
PLS-SEM (Partial Least Squares Structural Equation Modeling) là phương pháp phân tích thống kê đa biến được thiết kế để ước lượng các mô hình đường dẫn phức tạp. Nguyên nhân chính khiến các nhà nghiên cứu lựa chọn PLS-SEM là khả năng xử lý hiệu quả dữ liệu không phân phối chuẩn, cỡ mẫu nhỏ và các mô hình có cấu trúc phức tạp (đặc biệt là biến nguyên nhân – formative). Giải pháp phân tích nhanh và chuẩn xác nhất là tuân thủ quy trình đánh giá hai giai đoạn (Mô hình đo lường và Mô hình cấu trúc) theo hướng dẫn của Hair et al. (2017). Bằng cách ứng dụng mô hình này, các nhà nghiên cứu và nghiên cứu sinh có thể vượt qua những rào cản khắt khe của các phương pháp thống kê thế hệ cũ, từ đó khám phá ra những mối quan hệ tiềm ẩn sâu sắc trong hành vi người tiêu dùng và chiến lược quản trị doanh nghiệp hiện đại.
1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh tài liệu
- Tiêu đề gốc: A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (Second Edition)
- Tiêu đề tiếng Việt: Hướng dẫn cơ bản về Mô hình phương trình cấu trúc bình phương tối thiểu riêng phần (PLS-SEM) – Ấn bản thứ 2
- Tác giả: Joseph F. Hair, Jr., G. Tomas M. Hult, Christian M. Ringle, Marko Sarstedt
- Nhà xuất bản: SAGE Publications (2017)
- Ghi chú học thuật: Đây được xem là “cuốn sách gối đầu giường” (must-read) và là bộ tài liệu chuẩn mực nhất trên toàn cầu cho bất kỳ ai muốn bước chân vào thế giới của phân tích định lượng dựa trên phương sai.
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Trong nghiên cứu kinh doanh và khoa học xã hội, các mô hình lý thuyết ngày càng phức tạp với sự xuất hiện của nhiều biến tiềm ẩn (latent variables) và cấu trúc đa hướng. Phương pháp CB-SEM (Covariance-Based SEM) truyền thống yêu cầu khắt khe về cỡ mẫu lớn và dữ liệu phân phối chuẩn, gây khó khăn cho nhiều nghiên cứu thực nghiệm. PLS-SEM ra đời và được Hair et al. (2017) hệ thống hóa nhằm lấp đầy khoảng trống này, cung cấp một công cụ linh hoạt, tập trung vào việc dự báo và giải thích phương sai (variance) của các cấu trúc mục tiêu thay vì tái tạo lại ma trận hiệp phương sai.
Đặc biệt, trong các cuộc khảo sát thực tế (như khảo sát mức độ hài lòng, khảo sát đánh giá nhân sự), dữ liệu thu về hiếm khi đạt được đường cong phân phối chuẩn lý tưởng (normal distribution). Việc cố ép dữ liệu vào các giả định khắt khe sẽ dẫn đến những kết luận sai lệch hoặc buộc phải loại bỏ lượng lớn dữ liệu quý giá. Do đó, PLS-SEM nổi lên như một giải pháp cứu cánh tuyệt vời, cho phép nhà nghiên cứu xử lý dữ liệu “thực” (real-world data) một cách mạnh mẽ và đáng tin cậy hơn.
1.3 Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
PLS-SEM không dựa trên một lý thuyết hành vi đơn lẻ mà là một phương pháp luận thống kê (Statistical Methodology) nền tảng cho việc kiểm định lý thuyết. Phương pháp này hoạt động dựa trên nguyên lý bình phương tối thiểu thông thường (OLS – Ordinary Least Squares) để tối đa hóa phương sai được giải thích (R²) của các biến nội sinh (endogenous latent variables). Việc ứng dụng PLS-SEM cho phép các nhà nghiên cứu mở rộng lý thuyết, kết hợp linh hoạt giữa phân tích nhân tố (Factor Analysis) và phân tích hồi quy đa biến (Multiple Regression).
Thay vì cố gắng tìm cách làm cho sự chênh lệch giữa ma trận hiệp phương sai của mẫu và mô hình lý thuyết bằng không (như thuật toán Maximum Likelihood của CB-SEM), PLS-SEM hoạt động giống như một cỗ máy tối ưu hóa thực dụng. Nó liên tục điều chỉnh các trọng số (weights) để đảm bảo rằng các biến độc lập có thể dự báo chính xác nhất sự biến thiên của biến phụ thuộc. Điều này làm cho PLS-SEM cực kỳ hữu ích trong các nghiên cứu mang tính khám phá (exploratory research) hoặc trong bối cảnh lý thuyết nền tảng vẫn đang ở giai đoạn sơ khai, cần được bổ sung và tinh chỉnh.
1.4 Cấu trúc nội dung chi tiết của tài liệu gốc (Brief Contents)
Để nắm bắt toàn diện phương pháp PLS-SEM, cuốn sách kinh điển của Hair et al. (2017) được tổ chức logic thành 8 chương cốt lõi, đi từ nền tảng lý thuyết đến các kỹ thuật nâng cao. Dưới đây là cấu trúc chi tiết để các nhà nghiên cứu tiện tra cứu:
- Chương 1: Giới thiệu về Mô hình phương trình cấu trúc (Trang 1)
- Chương 2: Xác định mô hình đường dẫn và Kiểm tra dữ liệu (Trang 36)
- Chương 3: Ước lượng mô hình đường dẫn (Trang 81)
- Chương 4: Đánh giá kết quả PLS-SEM Phần I: Đánh giá các mô hình đo lường kết quả (Reflective Measurement Models) (Trang 104)
- Chương 5: Đánh giá kết quả PLS-SEM Phần II: Đánh giá các mô hình đo lường nguyên nhân (Formative Measurement Models) (Trang 137)
- Chương 6: Đánh giá kết quả PLS-SEM Phần III: Đánh giá mô hình cấu trúc (Trang 190)
- Chương 7: Phân tích biến trung gian (Mediator) và biến điều tiết (Moderator) (Trang 227)
- Chương 8: Triển vọng về các phương pháp nâng cao (Trang 275)
- Phần Phụ lục: Thuật ngữ (Trang 312), Tài liệu tham khảo (Trang 331), Chỉ mục tác giả (Trang 346) và Chỉ mục chủ đề (Trang 350).
