
Phân tích đa nhóm trong PLS-SEM (Multigroup Analysis – MGA) là một kỹ thuật thống kê nâng cao nhằm kiểm định xem liệu có sự khác biệt có ý nghĩa thống kê về các tham số mô hình (chủ yếu là hệ số đường dẫn) giữa các nhóm dữ liệu khác nhau hay không (ví dụ: so sánh giữa các quốc gia, nền văn hóa, giới tính hay loại hình doanh nghiệp).
Vấn đề cốt lõi và cấp thiết mà nghiên cứu của Sarstedt, Henseler và Ringle (2011) giải quyết là sự thiếu hụt các phương pháp kiểm định thống kê phù hợp và chính xác trong bối cảnh PLS-SEM, đặc biệt khi dữ liệu thực tế thường không tuân theo phân phối chuẩn và khi nhà nghiên cứu cần so sánh nhiều hơn hai nhóm cùng một lúc.

1. Tổng Quan & Thông Tin Định Danh (Overview & Citation)
Trước khi đi sâu vào phương pháp luận và các công thức tính toán, chúng ta cần xác định rõ nguồn gốc của các lý thuyết này để phục vụ cho việc trích dẫn khoa học chính xác trong các công trình nghiên cứu.
1.1 Thông tin bài báo gốc
- Tiêu đề gốc: Multigroup Analysis in Partial Least Squares (PLS) Path Modeling: Alternative Methods and Empirical Results.
- Tiêu đề tiếng Việt: Phân tích đa nhóm trong mô hình đường dẫn bình phương nhỏ nhất từng phần (PLS): Các phương pháp thay thế và kết quả thực nghiệm.
- Tác giả: Marko Sarstedt, Jörg Henseler, & Christian M. Ringle.
- Tạp chí: Advances in International Marketing (2011), Volume 22, trang 195-218.
1.2 Vấn đề nghiên cứu: Tính không đồng nhất (Heterogeneity)
Trong lĩnh vực tiếp thị quốc tế, một giả định phổ biến nhưng đầy rủi ro là việc cho rằng dữ liệu thu thập từ các quốc gia khác nhau có thể được gộp chung vào một “mô hình toàn cầu” (global model) duy nhất. Việc này ngầm định rằng hành vi của mọi đối tượng là giống nhau. Tuy nhiên, thực tế thường tồn tại sự khác biệt lớn, gọi là tính không đồng nhất (heterogeneity).
Chúng ta cần phân biệt hai loại tính không đồng nhất:
- Tính không đồng nhất quan sát được (Observed Heterogeneity): Đây là trường hợp nhà nghiên cứu đã biết trước biến phân loại (categorical moderator variable). Ví dụ: Chia dữ liệu theo Quốc gia A vs Quốc gia B, hoặc Khách hàng mới vs Khách hàng cũ. Đây chính là đối tượng xử lý chính của Phân tích đa nhóm (MGA).
- Tính không đồng nhất không quan sát được (Unobserved Heterogeneity): Các nhóm ẩn tồn tại trong dữ liệu nhưng không thể xác định bằng các biến định danh có sẵn. Ví dụ: Nhóm khách hàng “nhạy cảm về giá” và “ưa thích thương hiệu” nằm lẫn lộn. Trong trường hợp này, cần sử dụng kỹ thuật FIMIX-PLS (Finite Mixture PLS) để phân loại và tách nhóm trước khi thực hiện MGA.

2. Các phương pháp tiếp cận hiện có trong PLS-SEM (Existing Approaches)
Nghiên cứu của Sarstedt et al. (2011) đã hệ thống hóa và đánh giá phê bình 03 phương pháp truyền thống được sử dụng trước năm 2011, chỉ ra các ưu nhược điểm cụ thể.
2.1 Phương pháp Tham số (Parametric Approach)
Được đề xuất bởi Keil et al. (2000). Đây là phương pháp dựa trên biến thể của kiểm định t-test truyền thống cho hai mẫu độc lập.
- Cơ chế hoạt động: Phương pháp này ước lượng tham số cho từng nhóm riêng biệt, sau đó sử dụng sai số chuẩn (Standard Error) thu được từ quá trình Bootstrapping làm đầu vào cho công thức kiểm định t.
