
Trong bối cảnh nghiên cứu khoa học xã hội và quản trị kinh doanh hiện đại, việc kiểm định các cơ chế trung gian (mediation) và điều tiết (moderation) đã trở thành chuẩn mực bắt buộc để giải thích sâu hơn về hành vi con người. Tuy nhiên, một thực trạng đáng báo động đang diễn ra phổ biến: Các nhà nghiên cứu thường sử dụng mô hình cấu trúc tuyến tính (SEM) để đánh giá thang đo, nhưng lại quay về sử dụng hồi quy truyền thống qua macro PROCESS để kiểm định giả thuyết. Đây được gọi là “Phân tích song song” (Tandem Analysis). Bài viết này, dựa trên công trình kinh điển của Sarstedt và cộng sự (2020), sẽ chứng minh tại sao phương pháp này là một bước lùi về mặt phương pháp luận. Đồng thời, chúng tôi cung cấp hướng dẫn chi tiết để thực hiện Phân tích trung gian với PLS-SEM – một giải pháp toàn diện, khoa học và tối ưu hơn, giúp khắc phục hoàn toàn các sai số mà phương pháp cũ mắc phải.

1. Tổng quan & Định nghĩa (Direct Answer)
Phân tích trung gian với PLS-SEM là phương pháp kiểm định cơ chế tác động gián tiếp giữa các biến tiềm ẩn (Latent Variables) trong một mô hình cấu trúc tổng thể, thay vì tách rời từng phương trình hồi quy. Phương pháp này cho phép ước lượng đồng thời mối quan hệ giữa các biến quan sát với biến tiềm ẩn (mô hình đo lường) và mối quan hệ giữa các biến tiềm ẩn với nhau (mô hình cấu trúc).
Vấn đề cốt lõi mà giới nghiên cứu đang gặp phải là sự lạm dụng “Phân tích song song” (Tandem Analysis). Cụ thể, quy trình này diễn ra như sau:
- Dùng SEM (thường là CB-SEM như AMOS hoặc PLS-SEM) để đánh giá độ tin cậy và giá trị thang đo.
- Sau đó trích xuất điểm nhân tố (factor scores) hoặc tệ hơn là tính điểm trung bình (mean scores).
- Cuối cùng, nhập các điểm số này vào macro PROCESS (của Hayes) trên SPSS để chạy hồi quy kiểm định giả thuyết.
Theo Sarstedt et al. (2020), đây là một thực hành sai lầm nghiêm trọng vì nó bỏ qua sai số đo lường (measurement error) vốn có trong các khái niệm trừu tượng và phá vỡ tính nhất quán của mạng lưới định danh (nomological network). Khi tách rời hai bước này, nhà nghiên cứu vô tình làm giảm sức mạnh thống kê của mô hình và đưa ra các kết luận thiếu chính xác.
Giải pháp: Các nhà nghiên cứu cần sử dụng PLS-SEM (SEM dựa trên biến tổng hợp – Composite-based SEM) để thực hiện đồng thời cả kiểm định đo lường và kiểm định cấu trúc (bao gồm trung gian, điều tiết, và trung gian có điều tiết). PLS-SEM ngày nay đã phát triển vượt bậc, cung cấp đầy đủ các chỉ số như khoảng tin cậy Bootstrap, kiểm định ý nghĩa thống kê mà không cần phải nhờ đến sự hỗ trợ của PROCESS.
2. Thông tin định danh bài báo khoa học (Article Metadata)
Để đảm bảo tính minh bạch, độ tin cậy khoa học và phục vụ cho việc trích dẫn trong các công trình nghiên cứu cấp cao, bài viết này được xây dựng và phân tích sâu dựa trên dữ liệu từ công trình gốc sau:
- Tiêu đề gốc: Beyond a tandem analysis of SEM and PROCESS: Use of PLS-SEM for mediation analyses!
- Tiêu đề tiếng Việt: Vượt ra ngoài phân tích song song SEM và PROCESS: Sử dụng PLS-SEM cho các phân tích trung gian!
- Tác giả: Marko Sarstedt, Joseph F. Hair Jr., Christian Nitzl, Christian M. Ringle, Matt C. Howard.
- Tạp chí: International Journal of Market Research, Vol. 62(3), 288–299.
- Năm xuất bản: 2020.
- DOI: 10.1177/1470785320915686.

