
Vấn đề đánh giá tác động nhân quả trong dữ liệu quan sát thường gặp nhiễu do các yếu tố không đồng nhất. Sai biệt kép (Difference-in-Differences – DiD) là phương pháp kinh tế lượng thiết kế tựa thực nghiệm giúp đo lường chính xác tác động của một chính sách hoặc sự kiện. Nguyên nhân chính gây sai lệch trong các mô hình truyền thống là nhiễu nội sinh từ các biến bỏ sót theo thời gian. Giải pháp tối ưu nhất là sử dụng DiD để tính toán sự chênh lệch kép giữa nhóm can thiệp và nhóm đối chứng trước và sau khi sự kiện xảy ra, từ đó cô lập tác động thực sự.

1. Tổng Quan Về Phương Pháp Sai Biệt Kép (Difference-in-Differences)
1.1. Khái Niệm Sai Biệt Kép (DiD) Là Gì?
Phương pháp sai biệt kép (DiD) là một kỹ thuật thống kê và kinh tế lượng được sử dụng phổ biến trong suy luận nhân quả (causal inference). Khái niệm này thuộc lĩnh vực kinh tế học ứng dụng, chính sách công và dịch tễ học.
Đặc điểm cốt lõi của sai biệt kép bao gồm:
- Tính chất tựa thực nghiệm (Quasi-experimental): DiD mô phỏng một thiết kế thực nghiệm bằng cách sử dụng dữ liệu quan sát để so sánh những đối tượng chịu tác động (nhóm can thiệp) và những đối tượng không chịu tác động (nhóm đối chứng).
- Phân tích theo chiều dọc (Longitudinal analysis): Đòi hỏi dữ liệu thu thập qua ít nhất hai mốc thời gian (trước và sau sự kiện).
- Triệt tiêu sai lệch: Giúp loại bỏ các khác biệt cố định không quan sát được giữa hai nhóm và các xu hướng chung theo thời gian ảnh hưởng đến cả hai nhóm.
1.2. Vai Trò Của DiD Trong Đánh Giá Tác Động Chính Sách
Sai biệt kép đóng vai trò nền tảng trong việc xác định hiệu quả thực tế của một can thiệp (chính sách pháp luật, chương trình y tế, chiến dịch kinh doanh). Thay vì chỉ so sánh kết quả trước và sau của một nhóm (dễ bị ảnh hưởng bởi xu hướng thời gian chung), hoặc chỉ so sánh hai nhóm tại một thời điểm (dễ bị ảnh hưởng bởi khác biệt nội tại), DiD kết hợp cả hai chiều đo lường. Điều này giúp các nhà nghiên cứu đưa ra kết luận khách quan, định lượng được sự thay đổi ròng do chính sách mang lại.
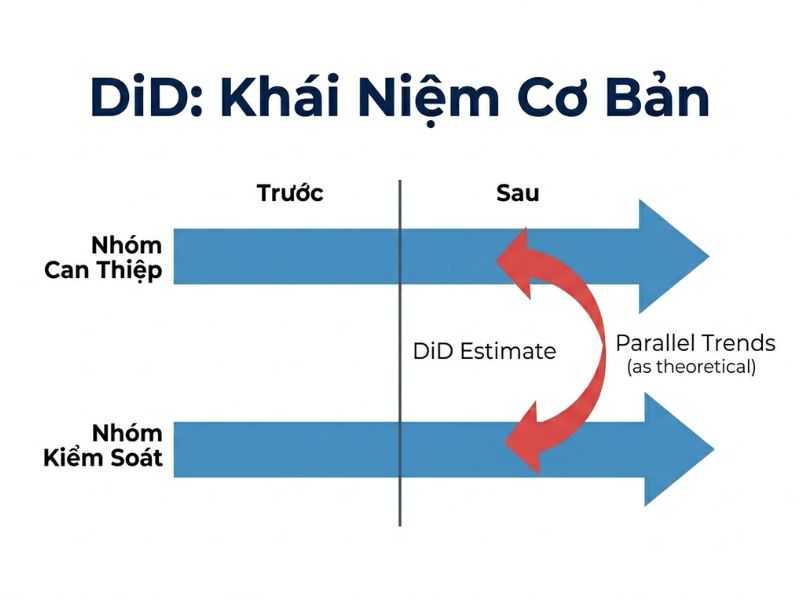
2. Thiết Lập Cấu Trúc Khung Phân Tích DiD
2.1. Phân Định Nhóm Can Thiệp (Treatment Group) Và Nhóm Đối Chứng (Control Group)
Việc thiết lập mô hình DiD bắt buộc phải định danh rõ hai nhóm thực thể:
- Nhóm can thiệp (Treatment Group): Tập hợp các đơn vị quan sát chịu sự tác động trực tiếp của chính sách hoặc sự kiện tại một thời điểm xác định.
