
Khó khăn lớn nhất trong việc phân tích phân phối dữ liệu là thiếu công cụ trực quan hóa độ phân tán một cách chính xác và triệt để. Biểu đồ hộp (Boxplot) là phương pháp biểu diễn đồ họa cấu trúc dữ liệu số lượng thông qua 5 giá trị tóm tắt cốt lõi. Nguyên nhân chính gây nhiễu các mô hình thống kê và làm sai lệch kết quả kiểm định là sự xuất hiện của các điểm dị biệt (outliers). Giải pháp nhanh nhất để xử lý vấn đề này là nắm vững cách đọc biểu đồ Boxplot, từ đó xác định rõ khoảng tứ phân vị (IQR), trung vị (median) và phát hiện độ lệch (skewness) của tập dữ liệu trước khi đưa vào mô hình phân tích chuyên sâu.

1. Biểu Đồ Hộp (Boxplot) Là Gì?
Biểu đồ hộp (tiếng Anh: Box-and-Whisker Plot) là một kỹ thuật trực quan hóa dữ liệu nền tảng trong thống kê mô tả, được nhà toán học John Tukey giới thiệu lần đầu vào năm 1969. Nó cung cấp cái nhìn tổng quan, chi tiết về đặc tính phân bố của một tập quan sát dựa trên quy tắc tóm tắt 5 số (Five-number summary) bao gồm:
- Giá trị nhỏ nhất (Minimum): Quan sát thấp nhất trong tập dữ liệu (không bao gồm điểm dị biệt).
- Tứ phân vị thứ nhất (Q1): Điểm phân vị thứ 25, đại diện cho 25% dữ liệu có giá trị thấp nhất.
- Trung vị (Median – Q2): Điểm phân vị thứ 50, chia tập dữ liệu thành hai nửa hoàn toàn bằng nhau.
- Tứ phân vị thứ ba (Q3): Điểm phân vị thứ 75, đại diện cho 75% dữ liệu có giá trị thấp nhất.
- Giá trị lớn nhất (Maximum): Quan sát cao nhất trong tập dữ liệu (không bao gồm điểm dị biệt).
So với các biểu đồ dạng cột (Histogram) truyền thống thường bị phụ thuộc vào số lượng cột (bins) và kích thước mẫu, biểu đồ hộp vượt trội hơn trong việc so sánh trực quan nhiều nhóm biến số cùng lúc. Biểu đồ này minh họa rõ ràng các giá trị bất thường mà không bị ảnh hưởng bởi giả định phân phối chuẩn. Mục tiêu cốt lõi của công cụ này là đánh giá mức độ hội tụ, độ phân tán thực tế và cung cấp bằng chứng toán học vững chắc để phát hiện điểm dị biệt (outliers) nhằm thanh lọc dữ liệu.
