
Vấn đề sai lệch trong nghiên cứu định lượng thường là do chưa kiểm soát tính không đồng nhất của thực thể. Dữ liệu mảng (Panel Data) là cấu trúc kết hợp đa chiều giữa chuỗi thời gian và dữ liệu chéo, giúp giải quyết triệt để vấn đề này. Nguyên nhân chính của các ước lượng sai là do chọn sai phương pháp. Giải pháp chuẩn xác nhất là áp dụng kỹ thuật chạy mô hình Pooled OLS, FEM, REM trên STATA kết hợp kiểm định Hausman.
1. Giới Thiệu Về Cấu Trúc Dữ Liệu Trong Nghiên Cứu Định Lượng
1.1 Khái Niệm Dữ Liệu Mảng (Panel Data)
Dữ liệu mảng (Panel Data) là loại dữ liệu thu thập các thông tin của nhiều đơn vị quan sát (thực thể/cá nhân/quốc gia/công ty) qua nhiều mốc thời gian liên tiếp. Đây là sự kết hợp chặt chẽ giữa không gian (nhiều thực thể) và thời gian (nhiều kỳ quan sát), cung cấp cái nhìn toàn diện về động thái thay đổi của các biến số kinh tế lượng.
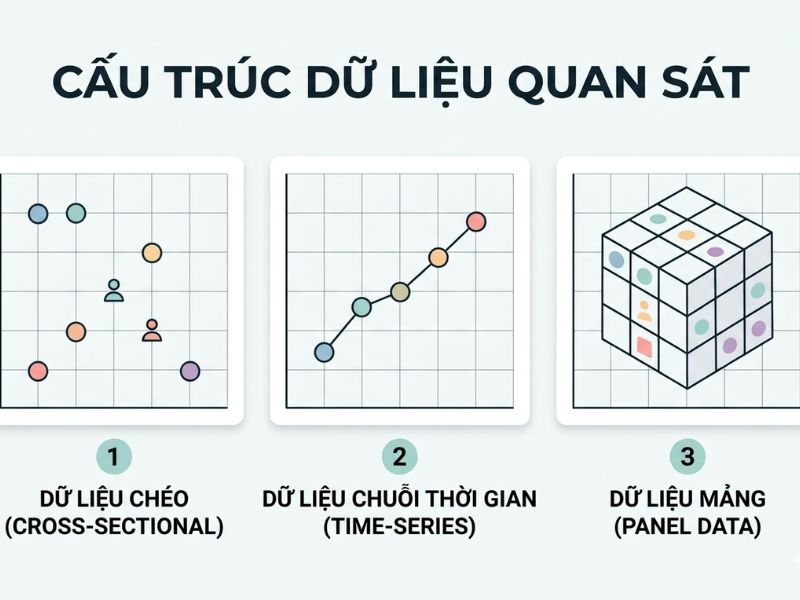
1.2 Phân Biệt Dữ Liệu Chéo (Cross-sectional), Dữ Liệu Chuỗi Thời Gian (Time-series) Và Dữ Liệu Mảng
Việc nhận diện chính xác cấu trúc dữ liệu quyết định việc lựa chọn mô hình phân tích. Tiêu chí phân biệt cốt lõi dựa vào số lượng đơn vị quan sát (i) và số mốc thời gian (t).
