
Đánh giá mô hình Generalized Structured Component Analysis (GSCA) thường gặp khó khăn do thiếu tiêu chuẩn cắt (cutoff) rõ ràng. Nguyên nhân cốt lõi là sự khác biệt nền tảng giữa GSCA (dựa trên thành phần) và phân tích nhân tố truyền thống (CB-SEM). Giải pháp tối ưu nhất cho nhà nghiên cứu là áp dụng các chỉ số độ phù hợp mô hình trong GSCA tiêu chuẩn: SRMR ≤ 0.08 và GFI ≥ 0.93 đối với cỡ mẫu trên 100 để xác định độ chính xác của mô hình.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: Cutoff criteria for overall model fit indexes in generalized structured component analysis
- Tiêu đề tiếng Việt: Tiêu chuẩn cắt cho các chỉ số độ phù hợp tổng thể mô hình trong phân tích cấu trúc thành phần tổng quát
- Tác giả: Gyeongcheol Cho, Heungsun Hwang, Marko Sarstedt, Christian M. Ringle
- Tạp chí: Journal of Marketing Analytics (2020) 8:189-202
- Lịch sử bài viết: Đã chỉnh sửa 25 tháng 5, 2020 / Xuất bản trực tuyến: 20 tháng 9, 2020
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
GSCA là một phương pháp tiếp cận thiết lập tốt về mặt kỹ thuật đối với mô hình hóa phương trình cấu trúc (SEM) dựa trên thành phần, cho phép kiểm tra các mối quan hệ giữa các biến quan sát và cấu phần của chúng. Dù phương pháp này cung cấp các chỉ số độ phù hợp mô hình trong GSCA tổng thể như GFI và SRMR, nhưng từ trước đến nay hoàn toàn chưa có nghiên cứu nào xác định hiệu suất và tiêu chuẩn cắt (cutoff criteria) của chúng trong môi trường GSCA.
Khoảng trống nghiên cứu này khiến các nhà phân tích dữ liệu gặp khó khăn khi ra quyết định chấp nhận hay bác bỏ một mô hình lý thuyết. Hầu hết các nhà nghiên cứu thường lạm dụng tiêu chuẩn của CB-SEM một cách máy móc, dẫn đến những sai lầm nghiêm trọng trong suy luận thống kê. Nghiên cứu này thực hiện một bài toán mô phỏng hệ thống để giải quyết vấn đề đó và xác định các điểm cắt tối thiểu hóa tỷ lệ sai lầm Loại I và Loại II một cách chính xác nhất.
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Để hiểu sâu, chúng ta cần phân biệt rõ hai trường phái SEM:
- Factor-based SEM (CB-SEM): Phân tích cấu trúc hiệp phương sai (CSA) giả định các biến quan sát bị chi phối bởi các nhân tố chung tiềm ẩn thay vì cấu phần. CB-SEM tập trung vào phương sai duy nhất (unique variance) bao gồm cả phương sai đặc thù và sai số đo lường ngẫu nhiên. Phương pháp này phù hợp khi các khái niệm lý thuyết tồn tại độc lập và sinh ra các biểu hiện bên ngoài.
- Component-based SEM (PLSPM và GSCA): Các khái niệm lý thuyết được đại diện bằng các biến tổng hợp (composites) hay cấu phần.
Sự khác biệt cốt lõi của GSCA: Khác với PLSPM (chia các tham số thành hai tập hợp và ước lượng tuần tự gây khó khăn trong việc đánh giá độ phù hợp), GSCA kết hợp ba mô hình con (đo lường, cấu trúc, quan hệ trọng số) thành một phương trình đại số duy nhất. Nhờ hàm mục tiêu bình phương tối thiểu duy nhất này, GSCA cho phép tính toán trực tiếp các chỉ số độ phù hợp mô hình trong GSCA tổng thể, giúp đánh giá toàn cục chất lượng mô hình một cách minh bạch.