- Công thức kiểm định:
- Trường hợp phương sai bằng nhau: Sử dụng thống kê t gộp (pooled t-test) với độ bậc tự do là n1 + n2 – 2.
- Trường hợp phương sai không bằng nhau (Kiểm định Levene có ý nghĩa): Sử dụng công thức t sửa đổi (tương tự công thức của Chin, 2000) và độ bậc tự do được tính theo phương trình Welch-Satterthwaite.
- Hạn chế lớn nhất: Phương pháp này yêu cầu giả định dữ liệu (cụ thể là các ước lượng tham số) phải tuân theo phân phối chuẩn. Điều này trái ngược hoàn toàn với bản chất “phi tham số” (distribution-free) của PLS-SEM.
- Kết luận thực nghiệm: Phương pháp này được chứng minh là quá “phóng khoáng” (liberal), tức là nó có xu hướng kết luận “có sự khác biệt” quá dễ dàng, dẫn đến nguy cơ cao mắc sai lầm loại I (bác bỏ giả thuyết không H0 trong khi H0 đúng).
2.2 Phương pháp Hoán vị (Permutation-Based Approach)
Được phát triển và hoàn thiện bởi Chin (2003b) và Dibbern & Chin (2005).
- Cơ chế hoạt động:
- Tính toán sự khác biệt thực tế giữa hai nhóm.
- Hoán đổi ngẫu nhiên các quan sát giữa hai nhóm (tráo đổi người của nhóm 1 sang nhóm 2 và ngược lại) nhưng vẫn giữ nguyên kích thước mẫu của mỗi nhóm.
- Tính toán lại sự khác biệt cho mẫu đã hoán vị. Lặp lại quá trình này hàng nghìn lần (ví dụ: 5.000 lần).
- So sánh sự khác biệt thực tế với phân phối của các sự khác biệt hoán vị để tìm ra giá trị p-value.
- Ưu điểm: Hoàn toàn phù hợp với PLS-SEM vì không cần giả định phân phối chuẩn.
- Hạn chế: Yêu cầu kích thước mẫu giữa các nhóm phải tương đối cân bằng (similar sample sizes) để đảm bảo độ chính xác, điều này không phải lúc nào cũng đạt được trong thực tế.
2.3 Phương pháp phi tham số của Henseler (Henseler’s Approach)
Được giới thiệu bởi Henseler (2007).
- Cơ chế hoạt động: So sánh trực tiếp các ước lượng bootstrap đã định tâm (centered bootstrap estimates) của nhóm này với nhóm kia. Nó tính toán xác suất P(theta_1 <= theta_2) dựa trên phân phối thực nghiệm của bootstrap.
- Đặc điểm: Phương pháp này không dựa vào giả định phân phối chuẩn. Tuy nhiên, nó được đánh giá là khá “thận trọng” (conservative), tức là khó tìm ra sự khác biệt có ý nghĩa thống kê hơn so với các phương pháp khác. Ngoài ra, nó thường chỉ áp dụng tốt nhất cho các giả thuyết một phía (one-sided hypothesis).
3. Các Phương Pháp Mới Đề Xuất (Novel Proposed Methods) – Trọng tâm bài báo
Đây là phần đóng góp quan trọng nhất của bài báo, cung cấp bộ công cụ mạnh mẽ và chính xác hơn cho các nhà nghiên cứu sử dụng PLS-SEM.
3.1 Phương pháp Tập tin cậy Phi tham số (Nonparametric Confidence Set Approach)
Để khắc phục tính “phóng khoáng” của phương pháp tham số và hạn chế về mẫu của phương pháp hoán vị, các tác giả đề xuất phương pháp dựa trên sự chồng lấn của khoảng tin cậy.
- Nguyên lý hoạt động chi tiết:
- Chạy thuật toán PLS cho từng nhóm riêng biệt.
- Xây dựng Khoảng tin cậy Bootstrap đã hiệu chỉnh sai lệch (Bias-corrected Confidence Intervals – BCa) cho từng tham số đường dẫn (thường dùng mức tin cậy 95%). Việc hiệu chỉnh sai lệch là cần thiết để đảm bảo độ chính xác khi phân phối bị lệch.
