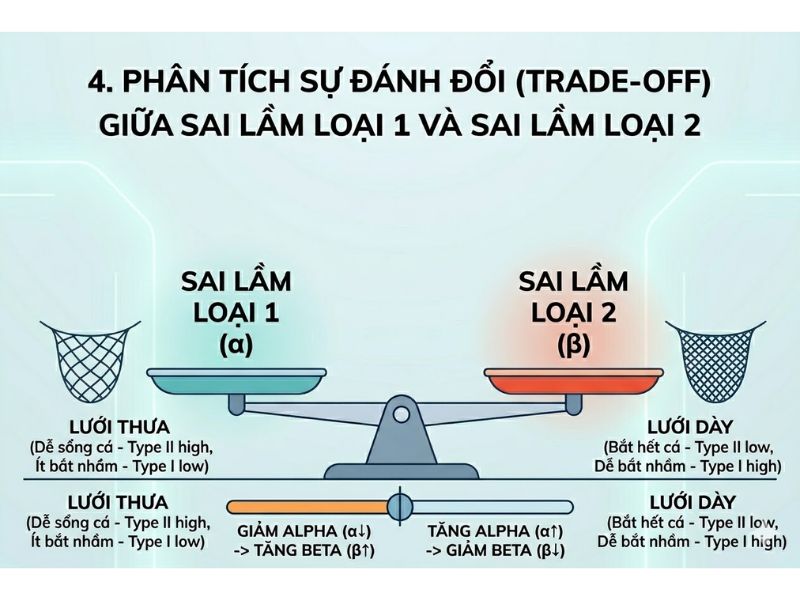
4. Phân tích sự đánh đổi (Trade-off) giữa Sai lầm loại 1 và Sai lầm loại 2
Trong kiểm định thống kê, luôn tồn tại một mối quan hệ nghịch đảo (Trade-off) giữa Sai lầm loại 1 và Sai lầm loại 2. Khi giữ nguyên Cỡ mẫu (Sample size), bất kỳ nỗ lực nào nhằm giảm thiểu rủi ro mắc Sai lầm loại 1 (giảm Alpha từ 0.05 xuống 0.01) sẽ tự động làm tăng rủi ro mắc Sai lầm loại 2 (tăng Beta) và ngược lại.
Để hiểu rõ sự khác biệt và mối quan hệ này, hãy xem xét bảng so sánh dữ liệu có cấu trúc dưới đây:
| Tiêu chí phân tích | Sai lầm loại 1 (Type I Error) | Sai lầm loại 2 (Type II Error) |
| Bản chất quyết định | Bác bỏ H0 khi H0 đúng | Không bác bỏ H0 khi H0 sai |
| Thuật ngữ tương đương | Dương tính giả (False Positive) | Âm tính giả (False Negative) |
| Ký hiệu xác suất | Alpha (α) | Beta (β) |
| Hệ quả đo lường | Báo cáo một hiệu ứng không tồn tại | Bỏ lỡ một hiệu ứng thực sự tồn tại |
| Mức độ kiểm soát | Do nhà nghiên cứu tự thiết lập (thường 5%) | Phụ thuộc vào Alpha, cỡ mẫu và độ lớn hiệu ứng |
Giải pháp duy nhất để có thể giảm đồng thời cả Alpha và Beta là tăng Cỡ mẫu (Sample size), cung cấp cho kiểm định nhiều thông tin hơn để phản ánh chính xác tổng thể.
5. Ứng dụng thực tiễn trong Nghiên cứu khoa học và Ra quyết định
5.1. Sai lầm loại 1 và loại 2 trong Y học và Dược lý
Trong lĩnh vực y tế, việc phân tích hệ quả của Sai lầm loại 1 và Sai lầm loại 2 ảnh hưởng trực tiếp đến sinh mạng và sức khỏe con người:
- Ví dụ về Type I Error: Một loại thuốc mới hoàn toàn không có tác dụng chữa bệnh, nhưng kết quả kiểm định sai lầm (Dương tính giả) lại kết luận thuốc có hiệu quả và đưa vào sản xuất. Hệ quả là bệnh nhân tốn tiền nhưng không được chữa trị đúng cách.
