
Phân tích biến điều tiết (Moderation Analysis) là một kỹ thuật thống kê nâng cao, đóng vai trò cốt lõi trong việc phát triển lý thuyết kinh doanh và khoa học xã hội. Kỹ thuật này cho phép nhà nghiên cứu vượt qua những câu hỏi đơn giản về mối quan hệ nhân quả (X tác động đến Y như thế nào) để giải quyết những vấn đề phức tạp hơn về bối cảnh: “Khi nào” và “Đối với ai” thì một tác động cụ thể sẽ xảy ra hoặc thay đổi.
Bài viết này được biên soạn dựa trên công trình nghiên cứu xã luận uy tín của Memon et al. (2019), nhằm cung cấp một hướng dẫn tường tận, giải quyết 7 vấn đề cốt lõi và các vấn đề mới nổi trong việc thực hiện phân tích điều tiết một cách chặt chẽ.
1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: Moderation Analysis: Issues and Guidelines
- Tiêu đề tiếng Việt: Phân tích biến điều tiết: Các vấn đề và Hướng dẫn thực hiện
- Tác giả: Mumtaz Ali Memon, Jun-Hwa Cheah, T. Ramayah, Hiram Ting, Francis Chuah và Tat Huei Cham
- Tạp chí: Journal of Applied Structural Equation Modeling (2019)
1.2 Bối cảnh ra đời và Tầm quan trọng
Tiếp nối sự thành công của các bài xã luận trước đó về những hiểu lầm phương pháp luận (2017) và phân tích trung gian (2018), nhóm tác giả đã nhận được vô số yêu cầu từ cộng đồng học thuật về một hướng dẫn tương tự cho phân tích biến điều tiết. Sự hiện diện của biến điều tiết trong mô hình nghiên cứu tượng trưng cho sự trưởng thành và tinh vi của một lĩnh vực nghiên cứu khoa học cụ thể.
Về mặt định nghĩa khoa học:
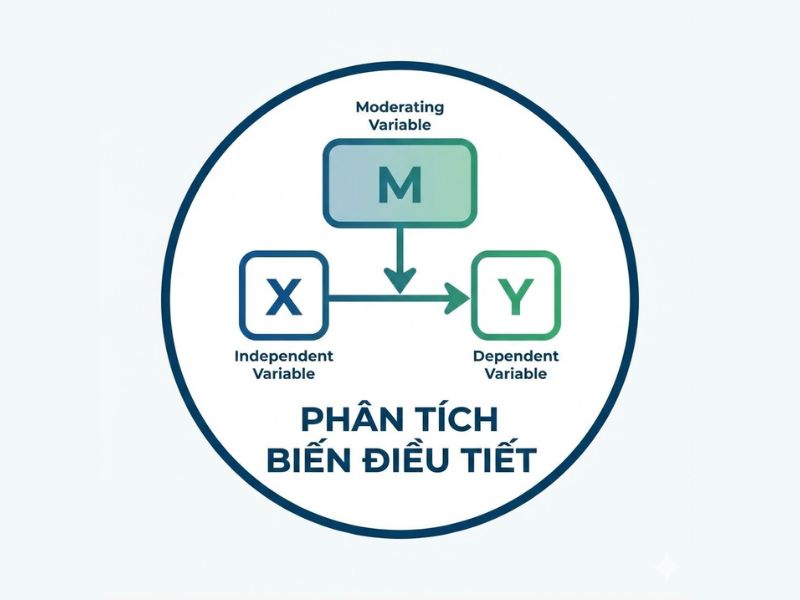
Một biến điều tiết là biến làm thay đổi bản chất (ví dụ: độ lớn và/hoặc hướng) của tác động giữa biến tiền tố (X) lên biến kết quả (Y).
Về mặt thống kê:
Sự điều tiết xảy ra khi mối quan hệ giữa một biến độc lập và một biến phụ thuộc thay đổi tùy theo giá trị của biến điều tiết. Nói một cách đơn giản, mô hình điều tiết giải quyết câu hỏi “khi nào” (when) hoặc “đối với ai” (for whom) một biến giải thích mạnh mẽ hoặc gây ra một biến kết quả.