Mỗi chương không chỉ cung cấp nền tảng lý thuyết hàn lâm mà còn đi kèm với các ví dụ thực hành minh họa sinh động trực tiếp trên phần mềm, giúp thu hẹp khoảng cách giữa các khái niệm thống kê phức tạp và khả năng thực chiến trong việc xử lý số liệu của nhà nghiên cứu.
1.5 Lời nói đầu (Preface): Bối cảnh bùng nổ của phương pháp PLS-SEM
Ấn bản thứ 2 ra đời chỉ 2 năm sau ấn bản đầu tiên (2014) nhằm đáp ứng sự quan tâm và ứng dụng bùng nổ theo cấp số nhân của PLS-SEM trong giới học thuật. Các bài báo nền tảng của nhóm tác giả trên Journal of Academy of Marketing Science (2012) và Journal of Marketing Theory and Practice (2011) đã thu hút hàng ngàn lượt trích dẫn (citations) theo Google Scholar, minh chứng cho tầm ảnh hưởng sâu rộng của phương pháp này.
Sự tiến hóa và phương pháp sư phạm:
- Tích hợp thuật toán mới: Các nghiên cứu cập nhật đã mở rộng phương pháp luận để khám phá tính không đồng nhất chưa quan sát được (unobserved heterogeneity) và tính bất biến của mô hình đo lường. Điều này đi kèm với sự ra mắt của phần mềm SmartPLS 3, cung cấp thuật toán PLS nhất quán (consistent PLS), bootstrapping nâng cao và phân tích bản đồ IPMA. Việc thấu hiểu tính không đồng nhất chưa quan sát được giúp các nhà nghiên cứu không bị đánh lừa bởi những kết quả trung bình chung chung của toàn bộ mẫu dữ liệu, mà có thể bóc tách dữ liệu thành các phân khúc khách hàng chuyên biệt, mang lại góc nhìn sâu sắc và có độ chính xác cao hơn.
- Kỷ nguyên Dữ liệu lớn (Big Data): Sự dồi dào của dữ liệu đòi hỏi các phần mềm thống kê thân thiện, tối ưu hóa thời gian và chi phí.
- Tiếp cận thực tế (Rules of thumb): Thay vì sa đà vào các phương trình toán học phức tạp (ký hiệu Hy Lạp), tài liệu này tập trung giải thích nguyên tắc cốt lõi và cung cấp các “quy tắc kinh nghiệm” để nhà nghiên cứu dễ dàng diễn giải và đánh giá kết quả, biến một công cụ học thuật thành một đòn bẩy tư duy logic.
1.6 Tổng quan Chương 1: Sự chuyển dịch từ thống kê thế hệ thứ nhất sang thế hệ thứ hai
Trong suốt nhiều thập kỷ trước những năm 1980, các công cụ thống kê thế hệ thứ nhất (như phân tích nhân tố – Factor Analysis và phân tích hồi quy – Multiple Regression) thống trị nghiên cứu khoa học xã hội. Tuy nhiên, giới hạn của chúng nằm ở việc chỉ phân tích được một lớp quan hệ tại một thời điểm. Việc phải chia nhỏ một mô hình phức tạp thành nhiều phương trình nhỏ lẻ không chỉ gây mất thời gian mà còn làm gia tăng sai số tích lũy (accumulated error) trong toàn bộ quá trình tính toán.
Từ những năm 1990, các phương pháp thế hệ thứ hai – điển hình là Mô hình phương trình cấu trúc (SEM) – đã vươn lên mạnh mẽ, chiếm gần 50% các công cụ thống kê trong nghiên cứu thực nghiệm. SEM cho phép phân tích dữ liệu đa biến (multivariate data analysis) bằng cách đo lường đồng thời nhiều biến số và nhiều mối quan hệ trong cùng một hệ thống duy nhất.
Sự khác biệt cốt lõi giữa hai loại SEM:
- CB-SEM (Covariance-Based SEM): Sử dụng chủ yếu để xác nhận hoặc bác bỏ lý thuyết. Phương pháp này đánh giá mức độ phù hợp của mô hình lý thuyết đề xuất trong việc ước lượng lại ma trận hiệp phương sai của tập dữ liệu mẫu.
- PLS-SEM (Partial Least Squares SEM): Định hướng khám phá và phát triển lý thuyết. Thay vì tái tạo ma trận hiệp phương sai, PLS-SEM tập trung tối đa hóa việc giải thích phương sai trong các biến phụ thuộc của mô hình.
Tóm lại, sự khác biệt cốt lõi này định hình chiến lược nghiên cứu của bạn: Nếu bạn làm việc với một lý thuyết đã quá vững chắc, không có ý định bổ sung thêm biến số mới và dữ liệu hoàn toàn chuẩn mực, hãy dùng CB-SEM. Tuy nhiên, nếu bạn đang xây dựng một mô hình mới, kết hợp nhiều lý thuyết với nhau trong bối cảnh thị trường đang thay đổi liên tục, PLS-SEM chắc chắn là sự lựa chọn tối ưu và hợp lý nhất.
1.7 Mục tiêu học tập Chương 1
Theo cấu trúc nguyên bản của tài liệu, nội dung cốt lõi của Chương 1 nhằm định hướng cho người học đạt được các mục tiêu sau:
- Hiểu ý nghĩa của mô hình phương trình cấu trúc (SEM) và mối quan hệ của nó với phân tích dữ liệu đa biến.
- Mô tả các cân nhắc cơ bản trong việc áp dụng phân tích dữ liệu đa biến.
- Nắm bắt các khái niệm cơ bản về mô hình phương trình cấu trúc bình phương tối thiểu riêng phần (PLS-SEM).
