
PLS-SEM (Partial Least Squares Structural Equation Modeling) là phương pháp thống kê thế hệ thứ hai (second-generation techniques) được sử dụng để ước lượng các mô hình quan hệ nhân quả phức tạp giữa các biến tiềm ẩn. Khác với CB-SEM (Covariance-Based SEM) tập trung vào sự phù hợp của mô hình lý thuyết (Goodness-of-fit), PLS-SEM tối đa hóa phương sai giải thích (R²) của các biến phụ thuộc, làm cho nó trở thành công cụ tối ưu cho mục tiêu dự báo và phát triển lý thuyết. Giải pháp này đặc biệt hiệu quả khi dữ liệu không phân phối chuẩn, kích thước mẫu nhỏ hoặc mô hình có chứa các biến cấu tạo (formative).

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh tài liệu gốc
Để đảm bảo tính chính xác và liêm chính trong trích dẫn khoa học, dưới đây là thông tin gốc của tài liệu nền tảng được sử dụng cho bài giảng này. Sinh viên và nghiên cứu viên cần lưu lại để đưa vào danh mục tài liệu tham khảo:
- Tiêu đề gốc: A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) – Second Edition.
- Tiêu đề tiếng Việt: Nhập môn Mô hình Cấu trúc Tuyến tính Bình phương Tối thiểu Riêng phần (PLS-SEM).
- Tác giả: Joseph F. Hair, Jr., G. Tomas M. Hult, Christian M. Ringle, và Marko Sarstedt.
- Nhà xuất bản: SAGE Publications, Inc. (2017).
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Trong nghiên cứu khoa học xã hội, hành vi và quản trị kinh doanh, các mô hình hồi quy tuyến tính truyền thống (như SPSS thông thường) gặp hạn chế lớn khi xử lý các biến tiềm ẩn (Latent variables) – những khái niệm trừu tượng không thể đo lường trực tiếp như “Lòng trung thành”, “Nhận thức rủi ro” hay các cấu trúc thuộc về động lực xã hội.
Lý thuyết Mô hình cấu trúc (SEM) ra đời để giải quyết vấn đề này bằng cách kết hợp phân tích nhân tố và hồi quy đa biến. Tuy nhiên, phương pháp truyền thống là CB-SEM (đại diện là phần mềm AMOS) đặt ra rào cản lớn: yêu cầu dữ liệu phải phân phối chuẩn đa biến nghiêm ngặt và kích thước mẫu phải lớn. Khoảng trống này đã được lấp đầy bởi PLS-SEM. Phương pháp này cho phép các nhà nghiên cứu làm việc với dữ liệu thực tế phức tạp hơn, mẫu nhỏ hơn và tập trung vào khả năng dự báo (Prediction) thay vì chỉ nặng về kiểm định sự phù hợp (Confirmation).
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
2.1 Bản chất của PLS-SEM
PLS-SEM hoạt động dựa trên phương sai (variance-based). Về mặt toán học, nó ước lượng các hệ số đường dẫn (path coefficients) để tối đa hóa giá trị R² của các biến nội sinh (biến đích).
Đây là phương pháp phi tham số (non-parametric), nghĩa là nó không đặt ra các giả định khắt khe về phân phối dữ liệu (như phân phối chuẩn). Thay vì tối thiểu hóa sự khác biệt giữa ma trận hiệp phương sai mẫu và lý thuyết như CB-SEM, PLS-SEM tối đa hóa phương sai giải thích được của các biến tiềm ẩn phụ thuộc bằng cách xác định các trọng số (weights) cho các chỉ báo.