| Tiêu chí | Dữ liệu chéo (Cross-sectional) | Dữ liệu chuỗi thời gian (Time-series) | Dữ liệu mảng (Panel Data) |
| Đơn vị quan sát (i) | Nhiều thực thể (i > 1) | Một thực thể duy nhất (i = 1) | Nhiều thực thể (i > 1) |
| Mốc thời gian (t) | Một thời điểm duy nhất (t = 1) | Nhiều mốc thời gian (t > 1) | Nhiều mốc thời gian (t > 1) |
| Mục tiêu nghiên cứu | So sánh sự khác biệt giữa các thực thể | Phân tích xu hướng, dự báo tương lai | Phân tích sự thay đổi qua thời gian của nhiều thực thể |
| Vấn đề thống kê thường gặp | Phương sai sai số thay đổi (Heteroskedasticity) | Tự tương quan (Autocorrelation) | Cả phương sai sai số thay đổi và tự tương quan |
1.3 Ưu Điểm Vượt Trội Của Dữ Liệu Mảng
- Kiểm soát tính không đồng nhất (Heterogeneity): Dữ liệu mảng cho phép kiểm soát các đặc điểm riêng biệt của từng thực thể không đo lường được (ví dụ: văn hóa doanh nghiệp, năng lực quản lý), giúp loại bỏ biến nội sinh.
- Tăng bậc tự do (Degrees of freedom): Với số lượng quan sát lớn (n × t), dữ liệu mảng cung cấp nhiều thông tin hơn, tăng bậc tự do và cải thiện tính hiệu quả (efficiency) của các ước lượng.
- Giảm hiện tượng đa cộng tuyến (Multicollinearity): Biến động đa chiều giúp giảm thiểu sự tương quan cao giữa các biến độc lập so với việc chỉ sử dụng dữ liệu chuỗi thời gian.
2. Lý Thuyết Về Các Mô Hình Hồi Quy Dữ Liệu Mảng Cơ Bản
2.1 Mô Hình Bình Phương Tối Thiểu Gộp (Pooled OLS)
- Giả định cơ bản: Pooled OLS giả định rằng hoàn toàn không có sự khác biệt về mặt đặc tính cá nhân hoặc thời gian giữa các đơn vị quan sát. Tất cả các dữ liệu được gộp chung thành một tệp dữ liệu chéo khổng lồ.
- Hạn chế: Mô hình này bỏ qua tính không đồng nhất của thực thể. Việc bỏ sót các biến đặc thù (Omitted variable bias) sẽ gom các đặc điểm này vào phần dư (random error term), làm cho các ước lượng OLS bị chệch và không nhất quán.
2.2 Mô Hình Tác Động Cố Định (Fixed Effects Model – FEM)
- Cơ chế hoạt động: FEM kiểm soát mọi đặc điểm không đổi theo thời gian của từng thực thể bằng cách cho phép hệ số chặn thay đổi qua từng thực thể (i). Sự khác biệt cá thể này được xem là một “tác động cố định”.
- Phương trình toán học: Y_it = β_0 + β_1*X_it + α_i + u_it (Trong đó α_i đại diện cho đặc tính riêng không đổi theo thời gian của thực thể i).
2.3 Mô Hình Tác Động Ngẫu Nhiên (Random Effects Model – REM)
- Cơ chế hoạt động: REM giả định rằng sự khác biệt giữa các thực thể (α_i) là ngẫu nhiên và hoàn toàn không tương quan với bất kỳ biến độc lập nào trong mô hình.
- Điều kiện áp dụng: Mô hình này cung cấp các ước lượng có tính hiệu quả cao (phương sai nhỏ) hơn FEM, nhưng chỉ đáng tin cậy (nhất quán) khi giả định không có sự tương quan giữa phần dư và biến độc lập được thỏa mãn.

3. Hướng Dẫn Thực Hành: Cách Chạy Mô Hình Pooled OLS, FEM, REM Trên STATA
3.1 Khai Báo Cấu Trúc Dữ Liệu Mảng (Lệnh xtset)
Trước khi phân tích, bắt buộc phải khai báo với STATA về cấu trúc dữ liệu (thiết lập biến thực thể và biến thời gian).
- Cú pháp: xtset panel_variable time_variable
- (Ví dụ: xtset company_id year)
3.2 Lệnh Ước Lượng Mô Hình Pooled OLS
- Cú pháp: reg Y X1 X2 X3
- Diễn giải tham số: Đọc hệ số Coef., p-value (P>|t|) và R² (R-squared) để đánh giá mức độ giải thích của biến độc lập đối với biến phụ thuộc theo nguyên tắc OLS truyền thống.
