
Vấn đề ảo giác AI (Hallucination) là tình trạng các mô hình ngôn ngữ lớn (LLMs) tự tạo ra thông tin và các trích dẫn học thuật không có thật. Nguyên nhân chính là do cơ chế dự đoán từ tiếp theo (Generative) thay vì truy xuất dữ liệu thực tế. Giải pháp nhanh nhất là tìm tài liệu bằng Perplexity AI, một nền tảng tích hợp cơ chế RAG giúp truy xuất trực tiếp các công bố khoa học với nguồn gốc rõ ràng, minh bạch.

1. Giới Thiệu: Vấn Đề Trích Dẫn Dữ Liệu Trong Các Mô Hình Ngôn Ngữ Lớn (LLMs)
Trong lĩnh vực nghiên cứu học thuật, tính chính xác và liêm chính của dữ liệu là yếu tố kiên quyết. Tuy nhiên, việc ứng dụng các mô hình ngôn ngữ lớn truyền thống vào việc tổng quan tài liệu (Literature Review) thường vấp phải rào cản lớn: hiện tượng ảo giác AI. Hệ thống có xu hướng tạo ra các tiêu đề bài báo khoa học, tên tác giả, hoặc chỉ số DOI giả mạo để làm hài lòng truy vấn của người dùng. Điều này tạo ra rủi ro nghiêm trọng về đạo đức nghiên cứu và làm mất thời gian kiểm chứng. Việc chuyển đổi sang các công cụ chuyên biệt có khả năng đối soát dữ liệu theo thời gian thực đã trở thành một yêu cầu bắt buộc đối với các nhà nghiên cứu và học giả.

2. Cơ Chế Hoạt Động Khác Biệt Giữa Perplexity AI Và ChatGPT Trong Nghiên Cứu
Để hiểu rõ hiệu quả của phương pháp tìm tài liệu bằng Perplexity AI, cần phân tích sự khác biệt trong kiến trúc nền tảng giữa hệ thống này và các LLMs thông thường.
Bảng so sánh cơ chế hoạt động của Perplexity AI và ChatGPT trong ngữ cảnh học thuật:
| Tiêu chí phân tích | ChatGPT (Cơ chế Generative thuần túy) | Perplexity AI (Cơ chế RAG) |
| Cơ chế cốt lõi | Dự đoán chuỗi xác suất từ vựng (Next-token prediction). | Truy xuất tăng cường tạo sinh (Retrieval-Augmented Generation). |
| Nguồn dữ liệu | Phụ thuộc vào tập dữ liệu huấn luyện có sẵn (bị giới hạn thời gian). | Truy vấn trực tiếp internet và cơ sở dữ liệu học thuật theo thời gian thực. |
| Xử lý trích dẫn | Dễ mắc lỗi tạo URL giả, trích dẫn bài báo không tồn tại (Hallucination). | Cung cấp footnote (chú thích) trích dẫn trực tiếp từ URL/nguồn tài liệu gốc. |
| Tính ứng dụng | Lên ý tưởng, viết lại câu, định dạng văn bản. | Tổng quan tài liệu, tìm kiếm báo cáo khoa học, kiểm chứng số liệu thực tế. |
2.1. Hạn Chế Của Cơ Chế Khởi Tạo Văn Bản (Generative) Ở ChatGPT
Cơ chế cốt lõi của ChatGPT tập trung vào việc tạo ra văn bản tự nhiên, trôi chảy dựa trên phân phối xác suất của từ vựng trong tập dữ liệu huấn luyện. Do không được thiết kế ban đầu như một công cụ tìm kiếm (Search Engine), mô hình này không có khả năng đối chiếu thông tin nó vừa tạo ra với các cơ sở dữ liệu bên ngoài tại thời điểm trả lời. Hệ quả là khi yêu cầu cung cấp các bài báo bình duyệt (peer-reviewed), hệ thống thường lắp ghép các từ khóa học thuật thành một trích dẫn hoàn toàn giả mạo.