- Thực hiện so sánh (Quy tắc quyết định):
- Kiểm tra xem ước lượng điểm (point estimate) của Nhóm 1 có nằm trong khoảng tin cậy của Nhóm 2 hay không.
- Kiểm tra xem ước lượng điểm của Nhóm 2 có nằm trong khoảng tin cậy của Nhóm 1 hay không.
- Kết luận:
- Nếu có sự chồng lấn (overlap) theo quy tắc trên -> Không có sự khác biệt có ý nghĩa thống kê.
- Nếu không có sự chồng lấn (ví dụ: toàn bộ khoảng tin cậy của nhóm 1 thấp hơn hẳn so với ước lượng của nhóm 2) -> Có sự khác biệt có ý nghĩa thống kê.
- Ưu điểm vượt trội: Xử lý tốt các mẫu nhỏ, không yêu cầu phân phối chuẩn, và giảm thiểu sai số loại II so với các phương pháp quá bảo thủ.
3.2 Kiểm định Tổng quát sự khác biệt nhóm (Omnibus Test of Group Differences – OTG)
Khi nghiên cứu có nhiều hơn 2 nhóm (ví dụ: So sánh khách hàng tại Đức, Anh, Pháp), việc thực hiện các so sánh cặp (Pairwise comparison) một cách rời rạc (Đức vs Anh, Anh vs Pháp, Đức vs Pháp) sẽ làm tăng tỷ lệ sai số tích lũy (Familywise Error Rate) vượt quá mức cho phép (thường là 0.05). OTG ra đời để giải quyết triệt để vấn đề này.
- Cơ chế vận hành: Phương pháp này tương tự như phân tích phương sai một yếu tố (One-way ANOVA) nhưng được thực hiện bằng kỹ thuật hoán vị (permutation).
- Bước 1 (Bootstrap): Thực hiện Bootstrapping cho toàn bộ các nhóm để thu được phân phối thực nghiệm của các tham số.
- Bước 2 (Tính F thực nghiệm): Tính tỷ số phương sai thực nghiệm (F_R) dựa trên công thức:
F_R = s²_between / s²_within
(Trong đó: s²_between là phương sai giữa các nhóm, s²_within là phương sai trong nội bộ các nhóm). - Bước 3 (Hoán vị – Permutation): Hoán vị ngẫu nhiên dữ liệu của tất cả các nhóm và tính lại giá trị F_R. Lặp lại quá trình này hàng nghìn lần (ví dụ: 5.000 lần) để tạo ra phân phối ngẫu nhiên của F_R.
- Bước 4 (Kết luận): So sánh giá trị F_R thực nghiệm (ở Bước 2) với phân phối hoán vị (ở Bước 3) để xác định giá trị xác suất p (p-value).
- Ứng dụng chiến lược: OTG đóng vai trò là “bộ lọc” bảo vệ đầu tiên. Nếu OTG không có ý nghĩa thống kê (p > 0.05), nhà nghiên cứu không nên tiến hành các so sánh cặp chi tiết, vì sự khác biệt quan sát được chỉ là ngẫu nhiên.
4. Kết Quả Thực Nghiệm & So Sánh (Empirical Comparison)
Để kiểm chứng hiệu quả của các phương pháp, nghiên cứu sử dụng dữ liệu khảo sát B2B về sự hài lòng khách hàng tại 3 quốc gia: Đức (n=65), Anh (n=115), và Pháp (n=170). Mô hình nghiên cứu kiểm tra tác động của Hài lòng về Sản phẩm/Dịch vụ/Giá cả đến Lòng trung thành.
