
Vấn đề xử lý dữ liệu liên tục cho kiểm định phương sai đòi hỏi việc chuyển đổi dữ liệu. Nguyên nhân chính là do phân tích ANOVA yêu cầu biến độc lập bắt buộc phải ở dạng biến phân loại (categorical). Giải pháp nhanh nhất là áp dụng cách gộp biến định lượng thành biến định tính trong SPSS thông qua hai lệnh cốt lõi: Recode into Different Variables hoặc Visual Binning.

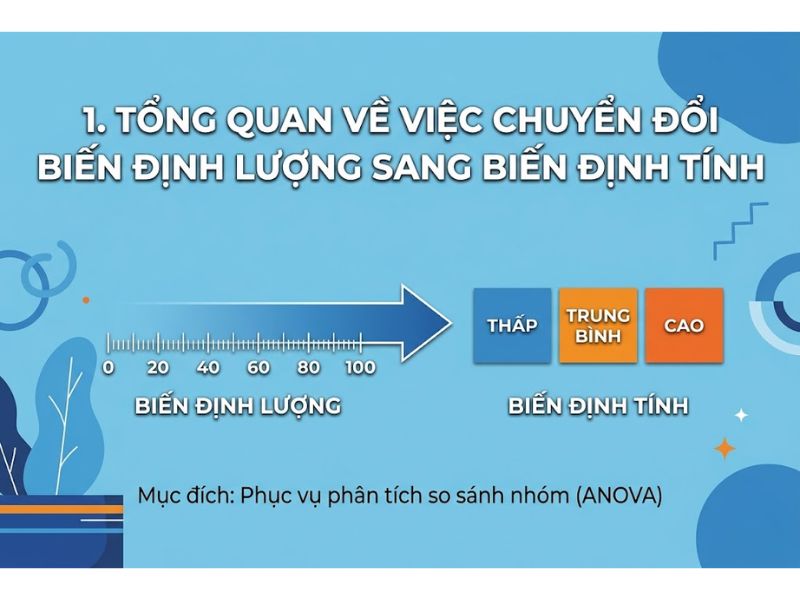
1. Tổng Quan Về Việc Chuyển Đổi Biến Định Lượng Sang Biến Định Tính
1.1. Bản chất của việc phân nhóm dữ liệu (Data Binning/Grouping)
Việc phân nhóm dữ liệu là quá trình chuyển đổi một biến có thang đo định lượng (Scale), chẳng hạn như độ tuổi, thu nhập, hoặc điểm số liên tục, thành một biến có thang đo định tính phân loại (Ordinal hoặc Nominal). Quá trình này giúp gom các giá trị đơn lẻ thành các khoảng (ranges) hoặc nhóm (categories) có ý nghĩa thống kê, giúp nhà nghiên cứu dễ dàng quan sát các đặc tính của từng nhóm đối tượng cụ thể.
Dưới góc độ thống kê học thuật, thao tác này có tác dụng nén thông tin liên tục thành các mảng rời rạc, làm giảm sự tác động của các nhiễu loạn ngẫu nhiên (random noise) và các giá trị ngoại lai (outliers) trong tập dữ liệu thô. Qua đó, nhà quản trị và nhà phân tích có thể tập trung vào việc so sánh đặc tính vĩ mô giữa các phân khúc cụ thể thay vì bị phân tán bởi từng điểm dữ liệu vi mô.
1.2. Yêu cầu dữ liệu đầu vào của phân tích phương sai (ANOVA)
Phân tích phương sai (ANOVA – Analysis of Variance) được sử dụng để kiểm định sự khác biệt về giá trị trung bình của một biến phụ thuộc (định lượng) giữa các nhóm độc lập. Do đó, giả định tiên quyết của mô hình này là biến độc lập (Independent Variable/Factor) phải là biến định tính (Categorical Variable) có từ hai nhóm trở lên.
Nếu nhà nghiên cứu thu thập dữ liệu biến độc lập ở dạng liên tục (ví dụ: tuổi chính xác của từng đáp viên), bắt buộc phải thực hiện cách gộp biến định lượng thành biến định tính trong SPSS trước khi đưa vào mô hình phân tích One-Way ANOVA. Việc cố tình đưa biến liên tục vào ô Factor trong ANOVA sẽ dẫn đến sai lệch thuật toán, khiến phần mềm không thể tính toán chính xác tổng bình phương giữa các nhóm (Between-Groups Sum of Squares) và làm mất đi ý nghĩa của trị số F (F-statistic).