1.3 Mô hình Khái niệm và Mô hình Thống kê
Để thực hiện đúng phân tích biến điều tiết, nhà nghiên cứu cần phân biệt rõ sự khác nhau giữa cách tư duy lý thuyết và cách xử lý dữ liệu:
- Mô hình khái niệm (Conceptual Framework): Trong tư duy lý thuyết, biến điều tiết (M) được vẽ với mũi tên chỉ vào đường dẫn (mũi tên) nối giữa Biến độc lập (X) và Biến phụ thuộc (Y). Hình ảnh này biểu thị rằng M đang can thiệp vào mối quan hệ X-Y.
- Mô hình thống kê (Statistical Model): Khi đưa vào phần mềm phân tích, hình dung này thay đổi. Chúng ta phải tạo ra một biến tương tác (Interaction term), ký hiệu là X*M (hoặc Z). Lúc này, mũi tên từ biến tương tác Z sẽ trỏ trực tiếp vào biến phụ thuộc (Y).
Lưu ý quan trọng: Biến điều tiết có thể là biến phân loại (danh nghĩa/thứ bậc như giới tính, loại hình trường học) hoặc biến liên tục (thang đo khoảng như mức độ hoài nghi, mức độ hỗ trợ). Quan niệm cho rằng phân tích biến điều tiết chỉ dành cho dữ liệu phân loại là hoàn toàn không chính xác.

2. Vấn đề 1: Cách Nhận Diện Các Biến Điều Tiết Tiềm Năng (Identification)
Việc lựa chọn biến điều tiết không nên dựa trên cảm tính, tham vọng cá nhân hay chỉ để làm phức tạp mô hình nghiên cứu. Thay vào đó, nó phải dựa trên cơ sở lý thuyết vững chắc. Dưới đây là các phương pháp khoa học để tìm ra chúng:
- Dựa trên sự không nhất quán của các nghiên cứu trước: Khi các nghiên cứu trong quá khứ đưa ra kết quả mâu thuẫn (Nghiên cứu A thấy tác động dương, Nghiên cứu B thấy không tác động) về cùng một tiền tố, đó là dấu hiệu mạnh mẽ cho thấy sự tồn tại của một biến điều tiết đang chi phối. Việc thực hiện tổng quan tài liệu hệ thống hoặc phân tích tổng hợp (meta-analysis) rất hữu ích để phát hiện điều này.
- Rà soát các đề xuất nghiên cứu: Một điểm khởi đầu tốt là xem xét kỹ phần “Hạn chế” (Limitations) và “Hướng nghiên cứu tương lai” (Future directions) trong các bài báo uy tín.
- Vay mượn lý thuyết liên ngành: Sử dụng yếu tố bối cảnh từ một lĩnh vực khác (ví dụ: áp dụng lý thuyết thế hệ từ xã hội học vào nghiên cứu tiếp thị) với lời giải thích lý thuyết mang tính xây dựng sẽ tạo ra cơ sở vững chắc cho biến điều tiết.
- Tham vấn chuyên gia: Thảo luận với các chuyên gia trong ngành hoặc những người cung cấp thông tin chính (key informants) để tìm ra các ý tưởng về yếu tố tiềm năng.
- Điều tra định tính (Qualitative Inquiry): Đây là phương pháp quan trọng để khám phá các yếu tố bối cảnh chưa từng được kiểm định thực nghiệm. Sử dụng phỏng vấn nhóm tập trung (focus groups), quan sát tham dự hoặc phỏng vấn cá nhân để nhận diện các yếu tố bối cảnh trong môi trường tự nhiên.
3. Vấn đề 2: Sự Khác Biệt Giữa Phân Tích Điều Tiết Đơn Giản và Phân Tích Đa Nhóm (MGA)
Sự nhầm lẫn giữa hai kỹ thuật này là rất phổ biến trong cộng đồng nghiên cứu sinh. Memon et al. (2019) phân định rõ ràng như sau:
3.1 Phân tích Đa nhóm (Multi-Group Analysis – MGA)
- Mục đích: Đánh giá xem hai hoặc nhiều biến có mối quan hệ giống nhau hay khác nhau giữa các nhóm.