4.1 Bảng so sánh đặc tính các phương pháp
| Đặc điểm | Phương pháp Tham số (Keil et al.) | Phương pháp Hoán vị (Chin) | Phương pháp Henseler | Phương pháp Tập tin cậy (Mới) |
| Loại kiểm định | Tham số (Parametric) | Phi tham số (Nonparametric) | Phi tham số | Phi tham số |
| Giả định phân phối | Bắt buộc Phân phối chuẩn | Không yêu cầu | Không yêu cầu | Không yêu cầu |
| Xu hướng kết luận | Phóng khoáng (Liberal): Rất dễ tìm thấy sự khác biệt, dễ mắc lỗi Type I. | Trung dung | Thận trọng (Conservative): Khó tìm thấy sự khác biệt. | Thận trọng & Chính xác: Cân bằng tốt nhất. |
| Yêu cầu mẫu | Không quan trọng chênh lệch | Cần kích thước mẫu tương đồng | Không quan trọng | Hoạt động tốt với mẫu nhỏ |
| Phạm vi áp dụng | So sánh 2 nhóm | So sánh 2 nhóm | So sánh 2 nhóm (thường là 1 phía) | So sánh 2 nhóm |
4.2 Kết quả chi tiết từ dữ liệu thực tế
- Kết quả kiểm định OTG: Kết quả cho thấy giá trị F_R rất lớn và p-value <= 0.01 cho cả 3 mối quan hệ đường dẫn giữa 3 quốc gia. Điều này khẳng định sự khác biệt là có thật và hợp thức hóa việc tiến hành các bước so sánh cặp tiếp theo.
- Sự khác biệt về kết luận giữa các phương pháp:
- Phương pháp tham số: Chỉ ra số lượng mối quan hệ khác biệt nhiều nhất. Ví dụ, nó cho rằng mối quan hệ “Hài lòng Dịch vụ -> Trung thành” giữa Đức và Anh là khác biệt có ý nghĩa (p <= 0.10).
- Phương pháp Hoán vị & Tập tin cậy: Cho kết quả thận trọng hơn. Trong ví dụ trên, cả hai phương pháp này đều kết luận không có sự khác biệt có ý nghĩa giữa Đức và Anh về “Hài lòng Dịch vụ”.
- Ví dụ điển hình: Đối với mối quan hệ “Hài lòng giá cả -> Trung thành” giữa Đức và Pháp: Phương pháp tham số kết luận là khác biệt (Significant), trong khi phương pháp Tập tin cậy kết luận là không khác biệt (Non-significant) vì khoảng tin cậy vẫn có sự chồng lấn.
5. Hướng Dẫn Ứng Dụng (Implications for Researchers)
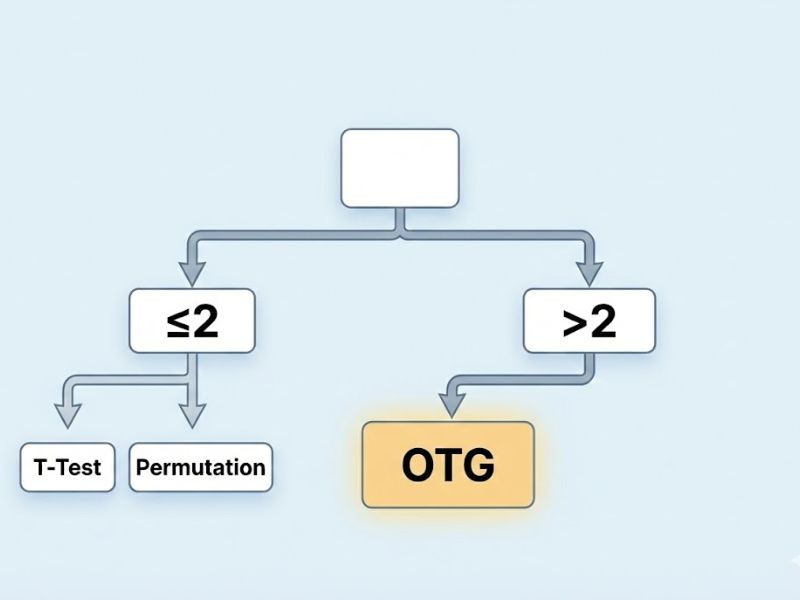
Dựa trên kết luận của bài báo, các nhà nghiên cứu và nghiên cứu sinh cần tuân thủ quy trình chuẩn sau để đảm bảo tính chính xác và thuyết phục cho luận văn/bài báo khoa học:
- Bước 1 – Đánh giá mô hình đo lường & Bất biến đo lường (Measurement Invariance):
Trước khi so sánh các hệ số, phải đảm bảo thang đo là tin cậy và giá trị. Quan trọng nhất, phải kiểm tra sự bất biến trong đo lường (theo Steenkamp & Baumgartner, 1998). Nếu người Đức và người Pháp hiểu câu hỏi khảo sát theo hai cách khác nhau, thì việc so sánh kết quả là vô nghĩa. - Bước 2 – Kiểm định OTG (Nếu có từ 3 nhóm trở lên):
- Bắt buộc chạy OTG trước tiên.