2. Kỹ Thuật Chuyển Đổi Bằng Lệnh Recode Into Different Variables
2.1. Nguyên lý hoạt động của lệnh Recode
Lệnh Recode Into Different Variables cho phép nhà nghiên cứu thiết lập các điều kiện giá trị cũ (Old Values) và gán cho chúng các giá trị mã hóa mới (New Values) trên một biến hoàn toàn mới. Phương pháp này bảo toàn nguyên vẹn biến gốc ban đầu, tránh sai lệch mất mát dữ liệu thô, đồng thời cung cấp sự kiểm soát thủ công tuyệt đối đối với các khoảng giá trị phân nhóm.
Nguyên lý cốt lõi của lệnh này dựa trên mệnh đề logic có điều kiện (If-Then logic). Nhà nghiên cứu bắt buộc phải dựa vào cơ sở lý thuyết (Literature Review) hoặc các chuẩn mực phân loại của ngành (ví dụ: thang đo thế hệ Gen Z, Millennial) để xác định chính xác các điểm giới hạn (cut-off points) trước khi thực hiện thiết lập trên phần mềm.
2.2. Quy trình thực hiện Recode Into Different Variables chi tiết
Để thực hiện cách gộp biến định lượng thành biến định tính trong SPSS bằng lệnh Recode, hãy tuân thủ các bước sau:
- Trêm thanh menu chính, chọn Transform > Recode into Different Variables. Đây là bước kích hoạt cửa sổ mã hóa biến độc lập.
- Đưa biến định lượng cần gộp (ví dụ: Tuoi_LienTuc) từ cột bên trái vào ô Numeric Variable -> Output Variable.
- Tại mục Output Variable, nhập tên biến mới vào ô Name (ví dụ: Nhom_Tuoi) và dán nhãn giải thích vào ô Label, sau đó nhấn nút Change. Bước này xác nhận việc khởi tạo một biến mới hoàn toàn, giữ an toàn cho dữ liệu gốc.
- Nhấn chọn nút Old and New Values… để mở hộp thoại cấu hình chi tiết các dải dữ liệu.
- Tại cột Old Value, chọn Range và nhập khoảng giá trị cần gộp (ví dụ: Range từ 18 đến 25). Chức năng Range đảm bảo hệ thống quét toàn bộ các quan sát nằm trong khoảng giới hạn này.
- Tại cột New Value, nhập mã số đại diện cho nhóm đó vào ô Value (ví dụ: 1). Khuyến nghị nên sử dụng số nguyên dương.
- Nhấn Add để đưa điều kiện vào danh sách Old –> New. Lặp lại bước 5-7 cho các nhóm còn lại một cách tuần tự và logic, đảm bảo không có khoảng trống (gaps) hoặc sự chồng chéo (overlaps) giữa các nhóm.
- Nhấn Continue và cuối cùng chọn OK để phần mềm thực thi lệnh. Nhớ vào phần Variable View để khai báo Values (1 = 18-25 tuổi, 2 = 26-35 tuổi…) cho biến mới, phục vụ cho việc đọc kết quả đầu ra (Output) sau này.
3. Kỹ Thuật Phân Nhóm Tự Động Bằng Lệnh Visual Binning
3.1. Chức năng và ứng dụng của Visual Binning
Visual Binning là công cụ tối ưu khi nhà nghiên cứu cần phân nhóm một biến định lượng có độ phân tán cao. Lệnh này cung cấp biểu đồ phân phối tần suất trực quan (histogram), hỗ trợ tự động tính toán và tạo ra các điểm cắt (Cutpoints) dựa trên tỷ lệ phần trăm đều nhau (Equal Percentiles) hoặc độ rộng khoảng cách đều nhau (Equal Width), giảm thiểu yếu tố chủ quan của người phân tích.
Đặc biệt trong các nghiên cứu thực nghiệm không có sẵn tiêu chuẩn phân nhóm từ trước, Visual Binning đóng vai trò như một phương pháp khám phá dữ liệu (Exploratory Data Analysis). Nó giúp nhận diện cấu trúc tiềm ẩn của dữ liệu liên tục và đề xuất các nhóm sao cho đảm bảo tính đại diện thống kê cao nhất.
3.2. Các bước thiết lập Cutpoints và tạo dải phân nhóm (Bins)
Thực hiện cách gộp biến định lượng thành biến định tính trong SPSS theo quy trình tự động hóa như sau:
- Chọn Transform > Visual Binning.
- Đưa biến định lượng cần xử lý vào ô Variables to Bin và nhấn Continue.
- Tại hộp thoại Visual Binning, đặt tên cho biến định tính mới tại ô Binned Variable. Bước này bắt buộc phải thực hiện trước khi có thể chỉnh sửa các thông số khác.