1.4 Lịch sử hình thành và phát triển của lý thuyết
- Mô hình SEM dựa trên yếu tố: Được dẫn dắt bởi phương pháp Phân tích cấu trúc hiệp phương sai (CSA) tiêu chuẩn do Jöreskog (1970) khởi xướng.
- Mô hình SEM dựa trên cấu phần: Khởi nguồn từ Mô hình hóa đường dẫn bình phương tối thiểu một phần (PLSPM) do Wold (1982) và Lohmöller (1989) phát triển. Đến năm 2004, Hwang và Takane đã hoàn thiện phương pháp tiếp cận này bằng việc giới thiệu Phân tích cấu phần cấu trúc tổng quát (GSCA), giải quyết triệt để vấn đề tối ưu hóa cục bộ mà PLSPM gặp phải.
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Mô hình GSCA đánh giá chất lượng tổng thể thông qua hai chỉ số chính:
- GFI (Goodness-of-Fit Index): Đo lường mức độ khác biệt giữa ma trận hiệp phương sai mẫu (S) và ma trận hiệp phương sai ngụ ý từ mô hình (Σ̂). Công thức tính toán được biểu diễn dưới dạng toán học chuẩn:
GFI tiến gần 1 thể hiện mô hình khớp với dữ liệu tốt ở mức có thể chấp nhận được. Trong thực hành, đây là thước đo tỷ lệ phương sai đồng biến được giải thích bởi mô hình.
- SRMR (Standardized Root Mean Square Residual): Là phần dư bình phương trung bình chuẩn hóa, phản ánh sai số giữa dữ liệu thực tế và dữ liệu dự báo. Công thức tính toán.
SRMR tiến gần 0 chứng tỏ độ phù hợp ở mức có thể chấp nhận được, nghĩa là sai lệch dư thừa đã được thu hẹp đến mức tối thiểu.
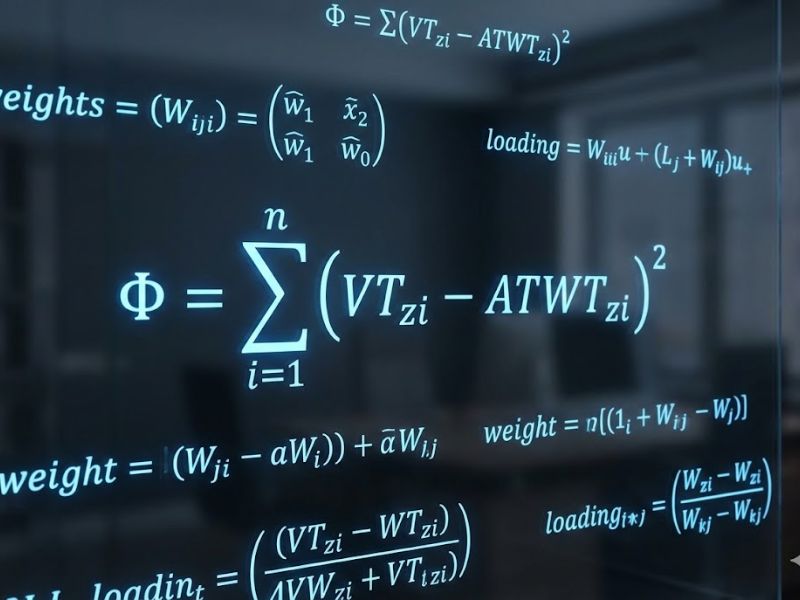
3. Cơ Sở Đặc Tả Và Ước Lượng Tham Số Toán Học Trong GSCA
Để cung cấp một đánh giá toàn diện cho các chỉ số độ phù hợp mô hình trong GSCA, đặc tả mô hình GSCA yêu cầu tích hợp toán học chặt chẽ ba mô hình con:
- Mô hình đo lường (Measurement Model): Thể hiện mối quan hệ giữa các biến quan sát z và các cấu phần γ:
(Trong đó C là ma trận hệ số tải gồm các “loadings”, ε là vectơ phần dư của z bao gồm các sai số không được giải thích bởi cấu phần).