- Nếu OTG bác bỏ giả thuyết không H0 (p < 0.05) -> Kết luận: “Có ít nhất một nhóm khác biệt với các nhóm còn lại”. -> Chuyển sang Bước 3.
- Nếu OTG chấp nhận H0 (p > 0.05) -> Kết luận: “Không có sự khác biệt giữa các nhóm”. -> Dừng lại, không phân tích thêm.
- Bước 3 – So sánh cặp (Pairwise Comparison):
Sử dụng Phương pháp Tập tin cậy (Confidence Set Approach) hoặc Phương pháp Hoán vị để xác định cụ thể nhóm nào khác nhóm nào. Ưu tiên Phương pháp Tập tin cậy nếu dữ liệu không chuẩn hoặc kích thước mẫu nhỏ/chênh lệch.
6. Các Câu Hỏi Thường Gặp (FAQ)
Tại sao tôi không nên dùng t-test thông thường (như trong SPSS) để so sánh hệ số đường dẫn của 2 nhóm PLS?
Kiểm định t-test truyền thống trong SPSS thường dùng để so sánh giá trị trung bình (Mean comparison). Trong PLS-SEM, chúng ta đang so sánh hệ số đường dẫn (Path coefficients). Hơn nữa, sai số chuẩn trong PLS được ước lượng qua Bootstrapping và thường không tuân theo phân phối chuẩn. Việc dùng t-test tham số (như phương pháp của Keil) sẽ vi phạm giả định phân phối, dẫn đến kết quả sai lệch (thường là báo cáo sai rằng có sự khác biệt trong khi thực tế không có).
Khi nào nên dùng FIMIX-PLS và khi nào dùng MGA?
Đây là hai kỹ thuật xử lý hai loại không đồng nhất khác nhau:
- Dùng FIMIX-PLS khi bạn nghi ngờ dữ liệu không đồng nhất nhưng chưa biết nguyên nhân hoặc chưa có biến phân loại (ví dụ: tìm kiếm các phân khúc thị trường tiềm năng).
- Dùng MGA khi bạn đã có sẵn biến phân loại cụ thể (Ví dụ: Nam/Nữ, Doanh nghiệp Nhà nước/Tư nhân) và muốn kiểm định giả thuyết về sự khác biệt giữa các nhóm này.
OTG và phương pháp Tập tin cậy có sẵn trong phần mềm SmartPLS không?
Hiện nay, các phiên bản hiện đại của phần mềm SmartPLS (từ phiên bản 3 và 4) đã tích hợp rất mạnh mẽ các tính năng MGA. Cụ thể, SmartPLS cung cấp tính năng Permutation Multi-Group Analysis (hoạt động dựa trên nguyên lý hoán vị tương tự như OTG để kiểm tra tổng quát) và cung cấp cả kết quả Confidence Intervals (cho phép thực hiện phương pháp Tập tin cậy thủ công hoặc tự động) và Henseler’s MGA.
7. Tài Liệu Tham Khảo (References)
Baron, R. M., & Kenny, D. A. (1986). The moderator-mediator variable distinction in social psychological research: Conceptual, strategic and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173-1182.
Bortz, J., Lienert, G. A., & Boehnke, K. (2003). Verteilungsfreie Methoden in der Biostatistik (3 ed.). Berlin: Springer.
Brettel, M., Engelen, A., Heinemann, F., & Vadhanasindhu, P. (2008). Antecedents of market orientation: A cross-cultural comparison. Journal of International Marketing, 16(2), 84-119.
Chambers, J. M., Cleveland, W. S., Kleiner, B., & Tukey, P. A. (1983). Graphical methods for data analysis. Belmont: Wadsworth.
Chernick, M. R. (2008). Bootstrap methods. A guide for practitioners and researchers (Wiley Series in Probability and Statistics, 2: Wiley).
Chin, W. W. (1998). The partial least squares approach to structural equation modeling. In: G. A. Marcoulides (Ed.). Modern methods for business research (pp. 295-358). Mahwah: Erlbaum.
Chin, W. W. (2000). Multi-group analysis with PLS. Retrieved from http://dise-nt.cba.uh.edu/chin/plsfaq/multigroup.htm.