2.2 So sánh PLS-SEM và CB-SEM (Dữ liệu có cấu trúc)
Việc phân biệt rõ hai trường phái này là bắt buộc trong phần “Phương pháp nghiên cứu” của luận văn để biện minh cho sự lựa chọn của tác giả.
| Tiêu chí | PLS-SEM (SmartPLS) | CB-SEM (AMOS/LISREL) |
| Mục tiêu nghiên cứu | Dự báo (Prediction) các biến mục tiêu; Phát triển lý thuyết mới/khám phá. | Kiểm định (Confirmation) lý thuyết đã vững chắc; So sánh/lựa chọn mô hình. |
| Phân phối dữ liệu | Phi tham số: Không yêu cầu chuẩn (Non-normal data). | Tham số: Bắt buộc phân phối chuẩn đa biến (Multivariate normality). |
| Kích thước mẫu | Hoạt động tốt với mẫu nhỏ (khi công suất thống kê đủ) và cả mẫu lớn. | Yêu cầu mẫu lớn để đảm bảo độ chính xác của ước lượng. |
| Mô hình đo lường | Xử lý tốt cả thang đo Kết quả (Reflective) và Cấu tạo (Formative). | Chủ yếu tối ưu cho thang đo Kết quả (Reflective). Khó xử lý Formative. |
| Sai số mô hình | Chấp nhận sự phức tạp, ít nhạy cảm với sai số chỉ báo. | Rất nhạy cảm với sai số mô hình (Model fit indices). |
2.3 Quy tắc ngón tay cái: Khi nào chọn PLS-SEM?
Dựa trên Hair et al. (2017), bạn nên chọn PLS-SEM khi nghiên cứu có các đặc điểm sau:
- Mục tiêu là dự báo các biến đích (Target constructs) hoặc xác định các yếu tố dẫn dắt chính (Key driver constructs).
- Mô hình cấu trúc phức tạp (nhiều biến tiềm ẩn, nhiều đường dẫn, nhiều lớp).
- Mô hình có sử dụng các biến đo lường dạng Cấu tạo (Formative).
- Cỡ mẫu nhỏ hoặc dữ liệu bị lệch (skewed), không tuân theo phân phối chuẩn.
- Sử dụng dữ liệu thứ cấp (Secondary data) hoặc dữ liệu mảng (panel data).

3. Quy Trình Thực Hiện Phân Tích & Xử Lý Dữ Liệu
Theo chuẩn mực của Hair et al. (2017), một nghiên cứu định lượng sử dụng PLS-SEM phải tuân thủ nghiêm ngặt quy trình sau:
3.1 Thiết lập Mô hình Đường dẫn (Path Model Specification)
- Mô hình cấu trúc (Inner Model): Biểu diễn mối quan hệ giữa các biến tiềm ẩn (các hình tròn).
- Biến ngoại sinh (Exogenous): Biến độc lập, chỉ có mũi tên đi ra, không có mũi tên đi vào.
- Biến nội sinh (Endogenous): Biến phụ thuộc hoặc trung gian, có ít nhất một mũi tên đi vào.
- Mô hình đo lường (Outer Model): Biểu diễn mối quan hệ giữa biến tiềm ẩn và các chỉ báo quan sát (các hình chữ nhật).
3.2 Xử lý dữ liệu đầu vào (Data Examination)
Trước khi đưa vào phần mềm (như SmartPLS), dữ liệu thô phải được làm sạch:
- Dữ liệu thiếu (Missing Data):
- Nếu thiếu < 5% mỗi chỉ báo: Sử dụng phương pháp thay thế bằng giá trị trung bình (Mean Replacement).
- Nếu thiếu > 15%: Nên xóa bỏ toàn bộ quan sát đó (Casewise deletion) để tránh làm sai lệch kết quả.
- Phân phối dữ liệu: Dù PLS-SEM là phi tham số, nhưng nếu dữ liệu quá lệch (Skewness/Kurtosis > 1) hoặc có điểm dị biệt cực đoan (Outliers), nó vẫn có thể ảnh hưởng đến kết quả Bootstrapping. Cần kiểm tra sơ bộ.
3.3 Thuật toán PLS hoạt động như thế nào? (PLS-SEM Algorithm)
Hiểu bản chất thuật toán giúp giải thích kết quả sâu sắc hơn:
- Thuật toán hoạt động dựa trên chuỗi các hồi quy OLS (bình phương tối thiểu thông thường).