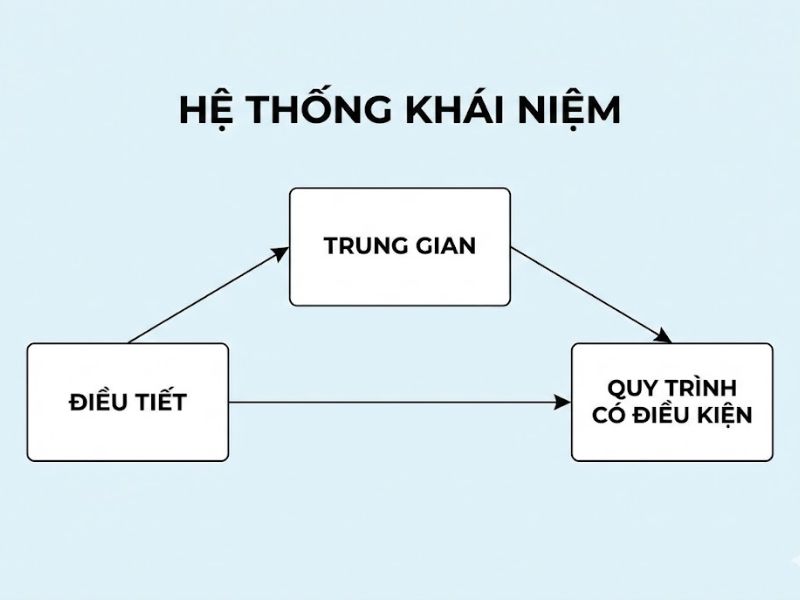
3. Hệ thống Khái niệm: Trung gian, Điều tiết và Quy trình có điều kiện
Trước khi đi sâu vào kỹ thuật phân tích dữ liệu, chúng ta cần phân định rõ các khái niệm lý thuyết nền tảng được đề cập trong bài báo để tránh nhầm lẫn về mặt bản chất:
3.1. Trung gian (Mediation)
Là thiết kế nghiên cứu xuất hiện một biến thứ ba (Biến trung gian – Mediator) can thiệp vào mối quan hệ giữa biến độc lập và biến phụ thuộc. Khái niệm này trả lời cho câu hỏi “Tại sao” hoặc “Thông qua cơ chế nào” mà một nguyên nhân dẫn đến kết quả.
- Cơ chế: Biến độc lập (X) tác động làm thay đổi Biến trung gian (M), và từ sự thay đổi của M dẫn đến sự thay đổi của Biến phụ thuộc (Y).
- Ví dụ: Quảng cáo (X) → Nhận thức thương hiệu (M) → Quyết định mua (Y).
3.2. Điều tiết (Moderation)
Là thiết kế nghiên cứu trong đó biến thứ ba (Biến điều tiết – Moderator) tác động trực tiếp đến độ mạnh hoặc hướng của mối quan hệ giữa hai khái niệm khác. Nó trả lời cho câu hỏi “Khi nào”, “Trong điều kiện nào” hoặc “Đối với nhóm đối tượng nào” thì mối quan hệ xảy ra mạnh hơn hoặc yếu đi.
- Ví dụ: Mối quan hệ giữa Giá cả và Ý định mua sẽ yếu đi đối với nhóm khách hàng có Thu nhập cao (Biến điều tiết).
3.3. Quy trình có điều kiện (Conditional Process Models)
Đây là mô hình phức tạp kết hợp cả trung gian và điều tiết (thường gọi là Trung gian có điều tiết – Moderated Mediation). Đây là dạng mô hình phản ánh sát thực tế nhất trong khoa học xã hội.
- Ví dụ: Một biến điều tiết tác động lên đường dẫn từ X → M (Giai đoạn 1) hoặc từ M → Y (Giai đoạn 2).
Các mô hình này thường rất khó ước lượng chính xác nếu sử dụng các phương pháp hồi quy truyền thống (như OLS trong SPSS) do sự phức tạp của việc tạo biến tương tác và sự cộng hưởng của các sai số đo lường.
4. Hạn chế cốt lõi của PROCESS trong Mạng lưới Định danh (Nomological Networks)
Một trong những lập luận đanh thép nhất và quan trọng nhất của Sarstedt và cộng sự (2020) là sự khác biệt nền tảng trong cách xử lý Mạng lưới định danh giữa hai phương pháp.
4.1. Tư duy manh mún của PROCESS (Piecemeal Approach)
PROCESS hoạt động dựa trên nguyên tắc hồi quy Bình phương tối thiểu thông thường (OLS) từng phần. Khi kiểm định một mô hình trung gian đơn giản (X → M → Y):
- Nó chạy một phương trình hồi quy cho M lên X.
- Nó chạy một phương trình hồi quy riêng biệt cho Y lên X và M.
Hệ quả: Việc ước lượng tham số trong phương trình này hoàn toàn không ảnh hưởng hay liên quan gì đến phương trình kia. Nó xử lý các mối quan hệ như các quy trình riêng biệt, rời rạc. Điều này đi ngược lại tư duy hệ thống (Jacoby, 1978), vốn cho rằng các biến trong một mạng lưới lý thuyết luôn có sự tác động qua lại lẫn nhau. PROCESS hoàn toàn bỏ qua các tiền tố khác của X hoặc Y trong cùng một mạng lưới nếu chúng không được đưa vào phương trình hồi quy cụ thể đó.