- Nhóm đối chứng (Control Group): Tập hợp các đơn vị quan sát không chịu sự tác động của chính sách, có các đặc điểm nền tảng tương đồng với nhóm can thiệp để đóng vai trò làm mức cơ sở so sánh (baseline).
2.2. Biến Thời Gian: Giai Đoạn Trước (Pre-Treatment) Và Sau Can Thiệp (Post-Treatment)
Khung thời gian phân tích phải được chia cắt rõ ràng bởi thời điểm xảy ra sự kiện ngoại sinh:
- Giai đoạn trước (Pre-Treatment): Thời kỳ dữ liệu được thu thập khi chưa có bất kỳ sự can thiệp nào xảy ra đối với cả hai nhóm.
- Giai đoạn sau (Post-Treatment): Thời kỳ chính sách hoặc sự kiện đã có hiệu lực đối với nhóm can thiệp.
Bảng Tổng Hợp Trạng Thái Của Khung Phân Tích DiD:
| Tiêu Chí So Sánh | Nhóm Can Thiệp (Treatment Group) | Nhóm Đối Chứng (Control Group) |
| Giai đoạn Trước (Pre-Treatment) | Không có sự can thiệp (Y_T,₀) | Không có sự can thiệp (Y_C,₀) |
| Giai đoạn Sau (Post-Treatment) | Có chịu sự can thiệp (Y_T,₁) | Không có sự can thiệp (Y_C,₁) |
| Sai phân theo thời gian (Δ Time) | Mức chênh lệch: (Y_T,₁ – Y_T,₀) | Mức chênh lệch: (Y_C,₁ – Y_C,₀) |
| Sai biệt kép (DiD Estimator) | Δ DiD = (Y_T,₁ – Y_T,₀) – (Y_C,₁ – Y_C,₀) |
3. Cơ Sở Toán Học Và Phương Trình Hồi Quy Của Mô Hình DiD
3.1. Phương Trình Hồi Quy Tuyến Tính Cơ Bản
Hệ số sai biệt kép thường được ước lượng thông qua mô hình hồi quy OLS (Ordinary Least Squares) để dễ dàng kiểm soát các biến ngoại sinh khác. Phương trình cơ bản có dạng:
Y_it = β₀ + β₁ × Treatment_i + β₂ × Post_t + β₃ × (Treatment_i × Post_t) + ε_it
Trong đó:
- Y_it: Biến phụ thuộc (kết quả quan sát) của đơn vị i tại thời điểm t.
- Treatment_i: Biến giả (Dummy variable) nhận giá trị 1 nếu đơn vị i thuộc nhóm can thiệp, 0 nếu thuộc nhóm đối chứng.
- Post_t: Biến giả thời gian nhận giá trị 1 cho giai đoạn sau can thiệp, 0 cho giai đoạn trước can thiệp.
- ε_it: Sai số ngẫu nhiên.
3.2. Ý Nghĩa Của Hệ Số Tương Tác (Interaction Term) Đo Lường Tác Động Kép
Trong phương trình trên, β₃ (hệ số của biến tương tác Treatment_i × Post_t) chính là trọng tâm của phương pháp sai biệt kép. Hệ số β₃ đo lường mức độ tác động nhân quả ròng của chính sách đối với biến phụ thuộc.
- Nếu β₃ có ý nghĩa thống kê (p-value < mức ý nghĩa cho phép), nghiên cứu khẳng định chính sách có tạo ra sự thay đổi.
- Hệ số β₁ kiểm soát sự khác biệt ban đầu giữa hai nhóm.
- Hệ số β₂ kiểm soát xu hướng thay đổi tự nhiên theo thời gian của cả hai nhóm.