- Mô hình cấu trúc (Structural Model): Xác định mối quan hệ nội tại giữa các cấu phần với nhau để kiểm định giả thuyết lý thuyết:
(Trong đó B là ma trận hệ số đường dẫn, ζ là vectơ phần dư của γ).- Mô hình quan hệ trọng số (Weighted Relation Model): Định nghĩa cấu phần như một biến tổng hợp tuyến tính, một đặc trưng làm nên sức mạnh của hệ thống Component-based:
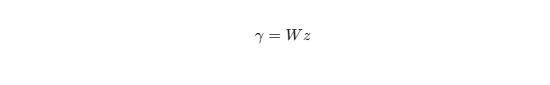
- (Trong đó W là ma trận trọng số được gán cho các biến quan sát).
Tất cả được GSCA kết hợp lại thành phương trình mô hình GSCA tổng thể để tạo ra một ma trận đồng nhất:
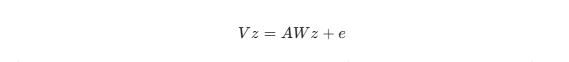
Để ước lượng tham số, hàm mục tiêu bình phương tối thiểu được sử dụng (giả định chuẩn hóa, không yêu cầu phân phối chuẩn khắt khe):
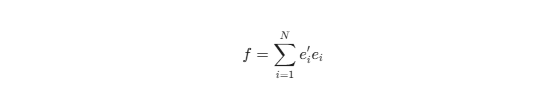
4. Quy Trình Mô Phỏng Đánh Giá Chỉ Số (Simulation Design Process)
Dưới góc độ nghiên cứu phương pháp luận, bài báo sử dụng phương pháp mô phỏng Monte Carlo để kiểm định tính hợp lý của các chỉ số:
- Cấu trúc mô hình: Thiết kế một mô hình đo lường phức tạp gồm 5 cấu phần, mỗi cấu phần có 5 biến quan sát nhằm mô phỏng lại một nghiên cứu thực chứng điển hình trong marketing.
- Tình huống kiểm định: So sánh giữa Mô hình chính xác (Correct Model) và Mô hình bị chỉ định sai (Misspecified Model – nối sai 1 hoặc 2 biến quan sát sang cấu phần khác, làm thay đổi hoàn toàn ý nghĩa thực chất của cấu phần).
- Thông số thực nghiệm: Chạy 1000 mẫu ngẫu nhiên cho mỗi điều kiện từ một phân phối chuẩn đa biến với giá trị trung bình bằng 0.
- Biến thiên cỡ mẫu (N): 100, 200, 500, 1000, và 2000.
- Biến thiên tương quan thành phần (r): 0, 0.2, và 0.4 nhằm đảm bảo tính giá trị phân biệt (discriminant validity) của mô hình.
5. Tham Số Khởi Tạo Mô Hình Đo Lường (Measurement Parameters Setup)
Để các bạn học viên dễ hình dung cách thiết lập ma trận mô phỏng dữ liệu, tác giả đã cố định các biến quan sát (Items) đóng góp tương đương vào thành phần của chúng:
| Thông số thiết lập | Giá trị gán cho 5 biến quan sát trong 1 thành phần | Ý nghĩa phương pháp luận |
| Trọng số (Weights – W) | 0.24, 0.24, 0.28, 0.32, 0.32 | Biểu thị mức độ đóng góp của từng biến quan sát để hình thành nên cấu phần tổng hợp một cách cân bằng. |
| Hệ số tải (Loadings – C) | 0.6, 0.6, 0.7, 0.8, 0.8 | Biểu thị mức độ cấu phần giải thích được phương sai của biến quan sát tương ứng (phản ánh độ tin cậy của thang đo). |
6. Phân Tích Kết Quả Tỷ Lệ Sai Lầm (Error Rate Analysis)
Dựa trên kết quả chạy mô phỏng 1000 mẫu, Bảng 1, Bảng 2 và Bảng 3 trong nghiên cứu đã cung cấp bằng chứng thống kê thực tế:
- Đối với mô hình chính xác, giá trị GFI tiến gần 1 (ví dụ: trung bình đạt > 0.90) và SRMR tiến gần 0 (ví dụ: < 0.08) khi kích thước mẫu tăng lên. Điều này khẳng định độ nhạy bén của thuật toán.