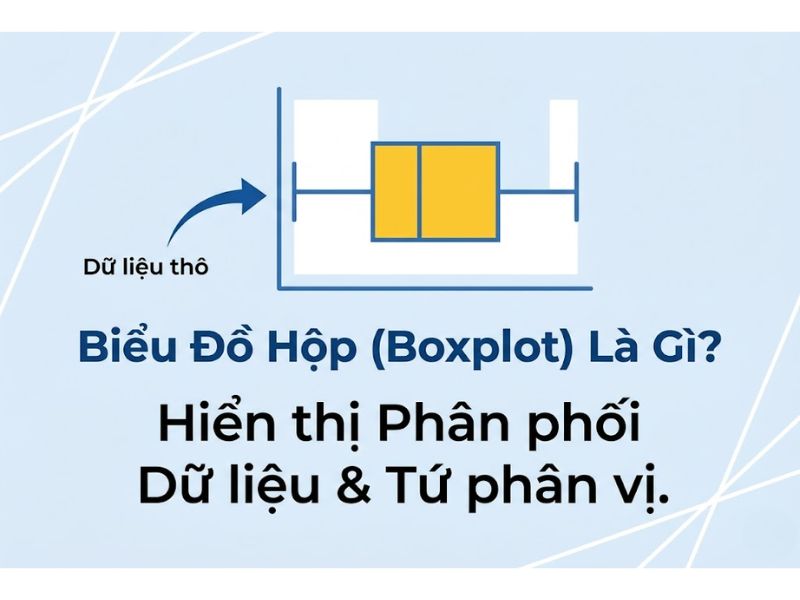
2. Cấu Trúc Và Các Thành Phần Cơ Bản Của Biểu Đồ Boxplot
Để thực hiện đúng cách đọc biểu đồ Boxplot, nhà nghiên cứu cần bóc tách, định hình và phân tích độc lập từng thành phần cấu tạo nên biểu đồ. Bảng dưới đây tổng hợp chi tiết ý nghĩa thống kê và cách diễn giải của từng bộ phận:
| Thành phần đồ họa | Ký hiệu thống kê | Ý nghĩa và Chức năng cốt lõi | Cách diễn giải thực tế |
| Hộp (Box) | IQR (Q3 – Q1) | Chứa 50% dữ liệu trung tâm. Phản ánh độ phân tán nội bộ cốt lõi của mẫu quan sát. | Hộp càng dài, độ biến thiên của 50% dữ liệu cốt lõi càng lớn, cho thấy sự thiếu đồng nhất. |
| Đường chẻ giữa hộp | Median (Q2) | Đại diện cho xu hướng trung tâm. Chia tập dữ liệu thành hai nửa bằng nhau (50% lớn hơn, 50% nhỏ hơn). | Định vị trọng tâm dữ liệu. Vị trí của đường này so với hai đầu hộp quyết định độ lệch của phân phối. |
| Râu (Whiskers) | Râu trên / Râu dưới | Thể hiện giới hạn phân tán tự nhiên của dữ liệu (không bao gồm điểm dị biệt). | Chỉ ra khoảng giới hạn an toàn. Bất kỳ dữ liệu nào nằm trong dải này đều được xem là bình thường. |
| Dấu chấm/sao | Outliers | Xác định các điểm dị biệt có giá trị vượt ra ngoài giới hạn tính toán lý thuyết của tập dữ liệu. | Các điểm dị biệt cần được xem xét riêng biệt để quyết định loại bỏ hay giữ lại nhằm tìm ra nguyên nhân gốc rễ. |
2.1. Hộp (Box) Và Khoảng Tứ Phân Vị (IQR)
Khối hộp hình chữ nhật trung tâm bao hàm chính xác 50% số lượng quan sát cốt lõi của tập dữ liệu. Cạnh dưới của hộp (box) đại diện cho tứ phân vị thứ nhất (Q1), trong khi cạnh trên biểu thị tứ phân vị thứ ba (Q3).
Hiệu số giữa Q3 và Q1 được gọi là khoảng tứ phân vị (Interquartile Range – IQR). Công thức tính toán: IQR = Q3 – Q1. Khác với phương sai hay độ lệch chuẩn dễ bị nhiễu bởi các giá trị cực đoan, IQR là một thước đo đo lường độ phân tán cực kỳ bền vững (robust). Chiều cao của hộp càng lớn, dữ liệu ở vùng trung tâm càng có độ phân tán cao, chứng tỏ tập quan sát thiếu tính tập trung.
2.2. Đường Trung Vị (Median)
Đường trung vị (median) là vạch kẻ ngang nằm bên trong hộp. Nó xác định trọng tâm thực tế của phân phối dữ liệu thay vì sử dụng giá trị trung bình (Mean). Vị trí của trung vị so với Q1 và Q3 là cơ sở quan trọng nhất để xác định tính đối xứng của mẫu. Nếu trung vị không nằm ở chính giữa hộp, tập dữ liệu chắc chắn bị lệch.