- Đối tượng: Áp dụng khi biến điều tiết là biến phân loại (ví dụ: Quốc tịch, Ngành nghề).
- Phạm vi tác động: MGA kiểm tra và so sánh hiệu ứng của mọi đường dẫn cấu trúc qua các nhóm khác nhau, thay vì chỉ một đường dẫn cụ thể.
- Yêu cầu bắt buộc – Bất biến đo lường (Measurement Invariance): Vì so sánh trên toàn mô hình, việc kiểm định sự bất biến là bắt buộc để đảm bảo thang đo được hiểu giống nhau giữa các nhóm.
- Trong CB-SEM: Cần kiểm tra bất biến cấu hình, bất biến đo lường (metric), và bất biến thang đo (scalar).
- Trong PLS-SEM: Cần kiểm tra bất biến cấu hình, bất biến thành phần (compositional), giá trị trung bình bằng nhau và phương sai bằng nhau.
- Điều kiện tối thiểu: Phải đạt ít nhất kết quả bất biến từng phần (partial invariance) để tiến hành so sánh.
3.2 Phân tích Điều tiết Đơn giản (Simple Moderation)
- Mục đích: Kiểm tra xem biến điều tiết có làm thay đổi cường độ/hướng của một đường dẫn cụ thể nào đó không, dựa trên hỗ trợ lý thuyết.
- Đối tượng: Có thể là biến liên tục hoặc biến phân loại.
- Cảnh báo quan trọng: Tuyệt đối không chuyển đổi biến liên tục (như Tuổi, Thu nhập) thành biến phân loại (như Nhóm cao/Nhóm thấp) để chạy phân tích. Hành động này làm giảm sức mạnh thống kê (statistical power) và gây ra các vấn đề về điểm cắt tùy ý (như trung vị hoặc trung bình).
4. Vấn đề 3: Khi Nào Nên Sử Dụng Biến Điều Tiết (Usage)
Nhà nghiên cứu nên đưa biến điều tiết vào mô hình trong các trường hợp cụ thể sau:
- Kết quả không nhất quán (Inconclusive findings): Khi mối quan hệ giữa tiền tố và kết quả là yếu hoặc không nhất quán một cách bất ngờ qua các nghiên cứu. Baron & Kenny (1986) định nghĩa đây là trường hợp “một mối quan hệ tồn tại trong bối cảnh này nhưng không tồn tại trong bối cảnh khác”.
- Ví dụ thực tế: Froese et al. (2018) đã sử dụng đặc điểm nhân khẩu học để giải thích tại sao phần thưởng dựa trên thành tích không phải lúc nào cũng dẫn đến sự hài lòng trong công việc.
- Phát triển lý thuyết mới: Đưa vào các yếu tố bối cảnh mới (như văn hóa quốc gia) để lấp đầy khoảng trống nghiên cứu và cung cấp cái nhìn sâu sắc hơn về hiện tượng.
Lưu ý: Không áp dụng phương pháp “thử và sai” (trial and error) hoặc cố tình thêm biến điều tiết chỉ để làm luận văn phức tạp hơn. Mọi sự bổ sung phải có lý do lý thuyết rõ ràng giải thích tại sao sự hiện diện của biến đó giúp giải thích hiện tượng tốt hơn.
5. Vấn đề 4: Cách Khái Niệm Hóa và Đặt Giả Thuyết (Conceptualization)
Memon et al. (2019) khuyến nghị mạnh mẽ khung 7 bước của Andersson et al. (2014) để xây dựng giả thuyết cho mối quan hệ điều tiết:
- Xác định lý thuyết giải thích cả hiệu ứng trực tiếp và hiệu ứng điều tiết.
- Áp dụng lý thuyết vào câu hỏi nghiên cứu và giải thích cơ chế đằng sau hiệu ứng trực tiếp.
- Cung cấp biện minh lý thuyết cho việc chọn biến điều tiết (M).
- Giải thích tác động trực tiếp của M lên biến phụ thuộc (Y) để làm rõ sự khác biệt với hiệu ứng điều tiết (Z).