- Giải thích sự khác biệt giữa SEM dựa trên hiệp phương sai (CB-SEM) và PLS-SEM, cũng như khi nào nên sử dụng từng phương pháp.
1.8 Các cân nhắc thiết yếu khi áp dụng Phân tích Đa biến & SEM
Tùy thuộc vào câu hỏi nghiên cứu và dữ liệu thực nghiệm sẵn có, các nhà nghiên cứu phải chọn phương pháp phân tích đa biến phù hợp. Dưới đây là 5 yếu tố cốt lõi quan trọng nhất cần cân nhắc:
- Biến tổng hợp (Composite Variables): Một biến tổng hợp (hay còn gọi là variate) là sự kết hợp tuyến tính của nhiều biến số được chọn dựa trên vấn đề nghiên cứu. Quá trình này bao gồm việc tính toán một tập hợp các trọng số, nhân các trọng số này với các quan sát dữ liệu tương ứng của các biến, và tính tổng của chúng.
- Đo lường (Measurement) và Biến tiềm ẩn: Đo lường là quá trình gán các con số cho một biến dựa trên một tập hợp các quy tắc. Khi hiện tượng cần đo lường rất trừu tượng, phức tạp và không thể quan sát trực tiếp (như “sự hài lòng” hay “niềm tin”), chúng ta gọi đó là các biến tiềm ẩn (latent variables) hoặc cấu trúc khái niệm (constructs). Cách tiếp cận phổ biến là đo lường chúng gián tiếp thông qua một thang đo đa biến (multi-item scale) gồm nhiều câu hỏi khảo sát (chỉ báo proxy). Mục tiêu của việc dùng nhiều câu hỏi là để giảm thiểu sai số đo lường (measurement error) – tức là sự chênh lệch giữa giá trị thực của một biến và giá trị thu được từ phép đo.
- Thang đo lường (Measurement Scales): Có bốn loại thang đo: danh nghĩa (nominal), thứ bậc (ordinal), khoảng (interval), và tỷ lệ (ratio). Thang đo danh nghĩa và thứ bậc có nhiều hạn chế về mặt toán học. Thang đo khoảng cung cấp thông tin chính xác về thứ tự và khoảng cách giữa các giá trị (equidistance), nên được phép thực hiện hầu hết các phép tính toán học. Thang đo tỷ lệ cung cấp nhiều thông tin nhất với điểm 0 tuyệt đối mang ý nghĩa thực sự.
- Mã hóa (Coding): Việc gán số cho các danh mục trả lời. Trong bối cảnh SEM, các thang đo Likert (vốn là thang đo thứ bậc) thường được mã hóa cẩn thận để đảm bảo tính đối xứng và khoảng cách đều, qua đó có thể xấp xỉ chức năng của một thang đo khoảng.
- Phân phối dữ liệu (Data Distributions): Trong khi CB-SEM đòi hỏi nghiêm ngặt dữ liệu phải có phân phối chuẩn (normal distribution), PLS-SEM thường không đưa ra giả định về phân phối dữ liệu. Tuy nhiên, các nhà nghiên cứu vẫn nên kiểm tra mức độ lệch (skewness) và độ nhọn (kurtosis) để đánh giá mức độ sai lệch của dữ liệu so với phân phối chuẩn.
2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Trong hệ thống PLS-SEM, cấu trúc khái niệm được chia thành hai thành phần cốt lõi:
2.1 Lý thuyết Cấu trúc (Structural Theory / Inner Model)
Biểu diễn mối quan hệ nhân quả giữa các biến tiềm ẩn với nhau. Đây là nơi kiểm định các giả thuyết nghiên cứu (H1, H2, H3…).
- Biến ngoại sinh (Exogenous variables): Các biến tiềm ẩn chỉ đóng vai trò độc lập, không bị tác động bởi biến nào khác trong mô hình, thường được đặt ở phía bên trái.
- Biến nội sinh (Endogenous variables): Các biến tiềm ẩn đóng vai trò phụ thuộc (hoặc vừa độc lập vừa phụ thuộc), chịu sự tác động của các biến khác.
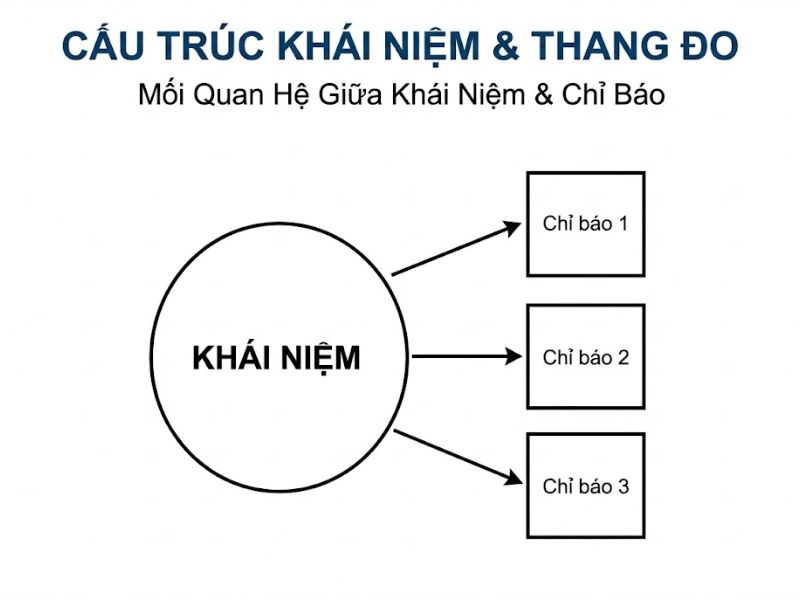
2.2 Lý thuyết Đo lường (Measurement Theory / Outer Model)
Biểu diễn mối quan hệ giữa biến tiềm ẩn (Latent Constructs) và các biến quan sát (Indicators/Items). Đây là cầu nối giữa các khái niệm trừu tượng (không đo lường trực tiếp được) với các câu hỏi cụ thể trong bảng khảo sát. Đặc biệt, PLS-SEM phân định rõ hai loại cấu trúc đo lường:
- Cấu trúc phản ánh (Reflective Constructs): Hướng mũi tên đi từ biến tiềm ẩn đến biến quan sát. Các biến quan sát có tính hoán đổi cho nhau và cùng phản ánh một khái niệm. Đặc trưng của đo lường này là luôn đi kèm với sai số đo lường (error term). (Ví dụ: Sự hài lòng của khách hàng được đo bằng 3 câu hỏi: Tôi thấy vui vẻ, Tôi thấy thỏa mãn, Tôi thấy thích thú – nếu bỏ đi 1 câu, bản chất khái niệm “Sự hài lòng” vẫn không thay đổi).