- Đối với mô hình sai lệch, GFI trung bình nhỏ hơn 0.90 ở mức tương quan r ≤ 0.2, và SRMR duy trì mức lớn hơn 0.08 trong mọi điều kiện phân tích.
- Tỷ lệ sai lầm Loại I (từ chối mô hình đúng) và Loại II (chấp nhận mô hình sai) đạt mức tối thiểu tại các điểm cắt cụ thể tùy thuộc vào cỡ mẫu (chi tiết tại mục Hướng dẫn ứng dụng). Ví dụ: Ở cỡ mẫu N = 100, việc sử dụng SRMR = 0.09 đưa tỷ lệ lỗi trung bình xuống chỉ còn 0.001.
7. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
- Tiền tố (Antecedents): Cỡ mẫu (N) và sự sai lệch mô hình (Misspecification) là các yếu tố đầu vào tác động trực tiếp đến kết quả tính toán của GFI và SRMR. Đặc biệt ở các mẫu nhỏ, các chỉ số này nhạy cảm hơn với các điểm cắt.
- Hậu tố (Consequences): Khả năng ra quyết định sai lầm của nhà nghiên cứu trong báo cáo khoa học. Việc chọn tiêu chuẩn cắt (cutoff) sẽ dẫn đến 2 loại sai lầm thực tiễn:
- Sai lầm loại I (Type I Error): Từ chối một mô hình đúng. Xảy ra rất nhiều nếu nhà nghiên cứu đặt ngưỡng cắt GFI quá cao (tiến sát 1) hoặc SRMR quá thấp ở điều kiện cỡ mẫu nhỏ (N ≤ 200).
- Sai lầm loại II (Type II Error): Không bác bỏ một mô hình sai lệch. Lỗi này được giảm thiểu tối đa khi ngưỡng cắt GFI được tinh chỉnh lớn hơn và ngưỡng cắt SRMR nhỏ hơn một cách hợp lý.
8. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Là một nhà nghiên cứu, khi bạn áp dụng phương pháp GSCA cho luận văn hay bài báo của mình, đây là bộ nguyên tắc bắt buộc khi báo cáo chỉ số độ phù hợp mô hình trong GSCA để không bị phản biện (reviewer) từ chối:
- Khảo sát có cỡ mẫu nhỏ (N = 100):
- Dùng tiêu chuẩn: GFI ≥ 0.89 và SRMR ≤ 0.09.
- Lưu ý chuyên sâu: Hãy ưu tiên dùng SRMR. Nếu SRMR ≤ 0.09, tỷ lệ lỗi trung bình (Average error rate) là thấp nhất, tốt hơn hẳn so với dùng GFI độc lập. Khi đó, nếu GFI ≥ 0.85 thì kết quả vẫn có thể được coi là phù hợp và an toàn.
- Khảo sát có cỡ mẫu vừa và lớn (N > 100):
- Dùng tiêu chuẩn: GFI ≥ 0.93 và SRMR ≤ 0.08.
- Ở cỡ mẫu này, tỷ lệ lỗi trung bình của cả hai chỉ số đều bằng không, do đó bạn có thể dùng độc lập một trong hai chỉ số để kết luận mô hình phù hợp một cách vững chắc.
Lưu ý hàn lâm: Đừng coi các ngưỡng cắt này là “quy tắc vàng” tuyệt đối cho mọi bối cảnh. Một mô hình có chỉ số phù hợp (well-fitting) hoàn toàn không đảm bảo năng lực dự báo (predictive power) hoặc tính hợp lý về mặt lý thuyết thực chất (substantive theory). Bạn cần phải kết hợp đánh giá chéo thêm các độ đo phù hợp cục bộ (local fit) như FIT_M và FIT_S để bảo vệ luận điểm của mình.
9. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Trong nghiên cứu thị trường thực tế (business intelligence), việc xác nhận độ tin cậy của mô hình là bước sống còn trước khi ra quyết định kinh doanh mang tính chiến lược:
- Tối ưu hóa mô hình đo lường: Khi thiết kế các bộ KPIs đánh giá nhân sự hoặc khảo sát sự hài lòng khách hàng, bộ phận quản trị dữ liệu có thể dùng các trọng số tuyến tính để nén dữ liệu khổng lồ. Việc đảm bảo mô hình đạt SRMR ≤ 0.08 giúp ban giám đốc hoàn toàn tin tưởng rằng dữ liệu khảo sát khách hàng đã đo lường đúng mục tiêu chiến lược, không bị pha loãng bởi yếu tố rác.
- Quản trị rủi ro chiến lược: Một mô hình bị chỉ định sai (misspecified) trong thực tế đồng nghĩa với việc bạn đang nhận định sai insight khách hàng và phân bổ ngân sách marketing sai kênh. Áp dụng chuẩn GFI ≥ 0.93 giúp loại bỏ sớm các biến số gây nhiễu, đảm bảo kết luận dựa trên lý thuyết thực chứng chính xác, từ đó gia tăng ROI và giảm rủi ro lãng phí tài nguyên.
10. Các Câu Hỏi Thường Gặp (FAQ)
Tại sao GSCA có thể tính toán độ phù hợp tổng thể (Overall Fit) còn PLSPM thì khó khăn hơn?
Trả lời: Vì GSCA tích hợp đồng thời các mô hình thành phần vào một phương trình đại số duy nhất và tối ưu hóa dựa trên một hàm mục tiêu bình phương tối thiểu tổng thể. Ngược lại, PLSPM ước lượng thông số qua hai bước tách biệt (sequential stages), nên nó hoàn toàn không có một tiêu chuẩn tối ưu hóa duy nhất nào để có thể đánh giá toàn cục một cách dễ dàng và khách quan.
Trong môi trường cỡ mẫu nhỏ, tôi nên ưu tiên báo cáo GFI hay SRMR?
Trả lời: Nên ưu tiên báo cáo SRMR. Nghiên cứu thực nghiệm chỉ ra rằng ở cỡ mẫu nhỏ (N = 100), việc sử dụng ngưỡng SRMR ≤ 0.09 mang lại tỷ lệ lỗi trung bình (Average of Type I and II error rates) thấp hơn đáng kể so với việc sử dụng GFI.
Cấu phần (Component) khác với Nhân tố chung (Common Factor) như thế nào trong phân tích?
Trả lời: Nhân tố chung trong CSA đại diện cho khái niệm lý thuyết không thể quan sát trực tiếp được và giả định luôn tồn tại sai số đo lường ngẫu nhiên riêng. Trong khi đó, Cấu phần trong GSCA/PLSPM là một biến tổng hợp có trọng số (weighted composite) được tính trực tiếp từ các biến quan sát, được thiết lập một cách có chủ đích để làm giảm sai số ngẫu nhiên khi hình thành biến.
11. Phụ Lục: Quy Trình Dẫn Xuất Ma Trận Hiệp Phương Sai Ngụ Ý (Appendix)
Dành cho các nhà nghiên cứu định lượng muốn tái tạo mô phỏng toán học trong R hoặc Python, giả sử Zₚ là vectơ của các biến quan sát cấu thành cấu phần thứ p và Σₚ là ma trận hiệp phương sai của nó. Trọng số wₚ và hệ số tải cₚ được xác định để tối đa hóa phương sai giải thích:
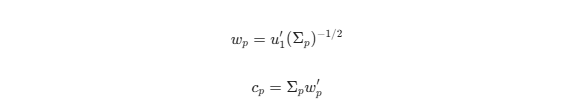
(Trong đó u₁ là eigenvector (vectơ riêng) đầu tiên của Σₚ). Từ đó, ma trận hiệp phương sai phần dư Ψₚ được tính toán dựa trên cấu trúc toán học (I – cₚwₚ)Σₚ(I – wₚ′cₚ′) để thiết lập công thức hiệp phương sai cuối cùng Σ = CΦC‘ + Ψ.