- Nó ước lượng điểm số (scores) của biến tiềm ẩn dưới dạng tổ hợp tuyến tính của các chỉ báo.
- Lưu ý về Sai lệch (Bias): PLS-SEM thường có xu hướng đánh giá thấp (underestimate) các mối quan hệ cấu trúc và đánh giá cao (overestimate) các mối quan hệ đo lường so với CB-SEM. Tuy nhiên, sai lệch này rất nhỏ và được chấp nhận trong thống kê, gọi là “tính nhất quán ở mức rộng” (consistency at large).
4. Đánh Giá Mô Hình Đo Lường (Measurement Model Evaluation)
Đây là bước quan trọng nhất. Nếu mô hình đo lường sai, mọi kết quả kiểm định giả thuyết đều vô nghĩa. Cần phân biệt rõ hai loại thang đo.
4.1 Thang đo Kết quả (Reflective – Mode A)
(Đặc điểm: Biến tiềm ẩn là nguyên nhân gây ra chỉ báo. Các chỉ báo có tương quan cao với nhau).
Bước 1: Độ tin cậy nhất quán nội bộ (Internal Consistency Reliability)
- Cronbach’s Alpha (α): Ngưỡng chấp nhận > 0.70.
- Độ tin cậy tổng hợp (Composite Reliability – CR): Đây là chỉ số chính xác hơn Alpha trong PLS.
- Giá trị 0.70 – 0.90 là tốt nhất.
- Nếu > 0.95: Cảnh báo sự dư thừa chỉ báo (các câu hỏi quá giống nhau), làm giảm giá trị nội dung.
Bước 2: Giá trị hội tụ (Convergent Validity)
- Hệ số tải ngoài (Outer Loadings): Phải ≥ 0.708.
- Nếu loading từ 0.40 đến 0.70: Chỉ xóa nếu việc xóa giúp tăng CR hoặc AVE vượt ngưỡng chuẩn.
- Nếu loading < 0.40: Luôn xóa bỏ khỏi thang đo.
- Phương sai trích trung bình (AVE): Phải > 0.50. Nghĩa là biến tiềm ẩn giải thích được hơn 50% phương sai của các chỉ báo quan sát của nó.
Bước 3: Giá trị phân biệt (Discriminant Validity)
- Tiêu chuẩn Fornell-Larcker: Căn bậc 2 của AVE của một biến phải lớn hơn tương quan của biến đó với tất cả các biến khác. (Cách cũ, độ nhạy kém).
- Tỷ lệ HTMT (Heterotrait-Monotrait Ratio): Tiêu chuẩn hiện đại và ưu việt nhất.
- HTMT < 0.85: Cho các khái niệm hoàn toàn khác biệt.
- HTMT < 0.90: Cho các khái niệm có ý nghĩa gần tương tự.
- Bootstrapping HTMT: Khoảng tin cậy (Confidence Interval) của HTMT không được chứa giá trị 1.
4.2 Thang đo Cấu tạo (Formative – Mode B)
(Đặc điểm: Các chỉ báo kết hợp lại tạo thành biến tiềm ẩn. Các chỉ báo không nhất thiết phải tương quan).
Bước 1: Giá trị hội tụ (Convergent Validity)
- Kiểm tra bằng Phân tích dư thừa (Redundancy Analysis).
- Hệ số đường dẫn giữa biến Formative và một biến Reflective (hoặc Global single item) của cùng một khái niệm phải ≥ 0.70.
Bước 2: Kiểm tra Đa cộng tuyến (Collinearity)
- Vì các chỉ báo Formative đóng vai trò như các biến độc lập trong hồi quy, chúng không được trùng lặp thông tin.
- Chỉ số VIF (Variance Inflation Factor) của các chỉ báo phải < 5. Lý tưởng nhất là < 3.
Bước 3: Ý nghĩa và độ lớn trọng số (Outer Weights)
- Dùng Bootstrapping để kiểm định.
- Nếu trọng số (weight) có ý nghĩa thống kê (p < 0.05) → Giữ lại.