4.2. Tư duy tổng thể của PLS-SEM (Holistic Approach)
Ngược lại, Phân tích trung gian với PLS-SEM ước lượng toàn bộ mô hình cấu trúc trong một lần phân tích duy nhất (simultaneous estimation).
Quy trình lặp (Iterative process): PLS-SEM sử dụng thuật toán lặp để tính toán điểm số của các khái niệm (construct scores) nhằm tối đa hóa phương sai giải thích (R²) của biến phụ thuộc. Điểm số này được tính dựa trên bối cảnh của toàn bộ mô hình (bao gồm cả các biến tiền đề, biến kết quả và các biến khác trong mạng lưới).
Ví dụ thực tế (Mô hình ACSI – Hình 2 trong bài báo): Khi xét mối quan hệ Sự hài lòng → Hành vi phàn nàn → Lòng trung thành.
- Với PROCESS: Nó chỉ nhìn vào 3 biến này một cách cô lập, cắt đứt mối liên hệ với phần còn lại của lý thuyết.
- Với PLS-SEM: Thuật toán sẽ tính toán điểm số của “Sự hài lòng” bằng cách cân nhắc cả sự tác động của các biến đi trước nó như “Kỳ vọng của khách hàng”, “Chất lượng cảm nhận”, và “Giá trị cảm nhận”. Điều này đảm bảo tính đại diện cao nhất của khái niệm trong bối cảnh nghiên cứu cụ thể, giúp kết quả ước lượng chính xác hơn về mặt thực tiễn.
5. Vấn đề “Không xác định của Nhân tố” (Factor Indeterminacy)
Tại sao không nên dùng AMOS/LISREL (Factor-based SEM) để lấy điểm nhân tố rồi chạy trong PROCESS? Đây là một kiến thức chuyên sâu về toán học thống kê mà bài báo làm rõ, giúp bạn phản biện lại các yêu cầu vô lý từ người phản biện (Reviewer):
- SEM dựa trên nhân tố (Factor-based SEM – ví dụ: CB-SEM): Các phương pháp này mắc phải vấn đề “Không xác định của nhân tố” (Factor Indeterminacy). Về mặt toán học, mô hình nhân tố chung (Common Factor Model) giả định rằng biến quan sát được tạo thành từ nhân tố chung và sai số riêng. Tuy nhiên, chúng ta không bao giờ có thể tính toán chính xác tuyệt đối điểm số của nhân tố chung đó. Nghĩa là, có vô số bộ điểm số nhân tố khác nhau có thể phù hợp với cùng một mô hình và cùng một bộ dữ liệu. Do đó, điểm số trích xuất ra là không duy nhất và không đáng tin cậy để dùng cho phân tích tiếp theo (như hồi quy trong PROCESS).
- SEM dựa trên biến tổng hợp (Component-based SEM / PLS-SEM): Điểm số biến tiềm ẩn là xác định (Determinate). Chúng được tính toán bằng cách kết hợp tuyến tính có trọng số các chỉ báo (Items). Do đó, chúng là duy nhất và hoàn toàn phù hợp để phân tích tiếp. Tuy nhiên, vì PLS-SEM đã có khả năng chạy trung gian trực tiếp rất mạnh mẽ, việc chuyển sang PROCESS là hành động dư thừa, làm tốn thời gian và không mang lại thêm giá trị khoa học nào.

6. Sai số đo lường trong Mô hình Quy trình có điều kiện (Moderated Mediation)
Đây là phần quan trọng nhất giải thích tại sao PROCESS thường thất bại hoặc đưa ra kết quả sai lệch trong các mô hình phức tạp (Conditional Process) có chứa biến điều tiết.
6.1. Tác động làm giảm (Attenuating Effect)
PROCESS sử dụng điểm trung bình (mean) hoặc điểm tổng (sum) của các câu hỏi khảo sát (items) để đại diện cho biến số. Cách làm này ngầm định rằng sai số đo lường bằng 0 (độ tin cậy = 100%), điều này là bất khả thi trong nghiên cứu khoa học xã hội. Thực tế, sai số luôn tồn tại. Việc bỏ qua sai số này dẫn đến hiện tượng “Attenuating Effect” – tức là các hệ số hồi quy ước lượng được sẽ bị thấp hơn thực tế (under-estimation), hay còn gọi là bị chệch về phía 0.
6.2. “Huyền thoại chết người” về Biến tương tác
Khi kiểm định mô hình Trung gian có điều tiết, bạn phải tạo ra một biến tương tác (Interaction term = Biến Độc lập × Biến Điều tiết).