2.2. Cơ Chế Truy Xuất Tích Hợp (Retrieval-Augmented Generation – RAG) Của Perplexity AI
Perplexity AI giải quyết triệt để lỗi bịa nguồn thông qua kiến trúc RAG. Khi người dùng nhập truy vấn, hệ thống không tự động sinh chữ ngay lập tức. Thay vào đó, nó thực hiện bước truy xuất (Retrieval) để quét các tài liệu thực tế trên các hệ thống cơ sở dữ liệu. Sau đó, nó đưa các tài liệu gốc này vào ngữ cảnh (Context) để mô hình ngôn ngữ lớn tiến hành tổng hợp (Generation). Quy trình này đảm bảo mọi thông tin đầu ra đều bị ràng buộc bởi các tài liệu có thật.

3. Cách Dùng Perplexity AI (Phiên Bản Pro) Để Tìm Kiếm Các Công Bố Mới Nhất
Để tối ưu hóa độ chính xác khi tìm tài liệu bằng Perplexity AI, nhà nghiên cứu cần áp dụng quy trình thiết lập tham số chuyên sâu, đặc biệt trên phiên bản Pro.
3.1. Kích Hoạt Và Tối Ưu Hóa Tính Năng “Focus – Academic” (Tính Năng Chuyên Học Thuật)
Đây là bước quan trọng nhất để loại bỏ các nguồn thông tin kém chất lượng (blog, báo chí phổ thông).
- Bước 1: Tại thanh tìm kiếm, chọn mục Focus (Tiêu điểm).
- Bước 2: Chọn bộ lọc Academic (Học thuật).
- Bước 3: Tiến hành nhập truy vấn. Lúc này, hệ thống sẽ chỉ trích xuất dữ liệu từ các thư viện khoa học uy tín như Semantic Scholar, PubMed, arXiv, v.v.
3.2. Xây Dựng Cấu Trúc Prompt Chuyên Sâu Cho Nghiên Cứu Khám Phá (Literature Review)
Việc đặt câu lệnh (Prompt) quyết định chất lượng đầu ra. Cấu trúc Prompt chuẩn khoa học cần tuân thủ các biến số:
- Chủ đề/Phạm vi: Xác định rõ đối tượng nghiên cứu (Ví dụ: Hành vi tiêu dùng bền vững).
- Điều kiện giới hạn: Yêu cầu các bài báo xuất bản trong khung thời gian nhất định (Ví dụ: Từ năm 2020 đến 2024).
- Định dạng đầu ra: Yêu cầu trình bày dưới dạng tóm tắt phương pháp nghiên cứu và kết quả chính.
- Ví dụ Prompt: “Tổng hợp 5 nghiên cứu định lượng (quantitative studies) về ảnh hưởng của AI đến hiệu suất làm việc từ năm 2022 đến nay. Cung cấp rõ phương pháp đo lường và kết luận của từng bài.”
3.3. Sử Dụng Tính Năng “Pro Search” Để Khai Thác Đa Chiều
Tính năng Pro Search (trước đây là Copilot) hoạt động như một trợ lý nghiên cứu tương tác. Thay vì trả lời ngay, hệ thống sẽ đặt các câu hỏi ngược lại cho người dùng để làm rõ hướng nghiên cứu.
- Hệ thống yêu cầu làm rõ ngành nghề cụ thể (Y tế, Giáo dục, hay Tài chính).
- Hệ thống thực hiện nhiều vòng tìm kiếm đồng thời (Multi-step reasoning) để đối chiếu thông tin từ nhiều khía cạnh trước khi đưa ra bản tóm tắt cuối cùng.
