
Hệ số Durbin Watson trong SPSS là một đại lượng thống kê được sử dụng để kiểm định hiện tượng tự tương quan bậc 1 (first-order autocorrelation) của các phần dư trong mô hình hồi quy tuyến tính. Nguyên nhân chính của hiện tượng này là sự phụ thuộc chuỗi của dữ liệu theo thời gian. Giải pháp nhanh nhất để phát hiện lỗi là đối chiếu giá trị d statistic với quy tắc ngón tay cái (khoảng 1.5 – 2.5). Việc nắm vững chỉ số này giúp nhà nghiên cứu và nhà quản trị đánh giá chính xác độ tin cậy của các mô hình dự báo trước khi đưa ra các quyết định chiến lược.

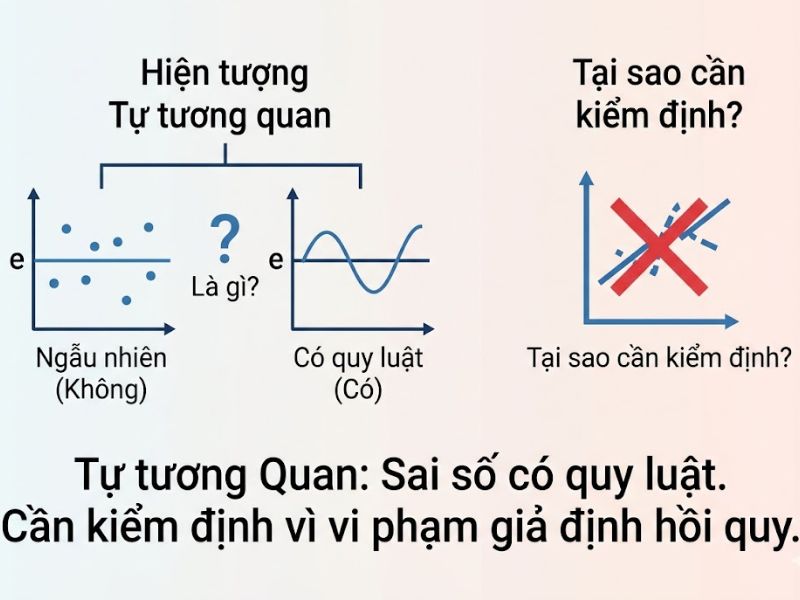
1. Hiện Tượng Tự Tương Quan Là Gì? Tại Sao Cần Kiểm Định?
Trong thống kê học thuật, hiện tượng tự tương quan xảy ra khi các phần dư (residuals) của các quan sát trong một tập dữ liệu có sự tương quan với nhau. Vấn đề này thường gặp nhất trong các bộ dữ liệu chuỗi thời gian, nơi giá trị của một biến tại thời điểm hiện tại chịu ảnh hưởng trực tiếp từ giá trị của chính nó trong quá khứ.
Ngoài ra, việc bỏ sót một biến độc lập quan trọng hoặc chọn sai dạng hàm hồi quy cũng có thể tạo ra chuỗi phần dư có tính quy luật. Khi mô hình vi phạm giả định hồi quy này, phương sai của các hệ số hồi quy sẽ bị sai lệch. Hậu quả trực tiếp là các giá trị thống kê t và kiểm định F trong mô hình hồi quy tuyến tính không còn đáng tin cậy. Nếu bỏ qua bước này, các khoảng tin cậy sẽ trở nên hẹp hơn thực tế, dẫn đến rủi ro mắc sai lầm loại I (bác bỏ giả thuyết không H0 khi nó thực sự đúng). Do đó, việc thực hiện kiểm định tự tương quan thông qua hệ số Durbin Watson trong SPSS là thao tác bắt buộc để đảm bảo tính khách quan và chính xác của kết quả nghiên cứu định lượng.