Theo Edwards (2009), sai số đo lường sẽ bị nhân lên (cộng hưởng) trong tích của hai biến.
Ví dụ minh họa: Nếu độ tin cậy của biến X là 0.8 (khá tốt), và biến Điều tiết M là 0.8 (khá tốt). Khi nhân chúng lại với nhau để tạo biến tương tác, độ tin cậy của biến Tương tác chỉ còn: 0.8 × 0.8 = 0.64. Con số này nằm dưới mức chấp nhận được (thường là 0.70).
Hậu quả: PROCESS (với việc sử dụng điểm tổng không khử sai số) sẽ làm cho lực thống kê (statistical power) giảm nghiêm trọng. Điều này khiến bạn không thể phát hiện ra các tác động điều tiết dù chúng thực sự có tồn tại (phạm sai lầm Loại II).
6.3. Ưu thế tuyệt đối của PLS-SEM
PLS-SEM cho phép tạo biến tương tác trực tiếp từ các biến tiềm ẩn (sử dụng các phương pháp tiên tiến như Product Indicator, Two-Stage Approach hay Orthogonalizing). Nó giúp khử được sai số đo lường trong quá trình ước lượng, mang lại các lợi ích:
- Tăng độ chính xác của hệ số đường dẫn (Path coefficients).
- Duy trì lực thống kê cao để phát hiện các tương tác nhỏ, tinh tế.
- Tránh tình trạng mà Cortina et al. (2020) ví von là “Kéo phanh tay ở Cleveland nhưng nhả phanh ở Columbus” – tức là sự thiếu nhất quán khi dùng biến tiềm ẩn (đã xử lý sai số) cho tác động chính, nhưng lại dùng biến quan sát (đầy sai số) cho tác động tương tác.
7. So sánh hiệu quả: PLS-SEM vs. Tandem Analysis (Structured Data)
Dưới đây là bảng tổng hợp chi tiết các tiêu chí so sánh, dựa trên các bằng chứng thực nghiệm và lập luận khoa học từ bài báo:
| Tiêu chí | Phân tích trung gian với PLS-SEM | Phân tích song song (Tandem: SEM + PROCESS) |
| Bản chất mô hình | Xử lý đồng thời (Simultaneous), toàn diện trong mạng lưới định danh. Các biến tác động qua lại lẫn nhau. | Xử lý manh mún, rời rạc (Piecemeal). Cô lập các biến, cắt đứt ngữ cảnh lý thuyết. |
| Điểm số biến tiềm ẩn | Xác định (Determinate) – Duy nhất và chính xác nhờ thuật toán kết hợp tuyến tính. | Không xác định (Indeterminate) – Nếu dùng CB-SEM, điểm số là mơ hồ và không duy nhất. |
| Xử lý sai số đo lường | Khử sai số đo lường trong quá trình ước lượng, tách biệt phần “tín hiệu” và phần “nhiễu”. | Bỏ qua sai số (dùng điểm tổng/trung bình), gộp chung nhiễu vào tín hiệu, dẫn đến sai lệch. |
| Mô hình phức tạp | Rất mạnh với mô hình Trung gian có điều tiết (Moderated Mediation) và các mô hình nhiều cấp. | Lực thống kê rất yếu, dễ bỏ sót các tương tác có ý nghĩa do sai số bị nhân lên. |
| Sự thuận tiện | Quy trình “All-in-one” (SmartPLS, SEMinR). Một phần mềm xử lý từ A-Z. | Phức tạp, tốn thời gian chuyển đổi dữ liệu qua lại giữa nhiều phần mềm (AMOS → Excel → SPSS). |
8. Sức mạnh thống kê và Kích thước mẫu
Một lợi thế thực tiễn cực lớn được Sarstedt et al. (2020) nhấn mạnh dựa trên nghiên cứu mô phỏng Monte Carlo của Hair et al. (2017), đập tan lo ngại về việc cần mẫu khổng lồ:
- Hiệu quả với mẫu nhỏ: PLS-SEM đạt được lực thống kê (statistical power) trên 90% ngay cả với kích thước mẫu thấp (n = 100) cho các tác động trung bình. Điều này vượt trội so với CB-SEM, vốn thường yêu cầu mẫu lớn (n > 200-300) để mô hình hội tụ.
- Độ nhạy cao: Khi kích thước tác động (effect size) nhỏ, lực thống kê của PLS-SEM vẫn cao hơn 80% trong hầu hết các cấu hình mô hình.
- Kết luận: Những lo ngại về kích thước mẫu (thường gặp ở AMOS/CB-SEM) hiếm khi là vấn đề đối với PLS-SEM. Ngay cả trong các mô hình trung gian phức tạp, PLS-SEM vẫn duy trì khả năng phát hiện các mối quan hệ có ý nghĩa thống kê một cách chính xác.