- Cấu trúc nguyên nhân (Formative Constructs): Hướng mũi tên đi từ biến quan sát đến biến tiềm ẩn. Các biến quan sát hình thành nên khái niệm và không nhất thiết phải tương quan với nhau. Những thước đo này được giả định là không có sai số. (Ví dụ: Chỉ số phát triển kinh tế được đo bằng Thu nhập bình quân, Tỷ lệ biết chữ, và Tuổi thọ – nếu bạn bỏ đi biến “Tuổi thọ”, bản chất của biến tổng “Chỉ số phát triển kinh tế” sẽ bị thay đổi hoàn toàn).
Lời khuyên từ Giáo sư: Việc hiểu sai và chỉ định sai (misspecification) hướng mũi tên giữa cấu trúc phản ánh và cấu trúc nguyên nhân là một trong những lỗi nghiêm trọng nhất, thường xuyên bị các hội đồng bảo vệ khóa luận hoặc hội đồng bình duyệt (Reviewer) bắt lỗi, có thể dẫn đến việc toàn bộ mô hình bị đánh giá là vô giá trị. Do đó, hãy cẩn trọng ngay từ khâu thiết kế bảng câu hỏi.
3. Quy Trình Phát Triển Thang Đo (Scale Development Process)
Theo Hair et al. (2017), quy trình đánh giá mô hình PLS-SEM bao gồm hai giai đoạn tuần tự và nghiêm ngặt:
- Giai đoạn 1: Đánh giá mô hình đo lường (Measurement Model Evaluation). Yêu cầu kiểm định độ tin cậy (Reliability) và độ giá trị (Validity) của các thang đo trước khi phân tích tiếp. Giai đoạn này nhằm trả lời câu hỏi: “Thước đo của chúng ta có thực sự đo lường đúng cái cần đo và đo lường một cách ổn định hay không?”.
- Giai đoạn 2: Đánh giá mô hình cấu trúc (Structural Model Evaluation). Phân tích năng lực dự báo và các mối quan hệ giả thuyết (R², f², Q², và mức độ ý nghĩa của các hệ số đường dẫn).
Sự phân chia hai giai đoạn này là nguyên tắc bắt buộc trong nghiên cứu học thuật. Bạn hoàn toàn không thể đưa ra bất kỳ kết luận quản trị nào về việc A tác động đến B (Giai đoạn 2), nếu như công cụ dùng để đo lường A và B ngay từ đầu đã bị sai lệch và chứa đầy nhiễu loạn (Giai đoạn 1). Tính logic, rành mạch và tính tuần tự chặt chẽ của quy trình này chính là nền tảng đảm bảo độ tin cậy tuyệt đối cho các bài báo cáo khoa học.
4. Thang Đo Lường Chính Thức (Measurement Scale) – Tiêu Chuẩn Đánh Giá
Dưới đây là bảng tổng hợp các chỉ số bắt buộc phải báo cáo khi sử dụng phần mềm SmartPLS để phân tích PLS-SEM, được trích xuất từ hệ thống tiêu chuẩn của Hair et al. (2017). Tất cả các ký hiệu đã được chuẩn hóa để bạn dễ dàng sao chép trực tiếp vào văn bản.
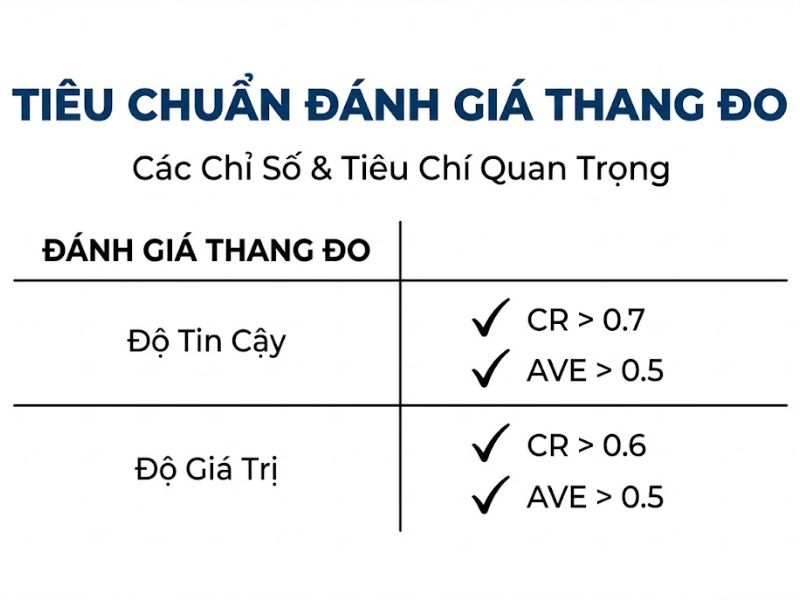
| Tiêu chí đánh giá (Criteria) | Chỉ số (Metrics) | Ngưỡng chấp nhận chuẩn khoa học (Thresholds) | Ý nghĩa (Implications) |
| Độ tin cậy nhất quán nội bộ (Internal Consistency Reliability) | Cronbach’s Alpha (α) & Composite Reliability (CR) | 0.70 ≤ Value ≤ 0.95 | Khẳng định các biến quan sát đo lường cùng một cấu trúc khái niệm. Nếu giá trị vượt quá 0.95, rất có thể các câu hỏi khảo sát đang bị lặp ý hoàn toàn (hiện tượng thừa thãi thông tin). |
| Độ giá trị hội tụ (Convergent Validity) | Hệ số tải ngoài (Outer Loadings) | ≥ 0.708 | Biến quan sát giải thích ít nhất 50% phương sai. Những chỉ báo có tải ngoài dưới 0.40 cần được loại bỏ ngay lập tức để không làm hỏng mô hình. |
| Độ giá trị hội tụ (Convergent Validity) | Phương sai trích (AVE – Average Variance Extracted) | ≥ 0.50 | Cấu trúc tiềm ẩn giải thích trung bình hơn một nửa phương sai của các biến quan sát, khẳng định mức độ hội tụ của bộ thang đo là tốt. |
| Độ giá trị phân biệt (Discriminant Validity) | HTMT (Heterotrait-Monotrait Ratio) | ≤ 0.85 (hoặc ≤ 0.90 với các cấu trúc tương đồng) | Khẳng định cấu trúc này là khác biệt hoàn toàn so với các cấu trúc khác trong mô hình. Điều này chứng minh rằng bạn không đưa hai khái niệm trùng lặp vào cùng một khung nghiên cứu. |
4.1 Đánh Giá Độ Giá Trị Phân Biệt Chuyên Sâu (Discriminant Validity) & Tỷ Lệ HTMT