- Nếu trọng số không có ý nghĩa, hãy kiểm tra hệ số tải (loading) của nó:
- Nếu Loading ≥ 0.50 → Giữ lại (do đóng góp tuyệt đối vẫn cao).
- Nếu Loading < 0.50 → Xóa bỏ (trừ khi lý thuyết bắt buộc phải có).
5. Đánh Giá Mô Hình Cấu Trúc (Structural Model Evaluation)
Sau khi mô hình đo lường đạt chuẩn, ta tiến hành đánh giá mô hình cấu trúc để kiểm định giả thuyết.
- Kiểm tra Đa cộng tuyến cấu trúc (Structural Collinearity):
- Kiểm tra VIF giữa các biến tiềm ẩn độc lập. Giá trị phải < 5 (tốt nhất là < 3) để đảm bảo không có hiện tượng đa cộng tuyến gây sai lệch hệ số hồi quy.
- Hệ số đường dẫn (Path Coefficients – β):
- Sử dụng kỹ thuật Bootstrapping (thường dùng 5.000 mẫu lặp) để tính giá trị t (t-values) và p (p-values).
- Giá trị t tới hạn (kiểm định 2 đuôi):
- t > 1.65 (mức tin cậy 90%, α = 0.10).
- t > 1.96 (mức tin cậy 95%, α = 0.05).
- t > 2.57 (mức tin cậy 99%, α = 0.01).
- Khuyến nghị: Dùng Khoảng tin cậy (Confidence Intervals – BC/BCa). Nếu khoảng này không chứa số 0 → Mối quan hệ có ý nghĩa thống kê.
- Hệ số xác định (R² – Coefficient of Determination):
- Đo lường khả năng dự báo của mô hình (tỷ lệ phương sai được giải thích).
- Ngưỡng (trong Marketing): 0.75 (Mạnh), 0.50 (Trung bình), 0.25 (Yếu).
- Lưu ý: Khi so sánh các mô hình, hãy dùng R² hiệu chỉnh (R² adjusted) để tránh thiên lệch do số lượng biến.
- Kích thước ảnh hưởng (f² Effect Size):
- Đo lường mức độ ảnh hưởng của việc loại bỏ một biến ngoại sinh lên R² của biến nội sinh.
- Ngưỡng: 0.02 (Nhỏ); 0.15 (Trung bình); 0.35 (Lớn). Nếu < 0.02 xem như không có ảnh hưởng.
- Khả năng dự báo (Q² Predictive Relevance):
- Dùng thủ tục Blindfolding (ẩn đi một phần dữ liệu và dự báo lại).
- Nếu Q² > 0: Mô hình có khả năng dự báo cho biến nội sinh đó.
- Nếu Q² ≤ 0: Mô hình thiếu khả năng dự báo.
- Lưu ý về Model Fit:
- Các chỉ số như SRMR (< 0.08) hay RMStheta (< 0.12) có thể tham khảo để đánh giá sự sai biệt. Tuy nhiên, không dùng chúng làm tiêu chuẩn cứng để loại bỏ mô hình PLS nếu khả năng dự báo vẫn tốt. Tuyệt đối không dùng chỉ số GoF (Goodness-of-Fit) cũ.