2.3. Râu (Whiskers)
Râu (whiskers) là hai đường thẳng kéo dài từ hai cạnh của hộp đến các giá trị quan sát xa nhất, nhưng vẫn bắt buộc phải nằm trong giới hạn thống kê an toàn được định trước. Theo quy chuẩn chặt chẽ của hệ thống Tukey:
- Râu dưới kết thúc tại giá trị quan sát nhỏ nhất lớn hơn hoặc bằng Q1 – 1.5 * IQR.
- Râu trên kết thúc tại giá trị quan sát lớn nhất nhỏ hơn hoặc bằng Q3 + 1.5 * IQR.
Khoảng cách 1.5 lần IQR được chứng minh toán học là tương đương với khoảng 3 độ lệch chuẩn (3 sigma) trong một phân phối chuẩn hoàn hảo, đảm bảo tính bao quát 99.7% dữ liệu hợp lệ.
2.4. Dấu Chấm Tròn (Outliers – Điểm Dị Biệt)
Bất kỳ điểm dữ liệu nào nằm ngoài giới hạn của hai râu đều được hiển thị độc lập dưới dạng dấu chấm hoặc ngôi sao. Đây là các điểm dị biệt (outliers). Việc nhận dạng cấu trúc này là bước không thể thiếu để sàng lọc dữ liệu thô. Nếu không có các điểm dị biệt này, râu sẽ chỉ kéo dài đến giá trị Min và Max tuyệt đối của tập dữ liệu.
3. Hướng Dẫn Cách Đọc Biểu Đồ Boxplot Trong Phân Tích Dữ Liệu
Nắm vững cách đọc biểu đồ Boxplot đòi hỏi nhà nghiên cứu phải có quy trình quan sát logic, bài bản và tuân thủ nghiêm ngặt các nguyên tắc diễn giải số liệu dưới đây.
3.1. Xác Định Dữ Liệu Bị Lệch (Skewness)
Độ lệch (skewness) chỉ ra sự bất đối xứng trong cấu trúc phân phối dữ liệu. Dựa vào hình dáng của biểu đồ hộp, nhà phân tích xác định độ lệch qua 3 trạng thái sau:
- Phân phối đối xứng (Symmetric): Đường trung vị nằm ở tâm của hộp. Khoảng cách từ trung vị đến Q1 bằng khoảng cách từ trung vị đến Q3. Độ dài hai râu (trên và dưới) tương đương nhau. Điều này cho thấy tập dữ liệu phân bổ đồng đều hai bên mức trung bình.
- Lệch phải (Positive Skew): Đường trung vị nằm sát cạnh Q1 (phía dưới hộp) hơn. Râu trên dài hơn râu dưới rõ rệt. Dữ liệu tập trung dày đặc ở dải giá trị thấp và kéo dài lê thê về phía các giá trị cực đại. (Ví dụ điển hình: Phân phối thu nhập trong một quốc gia, nơi số ít người có thu nhập khổng lồ kéo dài râu trên).
- Lệch trái (Negative Skew): Đường trung vị nằm sát cạnh Q3 (phía trên hộp) hơn. Râu dưới dài hơn râu trên. Dữ liệu tập trung ở dải giá trị cao và kéo dài về phía các giá trị cực tiểu. (Ví dụ điển hình: Phân phối điểm thi của một bài kiểm tra quá dễ, đa số học sinh đạt điểm cao).
3.2. Phương Pháp Xác Định Điểm Dị Biệt (Outliers)
Việc xác định điểm dị biệt (outliers) cần thực hiện tuần tự qua các phép toán học cụ thể để tránh loại bỏ nhầm các dữ liệu hợp lệ mang tính đại diện:
- Bước 1: Tính toán giá trị IQR dựa trên phần mềm thống kê chuyên dụng (như SPSS, R, Python, Stata).
- Bước 2: Xác định chính xác ngưỡng dưới bằng công thức Q1 – 1.5 * IQR và ngưỡng trên bằng công thức Q3 + 1.5 * IQR.