- Giải thích cách hiệu ứng điều tiết (Z) thay đổi các cơ chế bằng cách làm mạnh thêm hoặc làm yếu đi mối quan hệ trực tiếp.
- Về mặt lý thuyết, loại trừ khả năng tương tác ngược (trong đó X điều tiết mối quan hệ M -> Y).
- Quay trở lại lý thuyết khi diễn giải kết quả.
Cách viết giả thuyết chuẩn:
Tránh viết chung chung như “M điều tiết mối quan hệ giữa X và Y” vì đây không phải là một giả thuyết tốt. Thay vào đó, hãy viết rõ ràng hướng tác động:
- “Tác động của X lên Y sẽ tăng lên khi M hiện diện.”
- “Mối quan hệ giữa X và Y sẽ mạnh hơn khi M giảm xuống.”
Gardner et al. (2017) gợi ý 3 loại hiệu ứng tương tác: (1) Củng cố (strengthen), (2) Làm suy yếu (weaken), hoặc (3) Đảo ngược (reverse) mối quan hệ.
6. Vấn đề 5: Các Phương Pháp Tiếp Cận Trong PLS-SEM (Approaches)
Trong PLS-SEM, có 3 phương pháp chính để xử lý phân tích biến điều tiết. Việc lựa chọn phụ thuộc vào bản chất thang đo (Reflective – Kết quả hay Formative – Nguyên nhân):
| Phương pháp (Approach) | Mô tả & Cách thức hoạt động | Ưu điểm & Nhược điểm | Khuyên dùng khi |
| Product-Indicator (Chỉ báo tích) | Nhân các chỉ báo của biến độc lập (X) với chỉ báo của biến điều tiết (M). | Nhược điểm: Gây ra hiện tượng đa cộng tuyến (collinearity) trong mô hình cấu trúc. | Cả X và M đều là thang đo kết quả (Reflective). Không dùng cho thang đo nguyên nhân (Formative). |
| Two-Stage (Hai giai đoạn) | Giai đoạn 1: Tính điểm biến tiềm ẩn. Giai đoạn 2: Tạo biến tương tác từ điểm số này và chạy hồi quy bội. | Ưu điểm: Xử lý được biến nguyên nhân. Nhược điểm: Vẫn có thể gây đa cộng tuyến. | Khi biến độc lập (X) hoặc biến điều tiết (M) là thang đo nguyên nhân (Formative). |
| Orthogonalizing (Trực giao hóa) | Mở rộng của phương pháp Product-Indicator nhưng sử dụng quy tâm phần dư (residual centering) để loại bỏ cộng tuyến. | Ưu điểm: Loại bỏ hoàn toàn đa cộng tuyến, độ chính xác tham số cao. Nhược điểm: Sức mạnh thống kê thấp hơn. | Khi muốn tối ưu dự báo và tránh cộng tuyến. Chỉ áp dụng cho thang đo kết quả (Reflective). |
7. Vấn đề 6: Hướng Dẫn Trước Phân Tích (Pre-Analysis Guidelines)
Để đảm bảo thành công, nhà nghiên cứu cần chuẩn bị kỹ lưỡng trước khi thu thập dữ liệu. Memon et al. (2019) đề xuất 7 hướng dẫn quan trọng:
- Sử dụng thang đo đủ điểm: Khuyến nghị sử dụng thang đo Likert 7 điểm. Thang đo ít điểm hơn có thể gây mất thông tin, ngăn cản việc phát hiện hiệu ứng điều tiết, đặc biệt trong văn hóa tập thể (như Việt Nam, Malaysia).
- Kiểm tra trước (Pretest): Thực hiện phỏng vấn sâu hoặc kỹ thuật “debriefing” với người tham gia mục tiêu, thay vì chỉ chạy pilot study để kiểm tra độ tin cậy. Điều này giảm thiểu rủi ro dữ liệu kém chất lượng.
- Thứ tự câu hỏi: Đặt các mục quan trọng (liên quan đến biến điều tiết) lên đầu bảng câu hỏi, đặc biệt khi bảng câu hỏi dài.