9. Hướng dẫn Quy trình Phân tích chuẩn & Báo cáo
Dựa trên khuyến nghị của bài báo, để đảm bảo tính chuẩn mực học thuật, nhà nghiên cứu cần tuân thủ quy trình sau trong phần mềm (ví dụ: SmartPLS 3 hoặc 4):
- Chỉ định mô hình: Xây dựng toàn bộ mô hình (bao gồm biến độc lập, trung gian, phụ thuộc, và điều tiết) trong phần mềm PLS.
- Đánh giá mô hình đo lường:
- Kiểm tra độ tin cậy nhất quán nội tại (Cronbach’s Alpha, Composite Reliability – CR).
- Kiểm tra giá trị hội tụ (AVE > 0.5).
- Kiểm tra giá trị phân biệt (HTMT < 0.85 hoặc 0.90).
- Ước lượng ý nghĩa (Bootstrapping):
- Sử dụng kỹ thuật Bootstrapping với số lượng mẫu lặp lớn (khuyến nghị 5.000 – 10.000 subsamples) để đảm bảo độ ổn định.
- Lưu ý quan trọng về Khoảng tin cậy: Hayes và Scharkow (2013) chỉ ra rằng Khoảng tin cậy hiệu chỉnh độ lệch (Bias-Corrected CI) có lực thống kê tốt nhất, trong khi Phương pháp phân vị (Percentile Bootstrap) tốt hơn để giảm sai lầm loại I (báo cáo dương tính giả). Sarstedt khuyên nên báo cáo rõ loại CI sử dụng (thường dùng Bias-Corrected & Accelerated – BCa).
- Báo cáo kết quả:
- Báo cáo trực tiếp các hệ số đường dẫn (β), giá trị t (t-value), giá trị p (p-value) và khoảng tin cậy (CI) từ output của PLS-SEM.
- Tuyệt đối không xuất dữ liệu ra SPSS để chạy lại PROCESS nhằm lấy kết quả khác.
10. Các hướng nghiên cứu tương lai (Future Research Applications)
Bài báo không chỉ dừng lại ở phê bình mà còn gợi mở những hướng đi mới đầy tiềm năng cho các nhà nghiên cứu phương pháp luận (Methodologists) và Nghiên cứu sinh (PhD Students):
- Sức mạnh dự báo (Predictive Power): Thay vì chỉ tập trung vào khả năng giải thích (R²), hãy áp dụng quy trình PLSpredict (Shmueli et al., 2016, 2019) cho các mô hình trung gian. Cần tách biệt dự báo của mô hình đo lường và dự báo của mô hình cấu trúc để đánh giá xem biến trung gian thực sự đóng góp bao nhiêu vào khả năng dự báo biến phụ thuộc.
- So sánh mô hình (Model Comparison): Sử dụng các chỉ số mới (như BIC, AIC trong bối cảnh PLS) để so sánh độ phù hợp và sức mạnh dự báo giữa các cấu trúc mô hình trung gian khác nhau (ví dụ: so sánh giữa Trung gian toàn phần vs. Trung gian một phần).
- Điều kiện biên (Boundary Conditions): Kiểm định xem các kết luận về Bootstrap (Bias-Corrected vs. Percentile) có nhất quán trong mọi trường hợp phân phối dữ liệu của PLS-SEM hay không (ví dụ: dữ liệu cực kỳ không chuẩn).
11. Kết luận (Conclusion)
Bài báo của Sarstedt và cộng sự (2020) là lời khẳng định đanh thép và khoa học: Không cần thiết và không nên sử dụng song song SEM và PROCESS.
Việc sử dụng các phương pháp SEM dựa trên biến tổng hợp (đặc biệt là PLS-SEM) là phương pháp ưu việt nhất hiện nay để ước lượng các mô hình trung gian và quy trình có điều kiện. Nó khắc phục được điểm yếu “chí tử” của hồi quy OLS (trong PROCESS) là việc bỏ qua sai số đo lường – yếu tố có thể phá hủy độ chính xác và làm sai lệch hoàn toàn kết quả của các mô hình nghiên cứu khoa học xã hội phức tạp. Sử dụng PLS-SEM là bước đi đúng đắn để nâng cao chất lượng và độ tin cậy của nghiên cứu.
12. Các câu hỏi thường gặp (FAQ)
Tôi đang dùng AMOS (CB-SEM), tôi có thể lấy điểm nhân tố để chạy PROCESS không?
A: Không nên. Như đã phân tích ở mục 5, điểm số từ CB-SEM là “không xác định” (indeterminate) về mặt toán học. Việc đưa nó vào PROCESS là sai về mặt phương pháp luận và làm giảm độ chính xác. Nếu bạn dùng AMOS, hãy chạy trung gian trực tiếp trong AMOS (sử dụng User-defined estimands và Bootstrapping).