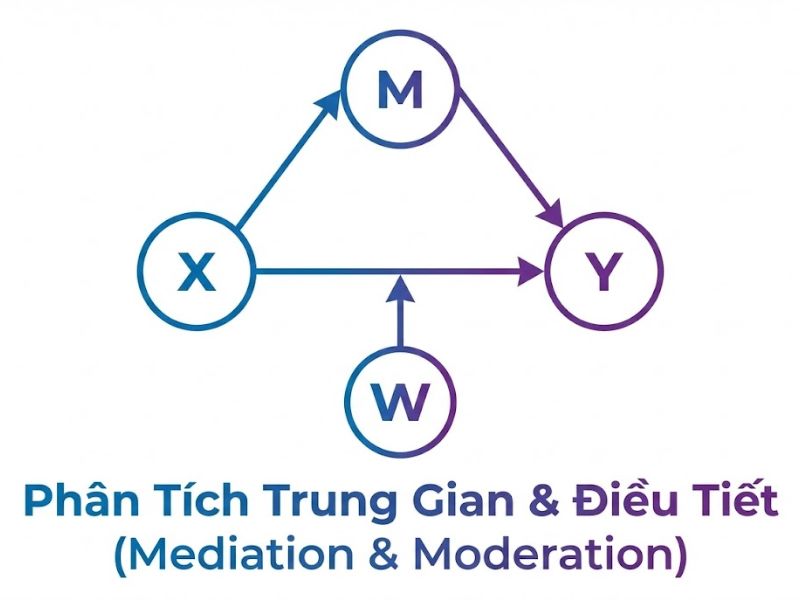
6. Phân Tích Trung Gian & Điều Tiết (Mediation & Moderation)
Đây là phần nâng cao giúp nâng tầm giá trị khoa học của luận văn (dựa trên Chương 7 của sách).
6.1 Phân tích Trung gian (Mediation Analysis)
Theo quy trình hiện đại của Zhao et al. (2010) và Nitzl et al. (2016), không còn dùng kiểm định Sobel vì yêu cầu phân phối chuẩn. Quy trình Bootstrapping chuẩn như sau:
- Bước 1: Kiểm tra tác động gián tiếp (a × b).
- Nếu khoảng tin cậy chứa số 0 → Không có trung gian (No mediation).
- Bước 2: Nếu tác động gián tiếp có ý nghĩa, kiểm tra tác động trực tiếp (c’).
- Nếu c’ không có ý nghĩa (chứa số 0) → Trung gian toàn phần (Full mediation / Indirect-only).
- Nếu c’ có ý nghĩa (không chứa số 0) → Trung gian một phần (Partial mediation).
- Bước 3: Phân loại trung gian một phần:
- Nếu tích a × b × c’ dương (cùng dấu) → Trung gian bổ sung (Complementary mediation).
- Nếu tích a × b × c’ âm (ngược dấu) → Trung gian cạnh tranh (Competitive mediation).
6.2 Phân tích Điều tiết (Moderation Analysis)
Điều tiết xảy ra khi biến thứ ba (M) làm thay đổi cường độ/chiều hướng quan hệ giữa X và Y.
- Xử lý biến tương tác (Interaction Term – X × M):
- Product Indicator Approach: Chỉ tốt khi tất cả là biến Reflective.
- Two-Stage Approach (Hai giai đoạn): Đây là phương pháp được Hair et al. (2017) khuyên dùng nhất (default trong SmartPLS 3/4). Nó tính điểm số biến tiềm ẩn ở giai đoạn 1, sau đó nhân chúng để tạo biến tương tác ở giai đoạn 2. Bắt buộc dùng nếu mô hình có biến Formative.
- Đánh giá: Xem xét ý nghĩa thống kê của đường dẫn tương tác và vẽ biểu đồ độ dốc đơn (Simple Slope Plot) để luận giải (ví dụ: khi M cao thì tác động của X lên Y mạnh hơn).
7. Các Kỹ Thuật Phân Tích Mở Rộng (Advanced Methods)
Để đạt mức độ chuyên gia (Expert) trong xử lý PLS-SEM, bạn cần nắm vững các kỹ thuật chương 8:
- Phân tích Bản đồ Tầm quan trọng – Hiệu suất (IPMA – Importance-Performance Map Analysis):
- Kết hợp Tổng tác động (Importance) và Điểm số trung bình (Performance – thang 0-100) của các biến.
- Mục tiêu: Tìm ra các yếu tố có tác động rất mạnh (Importance cao) nhưng doanh nghiệp đang làm chưa tốt (Performance thấp) để ưu tiên cải thiện.
- Mô hình Thành phần Thứ bậc (HCM – Hierarchical Component Models):
- Xử lý các khái niệm bậc 2 (Higher-Order Constructs) được hình thành từ các thành phần con bậc 1.