Chin, W. W. (2003a). PLS graph 3.0. Houston: Soft Modeling Inc.
Chin, W. W. (2003b). A permutation procedure for multi-group comparison of PLS models. In: M. Vilares, M. Tenenhaus, P. Coelho, V. Esposito Vinzi, A. Morineau (Eds.), PLS and Related Methods: Proceedings of the International Symposium PLS’03 (pp. 33-43). Lisbon: Decisia.
Chin, W. W., & Dibbern, J. (2010). An introduction to a permutation based procedure for multi-group PLS analysis: Results of tests of differences on simulated data and a cross cultural analysis of the sourcing of information system services between Germany and the USA. In: V. Esposito Vinzi, W. W. Chin, J. Henseler & H. Wang, et al. (Eds.). Handbook of partial least squares. Concepts, methods and applications (pp. 171-193). Berlin, Heidelberg: Springer-Verlag.
Davidson, R., & MacKinnon, J. G. (2007). Improving the reliability of bootstrap tests with the fast double bootstrap. Computational Statistics & Data Analysis, 51(7), 3259-3281.
Davison, A. C., & Hinkley, D. V. (1997). Bootstrap methods and their application. Cambridge: Cambridge University Press.
Dibbern, J., & Chin, W. W. (2005). Multi-group comparison: Testing a PLS model on the sourcing of application software services across Germany and the USA using a permutation based algorithm. In: F. Bliemel, A. Eggert, G. Fassott & J. Henseler, et al. (Eds.), Handbuch PLS-Pfadmodellierung. Methode, Anwendung, Praxisbeispiele (pp. 135-160). Stuttgart: Schäffer-Poeschel.
Edgington, E., & Onghena, P. (2007). Randomization tests (4th ed.). London: Chapman & Hall.
Efron, B. (1981). Nonparametric standard errors and confidence intervals. Canadian Journal of Statistics, 9(2), 139-172.
Efron, B., & Tibshirani, R. J. (1993). An introduction to the bootstrap. New York: Chapman & Hall.
Esposito Vinzi, V., Ringle, C. M., Squillacciotti, S., & Trinchera, L. (2007). Capturing and treating unobserved heterogeneity by response based segmentation in PLS path modeling: A comparison of alternative methods by computational experiments. Cergy Pontoise Cedex: ESSEC Research Center, Working Paper No. 07019.
Esposito Vinzi, V., Trinchera, L., Squillacciotti, S., & Tenenhaus, M. (2008). REBUS-PLS: A response-based procedure for detecting unit segments in PLS path modelling. Applied Stochastic Models in Business and Industry, 24(5), 439-458.
Festge, F., & Schwaiger, M. (2007). The drivers of customer satisfaction with industrial goods: An international study. Advances in International Marketing, 18, 179-207.
Fornell, C. G., & Larcker, D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 18(1), 39-50.
Graham, J. L., Mintu, A. T., & Rodgers, W. (1994). Explorations of negotiation behaviors in ten foreign cultures using a model developed in the United States. Management Science, 40(1), 72-95.
Grewal, R., Chakravarty, A., Ding, M., & Liechty, J. (2008). Counting chickens before the eggs hatch: Associating new product development portfolios with shareholder expectations in the pharmaceutical sector. International Journal of Research in Marketing, 25(3), 261-272.
Gudergan, S. P., Ringle, C. M., Wende, S., & Will, A. (2008). Confirmatory tetrad analysis in PLS path modeling. Journal of Business Research, 61(12), 1238-1249.
Haenlein, M., & Kaplan, A. M. (2011). The influence of observed heterogeneity on path coefficient significance: Technology acceptance within the marketing discipline. Journal of Marketing Theory and Practice, 19(2), 153-168.
Hahn, C., Johnson, M. D., Herrmann, A., & Huber, F. (2002). Capturing customer heterogeneity using a finite mixture PLS Approach. Schmalenbach Business Review, 54(3), 243-269.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2010). Multivariate data analysis (7 ed.). Englewood Cliffs: Prentice Hall.
Hair, J. F., Ringle, C. M., & Sarstedt, M. (2011). PLS-SEM: Indeed a silver bullet. Journal of Marketing Theory and Practice, 19(2), 139-151.