12. Tiểu Sử Nhóm Tác Giả (Author Biographies)
- Gyeongcheol Cho: Nghiên cứu sinh tiến sĩ tại khoa Tâm lý học, Đại học McGill. Hướng nghiên cứu chuyên sâu của ông tập trung vào SEM, học máy (machine learning) và mô hình hóa dự báo.
- Heungsun Hwang: Giáo sư tâm lý học uy tín tại Đại học McGill. Chuyên môn học thuật của ông bao gồm phân tích dữ liệu đa biến, SEM, phân tích cụm và dữ liệu hình ảnh thần kinh.
- Marko Sarstedt: Giáo sư tiếp thị tại Otto-von-Guericke-University Magdeburg (Đức). Thuộc danh sách các nhà nghiên cứu có tầm ảnh hưởng và được trích dẫn nhiều nhất thế giới của tổ chức Clarivate Analytics.
- Christian M. Ringle: Giáo sư quản trị tại Đại học Công nghệ Hamburg (Đức), chuyên gia hàng đầu về phương pháp định lượng cho kinh doanh và nghiên cứu thị trường, cũng thuộc danh sách Highly Cited Researchers của Clarivate.
13. Tài Liệu Tham Khảo (References)
- Bollen, K.A., & Bauldry, S. (2011). Three Cs in measurement models: Causal indicators, composite indicators, and covariates. Psychological Methods, 16(3), 265-284.
- Byrne, B.M. (2001). Structural equation modeling with AMOS: Basic concepts, applications, and programming. Mahwah, NJ: Erlbaum.
- Cho, G., & Choi, J. Y. (2020). An empirical comparison of generalized structured component analysis and partial least squares path modeling under variance-based structural equation models. Behaviormetrika, 47(1), 243-272.
- Hu, L., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6(1), 1-55.
- Hwang, H., & Takane, Y. (2004). Generalized structured component analysis. Psychometrika, 69(1), 81-99.
- Hwang, H., & Takane, Y. (2014). Generalized structured component analysis: A component-based approach to structural equation modeling. New York, NY: Chapman and Hall/CRC Press.
- Jöreskog, K.G. (1970). A general method for analysis of covariance structures. Biometrika, 57(2), 239-251.
- Lohmöller, J.B. (1989). Latent variable path modeling with partial least squares. New York, NY: Springer-Verlag.
- Wold, H. (1982). Soft modeling: The basic design and some extensions. In Systems under indirect observation: Causality, structure, prediction, part II, ed. K.G. Jöreskog and H. Wold, 1-54. Amsterdam: North Holland.
14. Lời kêu gọi hành động (CTA)
Để xây dựng một thiết kế nghiên cứu hoàn hảo trong các đồ án thạc sĩ hoặc bài báo ISI/Scopus, việc nắm vững các hàm mục tiêu toán học đằng sau công cụ GSCA là điều bắt buộc. Hệ thống R², Q² và các chỉ số GoF sẽ được cải thiện đáng kể nếu bạn làm chủ được bản chất cốt lõi của phương pháp này. Mời các học giả và chuyên gia phân tích dữ liệu tải bài báo gốc để nghiên cứu chi tiết phương pháp thiết kế mô phỏng Monte Carlo.
Cho, G., Hwang, H., Sarstedt, M., & Ringle, C. M. (2020). Cutoff criteria for overall model fit indexes in generalized structured component analysis. Journal of Marketing Analytics, 8(4), 189–202.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