- Phân tích lực (Power Analysis): Chạy phần mềm G*Power 2 lần. Lần 1 trước khi thu thập dữ liệu để xác định cỡ mẫu. Lần 2 sau khi thu thập để đảm bảo đủ sức mạnh phát hiện hiệu ứng. Nếu mẫu nhỏ và có nhiều biến điều tiết, hãy phân tích từng biến riêng biệt.
- Sàng lọc dữ liệu: Loại bỏ các phản hồi đáng ngờ như đánh thẳng một hàng (straight-lining), hình zíc-zắc, hoặc phản hồi có độ lệch chuẩn dưới 0.5.
- Làm “bài tập về nhà”: Đọc kỹ tài liệu để hiểu các khái niệm cơ bản trước khi đặt câu hỏi.
- Lựa chọn phần mềm: Chọn gói thống kê phù hợp (SmartPLS, IBM SPSS AMOS, WarpPLS…). SmartPLS 3.0 và WarpPLS 6.0 được đánh giá cao vì tích hợp sẵn các thuật toán điều tiết và vẽ biểu đồ dễ dàng.
8. Vấn đề 7: Phân Tích và Báo Cáo Kết Quả (Analysis & Reporting)
Quy trình báo cáo kết quả phân tích biến điều tiết cần tuân thủ 3 điểm cốt lõi sau:
- Tập trung vào ý nghĩa thống kê của tương tác (Z): Biến điều tiết (M) có thể không có tác động trực tiếp lên Y. Quyết định về hiệu ứng điều tiết phải dựa trên mối quan hệ có ý nghĩa giữa biến tương tác (Z) và biến phụ thuộc (Y).
- Tính toán và báo cáo kích thước hiệu ứng (f²): Báo cáo mức độ đóng góp của biến điều tiết vào việc giải thích phương sai R². SmartPLS 3.0 tính sẵn chỉ số này, các phần mềm khác có thể cần tính thủ công.
- Biểu đồ độ dốc đơn giản (Simple Slope Plot): Bắt buộc phải thực hiện và báo cáo biểu đồ này để kiểm tra trực quan hướng và độ mạnh của hiệu ứng điều tiết.
Quan trọng: Các nhà nghiên cứu phải “quay trở lại lý thuyết khi diễn giải kết quả”. Cần chú trọng vào ý nghĩa thực chất về mặt lý thuyết của hiện tượng hơn là chỉ dựa vào ý nghĩa thống kê.
9. Vấn đề 8: Các Vấn Đề Mới Nổi Cần Xem Xét (Emerging Issues)
Dựa trên Aguinis et al. (2017), bài xã luận cảnh báo 7 vấn đề kỹ thuật sâu hơn mà nhà nghiên cứu thường mắc phải:
- Thiếu chú ý đến sai số đo lường (Measurement Error): Nhiều bài báo không báo cáo sai số. Nếu độ tin cậy của X là 0.7 và Z là 0.5, thì độ tin cậy của tích số X*Z chỉ là 0.35. Điều này là không chấp nhận được. Cần báo cáo ước lượng độ tin cậy cho tất cả các biến dự báo bao gồm cả thành phần tích số.
- Giới hạn phạm vi (Range Restriction): Dữ liệu không đại diện cho toàn bộ dải giá trị của tổng thể (ví dụ: chỉ khảo sát công ty thành công, bỏ qua công ty thất bại). Điều này làm giảm phương sai và sức mạnh thống kê.
- Cỡ mẫu không đều (Unequal Sample Size): Với biến phân loại, nếu các nhóm chênh lệch quá lớn (ví dụ: 80% nữ), hiệu ứng điều tiết sẽ bị đánh giá thấp. Cần nỗ lực thu thập mẫu có tỷ lệ tương đồng.
- Thiếu sức mạnh thống kê (Insufficient Power): Nhiều nghiên cứu không đủ mẫu để phát hiện hiệu ứng. Cần tăng cỡ mẫu và tính toán power analysis trước khi nghiên cứu.