Các tiêu chuẩn truyền thống thường gặp các vấn đề lớn về độ giá trị phân biệt (theo Henseler và cộng sự, 2015). Cụ thể, hệ số tải chéo (cross-loadings) thất bại trong việc chỉ ra sự thiếu hụt độ giá trị phân biệt khi hai cấu trúc khái niệm có tương quan hoàn hảo với nhau, điều này khiến tiêu chí này trở nên kém hiệu quả trong nghiên cứu thực nghiệm. Tương tự, tiêu chuẩn Fornell-Larcker cũng hoạt động rất kém, đặc biệt là khi hệ số tải của các chỉ báo (indicator loadings) thuộc các cấu trúc đang xem xét chỉ khác biệt nhau một chút (ví dụ: tất cả hệ số tải đều dao động từ 0.60 đến 0.80). Ngay cả khi hệ số tải của các chỉ báo biến thiên mạnh hơn, hiệu suất của tiêu chuẩn Fornell-Larcker trong việc phát hiện các vấn đề về độ giá trị phân biệt có cải thiện nhưng nhìn chung vẫn khá kém (Voorhees và cộng sự, 2016).
Như một giải pháp khắc phục triệt để, Henseler và cộng sự (2015) đề xuất việc sử dụng Tỷ lệ dị đặc tính – đồng đặc tính (HTMT – Heterotrait-Monotrait Ratio). Nói ngắn gọn, HTMT là tỷ lệ giữa các tương quan chéo (between-trait) và các tương quan nội bộ (within-trait).
Về mặt kỹ thuật, phương pháp HTMT là một ước lượng về mức độ tương quan thực sự giữa hai cấu trúc nếu chúng được đo lường một cách hoàn hảo (tức là nếu chúng hoàn toàn đáng tin cậy). Tương quan thực sự này còn được gọi là tương quan đã loại bỏ suy giảm (disattenuated correlation). Một tương quan disattenuated giữa hai cấu trúc mà gần bằng 1 thì chỉ ra rằng mô hình đang thiếu độ giá trị phân biệt trầm trọng.
Ngưỡng chấp nhận chính xác của HTMT: Dựa trên các nghiên cứu thực chứng, Henseler và cộng sự (2015) đề xuất các mức chuẩn mực:
- Ngưỡng 0.90: Áp dụng nếu mô hình đường dẫn bao gồm các cấu trúc có khái niệm rất giống nhau (ví dụ: sự hài lòng về mặt cảm xúc, sự hài lòng về mặt nhận thức, và lòng trung thành). Nghĩa là, giá trị HTMT trên 0.90 cho thấy thiếu độ giá trị phân biệt.
- Ngưỡng 0.85: Khi các cấu trúc trong mô hình đường dẫn có sự khác biệt rõ ràng hơn về mặt khái niệm, một ngưỡng thấp hơn và thận trọng hơn là ≤ 0.85 bắt buộc phải được áp dụng.
4.2 Kiểm Định Ý Nghĩa Thống Kê Của HTMT Bằng Bootstrapping
Ngoài việc so sánh với ngưỡng tuyệt đối, HTMT đóng vai trò là cơ sở cho một kiểm định thống kê về độ giá trị phân biệt. Tuy nhiên, vì PLS-SEM không dựa trên bất kỳ giả định phân phối nào, nên các kiểm định ý nghĩa tham số tiêu chuẩn không thể được áp dụng để kiểm tra xem liệu thống kê HTMT có khác biệt đáng kể so với 1 hay không.
Thay vào đó, các nhà nghiên cứu phải dựa vào một quy trình gọi là Bootstrapping để tạo ra phân phối của thống kê HTMT. Trong bootstrapping, các mẫu con được rút ra ngẫu nhiên (có hoàn lại) từ tập dữ liệu gốc, lặp đi lặp lại cho đến khi tạo ra một số lượng lớn (thường là 5.000 mẫu con). Ước lượng từ các mẫu con này được dùng để tính toán sai số chuẩn, từ đó thiết lập Khoảng tin cậy (Bootstrap confidence interval).
- Nếu khoảng tin cậy chứa giá trị 1: Mô hình thiếu độ giá trị phân biệt.
- Nếu giá trị 1 nằm ngoài khoảng tin cậy: Cho thấy hai cấu trúc phân biệt với nhau về mặt thực nghiệm, khẳng định mô hình đo lường đạt chuẩn.
4.3 Xử Lý Các Vấn Đề Về Độ Giá Trị Phân Biệt
Các nhà nghiên cứu nên làm gì nếu bất kỳ tiêu chí nào báo hiệu sự thiếu hụt độ giá trị phân biệt? Dưới đây là các cách tiếp cận chuyên môn được khuyên dùng:
- Loại bỏ chỉ báo (Eliminate items): Tiến hành loại bỏ các chỉ báo có tương quan thấp với các chỉ báo khác cùng đo lường một cấu trúc, hoặc loại bỏ các chỉ báo có tương quan quá mạnh với các chỉ báo của một cấu trúc đối lập. Tuy nhiên, việc loại bỏ chỉ báo đơn thuần dựa trên lý do thống kê có thể gây hậu quả xấu cho độ giá trị nội dung (content validity) của cấu trúc. Ít nhất hai chuyên gia mã hóa (expert coders) nên đánh giá độc lập để đảm bảo tính khách quan.