Hair, J. F., Sarstedt, M., Ringle, C. M., & Mena, J. A. (2012). An assessment of the use of partial least squares structural equation modeling in marketing research. Journal of the Academy of Marketing Science, forthcoming (online available).
Henseler, J. (2007). A new and simple approach to multi-group analysis in partial least squares path modeling. In: H. Martens & T. Næs (Eds.), Causalities explored by indirect observation: Proceedings of the 5th international symposium on PLS and related methods (PLS’07) (pp. 104-107). Oslo.
Henseler, J., & Chin, W. W. (2010). A comparison of approaches for the analysis of interaction effects between latent variables using partial least squares path modeling. Structural Equation Modeling, 17(1), 82-109.
Henseler, J., & Fassott, G. (2010). Testing moderating effects in PLS path models: An illustration of available procedures. In: V. Esposito Vinzi, W. W. Chin, J. Henseler & H. Wang (Eds.), Handbook of partial least squares. Concepts, methods and applications (pp. 713-735). Berlin, Heidelberg: Springer-Verlag.
Henseler, J., Ringle, C. M., & Sinkovics, R. R. (2009). The use of partial least squares path modeling in international marketing. Advances in International Marketing, 20, 277-320.
Hoffmann, S., Mai, R., & Smirnova, M. (2011). Development and validation of a cross-nationally stable scale of consumer animosity. Journal of Marketing Theory and Practice, 19(2), 235-251.
Homburg, C., & Rudolph, B. (1997). Customer satisfaction in industrial markets: Dimensional and multiple role issues. Journal of Business Research, 52(1), 15-33.
Jedidi, K., Jagpal, H. S., & DeSarbo, W. S. (1997). Finite-mixture structural equation models for response-based segmentation and unobserved heterogeneity. Marketing Science, 16(1), 39-59.
Keil, M., Saarinen, T., Tan, B. C. Y., Tuunainen, V., Wassenaar, A., & Wei, K.-K. (2000). A cross-cultural study on escalation of commitment behavior in software projects. Management Information Systems Quarterly, 24(2), 299-325.
Lohmöller, J.-B. (1989). Latent variable path modeling with partial least squares. Heidelberg: Physica.
McCullough, B. D., & Vinod, H. D. (1998). Implementing the double bootstrap. Computational Economics, 12(1), 79-95.
McKnight, S. D., McKean, J. W., & Huitema, B. E. (2000). A double bootstrap method to analyze linear models with autoregressive error terms. Psychological Methods, 5(1), 87-101.
Mooi, E. A., & Sarstedt, M. (2011). A concise guide to market research: The process, data, and methods using IBM SPSS statistics. Berlin: Springer.
Nitzl, C. (2010). Eine anwenderorientierte Einführung in die Partial Least Square (PLS)-Methode. Hamburg: Universität Hamburg: Industrielles Management. Arbeitspapier Nr. 21.
Pitman, E. J. G. (1938). Significance tests which may be applied to samples from any population. Journal of the Royal Statistical Society Supplement, 4(1), 119-130.
Qureshi, I., & Compeau, D. R. (2009). Assessing between-group differences in information systems research: A comparision of covariance- and component-based SEM. Management Information Systems Quarterly, 33(1), 197-214.
R-Development-Core-Team. (2011). R: A language and environment for statistical computing. Vienna.
Revelle, W. (1979). Hierarchical clustering and the internal structure of tests. Multivariate Behavioral Research, 14(1), 57-74.
Rigdon, E. E., Ringle, C. M., & Sarstedt, M. (2010). Structural modeling of heterogeneous data with partial least squares. In: N. K. Malhotra (Ed.). Review of marketing research (Vol. 7, pp. 255-296). Armonk: Sharpe.
Ringle, C. M., Sarstedt, M., & Mooi, E. A. (2010). Response-based segmentation using finite mixture partial least squares: Theoretical foundations and an application to American Customer Satisfaction Index data. Annals of Information Systems, 8, 19-49.
Ringle, C. M., Sarstedt, M., & Schlittgen, R. (2010). Finite mixture and genetic algorithm segmentation in partial least squares path modeling: Identification of multiple segments in a complex path model. In: A. Fink, B. Lausen, W. Seidel & A. Ultsch (Eds.), Advances in data analysis, data handling and business intelligence (pp. 167-176). Berlin: Springer.