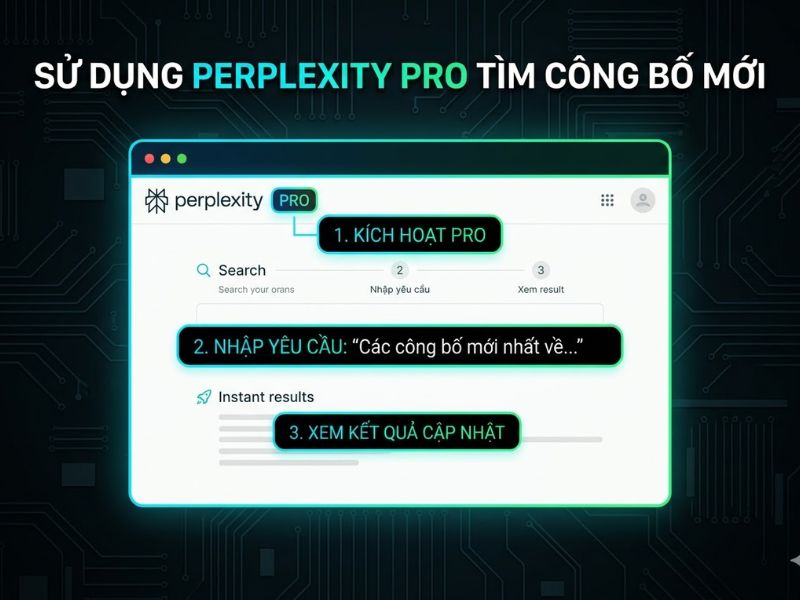
4. Quy Trình Kiểm Chứng Và Đánh Giá Độ Tin Cậy Của Trích Dẫn (Citation Verification)
Dù Perplexity AI sử dụng cơ chế RAG, nhà nghiên cứu vẫn cần thực hiện các bước đối soát độc lập nhằm đảm bảo liêm chính học thuật:
- Xác minh mã số định danh tài liệu (DOI): Nhấp vào các liên kết nguồn (footnote số [1], [2]) do Perplexity cung cấp, kiểm tra xem bài báo có chứa mã DOI hợp lệ hay không.
- Kiểm tra chéo trên Google Scholar: Copy tên bài báo hoặc tên tác giả dán vào Google Scholar để xác nhận tạp chí xuất bản có nằm trong danh mục uy tín (ISI/Scopus) hay không.
- Đọc tóm tắt gốc (Abstract): Đối chiếu nội dung Perplexity tóm tắt với bản Abstract gốc trên website của nhà xuất bản để tránh việc AI diễn giải sai lệch ý nghĩa thống kê của bài báo.
5. Tối Ưu Hóa Quy Trình Nghiên Cứu Với Perplexity AI
Việc tìm tài liệu bằng Perplexity AI đánh dấu một bước tiến quan trọng trong phương pháp luận nghiên cứu thời đại số. Thông qua việc ứng dụng công nghệ RAG, mô hình này đã khắc phục hoàn toàn rủi ro bịa nguồn của các hệ thống AI khởi tạo thông thường. Đối với các nhà quản trị, sinh viên và nghiên cứu sinh, việc khai thác đúng cách các tính năng Focus Academic và Pro Search sẽ tối ưu hóa thời gian xây dựng tổng quan tài liệu, đồng thời đảm bảo độ chính xác và tính minh bạch tuyệt đối của dữ liệu đầu vào.
Bài viết được chia sẻ và tổng hợp bởi giảng viên Nguyễn Thanh Phương, chuyên gia về tối ưu hóa quy trình nghiên cứu khoa học và phát triển năng lực quản trị doanh nghiệp.
6. Câu Hỏi Thường Gặp (FAQ) Về Việc Tích Hợp Perplexity AI Vào Nghiên Cứu Khoa Học
6.1. Phiên bản miễn phí của Perplexity AI có đáp ứng được nhu cầu tìm kiếm tài liệu chuẩn xác không?
Phiên bản miễn phí của Perplexity AI hoàn toàn có khả năng tìm kiếm tài liệu chuẩn xác nhờ cơ chế RAG mặc định. Tuy nhiên, hạn chế của bản miễn phí là số lượng truy vấn bằng tính năng Pro Search bị giới hạn, khiến việc phân tích đa chiều hoặc tìm kiếm các tài liệu chuyên sâu phức tạp không đạt hiệu suất tối đa như bản Pro.
6.2. Làm thế nào để xuất danh sách tài liệu tham khảo chuẩn (APA, IEEE) từ Perplexity?
Người dùng có thể yêu cầu Perplexity trực tiếp định dạng nguồn tài liệu thành chuẩn APA, IEEE thông qua câu lệnh Prompt. Cụ thể, sau khi hệ thống cung cấp thông tin, bạn hãy nhập câu lệnh bổ sung: “Hãy định dạng tất cả các nguồn tài liệu được trích dẫn ở trên theo tiêu chuẩn trích dẫn APA 7th Edition.” Hệ thống sẽ tự động cấu trúc lại các liên kết thành dạng danh mục tài liệu tham khảo hoàn chỉnh.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