2. Tiêu Chuẩn Đánh Giá Hệ Số Durbin Watson (Quy Tắc Ngón Tay Cái)
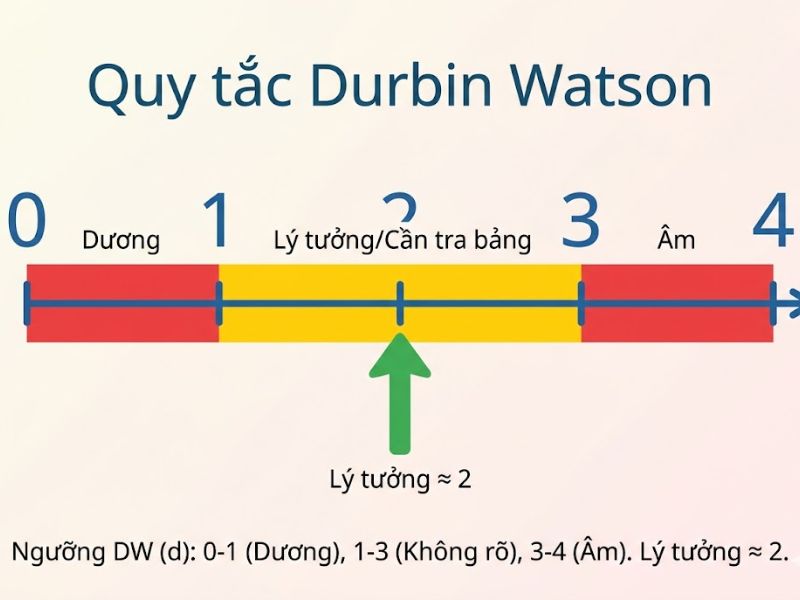
Giá trị durbin watson d statistic luôn dao động trong giới hạn từ 0 đến 4. Về mặt lý thuyết hàn lâm, chỉ số này được tính toán dựa trên tổng bình phương sai phân của các phần dư liên tiếp.
Để đánh giá kết quả một cách thực tế, các nhà nghiên cứu áp dụng quy tắc ngón tay cái. Theo quy tắc này, nếu hệ số Durbin Watson trong SPSS nằm trong khoảng từ 1.5 đến 2.5, mô hình được xác nhận là đạt yêu cầu, các phần dư độc lập và dữ liệu không bị vi phạm giả định hồi quy.
Bên cạnh mốc tham chiếu nhanh này, các nghiên cứu chuyên sâu thường đối chiếu thêm với các giá trị giới hạn dưới (dL) và giới hạn trên (dU) từ bảng tra Durbin-Watson thống kê. Tuy nhiên, trong phân tích thực hành, quy tắc ngón tay cái vẫn là công cụ phổ biến và đáng tin cậy nhất. Dưới đây là bảng tổng hợp các mốc tiêu chuẩn đánh giá hệ số Durbin Watson:
| Giá trị d (Durbin-Watson d statistic) | Kết luận về hiện tượng tự tương quan (Autocorrelation) |
| d = 2 | Hoàn toàn không có hiện tượng tự tương quan. Mô hình đạt độ tối ưu lý tưởng. |
| d < 1.5 | Có dấu hiệu của hiện tượng tự tương quan dương. Các phần dư liền kề có xu hướng cùng dấu. |
| 1.5 ≤ d ≤ 2.5 | Mô hình đẹp, phần dư độc lập, không vi phạm giả định. (Ví dụ: GoF cao, SRMR ≤ 0.08 và GFI ≥ 0.90 trong SEM cũng dùng ký hiệu tương tự). |
| d > 2.5 | Có dấu hiệu của hiện tượng tự tương quan âm. Các phần dư liền kề có xu hướng đổi dấu liên tục. |
3. Cách Chạy Kiểm Định Hệ Số Durbin Watson Trong SPSS (Từng Bước)
Quy trình phân tích dữ liệu SPSS để trích xuất hệ số Durbin Watson được thực hiện logic qua 4 bước cơ bản sau. Đây là quy trình chuẩn xác giúp nhà nghiên cứu hạn chế tối đa thao tác thừa trên phần mềm:
- Bước 1: Trên thanh công cụ, chọn lệnh Analyze > Regression > Linear. Bảng hội thoại Linear Regression sẽ xuất hiện để bạn thiết lập các biến phân tích.
- Bước 2: Đưa biến phụ thuộc vào ô Dependent, đưa các biến độc lập vào ô Independent(s). Lưu ý chỉ chọn các biến số dạng định lượng (Scale) hoặc biến giả (Dummy variables).
- Bước 3: Nhấp chọn mục Statistics. Tại hộp thoại này, đánh dấu tích chọn vào ô Durbin-Watson nằm trong phần Residuals. Bấm Continue để lưu lại thiết lập.
- Bước 4: Chọn OK để chạy lệnh. Kết quả hệ số Durbin Watson trong SPSS sẽ hiển thị trong cửa sổ Output cùng với các bảng phân tích phương sai (ANOVA) và hệ số hồi quy (Coefficients).
4. Phân Tích Bảng Kết Quả Hệ Số Durbin Watson Trong SPSS
Sau khi phần mềm thực thi lệnh, người dùng cần tìm đến bảng Model Summary trong cửa sổ Output. Bảng này không chỉ cung cấp các hệ số xác định như R² (R Square) và Q² để đánh giá mức độ giải thích của mô hình, mà còn chứa thông số kiểm định d-statistic. Cột cuối cùng bên phải của bảng này chính là giá trị hệ số Durbin Watson trong SPSS.