- Nhấn nút Make Cutpoints… để tự động thiết lập điểm cắt dựa trên thuật toán tích hợp sẵn của SPSS.
- Chọn tiêu chí phân nhóm:
- Equal Width intervals: Chia các nhóm có độ lớn bằng nhau. Phù hợp khi phân phối dữ liệu gốc là phân phối chuẩn (Normal Distribution).
- Equal Percentiles Based on Scanned Cases: Chia các nhóm sao cho số lượng quan sát (N) trong mỗi nhóm xấp xỉ bằng nhau. Đây là lựa chọn lý tưởng cho các dữ liệu bị lệch (Skewed Data), đảm bảo các nhóm đều có cỡ mẫu đủ lớn để chạy kiểm định.
- Nhập số lượng điểm cắt (Number of cutpoints) – lưu ý số điểm cắt luôn nhỏ hơn số nhóm mong muốn 1 đơn vị. Nhấn Apply.
- Nhấn Make Labels để SPSS tự động tạo nhãn dán cho các khoảng giá trị. Cuối cùng, nhấn OK để hoàn tất. Các nhãn tự động này sẽ hiển thị trực tiếp dải số liệu một cách chi tiết (ví dụ: “<= 25.00”).

4. Khi Nào Nên Sử Dụng Recode Hay Visual Binning?
Bảng dưới đây cung cấp cơ sở để nhà nghiên cứu lựa chọn công cụ phù hợp với tập dữ liệu, đảm bảo tính chặt chẽ trong luận giải phương pháp luận nghiên cứu:
| Tiêu chí phân tích | Lệnh Recode into Different Variables | Lệnh Visual Binning |
| Mức độ kiểm soát | Kiểm soát thủ công tuyệt đối từng khoảng giá trị, không phụ thuộc vào phân phối dữ liệu. | Tự động hóa dựa trên thuật toán và phân phối dữ liệu thực tế thu thập được. |
| Tính trực quan | Không hỗ trợ biểu đồ tần suất khi thiết lập thao tác. | Hiển thị biểu đồ phân phối Histogram trực tiếp giúp dễ dàng nhận diện cấu trúc mẫu. |
| Trường hợp khuyên dùng | Khi khoảng phân nhóm đã được xác định trước bởi cơ sở lý thuyết (ví dụ: phân loại độ tuổi theo chuẩn WHO). | Khi cần chia tập dữ liệu thành các nhóm có số lượng mẫu (N) bằng nhau để đảm bảo cỡ mẫu cho mô hình ANOVA. |
| Gắn nhãn (Labeling) | Phải thao tác gán nhãn thủ công tại giao diện Variable View. | Có nút Make Labels tự động gán nhãn nhanh chóng và chính xác. |
| Xử lý dữ liệu khuyết | Phải cấu hình riêng biệt cho các biến System-missing để tránh sai lệch. | Thuật toán quét và tách biệt giá trị Missing ngay từ bước dựng biểu đồ. |
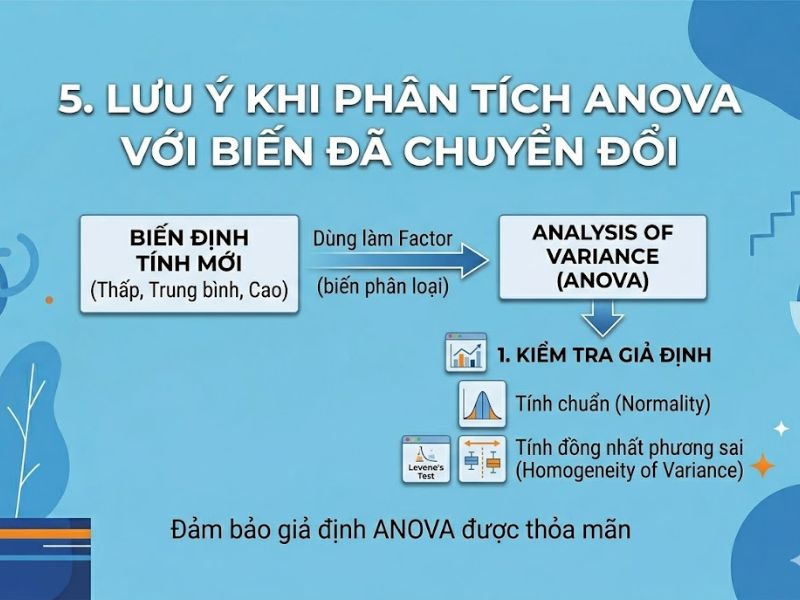
5. Ứng Dụng Biến Phân Nhóm Mới Vào Phân Tích ANOVA
Sau khi hoàn thiện cách gộp biến định lượng thành biến định tính trong SPSS, biến mới (ví dụ: Nhom_Tuoi) giờ đây đã mang thang đo Ordinal/Nominal, hoàn toàn đáp ứng giả định của phương sai. Để chạy kiểm định One-Way ANOVA:
- Vào Analyze > Compare Means > One-Way ANOVA.