- Bước 3: Ghi nhận số lượng và ID của các điểm nằm ngoài ngưỡng này (thể hiện bằng các dấu chấm độc lập trên đồ thị).
- Bước 4: Phân loại và quyết định xử lý. Điểm dị biệt sinh ra do sai số nhập liệu (human error) hoặc lỗi công cụ đo lường cần bị xóa bỏ hoàn toàn. Tuy nhiên, điểm dị biệt phản ánh bản chất hiện tượng thực tế (ví dụ: thu nhập đột biến của CEO trong một tập dữ liệu lương cơ bản) cần được tách ra để tiến hành phân tích nguyên nhân chuyên sâu, tuyệt đối không được tự ý xóa bỏ nếu không có lý do khoa học.
4. Ứng Dụng Của Biểu Đồ Hộp Trong Nghiên Cứu Khoa Học Và Quản Trị
Trong môi trường kinh doanh thực chứng và nghiên cứu khoa học dữ liệu, biểu đồ hộp đóng vai trò trọng yếu trong nhiều khâu phân tích định lượng:
- Tiền xử lý và làm sạch dữ liệu hàn lâm: Trong nghiên cứu học thuật, đặc biệt là khi xây dựng mô hình phương trình cấu trúc (SEM) hoặc bình phương tối thiểu riêng phần (PLS-SEM), việc xử lý các điểm dị biệt bằng biểu đồ hộp là bước làm sạch dữ liệu bắt buộc. Nếu không loại bỏ các giá trị nhiễu này, các chỉ số đánh giá độ phù hợp của mô hình (Model Fit) sẽ bị sai lệch nghiêm trọng. Cụ thể, các chỉ số quan trọng như hệ số xác định R², năng lực dự báo Q², hay chỉ số mức độ phù hợp toàn cục GoF (Goodness of Fit) sẽ bị suy giảm. Đồng thời, các tiêu chuẩn khắt khe để nghiệm thu mô hình như phần dư chuẩn hóa căn quân phương SRMR ≤ 0.08 và chỉ số mức độ phù hợp GFI ≥ 0.90 sẽ không thể đạt được nếu tập dữ liệu còn chứa quá nhiều outliers chưa được xử lý thông qua Boxplot.
- Kiểm định giả định trước mô hình hóa: Giúp đánh giá nhanh tính chuẩn hóa của dữ liệu phân phối, từ đó quyết định sử dụng các kiểm định tham số (như T-test, ANOVA) hay phi tham số (như Mann-Whitney U test).
- So sánh hiệu suất đa biến trong quản trị: Hỗ trợ giám đốc điều hành so sánh cấu trúc mức lương giữa các phòng ban, so sánh năng suất bán hàng của các chi nhánh khu vực thông qua việc đặt các Boxplot song song trên cùng một trục tọa độ.
- Quản trị rủi ro và vận hành: Ứng dụng để phát hiện các giao dịch gian lận tài chính (fraud detection) hoặc lỗi hệ thống máy móc dựa trên việc khoanh vùng các điểm dị biệt có biên độ vượt ngoài râu (whiskers).
5. Câu Hỏi Thường Gặp (FAQ) Về Biểu Đồ Boxplot
Biểu đồ Boxplot có thay thế được biểu đồ Histogram không?
Không. Biểu đồ Boxplot xuất sắc trong việc tóm tắt định lượng, so sánh nhiều nhóm và tìm điểm dị biệt một cách trực quan, nhưng nó không hiển thị chi tiết hình dáng phân phối thực tế bên trong vùng dữ liệu (ví dụ: phân phối đa đỉnh – bimodal) như Histogram. Chuyên gia thống kê thường sử dụng kết hợp cả hai biểu đồ này để có cái nhìn toàn diện nhất.
Điểm dị biệt cực đoan (Extreme Outliers) được xác định như thế nào trong biểu đồ hộp?