3.3 Lệnh Ước Lượng Mô Hình Tác Động Cố Định (FEM)
- Cú pháp: xtreg Y X1 X2 X3, fe
- Diễn giải tham số: Hậu tố fe chỉ định mô hình Fixed Effects. Chú ý đến giá trị rho (tỷ lệ phương sai do khác biệt cá thể gây ra) và p-value của kiểm định F ở cuối bảng kết quả để đánh giá ý nghĩa tổng thể.
3.4 Lệnh Ước Lượng Mô Hình Tác Động Ngẫu Nhiên (REM)
- Cú pháp: xtreg Y X1 X2 X3, re
- Hậu tố re chỉ định mô hình Random Effects. STATA sẽ xuất ra các hệ số hồi quy dưới giả định các tác động cá thể là một biến ngẫu nhiên. Sau bước này, phải lưu kết quả để tiến hành kiểm định.

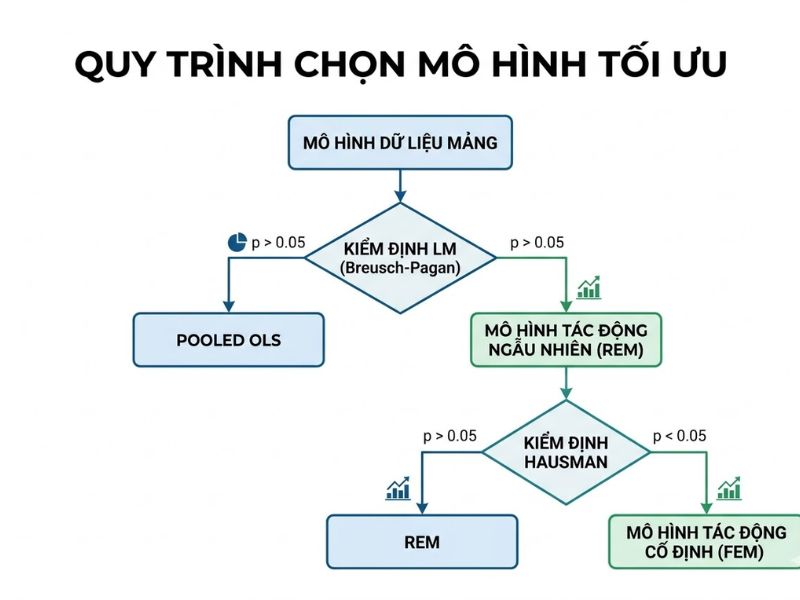
4. Quy Trình Kiểm Định Lựa Chọn Mô Hình Tối Ưu Trong STATA
4.1 Lựa Chọn Giữa Pooled OLS Và FEM: Kiểm Định F (F-test)
- Cơ sở: STATA tự động thực hiện kiểm định F ở dòng cuối cùng sau khi chạy lệnh xtreg …, fe.
- Quyết định: Nếu p-value < 0.05, bác bỏ giả thuyết H0 (tất cả α_i = 0). Kết luận mô hình FEM phù hợp hơn Pooled OLS.
4.2 Lựa Chọn Giữa Pooled OLS Và REM: Kiểm Định Breusch-Pagan Lagrange Multiplier (LM Test)
- Cú pháp lệnh: xttest0 (chạy ngay sau mô hình REM).
- Quyết định: Nếu p-value < 0.05, bác bỏ giả thuyết H0 (phương sai của các sai số cá thể bằng 0). Kết luận mô hình REM phù hợp hơn Pooled OLS.
4.3 Lựa Chọn Giữa FEM Và REM: Kiểm Định Hausman
Đây là kiểm định kinh tế lượng quan trọng nhất để chọn giữa FEM và REM.
- Giả thuyết H0: Không có sự tương quan giữa sai số đặc thù của thực thể (α_i) và các biến độc lập (Mô hình REM phù hợp).