- Gộp các cấu trúc (Merging constructs): Tiến hành gộp các cấu trúc gây ra vấn đề thành một cấu trúc tổng quát hơn (như một biến bậc 2 – Second-order construct), nếu như hệ thống lý thuyết đo lường (measurement theory) ủng hộ bước đi này.
4.4 Quy Tắc Kinh Nghiệm (Rules of Thumb) Đánh Giá Mô Hình Đo Lường Kết Quả (Exhibit 4.10)
Tóm tắt bộ nguyên tắc đánh giá từ Chương 4:
- Độ tin cậy nhất quán nội bộ: Độ tin cậy tổng hợp (Composite Reliability) phải lớn hơn 0.70. Xem Cronbach’s alpha là giới hạn dưới và độ tin cậy tổng hợp là giới hạn trên.
- Độ tin cậy của chỉ báo: Hệ số tải ngoài (outer loadings) phải lớn hơn 0.70. Chỉ báo dao động từ 0.40 đến 0.70 chỉ nên xem xét loại bỏ nếu việc đó giúp tăng Composite Reliability và AVE vượt qua ngưỡng tối thiểu.
- Độ giá trị hội tụ: Phương sai trích (AVE) phải lớn hơn 0.50.
- Độ giá trị phân biệt: Sử dụng tiêu chí ưu tiên HTMT. Khoảng tin cậy của HTMT thu được từ kỹ thuật Bootstrapping tuyệt đối không được bao gồm giá trị 1. Theo tiêu chuẩn Fornell-Larcker, căn bậc hai của AVE của mỗi cấu trúc phải lớn hơn tương quan cao nhất của nó với bất kỳ cấu trúc nào khác trong mô hình.
4.5 Minh Họa Nghiên Cứu Tình Huống (Case Study) Trên SmartPLS 3
Sử dụng mô hình thực chứng về Danh tiếng Doanh nghiệp (Corporate Reputation), nhóm tác giả tiến hành minh họa quy trình thao tác chuẩn xác như sau:
- Chạy thuật toán PLS-SEM Algorithm: Đảm bảo thuật toán hội tụ (converged) sau một số vòng lặp (ở đây là 5 vòng, ít hơn giới hạn mặc định 300).
- Đánh giá Hệ số tải ngoài (Outer Loadings): Tất cả các hệ số tải của các biến COMP, CUSL và LIKE đều vượt xa ngưỡng 0.70 (ví dụ thấp nhất là comp_2 đạt 0.798).
- Độ tin cậy tổng hợp & Cronbach’s Alpha: Cả hai chỉ số lần lượt đạt giá trị cao (từ mức 0.776 đến 0.899).
- Đánh giá AVE: Các giá trị AVE của COMP (0.681), CUSL (0.748), và LIKE (0.747) đều lớn hơn 0.50.
- Đánh giá Fornell-Larcker và Cross-loadings: Căn bậc hai của AVE (đường chéo) lớn hơn các hệ số tương quan ở các ô còn lại, hoàn toàn thỏa mãn điều kiện.
- Đánh giá HTMT: Các giá trị HTMT (ví dụ giữa CUSL và LIKE là 0.737) đều thấp hơn ngưỡng khắt khe 0.85. Bước chạy Bootstrapping (với 5,000 mẫu lặp) cho thấy khoảng tin cậy của HTMT (ví dụ: [0.364, 0.565]) hoàn toàn không chứa giá trị 1, qua đó khẳng định chắc chắn độ giá trị phân biệt của mô hình.
(Tóm tắt Chương 4): Mục tiêu của PLS-SEM là tối đa hóa phương sai được giải thích (R²) của các biến nội sinh. Do đó việc đánh giá chia thành 2 giai đoạn: đánh giá mô hình đo lường (Giai đoạn 5) và mô hình cấu trúc (Giai đoạn 6). Mô hình kết quả (Reflective) cần đánh giá độ tin cậy chỉ báo, độ tin cậy tổng hợp, độ giá trị hội tụ (AVE) và độ giá trị phân biệt (HTMT, Fornell-Larcker). Phần mềm SmartPLS 3 cung cấp các báo cáo trực quan và toàn diện để đánh giá, giúp người nghiên cứu dễ dàng báo cáo và diễn giải số liệu chuẩn xác.
5. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
Trong một mô hình PLS-SEM tiêu chuẩn, mạng lưới quan hệ được xác định qua:
- Tiền tố (Antecedents / Exogenous Variables): Các biến độc lập không bị tác động bởi bất kỳ biến nào khác trong mô hình. Sự thay đổi của các tiền tố này giải thích trực tiếp cho sự biến thiên của các biến mục tiêu. Trong marketing, đây thường là các biến đóng vai trò “đầu vào” như chất lượng dịch vụ, giá cả, hay hình ảnh thương hiệu.
- Hậu tố (Consequences / Endogenous Variables): Các biến phụ thuộc. Mô hình PLS-SEM đánh giá sức mạnh giải thích thông qua hệ số R² (Hệ số xác định) tại các hậu tố này. R² đạt 0.75, 0.50, và 0.25 lần lượt tương ứng với mức độ giải thích mạnh, trung bình và yếu.
Bên cạnh R², các nhà nghiên cứu phương pháp luận hiện đại yêu cầu phải đánh giá thêm hệ số dự báo Q² (thông qua kỹ thuật Blindfolding) để khẳng định mô hình không chỉ “khớp” (fit) với dữ liệu mẫu hiện tại mà thực sự có năng lực dự báo chính xác các quan sát mới ngoài mẫu. Một mô hình lý thuyết vững chắc phải cân bằng được cả sức mạnh giải thích và năng lực dự báo trong thực tế.
6. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Đối với các nghiên cứu sinh và giảng viên, việc lựa chọn giữa PLS-SEM và CB-SEM cần dựa trên bản chất nghiên cứu.
- Sử dụng PLS-SEM khi: Mục tiêu cốt lõi là dự báo và phát triển lý thuyết; mô hình có chứa các biến nguyên nhân (formative constructs); dữ liệu không đảm bảo phân phối chuẩn; hoặc cỡ mẫu nhỏ (dưới 100 mẫu).
- Kỹ thuật nâng cao: Hãy áp dụng kỹ thuật Bootstrapping (với ít nhất 5,000 mẫu lặp) để tính toán sai số chuẩn và giá trị t-value nhằm xác định mức độ ý nghĩa thống kê (p-value < 0.05) của các giả thuyết nghiên cứu. Kỹ thuật lấy mẫu lại (resampling) này chính là “trái tim” của PLS-SEM để xác nhận các mối quan hệ.
Ngoài ra, khi viết luận văn hoặc bài báo gửi tạp chí quốc tế (ISI/Scopus), việc bạn trích dẫn trực tiếp các tiêu chuẩn đánh giá từ Hair et al. (2017) ở chương Phương pháp nghiên cứu sẽ là một “bảo chứng” học thuật vững chắc, giúp bài viết vượt qua sự phản biện gắt gao của các Reviewer, chứng minh tính minh bạch và am hiểu sâu sắc về phương pháp luận.
7. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
Trong thực tiễn kinh doanh, các giám đốc Marketing (CMO) có thể sử dụng kết quả từ mô hình PLS-SEM để tối ưu hóa nguồn lực. Bằng cách phân tích Bản đồ Tầm quan trọng – Hiệu suất (IPMA – Importance-Performance Map Analysis) được tích hợp trong phần mềm phân tích, nhà quản trị có thể:
- Xác định đòn bẩy chiến lược: Nhận diện những yếu tố có tác động mạnh nhất (Importance) đến hành vi khách hàng nhưng hiện đang có điểm hiệu suất thấp (Performance).
- Ra quyết định phân bổ ngân sách: Chuyển dịch ngân sách Marketing vào các biến số mang lại hệ số tác động (f²) cao nhất nhằm tối đa hóa ROI.
Ví dụ thực tế dựa trên IPMA: Nếu bản đồ chỉ ra rằng biến “Chất lượng chăm sóc khách hàng” có tầm quan trọng (Importance) rất lớn trong việc định hình “Lòng trung thành”, nhưng điểm hiệu suất thực tế (Performance) do khách hàng chấm lại đang nằm ở nhóm thấp nhất, CMO cần ngay lập tức ngưng đổ tiền rầm rộ vào việc chạy quảng cáo bề nổi. Thay vào đó, ngân sách phải được dồn toàn lực vào khâu đào tạo lại thái độ nhân viên và quy trình hậu mãi. Đây chính là giá trị thực tiễn (Actionable insights) vô giá mà công cụ này mang lại cho doanh nghiệp.
8. Các Câu Hỏi Thường Gặp (FAQ)
PLS-SEM có yêu cầu dữ liệu phải phân phối chuẩn (Normal Distribution) không?
Không. Một trong những ưu điểm lớn nhất của PLS-SEM là nó thuộc nhóm phương pháp phi tham số (non-parametric), do đó nó không yêu cầu dữ liệu phải tuân thủ nghiêm ngặt giả định phân phối chuẩn như kỹ thuật CB-SEM. Tuy nhiên, nhà nghiên cứu vẫn nên cẩn trọng kiểm tra độ xiên (skewness) và độ nhọn (kurtosis) bằng các phần mềm thống kê cơ bản, vì nếu dữ liệu gặp tình trạng quá bất thường (extreme non-normality), nó vẫn có thể ảnh hưởng phần nào đến kết quả kiểm định ý nghĩa thống kê thông qua Bootstrapping.
Cỡ mẫu tối thiểu để chạy PLS-SEM là bao nhiêu?
Theo Hair et al. (2017), quy tắc “10 lần” (10 times rule) thường được áp dụng. Cỡ mẫu tối thiểu nên bằng 10 lần số lượng mũi tên lớn nhất trỏ vào một biến tiềm ẩn nội sinh bất kỳ trong mô hình cấu trúc. Tuy nhiên, để đảm bảo độ chính xác thống kê (statistical power) ở mức chuyên nghiệp và hàn lâm nhất, nhà nghiên cứu nên sử dụng phần mềm GPower để tính toán cỡ mẫu cụ thể dựa trên mức ý nghĩa (alpha), sức mạnh kỳ vọng (Power = 0.80) và quy mô hiệu ứng (effect size). Phương pháp GPower luôn được các tạp chí uy tín đánh giá cao hơn hẳn quy tắc ngón tay cái truyền thống.
Tại sao chỉ số HTMT lại được ưu tiên hơn tiêu chuẩn Fornell-Larcker khi đánh giá độ giá trị phân biệt trong PLS-SEM?
Nghiên cứu hiện đại chứng minh tiêu chuẩn Fornell-Larcker kém nhạy bén trong việc phát hiện sự thiếu hụt độ giá trị phân biệt (đôi khi nó không thể phát hiện ra 2 biến thực chất là 1). HTMT (Tỷ lệ dị đặc tính – đồng đặc tính) cung cấp ước lượng chính xác hơn về mối tương quan thực sự giữa các biến, giúp loại bỏ triệt để hiện tượng đa cộng tuyến. Hơn thế nữa, HTMT được phát triển dựa trên các thuật toán mô phỏng Monte Carlo tiên tiến, do đó khi báo cáo chỉ số này, bạn nên trình bày kèm theo Khoảng tin cậy (Confidence Interval Bootstrapping) để chứng minh chỉ số hoàn toàn đáng tin cậy và không chứa giá trị 1.0.