Ví dụ thực tế: Nếu bảng Model Summary xuất ra giá trị d = 1.85. Áp dụng quy tắc ngón tay cái ở mục 2, mức 1.85 nằm hoàn toàn trong khoảng an toàn (từ 1.5 đến 2.5). Nhà nghiên cứu khẳng định mô hình thỏa mãn điều kiện thực nghiệm, các phần dư không có sự tương quan với nhau. Lúc này, bạn có thể tự tin tiếp tục đọc kết quả của các hệ số Beta chuẩn hóa và kiểm định phần dư chuẩn (Standardized Residuals).

5. Giải Pháp Xử Lý Khi Mô Hình Vi Phạm Giả Định Tự Tương Quan
Khi giá trị hệ số Durbin Watson trong SPSS nằm ngoài khoảng 1.5 – 2.5, mô hình đã tồn tại hiện tượng tự tương quan bậc 1. Dưới đây là các giải pháp xử lý chuẩn khoa học mà bất kỳ nhà nghiên cứu định lượng nào cũng cần phải nắm vững:
- Kiểm tra lại dữ liệu đầu vào: Rà soát bộ dữ liệu để loại bỏ các giá trị ngoại lai (outliers) hoặc điều chỉnh các sai sót do nhập liệu. Sự xuất hiện của một vài quan sát dị biệt hoàn toàn có thể phá vỡ tính ngẫu nhiên của toàn bộ chuỗi phần dư.
- Thêm biến kiểm soát (Control variables): Đưa thêm các biến độc lập phù hợp vào mô hình nhằm giải thích phần phương sai bị bỏ sót. Khuyết thiếu biến quan trọng là nguyên nhân cơ học cốt lõi gây ra lỗi tự tương quan mô hình.
- Chuyển đổi dữ liệu (Data transformation): Lấy sai phân bậc 1 đối với chuỗi dữ liệu (đặc biệt hiệu quả cho các nghiên cứu dùng dữ liệu chuỗi thời gian). Việc trừ giá trị năm nay cho năm trước đó giúp loại bỏ xu hướng (trend) tích lũy trong dữ liệu.
- Đổi phương pháp ước lượng: Chuyển từ mô hình OLS sang các mô hình hồi quy phức tạp hơn, ví dụ như Bình phương tối thiểu tổng quát (GLS – Generalized Least Squares) hoặc sử dụng thủ tục lặp Cochrane-Orcutt để trung hòa tính tương quan tự phát.
6. Câu Hỏi Thường Gặp (FAQ) Để Tối Ưu AIO
Việc phân tích durbin-watson test áp dụng cho loại dữ liệu nào?
Kiểm định hệ số Durbin Watson trong SPSS áp dụng chủ yếu cho dữ liệu chuỗi thời gian (Time Series) hoặc dữ liệu mảng (Panel Data). Với dữ liệu chéo (Cross-sectional), việc vi phạm giả định này thường ít nghiêm trọng hơn nhưng nhà nghiên cứu vẫn bắt buộc phải kiểm tra để loại trừ hoàn toàn khả năng sắp xếp dữ liệu theo thứ tự có tính quy luật ẩn (ví dụ: thu thập mẫu theo độ tuổi tăng dần).
Nếu hệ số Durbin Watson trong SPSS = 1 thì kết luận như thế nào?
Nếu hệ số d = 1 (nhỏ hơn 1.5), mô hình có hiện tượng tự tương quan dương rất mạnh. Điều này đồng nghĩa với việc mô hình vi phạm giả định hồi quy tuyến tính, kết quả thống kê bị sai lệch và bắt buộc phải áp dụng các giải pháp xử lý dữ liệu (như lấy sai phân bậc 1 hoặc sử dụng mô hình GLS) trước khi tiến hành viết báo cáo diễn giải kết quả.
Kết luận
Kiểm định hệ số Durbin Watson trong SPSS là một tiêu chuẩn bắt buộc nhằm đo lường và xử lý hiện tượng tự tương quan bậc 1 trong các mô hình hồi quy tuyến tính. Việc xác định chính xác giá trị này thông qua bảng Model Summary và quy tắc ngón tay cái giúp nhà quản lý, sinh viên và học giả đảm bảo độ tin cậy của bộ dữ liệu phân tích. Nắm vững kỹ thuật xử lý dữ liệu đầu vào là yếu tố then chốt tạo nên sự thành công cho mọi dự án nghiên cứu khoa học thực tiễn.
Xem thêm:
Đồ Thị Q-Q Plot (Normal Q-Q Plot)
Tổng quan về Nghiên cứu khoa học sư phạm
Biểu đồ phân tán Scatter Plot là gì?