- Cú pháp thực hiện trên STATA:
- Bước 1: xtreg Y X1 X2, fe
- Bước 2: estimates store fixed
- Bước 3: xtreg Y X1 X2, re
- Bước 4: estimates store random
- Bước 5: hausman fixed random
- Quy tắc ra quyết định: Nếu p-value của kiểm định Hausman < 0.05, bác bỏ H0. Ta ưu tiên chọn mô hình FEM (để đảm bảo tính nhất quán). Nếu p-value > 0.05, chấp nhận H0 và chọn mô hình REM (để đảm bảo tính hiệu quả).
5. Kết Luận
Việc nắm vững lý thuyết dữ liệu mảng (Panel Data) là yêu cầu tiên quyết trong nghiên cứu kinh tế lượng hiện đại. Phân biệt rõ dữ liệu mảng với dữ liệu chéo và chuỗi thời gian giúp nhà nghiên cứu xác định đúng phương pháp ước lượng. Quy trình chạy và kiểm định các mô hình Pooled OLS, FEM, REM trên STATA thông qua kiểm định Hausman và LM Test đảm bảo loại bỏ các sai lệch thống kê, từ đó cung cấp những bằng chứng khoa học có tính xác thực và độ tin cậy cao nhất cho các chiến lược quản trị và kinh tế.
6. Câu Hỏi Thường Gặp (FAQ Về Dữ Liệu Mảng Và STATA)
Dữ liệu mảng không cân bằng (Unbalanced Panel Data) là gì và STATA có xử lý được không?
Dữ liệu mảng không cân bằng là cấu trúc dữ liệu mà một số thực thể bị thiếu dữ liệu ở một vài mốc thời gian. STATA hoàn toàn có thể xử lý loại dữ liệu này bằng các lệnh xtreg tương tự như mảng cân bằng, tuy nhiên số lượng quan sát thực tế đưa vào mô hình sẽ tự động bị giảm trừ đi phần dữ liệu khuyết.
Phải làm gì khi mô hình dữ liệu mảng bị tự tương quan (autocorrelation) hoặc phương sai sai số thay đổi (heteroskedasticity)?
Cần sử dụng sai số chuẩn mạnh (Robust Standard Errors) hoặc các ước lượng Generalized Least Squares (GLS). Trên STATA, bạn có thể thêm hậu tố robust (ví dụ: xtreg Y X, fe robust) để khắc phục hiện tượng phương sai thay đổi, hoặc dùng lệnh xtgls để xử lý đồng thời cả hai khuyết tật thống kê này.
Có thể chạy kiểm định Hausman với sai số robust không?
Kiểm định Hausman tiêu chuẩn không hỗ trợ option robust trực tiếp trong STATA. Để kiểm định Hausman khi có phương sai thay đổi, bạn phải sử dụng lệnh chuyên dụng thay thế là phương pháp kiểm định dựa trên hồi quy phụ (artificial regression) như lệnh xtoverid hoặc lệnh suest.
Làm thế nào để đánh giá độ phù hợp của mô hình định lượng (Model Fit) khi mở rộng nghiên cứu?
Ngoài việc quan tâm đến hệ số xác định R², cần xem xét thêm các chỉ số độ phù hợp (Goodness of Fit) toàn cục. Trong các nghiên cứu phân tích dữ liệu nâng cao (đặc biệt khi kết hợp phân tích đường dẫn hoặc mô hình cấu trúc), để chứng minh tính vững của mô hình, các nhà nghiên cứu thường báo cáo thêm các chỉ số như GoF và Q² để đo lường năng lực dự báo ngoài mẫu. Một mô hình được đánh giá là có độ phù hợp tốt khi thỏa mãn các ngưỡng tiêu chuẩn khắt khe, ví dụ điển hình như SRMR ≤ 0.08 và GFI ≥ 0.90. Việc đảm bảo các chỉ số này giúp củng cố niềm tin vào kết quả hồi quy dữ liệu mảng.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