- Phương pháp: Repeated Indicators (lặp lại chỉ báo) hoặc Two-Stage Approach (dùng điểm số bậc 1 làm chỉ báo cho bậc 2).
- Phân tích Tetrad Khẳng định (CTA-PLS):
- Kỹ thuật thực nghiệm giúp xác định xem nên dùng thang đo Reflective hay Formative dựa trên dữ liệu thực tế (thay vì chỉ dựa vào cảm tính lý thuyết).
- Xử lý Tính không đồng nhất (Heterogeneity):
- Observed (Quan sát được): Dùng Phân tích đa nhóm (MGA – Multi-Group Analysis) để so sánh sự khác biệt giữa các nhóm (ví dụ: Nam vs Nữ).
- Unobserved (Không quan sát được): Dùng FIMIX-PLS hoặc PLS-POS để phân khúc dữ liệu, tìm ra các nhóm hành vi ẩn.
- Consistent PLS (PLSc):
- Một thuật toán hiệu chỉnh để kết quả PLS tương đồng với CB-SEM. Chỉ sử dụng khi mô hình toàn bộ là biến Reflective và mục tiêu là so sánh với các nghiên cứu dùng AMOS.
8. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Nghiên cứu sử dụng PLS-SEM không chỉ là bài tập học thuật mà mang lại giá trị thực tiễn lớn cho doanh nghiệp:
- Tối ưu hóa nguồn lực (Resource Allocation): Nhờ phân tích IPMA, nhà quản trị biết chính xác cần đầu tư vào đâu. Ví dụ: Nếu “Thái độ nhân viên” có tác động mạnh gấp đôi “Cơ sở vật chất” lên sự hài lòng, nhưng điểm hiệu suất đang thấp, doanh nghiệp sẽ ưu tiên training nhân viên thay vì sửa sang cửa hàng.
- Dự báo hành vi (Predictive Analytics): PLS-SEM cho phép dự báo xác suất khách hàng rời bỏ dịch vụ (Churn rate) hoặc khả năng mua lại dựa trên dữ liệu khảo sát hiện tại.
- Phân khúc thị trường chuyên sâu: Thông qua FIMIX-PLS, doanh nghiệp phát hiện được các nhóm khách hàng có hành vi khác biệt mà các tiêu chí nhân khẩu học thông thường (tuổi, giới tính) không thể nhìn thấy được.
9. Các Câu Hỏi Thường Gặp (FAQ)
Tôi có thể dùng PLS-SEM để kiểm định sự phù hợp của mô hình (Model Fit) như AMOS không?
Không nên. Mục tiêu cốt lõi của PLS-SEM là tối đa hóa khả năng dự báo (R²), không phải tối thiểu hóa sự khác biệt hiệp phương sai. Các chỉ số như SRMR chỉ mang tính tham khảo để phát hiện sai biệt lớn, đừng dùng nó để bác bỏ một mô hình có các chỉ số đo lường và cấu trúc tốt.
Sự khác biệt cơ bản nhất giữa mô hình Reflective và Formative là gì?
- Reflective (Kết quả): Mũi tên đi từ Biến → Chỉ báo. Giả định biến tiềm ẩn gây ra chỉ báo. Các chỉ báo phải tương quan mạnh, có thể thay thế nhau (bỏ bớt 1 câu hỏi không làm thay đổi ý nghĩa).
- Formative (Cấu tạo/Nguyên nhân): Mũi tên đi từ Chỉ báo → Biến. Giả định các chỉ báo tạo thành biến. Chúng không cần tương quan và không được tùy tiện bỏ bớt vì sẽ làm thay đổi bản chất của biến (ví dụ: Chỉ số GDP được cấu thành từ Tiêu dùng, Đầu tư, Chi tiêu chính phủ… bỏ bớt một cái là sai bản chất).
Nếu dữ liệu của tôi thiếu nhiều (Missing Data) thì xử lý sao?
- Nếu thiếu < 5% mỗi biến: Dùng Mean Replacement (Thay thế bằng trung bình).