PLS-SEM có bị chệch (Bias) không?
A: Về lý thuyết, PLS-SEM có thể có độ chệch nhỏ (do tính chất của ước lượng composite), nhưng các nghiên cứu mô phỏng (Simulation studies) đã chứng minh rằng độ chệch này là không đáng kể và hoàn toàn chấp nhận được so với lợi ích khổng lồ về sức mạnh thống kê mà nó mang lại. Ngược lại, sai lệch do bỏ qua sai số đo lường của PROCESS còn nghiêm trọng hơn gấp nhiều lần.
Tôi nên dùng phần mềm nào để thực hiện theo khuyến nghị của bài báo này?
A: Các phần mềm PLS-SEM hiện đại như SmartPLS (giao diện kéo thả dễ dùng, trực quan) hoặc gói SEMinR (miễn phí, mạnh mẽ) trong ngôn ngữ lập trình R là những lựa chọn tối ưu nhất và chuẩn xác nhất để thực hiện các phân tích này.
13. Tài liệu tham khảo (References)
Aguinis, H., Beaty, J. C., Boik, R. J., & Pierce, C. A. (2005). Effect size and power in assessing moderating effects of categorical variables using multiple regression: a 30-year review. Journal of Applied Psychology, 90(1), 94-107.
Aguinis, H., Edwards, J. R., & Bradley, K. J. (2017). Improving our understanding of moderation and mediation in strategic management research. Organizational Research Methods, 20(4), 665-685.
Becker, J.-M., Ringle, C. M., & Sarstedt, M. (2018). Estimating moderating effects in PLS-SEM and PLSC-SEM: Interaction term generation*data treatment. Journal of Applied Structural Equation Modeling, 2, 1-21.
Bollen, K. A. (2002). Latent variables in psychology and the social sciences. Annual Review of Psychology, 53, 605-634.
Borau, S., El Akremi, A., Elgaaied-Gambier, L., Hamdi-Kidar, L., & Ranchoux, C. (2015). Analysing moderated mediation effects: Marketing applications. Recherche et Applications en Marketing (English Edition), 30, 88-128.
Busemeyer, J. R., & Jones, L. E. (1983). Analysis of multiplicative combination rules when the causal variables are measured with error. Psychological Bulletin, 93(3), 549-562.
Cheung, G. W., & Lau, R. S. (2017). Accuracy of parameter estimates and confidence intervals in moderated mediation models: A comparison of regression and latent moderated structural equations. Organizational Research Methods, 20(4), 746-769.
Chin, W. W., Marcolin, B. L., & Newsted, P. R. (2003). A Partial least squares latent variable modeling approach for measuring interaction effects: Results from a Monte Carlo simulation study and an electronic-mail emotion/adoption study. Information Systems Research, 14, 189-217.
Cole, D. A., & Preacher, K. J. (2014). Manifest variable path analysis: Potentially serious and misleading consequences due to uncorrected measurement error. Psychological Methods, 19, 300-315.
Cortina, J. M., Chen, G., & Dunlap, W. P. (2001). Testing interaction effects in LISREL: Examination and illustration of available procedures. Organizational Research Methods, 4, 324-360.
Cortina, J. M., Markell-Goldstein, H. M., Green, J. P., & Chang, Y. (2020). How are we testing interactions in latent variable models? Surging forward or fighting shy? Organizational Research Methods. Advance online publication. https://doi.org/10.1177/1094428119872531
Dawson, J. F. (2014). Moderation in management research: What, why, when, and how. Journal of Business & Psychology, 29, 1-19.
Demming, C. L., Jahn, S., & Boztug, Y. (2017). Conducting mediation analysis in marketing research. Marketing ZFP-Journal of Research and Management, 39, 76-98.
Edwards, J. R. (2009). Seven deadly myths of testing moderation in organizational research. In C. E. Lance & R. J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrine, verity and fable in the organizational and social sciences (pp. 143-164). Routlege.
Edwards, J. R., & Lambert, L. S. (2007). Methods for integrating moderation and mediation: A general analytical framework using moderated path analysis. Psychological Methods, 12, 1-22.
Finoti, L., Didonet, S. R., Toaldo, A. M., & Martins, T. (2017). The role of the marketing strategy process in the innovativeness-performance relationship of SMEs. Marketing Intelligence & Planning, 5, 298-315.
Fornell, C. G., Johnson, M. D., Anderson, E. W., Cha, J., & Bryant, B. E. (1996). The American Customer Satisfaction Index: Nature, purpose, and findings. Journal of Marketing, 60, 7-18.
Giovanis, A. (2016). Consumer-brand relationships’ development in the mobile internet market: Evidence from an extended relationship commitment paradigm. Journal of Product & Brand Management, 25, 568-585.