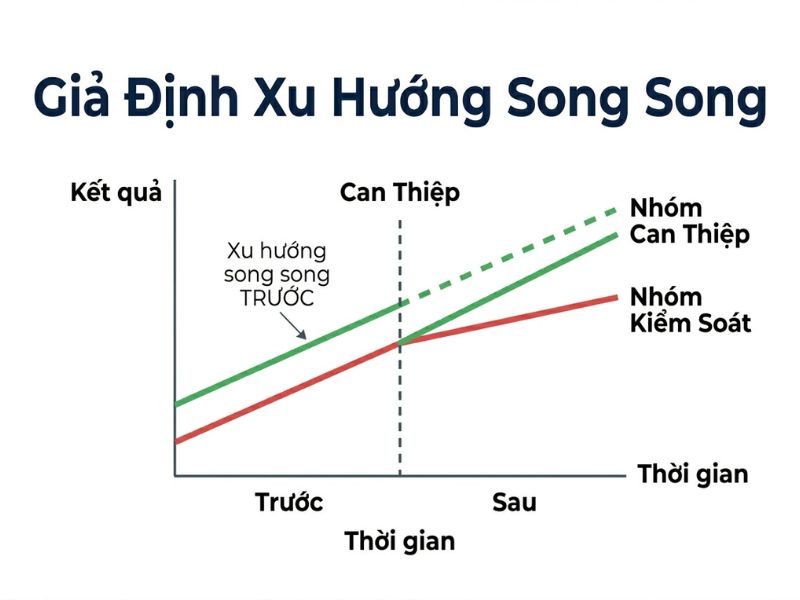
4. Giả Định Cốt Lõi: Xu Hướng Song Song (Parallel Trends Assumption)
4.1. Tầm Quan Trọng Của Giả Định Xu Hướng Song Song
Tính hợp lệ của mô hình sai biệt kép phụ thuộc tuyệt đối vào Giả định xu hướng song song (Parallel Trends Assumption). Giả định này phát biểu rằng: Nếu không có chính sách/sự kiện can thiệp xảy ra, quỹ đạo biến thiên (xu hướng) của biến kết quả ở nhóm can thiệp và nhóm đối chứng sẽ hoàn toàn song song với nhau theo thời gian. Đây là giả định không thể chứng minh trực tiếp (vì chúng ta không thể quan sát dữ liệu giả định – counterfactual của nhóm can thiệp khi không có chính sách), nhưng là nền tảng để đảm bảo β₃ không bị nhiễu.
4.2. Phương Pháp Kiểm Định Và Xử Lý Khi Vi Phạm Giả Định
Để tăng độ tin cậy, các nhà nghiên cứu định lượng phải kiểm định giả định này:
- Phân tích xu hướng trước can thiệp (Pre-trend analysis): Sử dụng dữ liệu của nhiều chu kỳ thời gian trước sự kiện để vẽ biểu đồ và chứng minh hai nhóm có xu hướng biến động tương đồng (parallel).
- Kiểm định Placebo (Placebo Test): Gán một thời điểm can thiệp giả (fake treatment time) vào giai đoạn trước sự kiện. Nếu hệ số DiD lúc này có ý nghĩa thống kê, giả định xu hướng song song đã bị vi phạm.
- Giải pháp xử lý: Nếu vi phạm, nhà nghiên cứu có thể sử dụng DiD kết hợp Propensity Score Matching (PSM-DiD) để chọn ra nhóm đối chứng tương đồng hơn, hoặc thêm các biến xu hướng thời gian riêng biệt cho từng nhóm (group-specific time trends) vào phương trình hồi quy.