- Phân đôi nhân tạo (Artificial Dichotomization): Tuyệt đối ngưng ngay việc chia biến liên tục thành nhóm (Cao/Thấp) để phân tích (thường thấy khi dùng AMOS). Việc này làm mất thông tin, giảm phương sai, giảm sức mạnh thống kê và làm chệch kết quả.
- Huyền thoại về đa cộng tuyến (Multicollinearity): Nhiều người lo sợ sự tương quan giữa X và XM. Aguinis khẳng định rằng đa cộng tuyến này không gây vấn đề cho phân tích điều tiết miễn là X, M và XM đều có trong mô hình. Việc quy tâm (mean-centering) chỉ giúp dễ diễn giải hệ số bậc thấp, không làm thay đổi bản chất kết quả tương tác.
- Diễn giải sai lệch: Không được diễn giải tác động bậc thấp (X -> Y) một cách độc lập khi có sự hiện diện của tương tác. Khi có điều tiết, tác động của X là một dải các hiệu ứng (simple slopes) thay đổi theo mức độ của M.
10. Các câu hỏi thường gặp (FAQ)
Tôi có nên chia biến “Thu nhập” (liên tục) thành hai nhóm “Thu nhập cao” và “Thu nhập thấp” để so sánh không?
Tuyệt đối không nên. Hành động này gọi là “Phân đôi nhân tạo” (Artificial Dichotomization). Theo Aguinis (1995) và Memon et al. (2019), việc này làm mất thông tin dữ liệu, giảm sức mạnh thống kê và làm chệch kết quả phân tích. Bạn nên giữ nguyên dạng liên tục và sử dụng biến tương tác (interaction term).
Khi nào tôi nên sử dụng Phân tích Đa nhóm (MGA) thay vì biến tương tác?
Bạn nên dùng MGA khi biến điều tiết là biến phân loại (như Giới tính, Quốc gia) VÀ bạn muốn so sánh sự khác biệt trên toàn bộ các đường dẫn của mô hình. Nếu bạn chỉ quan tâm đến một đường dẫn cụ thể hoặc biến điều tiết là liên tục, hãy dùng phương pháp phân tích điều tiết đơn giản.
Đa cộng tuyến giữa biến độc lập (X) và biến tương tác (X*M) có đáng lo ngại không?
Không. Đây là một hiểu lầm phổ biến. Aguinis et al. (2017) khẳng định rằng sự tương quan này không gây vấn đề cho việc kiểm định giả thuyết điều tiết, miễn là bạn đưa đầy đủ X, M và X*M vào mô hình. Việc quy tâm (mean-centering) có thể giúp dễ đọc hệ số hơn nhưng không thay đổi kết quả kiểm định tương tác.
SmartPLS có tính sẵn kích thước hiệu ứng f² cho biến điều tiết không?
Có. SmartPLS 3.0 (và các bản mới hơn) tính toán f² theo mặc định. Đây là một lợi thế lớn so với các phần mềm khác, giúp bạn báo cáo mức độ đóng góp của biến điều tiết vào R² một cách dễ dàng.
11. Kết Luận (Conclusion)
Bài xã luận của Memon et al. (2019) nhấn mạnh rằng việc thực hiện phân tích biến điều tiết không nên làm một cách máy móc như một “khuôn mẫu”. Việc thêm biến điều tiết vào mô hình chỉ để làm phức tạp nghiên cứu mà không có sự hiểu biết nền tảng giống như việc thực hiện nghiên cứu một cách vô định và thiếu cơ sở.
Mọi phân tích cần phải gắn liền với vấn đề nghiên cứu và được biện giải bằng lý thuyết vững chắc. Hy vọng rằng hướng dẫn chi tiết này sẽ giúp các nhà nghiên cứu và sinh viên thực hiện các phân tích chặt chẽ, tránh các sai lầm phương pháp luận phổ biến và đóng góp giá trị thực tiễn cho kho tàng tri thức khoa học.
Để nắm bắt chi tiết từng bước thực hiện trên phần mềm và xem các ví dụ minh họa cụ thể, cũng như danh sách tài liệu tham khảo đầy đủ, bạn hãy tải ngay tài liệu gốc.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