Giovanis, A., Athanasopoulou, P., & Tsoukatos, E. (2015). The role of service fairness in the service quality-relationship quality-customer loyalty chain: An empirical study. Journal of Service Theory and Practice, 25, 744-776.
Gong, T. (2018). Customer brand engagement behavior in online brand communities. Journal of Services Marketing, 32, 286-299.
Hair, J. F., Howard, M. C., & Nitzl, C. (2020). Assessing measurement model quality in PLS-SEM using confirmatory composite analysis. Journal of Business Research, 109, 101-110.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2017). A primer on partial least squares structural equation modeling (PLS-SEM). SAGE.
Hair, J. F., Hult, G. T. M., Ringle, C. M., Sarstedt, M., & Thiele, K. O. (2017). Mirror, mirror on the wall: A comparative evaluation of composite-based structural equation modeling methods. Journal of the Academy of Marketing Science, 45, 616-632.
Hair, J. F., Ringle, C. M., Gudergan, S. P., Fischer, A., Nitzl, C., & Menictas, C. (2019). Partial least squares structural equation modeling-based discrete choice modeling: An illustration in modeling retailer choice. Business Research, 12, 115-142.
Hair, J. F., & Sarstedt, M. (2019). Factors vs. composites: Guidelines for choosing the right structural equation modeling method. Project Management Journal, 50, 619-624.
Hair, J. F., Sarstedt, M., & Ringle, C. M. (2019). Rethinking some of the rethinking of partial least squares. European Journal of Marketing, 53, 566-584.
Hayes, A. F. (2018). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach. The Guilford Press.
Hayes, A. F., Montoya, A. K., & Rockwood, N. J. (2017). The analysis of mechanisms and their contingencies: PROCESS versus structural equation modeling. Australasian Marketing Journal, 25, 76-81.
Hayes, A. F., & Rockwood, N. J. (2020). Conditional process analysis: Concepts, computation, and advances in the modeling of the contingencies of mechanisms. American Behavioral Scientist, 64, 19-54.
Hayes, A. F., & Scharkow, M. (2013). The relative trustworthiness of inferential tests of the indirect effect in statistical mediation analysis: Does method really matter? Psychological Science, 24, 1918-1927.
Henseler, J., Dijkstra, T. K., Sarstedt, M., Ringle, C. M., Diamantopoulos, A., Straub, D. W., Ketchen, D. J., Hair, J. F., Hult, G. T. M., & Calantone, R. J. (2014). Common beliefs and reality about PLS: Comments on Rönkkö & Evermann (2013). Organizational Research Methods, 17, 182-209.
Hwang, H., Sarstedt, M., Cheah, J. H., & Ringle, C. M. (2020). A concept analysis of methodological research on composite-based structural equation modeling: Bridging PLSPM and GSCA. Behaviormetrika, 47, 219-241.
Hwang, H., & Takane, Y. (2004). Generalized structured component analysis. Psychometrika, 69, 81-99.
Hwang, H., Takane, Y., & Malhotra, N. K. (2007). Multilevel generalized structured component analysis. Behaviormetrika, 34, 95-109.
Iacobucci, D., Saldanha, N., & Deng, X. (2007). A mediation on mediation: Evidence that structural equation models perform better than regression. Journal of Consumer Psychology, 17, 140-154.
Jacoby, J. (1978). Consumer research: How valid and useful are all our consumer behavior research findings? A state of the art review. Journal of Marketing, 42, 87-96.
Jöreskog, K. G. (1973). A general method for estimating a linear structural equation system. In A. S. Goldberger & O. D. Duncan (Eds.), Structural equation models in the social sciences (pp. 255-284). Seminar Press.
Jöreskog, K. G., & Wold, H. (1982). The ML and PLS techniques for modeling with latent variables: Historical and comparative aspects. In H. Wold & K. G. Jöreskog (Eds.), Systems under indirect observation: Part I (pp. 263-270). North-Holland.
Jung, K., Takane, Y., Hwang, H., & Woodward, T. S. (2012). Dynamic GSCA (generalized structured component analysis) with applications to the analysis of effective connectivity in functional neuroimaging data. Psychometrika, 77, 827-848.
Li, M., Sharp, B. M., Bergh, D. D., & Vandenberg, R. (2019). Statistical and methodological myths and urban legends in strategic management research: The case of moderation analysis. European Management Review, 16, 209-220.
Liengaard, B., Sharma, P. N., Hult, G. T. M., Jensen, M. B., Sarstedt, M., Hair, J. F., & Ringle, C. M. (2020). Prediction: Coveted, yet forsaken? Introducing a cross-validated predictive ability test in partial least squares path modeling. Decision Sciences. Advance online publication.