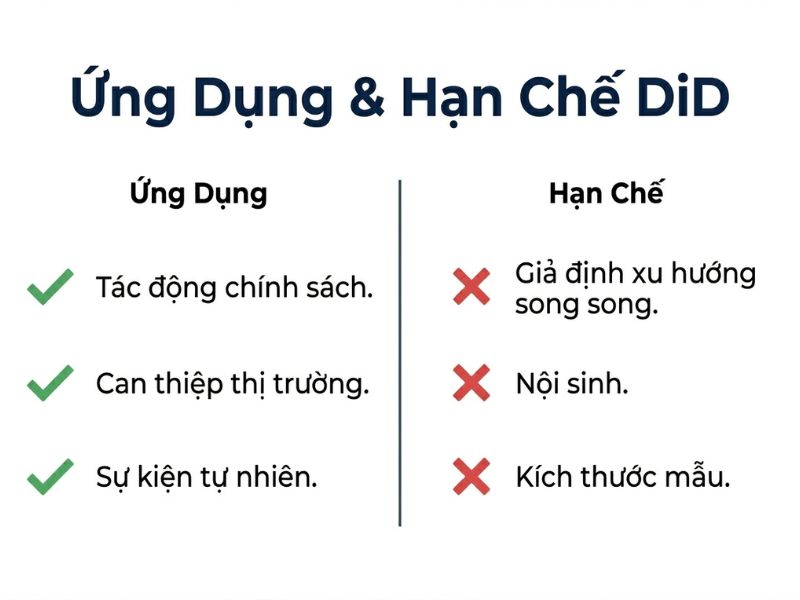
5. Ưu Điểm Và Hạn Chế Của Phương Pháp Sai Biệt Kép
5.1. Khả Năng Kiểm Soát Sai Lệch Biến Bỏ Sót (Omitted Variable Bias)
Ưu điểm lớn nhất của mô hình DiD là khả năng xử lý mạnh mẽ vấn đề sai lệch do biến bỏ sót (omitted variable bias). Nhờ cấu trúc chênh lệch hai lần, mô hình tự động triệt tiêu:
- Các đặc điểm cố định không đổi theo thời gian của các đơn vị quan sát (Time-invariant unobserved traits).
- Các cú sốc vĩ mô ảnh hưởng chung đến toàn bộ tổng thể tại một thời điểm (Common shocks).
5.2. Hạn Chế Từ Các Cú Sốc Ngoại Sinh Đứt Gãy Đồng Thời (Simultaneous External Shocks)
Dù ưu việt, sai biệt kép đối diện với các giới hạn thực tế:
- Nhiễu đồng thời (Confounding concurrent events): Nếu có một sự kiện ngoại sinh khác xảy ra cùng lúc với chính sách can thiệp và chỉ tác động đến một trong hai nhóm, kết quả DiD sẽ bị sai lệch (bias).
- Giới hạn về đối chứng: Trong nhiều trường hợp vĩ mô, việc tìm kiếm một nhóm đối chứng hoàn toàn không bị ảnh hưởng bởi chính sách (spillover effects) là rất khó khăn.
6. Vai Trò Của Sai Biệt Kép Trong Việc Ra Quyết Định Khoa Học
Phương pháp sai biệt kép (DiD) không chỉ là một công cụ kinh tế lượng hàn lâm mà còn là kim chỉ nam trong việc thiết kế và đánh giá các chiến lược thực tiễn. Bằng cách thiết lập cấu trúc đối chứng và khung thời gian nghiêm ngặt, DiD cung cấp bằng chứng định lượng chính xác về tác động nhân quả, giúp loại bỏ các kết luận cảm tính hoặc bị nhiễu bởi xu hướng chung. Đối với các nhà quản trị và học giả, việc ứng dụng thành thạo mô hình này là cơ sở vững chắc để xây dựng các bài luận văn, phân tích báo cáo và tiến hành các báo cáo nghiên cứu khoa học đạt chuẩn quốc tế.
7. Câu Hỏi Thường Gặp (FAQ) Về Mô Hình DiD
7.1. Cần Bao Nhiêu Dữ Liệu Thời Gian Trước Khi Can Thiệp Để Chứng Minh Xu Hướng Song Song?
Để chứng minh xu hướng song song một cách thuyết phục, các nhà nghiên cứu cần ít nhất 3 đến 5 chu kỳ dữ liệu (năm, quý, hoặc tháng) trước thời điểm can thiệp. Mức độ này cung cấp đủ điểm dữ liệu để vẽ quỹ đạo và chạy các kiểm định thống kê (như lead-lag model) nhằm loại trừ sự khác biệt xu hướng nền tảng giữa hai nhóm.
7.2. Phương Pháp DiD Có Thể Áp Dụng Cho Dữ Liệu Cắt Ngang (Cross-Sectional Data) Không?
Có, DiD có thể áp dụng cho dữ liệu cắt ngang gộp (Pooled Cross-Sectional Data), nhưng với điều kiện dữ liệu phải được thu thập từ cùng một tổng thể (population) ở cả trước và sau thời điểm can thiệp. Trong trường hợp này, các cá thể quan sát trước và sau không nhất thiết phải là một người (không phải panel data), miễn là đặc tính cấu trúc của hai nhóm can thiệp và đối chứng không bị thay đổi theo thời gian.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