Ringle, C. M., Wende, S., & Will, A. (2005). SmartPLS 2.0 (Beta). Hamburg: SmartPLS. Retrieved from www.smartpls.de.
Ringle, C. M., Wende, S., & Will, A. (2010). Finite mixture partial least squares analysis: Methodology and numerical examples. In: V. Esposito Vinzi, W. W. Chin, J. Henseler & H. Wang (Eds.), Handbook of partial least squares. Concepts, methods and applications (pp. 195-218). Berlin, Heidelberg: Springer-Verlag.
Rodríguez, C. M., & Wilson, D. T. (2002). Relationship bonding and trust as a foundation for commitment is U.S.-Mexican strategic alliances: A structural equation modeling approach. Journal of International Marketing, 10(4), 53-76.
Sarstedt, M. (2008). A review of recent approaches for capturing heterogeneity in partial least squares path modelling. Journal of Modelling in Management, 3(2), 140-161.
Sarstedt, M., Becker, J.-M., Ringle, C. M., & Schwaiger, M. (2011). Uncovering and treating unobserved heterogeneity with FIMIX-PLS: Which model selection criterion provides an appropriate number of segments? Schmalenbach Business Review, 63(1), 34-62.
Sarstedt, M., & Ringle, C. M. (2010). Treating unobserved heterogeneity in PLS path modelling: A comparison of FIMIX-PLS with different data analysis strategies. Journal of Applied Statistics, 37(8), 1299-1318.
Sarstedt, M., Schwaiger, M., & Ringle, C. M. (2009). Do we fully understand the critical success factors of customer satisfaction with industrial goods? Extending Festge and Schwaiger’s model to account for unobserved heterogeneity. Journal of Business Market Management, 3(3), 185-206.
Sarstedt, M., & Wilczynski, P. (2009). More for less? A comparison of single-item and multi-item measures. Die Betriebswirtschaft, 69(2), 211-227.
Shi, S. G. (1992). Accurate and efficient double-bootstrap confidence limit method. Computational Statistics and Data Analysis, 13(1), 21-32.
Steenkamp, J. B. E. M., & Baumgartner, H. (1998). Assessing measurement invariance in cross national consumer research. Journal of Consumer Research, 25(1), 78-107.
Vandenberg, R. J., & Lance, C. E. (2000). A review and synthesis of the measurement invariance literature: Suggestions, practices, and recommendations for organizational research. Organizational Research Methods, 3(1), 4-70.
Wold, H. (1975). Path models with latent variables: The NIPALS approach. In: H. M. Blalock, A. Aganbegian, F. M. Borodkin, R. Boudon & V. Capecchi (Eds.), Quantitative sociology: International perspectives on mathematical and statistical modeling (pp. 307-357). New York: Academic Press.
Wold, H. (1982). Soft modeling: The basic design and some extensions. In: K. G. Jöreskog & H. Wold (Eds.), Systems under indirect observations: Part II (pp. 1-54). Amsterdam: North-Holland.
Zeithaml, V. A., Berry, L. L., & Parasuraman, A. (1996). The behavioral consequences of service quality. Journal of Marketing, 60(2), 31-46.
8. Lời kết
Nghiên cứu của Sarstedt, Henseler và Ringle (2011) không chỉ dừng lại ở việc so sánh các phương pháp thống kê, mà còn đặt nền móng chuẩn mực cho việc xử lý tính không đồng nhất trong dữ liệu nghiên cứu tiếp thị quốc tế.
Để đảm bảo tính chính xác và sự thuyết phục cho công trình nghiên cứu của mình, đặc biệt khi bảo vệ trước hội đồng khoa học hoặc gửi đăng tạp chí quốc tế, việc trích dẫn và áp dụng đúng quy trình OTG kết hợp với Phương pháp Tập tin cậy (Confidence Set Approach) là bước đi bắt buộc đối với các nhà nghiên cứu sử dụng PLS-SEM.
Chúng tôi khuyến nghị bạn tải xuống và nghiên cứu chi tiết toàn văn tài liệu gốc để nắm vững các công thức toán học và quy trình thực hiện cụ thể:
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