9. Tài Liệu Tham Khảo (References)
Tài liệu nền tảng và nghiên cứu cốt lõi (Theo Chương 1 & Chương 4):
- Boudreau, M. C., Gefen, D., & Straub, D. W. (2001). Validation in information systems research: A state-of-the-art assessment. MIS Quarterly, 25, 1-16.
- Chin, W. W. (1998). The partial least squares approach to structural equation modeling. Trong cuốn G. A. Marcoulides (Chủ biên), Modern methods for business research (tr. 295-358). Mahwah, NJ: Erlbaum.
- Chin, W. W. (2010). How to write up and report PLS analyses. Trong cuốn V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Chủ biên), Handbook of partial least squares: Concepts, methods and applications in marketing and related fields (Tập II, tr. 655-690). Berlin: Springer.
- Dijkstra, T. K. (2014). PLS’ Janus face-response to Professor Rigdon’s “Rethinking partial least squares modeling: In praise of simple methods.” Long Range Planning, 47, 146-153.
- Do Valle, P. O., & Assaker, G. (in press). Using partial least squares structural equation modeling in tourism research: A review of past research and recommendations for future applications. Journal of Travel Research.
- Esposito Vinzi, V., Trinchera, L., & Amato, S. (2010). PLS path modeling: From foundations to recent developments and open issues for model assessment and improvement. Trong cuốn Handbook of partial least squares (tr. 47-82). New York: Springer.
- Gefen, D., Rigdon, E. E., & Straub, D. W. (2011). Editor’s comment: An update and extension to SEM guidelines for administrative and social science research. MIS Quarterly, 35, iii-xiv.
- Gefen, D., Straub, D. W., & Boudreau, M. C. (2000). Structural equation modeling techniques and regression: Guidelines for research practice. Communications of the AIS, 1, 1-78.
- Götz, O., Liehr-Gobbers, K., & Krafft, M. (2010). Evaluation of structural equation models using the partial least squares (PLS) approach. Trong cuốn Handbook of partial least squares (tr. 691-711). Berlin: Springer.
- Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2017). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (2nd ed.). SAGE Publications.
- Hair, J. F., Ringle, C. M., & Sarstedt, M. (2011). PLS-SEM: Indeed a silver bullet. Journal of Marketing Theory and Practice, 19, 139-151.
- Hair, J. F., Ringle, C. M., & Sarstedt, M. (2013). Partial least squares structural equation modeling: Rigorous applications, better results and higher acceptance. Long Range Planning, 46, 1-12.
- Hair, J. F., Sarstedt, M., Ringle, C. M., & Mena, J. A. (2012). An assessment of the use of partial least squares structural equation modeling in marketing research. Journal of the Academy of Marketing Science, 40, 414-433.
- Henseler, J., Dijkstra, T. K., Sarstedt, M., Ringle, C. M., Diamantopoulos, A., Straub, D. W., et al. (2014). Common beliefs and reality about partial least squares: Comments on Rönkkö & Evermann (2013). Organizational Research Methods, 17, 182-209.
- Henseler, J., Ringle, C. M., & Sarstedt, M. (2012). Using partial least squares path modeling in international advertising research: Basic concepts and recent issues. Trong cuốn Handbook of research in international advertising (tr. 252-276). Cheltenham, UK: Edward Elgar.
- Henseler, J., Ringle, C. M., & Sarstedt, M. (2015). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43, 115-135.
- Henseler, J., Ringle, C. M., & Sinkovics, R. R. (2009). The use of partial least squares path modeling in international marketing. Advances in International Marketing, 20, 277-320.
- Jöreskog, K. G., & Wold, H. (1982). The ML and PLS techniques for modeling with latent variables: Historical and comparative aspects. Trong cuốn Systems under indirect observation (tr. 263-270). Amsterdam: North-Holland.
- Lohmöller, J. B. (1989). Latent variable path modeling with partial least squares. Heidelberg, Germany: Physica.
- Marcoulides, G. A., & Chin, W. W. (2013). You write but others read: Common methodological misunderstandings in PLS and related methods. Trong cuốn New perspectives in partial least squares and related methods (tr. 31-64). New York: Springer.
- Mateos-Aparicio, G. (2011). Partial least squares (PLS) methods: Origins, evolution, and application to social sciences. Communications in Statistics: Theory and Methods, 40, 2305-2317.
- Rigdon, E. E. (2012). Rethinking partial least squares path modeling: In praise of simple methods. Long Range Planning, 45, 341-358.
- Ringle, C. M., Sarstedt, M., & Straub, D. W. (2012). A critical look at the use of PLS-SEM in MIS Quarterly. MIS Quarterly, 36, iii-xiv.
- Roldán, J. L., & Sánchez-Franco, M. J. (2012). Variance-based structural equation modeling: Guidelines for using partial least squares in information systems research. Trong cuốn Research methodologies, innovations and philosophies in software systems engineering (tr. 193-221). Hershey, PA: IGI Global.
- Straub, D., Boudreau, M. C., & Gefen, D. (2004). Validation guidelines for IS positivist research. Communications of the Association for Information Systems, 13, 380-427.
- Tenenhaus, M., Esposito Vinzi, V., Chatelin, Y. M., & Lauro, C. (2005). PLS path modeling. Computational Statistics & Data Analysis, 48, 159-205.
- Voorhees, C. M., Brady, M. K., Calantone, R., & Ramirez, E. (2016). Discriminant validity testing in marketing: An analysis, causes for concern, and proposed remedies. Journal of the Academy of Marketing Science, 44, 119-134.
10. Lời kêu gọi hành động (CTA)
Để áp dụng chuẩn xác lý thuyết từ tài liệu học thuật kinh điển này vào bài báo cáo khoa học hoặc khóa luận của bạn, việc nắm vững các thao tác trên phần mềm SmartPLS 3 và diễn giải số liệu chuẩn khoa học là điều kiện tiên quyết. Khám phá chi tiết phương pháp luận, các bước thiết lập mô hình toàn diện và những quy tắc đánh giá (rules of thumb) ngay trong tài liệu học thuật chuyên sâu dưới đây.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2017). A primer on partial least squares structural equation modeling (PLS-SEM) (2nd ed.). SAGE Publications.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