Trong các phần mềm thống kê chuyên ngành như SPSS, điểm dị biệt thông thường là các quan sát nằm ngoài khoảng 1.5 lần IQR. Điểm dị biệt cực đoan (extreme outliers) là những quan sát nằm ngoài khoảng 3 lần IQR (tức là có giá trị < Q1 – 3 * IQR hoặc > Q3 + 3 * IQR). Các phần mềm thường phân biệt chúng bằng cách ký hiệu điểm cực đoan là dấu sao (*) thay vì dấu chấm tròn thông thường.
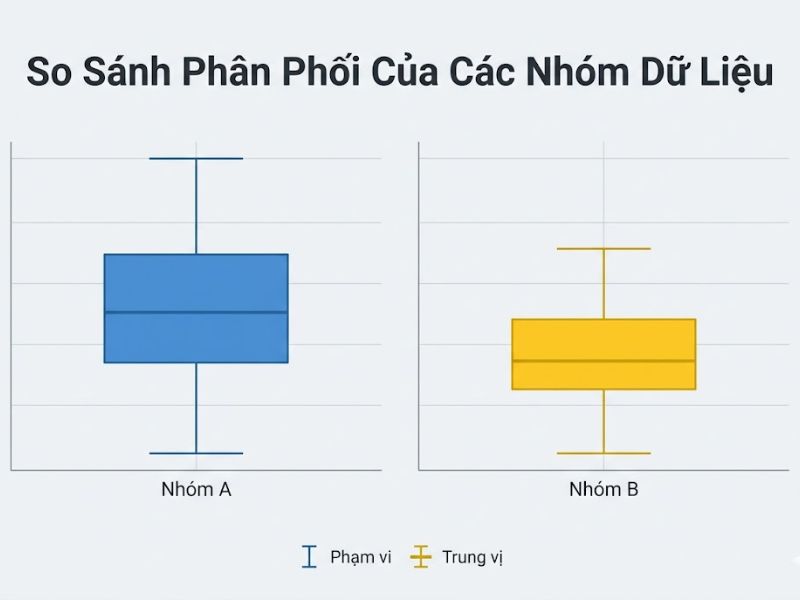
Làm sao để so sánh độ phân tán giữa hai nhóm dữ liệu qua biểu đồ hộp?
Để so sánh độ phân tán một cách chính xác, nhà nghiên cứu hãy đối chiếu trực quan chiều cao của phần hộp (chỉ số IQR) và tổng khoảng cách từ râu dưới đến râu trên (khoảng biến thiên – Range). Nhóm dữ liệu nào có phần hộp dài hơn và râu kéo giãn xa hơn chứng tỏ nhóm đó có mức độ phân tán dữ liệu cao hơn, tính ổn định và đồng nhất thấp hơn.
6. Kết Luận
Việc thành thạo cách đọc biểu đồ Boxplot là kỹ năng phân tích định lượng nền tảng bắt buộc đối với mọi nhà nghiên cứu, nhà khoa học dữ liệu và quản trị viên cấp cao. Quá trình phân rã và hiểu rõ sự tương quan logic giữa trung vị (median), tứ phân vị thứ nhất (Q1), tứ phân vị thứ ba (Q3) và khoảng tứ phân vị (IQR) giúp xác lập góc nhìn chính xác về độ hội tụ cũng như cấu trúc phân phối dữ liệu. Đồng thời, công cụ này cung cấp một bộ quy tắc toán học minh bạch để định vị và xử lý triệt để các điểm dị biệt (outliers). Áp dụng chuẩn mực trực quan hóa chặt chẽ này sẽ củng cố tối đa độ tin cậy của tập dữ liệu đầu vào, từ đó nâng tầm chất lượng, tính xác đáng cho các công trình nghiên cứu khoa học và các báo cáo phục vụ việc ra quyết định chiến lược trong doanh nghiệp.