- Ví dụ về Type II Error: Thuốc có khả năng chữa khỏi bệnh, nhưng kết quả nghiên cứu lại không phát hiện ra hiệu ứng này (Âm tính giả) và loại bỏ thuốc. Hệ quả là bỏ lỡ một phương pháp điều trị tiềm năng.
5.2. Tác động của các sai lầm thống kê trong Quản trị kinh doanh
Đối với hoạt động kinh doanh, đặc biệt là trong các chiến dịch Marketing thông qua A/B Testing, nhà quản trị cần đưa ra quyết định dựa trên dữ liệu thay vì cảm tính:
- Nếu mắc Sai lầm loại 1, doanh nghiệp sẽ đầu tư ngân sách lớn để triển khai một chiến dịch quảng cáo hoặc một tính năng sản phẩm mới không hề mang lại hiệu quả chuyển đổi như báo cáo.
- Nếu mắc Sai lầm loại 2, doanh nghiệp sẽ loại bỏ một chiến lược tiềm năng mang lại lợi nhuận cao chỉ vì dữ liệu kiểm định hiện tại chưa đủ mạnh để chứng minh hiệu quả.
6. Kết luận
Việc hiểu và kiểm soát Sai lầm loại 1 và Sai lầm loại 2 là nền tảng bắt buộc để đảm bảo độ tin cậy của các mô hình phân tích dữ liệu. Bằng cách cân đối giữa mức ý nghĩa Alpha (5%) và Lực kiểm định, đồng thời tối ưu hóa cỡ mẫu, các nhà phân tích có thể đưa ra quyết định khách quan, giảm thiểu rủi ro “bác bỏ giả thuyết đúng” hoặc “chấp nhận giả thuyết sai”. Đây là giá trị cốt lõi của việc áp dụng chặt chẽ các nguyên lý thống kê vào nghiên cứu khoa học, giúp kiến tạo các chiến lược có tính xác thực cao trong cả môi trường hàn lâm và thực tiễn doanh nghiệp.
7. FAQ – Các câu hỏi thường gặp về Sai số thống kê
Giữa Sai lầm loại 1 và Sai lầm loại 2, loại nào nghiêm trọng hơn?
Khái niệm mức độ nghiêm trọng phụ thuộc hoàn toàn vào ngữ cảnh cụ thể của từng bài toán. Trong y tế, Sai lầm loại 1 (đưa thuốc độc hại/vô dụng ra thị trường) thường nghiêm trọng hơn. Tuy nhiên, trong an ninh mạng hoặc chẩn đoán ung thư, Sai lầm loại 2 (không phát hiện ra virus/khối u) lại mang đến hệ quả tai hại hơn rất nhiều.
Tại sao mức ý nghĩa Alpha thường được cố định ở mức 5% mà không phải là 0%?
Không thể thiết lập Alpha bằng 0% vì điều đó đồng nghĩa với việc đòi hỏi độ tin cậy tuyệt đối 100%. Trong thống kê, trừ khi đo lường toàn bộ dân số (tổng thể), chúng ta luôn phải dựa vào dữ liệu mẫu. Việc triệt tiêu hoàn toàn Sai lầm loại 1 (Alpha = 0) sẽ đẩy Sai lầm loại 2 (Beta) lên mức tối đa, khiến kiểm định mất đi sức mạnh phân tích thực tế. Mức 5% là một sự thỏa hiệp hợp lý được giới khoa học đồng thuận.
P-value có mối liên hệ như thế nào với Sai lầm loại 1?
P-value chính là xác suất thực tế thu được từ dữ liệu mẫu. Nếu P-value nhỏ hơn hoặc bằng Xác suất Alpha (thường là 0.05), nhà nghiên cứu sẽ quyết định bác bỏ Giả thuyết không (H0). P-value càng nhỏ, bằng chứng để bác bỏ H0 càng mạnh, và rủi ro thực tế của việc mắc Sai lầm loại 1 càng thấp.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