Lohmöller, J.-B. (1989). Latent variable path modeling with partial least squares. Physica.
Martínez-López Francisco, J., Gázquez-Abad Juan, C., & Sousa Carlos, M. P. (2013). Structural equation modelling in marketing and business research: Critical issues and practical recommendations. European Journal of Marketing, 47, 115-152.
Memon, M., Cheah, J., Ramayah, T., Ting, H., & Chin Wei, F. (2018). Mediation analysis issues and recommendations. Journal of Applied Structural Equation Modeling, 2, 1-9.
Murphy, K. R., & Russell, C. J. (2017). Mend it or end it: Redirecting the search for interactions in the organizational sciences. Organizational Research Methods, 20(4), 549-573.
Nitzl, C., Roldán, J. L., & Cepeda, G. (2016). Mediation analyses in partial least squares structural equation modeling: Helping researchers to discuss more sophisticated models. Industrial Management & Data Systems, 116, 1849-1864.
Pek, J., & Hoyle, R. H. (2016). On the (in) validity of tests of simple mediation: Threats and solutions. Social and Personality Psychology Compass, 10, 150-163.
Ray, S., & Danks, N. (2019). SEMinR. https://cran.r-project.org/web/packages/seminr/vignettes/SEMinR.html
Rigdon, E. E., Becker, J.-M., & Sarstedt, M. (2019a). Factor indeterminacy as metrological uncertainty: Implications for advancing psychological measurement. Multivariate Behavioral Research, 54, 429-443.
Rigdon, E. E., Becker, J.-M., & Sarstedt, M. (2019b). Parceling cannot reduce factor indeterminacy in factor analysis: A research note. Psychometrika, 84, 772-780.
Rigdon, E. E., Sarstedt, M., & Becker, J.-M. (2020). Quantify uncertainty in behavioral research. Nature Human Behaviour, 4, 329-331.
Ringle, C. M., Wende, S., & Becker, J.-M. (2015). SmartPLS 3 [Computer software]. SmartPLS. www.smartpls.de
Sakib, M. N., Zolfagharian, M., & Yazdanparast, A. (2020). Does parasocial interaction with weight loss vloggers affect compliance? The role of vlogger characteristics, consumer readiness, and health consciousness. Journal of Retailing and Consumer Services, 52, Article 101733.
Sardeshmukh, S. R., & Vandenberg, R. J. (2017). Integrating moderation and mediation: A structural equation modeling approach. Organizational Research Methods, 20, 721-745.
Sarstedt, M., Hair, J. F., Ringle, C. M., Thiele, K. O., & Gudergan, S. P. (2016). Estimation issues with PLS and CBSEM: Where the bias lies!. Journal of Business Research, 69, 3998-4010.
Schönemann, P. H., & Haagen, K. (1987). On the use of factor scores for prediction. Biometrical Journal, 29, 835-847.
Sharma, P., Sarstedt, M., Shmueli, G., Kim, K. H., & Thiele, K. O. (2019). PLS-based model selection: The role of alternative explanations in information systems research. Journal of the Association for Information Systems, 20, Article 4.
Sharma, P., Shmueli, G., Sarstedt, M., Danks, N., & Ray, S. (2020). Prediction-oriented model selection in partial least squares path modeling. Decision Sciences. Advance online publication. https://doi.org/10.1111/deci.12329
Shmueli, G., Ray, S., Velasquez Estrada, J. M., & Chatla, S. B. (2016). The elephant in the room: Evaluating the predictive performance of PLS models. Journal of Business Research, 69, 4552-4564.
Shmueli, G., Sarstedt, M., Hair, J. F., Cheah, J., Ting, H., Vaithilingam, S., & Ringle, C. M. (2019). Predictive model assessment in PLS-SEM: Guidelines for using PLSpredict. European Journal of Marketing, 53, 2322-2347.
Spencer, S. J., Zanna, M. P., & Fong, G. T. (2005). Establishing a causal chain: Why experiments are often more effective than mediational analyses in examining psychological processes. Journal of Personality and Social Psychology, 89, 845-851.
Steiger, J. H. (1979). Factor indeterminacy in the 1930’s and the 1970’s some interesting parallels. Psychometrika, 44, 157-167.
Yuan, K.-H., Wen, Y., & Tang, J. (2020). Regression analysis with latent variables by partial least squares and four other composite scores: Consistency, bias and correction. Structural Equation Modeling: A Multidisciplinary Journal. Advance online publication. https://doi.org/10.1080/10705511.2019.1647107
Bài báo gốc chứa đựng nhiều minh chứng toán học chi tiết và các biểu đồ mô phỏng Monte Carlo rất giá trị để bạn sử dụng làm bằng chứng bảo vệ luận điểm trong luận án của mình trước hội đồng.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