- Nếu thiếu > 15%: Hãy mạnh dạn xóa quan sát đó để đảm bảo độ sạch (Cleanliness) của dữ liệu, vì PLS-SEM cần chất lượng dữ liệu tốt để Bootstrap chính xác.
10. Tài Liệu Tham Khảo (References)
Dưới đây là danh sách đầy đủ các tài liệu tham khảo nền tảng được trích xuất từ sách, tuân thủ chuẩn APA để bạn đưa vào luận văn:
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2017). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (2nd ed.). Thousand Oaks, CA: Sage.
Ringle, C. M., Wende, S., & Becker, J.-M. (2015). SmartPLS 3. Boenningstedt: SmartPLS GmbH.
Aguinis, H., Beaty, J. C., Boik, R. J., & Pierce, C. A. (2005). Effect size and power in assessing moderating effects of categorical variables using multiple regression: A 30-year review. Journal of Applied Psychology, 90(1), 94–107.
Albers, S. (2010). PLS and success factor studies in marketing. In V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of Partial Least Squares: Concepts, Methods and Applications (pp. 409–425). Berlin: Springer.
Barclay, D. W., Higgins, C. A., & Thompson, R. (1995). The partial least squares approach to causal modeling: Personal computer adoption and use as illustration. Technology Studies, 2(2), 285–309.
Baron, R. M., & Kenny, D. A. (1986). The moderator-mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173–1182.
Becker, J.-M., Klein, K., & Wetzels, M. (2012). Formative hierarchical latent variable models in PLS-SEM. Long Range Planning, 45(5-6), 359–394.
Becker, J.-M., Rai, A., Ringle, C. M., & Völckner, F. (2013). Discovering unobserved heterogeneity in structural equation models to avert validity threats. MIS Quarterly, 37(3), 665–694.
Bentler, P. M., & Huang, W. (2014). On components, latent variables, PLS and simple methods: Reactions to Rigdon’s rethinking of PLS. Long Range Planning, 47(3), 136–145.
Chin, W. W. (1998). The partial least squares approach to structural equation modeling. In G. A. Marcoulides (Ed.), Modern Methods for Business Research (pp. 295–358). Mahwah, NJ: Lawrence Erlbaum.
Chin, W. W. (2010). How to write up and report PLS analyses. In V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of Partial Least Squares: Concepts, Methods and Applications (pp. 655–690). Berlin: Springer.
Chin, W. W., Marcolin, B. L., & Newsted, P. R. (2003). A partial least squares latent variable modeling approach for measuring interaction effects. Information Systems Research, 14(2), 189–217.
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2nd ed.). Mahwah, NJ: Lawrence Erlbaum.
Cohen, J. (1992). A power primer. Psychological Bulletin, 112(1), 155–159.
Diamantopoulos, A., & Winklhofer, H. M. (2001). Index construction with formative indicators: An alternative to scale development. Journal of Marketing Research, 38(2), 269–277.
Dijkstra, T. K., & Henseler, J. (2015a). Consistent and asymptotically normal PLS estimators for linear structural equations. Computational Statistics & Data Analysis, 81, 10–23.
Dijkstra, T. K., & Henseler, J. (2015b). Consistent partial least squares path modeling. MIS Quarterly, 39(2), 297–316.
Fornell, C., & Larcker, D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 18(1), 39–50.
Geisser, S. (1974). A predictive approach to the random effects model. Biometrika, 61(1), 101–107.
Gudergan, S. P., Ringle, C. M., Wende, S., & Will, A. (2008). Confirmatory tetrad analysis in PLS path modeling. Journal of Business Research, 61(12), 1238–1249.
Hair, J. F., Ringle, C. M., & Sarstedt, M. (2011). PLS-SEM: Indeed a silver bullet. Journal of Marketing Theory and Practice, 19(2), 139–151.
Hair, J. F., Sarstedt, M., Ringle, C. M., & Mena, J. A. (2012). An assessment of the use of partial least squares structural equation modeling in marketing research. Journal of the Academy of Marketing Science, 40(3), 414–433.