- Đưa biến phụ thuộc (Scale) vào ô Dependent List. Đây là biến kết quả chịu tác động.
- Đưa biến định tính vừa gộp được vào ô Factor. Đây chính là căn cứ để SPSS chia nhóm dữ liệu và so sánh các trung bình mẫu.
- Thiết lập các tùy chọn Post Hoc và Options (Descriptive, Homogeneity of variance test) để hoàn thành phân tích. Việc kiểm tra tính đồng nhất của phương sai là bắt buộc trước khi kết luận trị số Sig. của bảng ANOVA.
6. Tổng Kết Khuyến Nghị Đối Với Nhà Nghiên Cứu
Việc chuyển đổi biến số không đơn thuần là kỹ thuật phần mềm mà phải phục vụ chặt chẽ cho lý thuyết thống kê. Khi phân nhóm dữ liệu, nhà nghiên cứu cần đảm bảo mỗi nhóm được tạo ra phải có đủ số lượng quan sát (thường n > 30) để đảm bảo độ tin cậy của kiểm định phân phối chuẩn và tính đồng nhất phương sai (Levene’s Test) trong ANOVA. Tránh việc chia quá nhiều nhóm nhỏ lẻ làm loãng dữ liệu và giảm bậc tự do (degree of freedom) của mô hình.
Đặc biệt, trong các hướng nghiên cứu kết hợp mở rộng hoặc mô hình phương trình cấu trúc phức tạp sau này, việc xử lý dữ liệu và cấu trúc lại thang đo đầu vào từ các biến định lượng cũng đóng vai trò quyết định giúp cải thiện các chỉ số đo lường. Sự đồng nhất và chính xác trong khâu làm sạch biến sẽ góp phần trực tiếp giúp mô hình đạt được các giá trị kiểm định tối ưu (ví dụ: R², GoF và Q² hoặc các chỉ số đánh giá độ phù hợp tổng thể như SRMR ≤ 0.08 và GFI ≥ 0.90).
7. Câu Hỏi Thường Gặp (FAQ) Về Quá Trình Gộp Biến Trong SPSS
Có nên dùng lệnh Recode into Same Variables không?
Không. Recode into Same Variables sẽ ghi đè dữ liệu mới lên biến gốc, làm mất hoàn toàn dữ liệu thô ban đầu định lượng. Phải luôn sử dụng Recode into Different Variables để bảo toàn dữ liệu gốc, phục vụ cho quá trình đối chiếu hoặc chạy các kiểm định hồi quy khác yêu cầu biến độc lập ở dạng liên tục.
Xử lý Missing Values khi gộp biến như thế nào?
Trong hộp thoại Old and New Values, luôn tạo một quy tắc riêng cho giá trị khuyết: Đặt System-missing ở mục Old Value thành System-missing ở mục New Value, tránh việc SPSS tự động đẩy các giá trị khuyết vào các nhóm phân loại một cách sai lệch. Nếu bỏ qua bước này, hệ thống có thể gom các dữ liệu trống vào các nhóm giới hạn dưới, làm méo mó nghiêm trọng trung bình mẫu của nhóm đó.
Số lượng nhóm (bins) bao nhiêu là phù hợp cho phân tích ANOVA?
Thông thường, số lượng nhóm phân loại lý tưởng trong One-Way ANOVA nằm từ 3 đến 5 nhóm. Nếu ít hơn 3 nhóm (tức 2 nhóm), bạn nên sử dụng Independent Samples T-Test. Nếu chia quá 5 nhóm, kết quả hậu kiểm (Post Hoc) sẽ phức tạp và làm giảm power của kiểm định thống kê, dẫn đến việc khó rút ra được một khuyến nghị quản trị thực tế do ranh giới giữa các nhóm quá mờ nhạt.Kết luận: Quá trình chuyển hóa dữ liệu là nền tảng cốt lõi trong thống kê định lượng. Việc nắm vững kỹ thuật và lý luận thống kê đằng sau quy trình này giúp nhà nghiên cứu loại bỏ sai sót phương pháp luận trước khi đưa dữ liệu vào các mô hình phức tạp. Nền tảng tư duy xử lý dữ liệu chuẩn xác là một phần quan trọng của công tác nghiên cứu khoa học, giúp đảm bảo tính hợp lệ, độ tin cậy và giá trị thực tiễn của công trình công bố.