Hayes, A. F. (2013). Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach. New York, NY: Guilford Press.
Hayes, A. F. (2015). An index and test of linear moderated mediation. Multivariate Behavioral Research, 50(1), 1–22.
Henseler, J., & Chin, W. W. (2010). A comparison of approaches for the analysis of interaction effects between latent variables. Structural Equation Modeling, 17(1), 82–109.
Henseler, J., Ringle, C. M., & Sarstedt, M. (2015). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115–135.
Henseler, J., Ringle, C. M., & Sinkovics, R. R. (2009). The use of partial least squares path modeling in international marketing. Advances in International Marketing, 20, 277–320.
Höck, M., Ringle, C. M., & Sarstedt, M. (2010). Management of multi-purpose stadiums: Importance and performance measurement of service interfaces. International Journal of Services Technology and Management, 14(2-3), 188–207.
Little, T. D., Bovaird, J. A., & Widaman, K. F. (2006). On the merits of orthogonalizing powered and product terms: Implications for modeling interactions. Structural Equation Modeling, 13(4), 497–519.
Lohmöller, J.-B. (1989). Latent Variable Path Modeling with Partial Least Squares. Heidelberg: Physica.
Preacher, K. J., & Hayes, A. F. (2008). Asymptotic and resampling strategies for assessing and comparing indirect effects in simple and multiple mediator models. Behavior Research Methods, 40(3), 879–891.
Reinartz, W., Haenlein, M., & Henseler, J. (2009). An empirical comparison of the efficacy of covariance-based and variance-based structural equation modeling. International Journal of Research in Marketing, 26(4), 332–344.
Rigdon, E. E. (2012). Rethinking partial least squares path modeling: In praise of simple methods. Long Range Planning, 45(5-6), 341–358.
Ringle, C. M., Sarstedt, M., & Straub, D. W. (2012). A critical look at the use of PLS-SEM in MIS Quarterly. MIS Quarterly, 36(1), iii–xiv.
Sarstedt, M., Henseler, J., & Ringle, C. M. (2011). Multi-group analysis in partial least squares (PLS) path modeling: Alternative methods and empirical results. Advances in International Marketing, 22, 195–218.
Sarstedt, M., Ringle, C. M., Henseler, J., & Hair, J. F. (2014). On the emancipation of PLS-SEM: A commentary on Rigdon (2012). Long Range Planning, 47(3), 154–160.
Shmueli, G. (2010). To explain or to predict? Statistical Science, 25(3), 289–310.
Sobel, M. E. (1982). Asymptotic confidence intervals for indirect effects in structural equation models. Sociological Methodology, 13, 290–312.
Stone, M. (1974). Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical Society: Series B (Methodological), 36(2), 111–147.
Wold, H. (1982). Soft modeling: The basic design and some extensions. In K. G. Jöreskog & H. Wold (Eds.), Systems under Indirect Observation: Causality, Structure, Prediction (Part II, pp. 1–54). Amsterdam: North-Holland.
Zhao, X., Lynch, J. G., & Chen, Q. (2010). Reconsidering Baron and Kenny: Myths and truths about mediation analysis. Journal of Consumer Research, 37(2), 197–206.
Khuyến nghị bạn tải xuống và lưu trữ tài liệu tham khảo chính thức dưới đây để phục vụ cho quá trình trích dẫn và tra cứu chuyên sâu:
Tải tài liệu nghiên cứu gốc (Full PDF):
Xem thêm:
Báo cáo kết quả PLS-SEM theo Hair et al. (2019): Hướng dẫn chuẩn hóa và Quy trình thực hiện
Các Lý thuyết tổ chức: Tiêu Chí Đánh Giá, Cấu Trúc và Nền Tảng Xây Dựng (Bacharach, 1989)
Đóng góp lý thuyết trong Nghiên cứu Quản trị Xu hướng qua 5 Thập kỷ (Theoretical Contribution)
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



