
Vấn đề sai lệch lựa chọn (Selection Bias) làm sai lệch kết quả đánh giá tác động trong các tập dữ liệu quan sát không ngẫu nhiên. Ghép cặp điểm xu hướng (Propensity Score Matching – PSM) là một phương pháp thống kê giúp cân bằng đặc điểm hiệp biến giữa nhóm can thiệp và nhóm đối chứng. Nguyên nhân chính gây ra sai lệch là do sự phân bổ không đồng đều của các đặc điểm nền giữa các đối tượng. Giải pháp hiệu quả nhất là ứng dụng PSM để tạo ra một môi trường giả lập thử nghiệm ngẫu nhiên, từ đó cho phép ước lượng tác động nhân quả một cách chính xác và khách quan.

Giới thiệu tổng quan về vai trò của PSM trong nghiên cứu khoa học thực chứng
Trong các thiết kế nghiên cứu thực chứng, dữ liệu quan sát thường tồn tại nhiều rào cản về mặt thống kê.
- Thách thức của dữ liệu quan sát và vấn đề sai lệch lựa chọn (Selection Bias): Khác với thử nghiệm ngẫu nhiên có đối chứng (RCT), các đối tượng trong dữ liệu quan sát tự lựa chọn tham gia vào nhóm can thiệp (treatment group) dựa trên những đặc điểm cá nhân. Điều này tạo ra sai lệch lựa chọn, khiến việc so sánh trực tiếp kết quả giữa hai nhóm trở nên thiếu chính xác.
- Tầm quan trọng của việc kiểm soát các biến nhiễu (Confounders): Biến nhiễu là những yếu tố tác động đồng thời đến xác suất nhận can thiệp và kết quả đầu ra. Nếu không kiểm soát chặt chẽ các biến này, nghiên cứu sẽ dẫn đến những kết luận sai lệch về mối quan hệ nhân quả.
- PSM như một công cụ thiết kế nghiên cứu giả lập thử nghiệm ngẫu nhiên: Thuật toán này điều chỉnh dữ liệu bằng cách tìm kiếm và ghép cặp các đối tượng có đặc điểm quan sát tương đồng, từ đó giả lập một môi trường phân bổ ngẫu nhiên nhằm loại bỏ ảnh hưởng của các biến nhiễu.
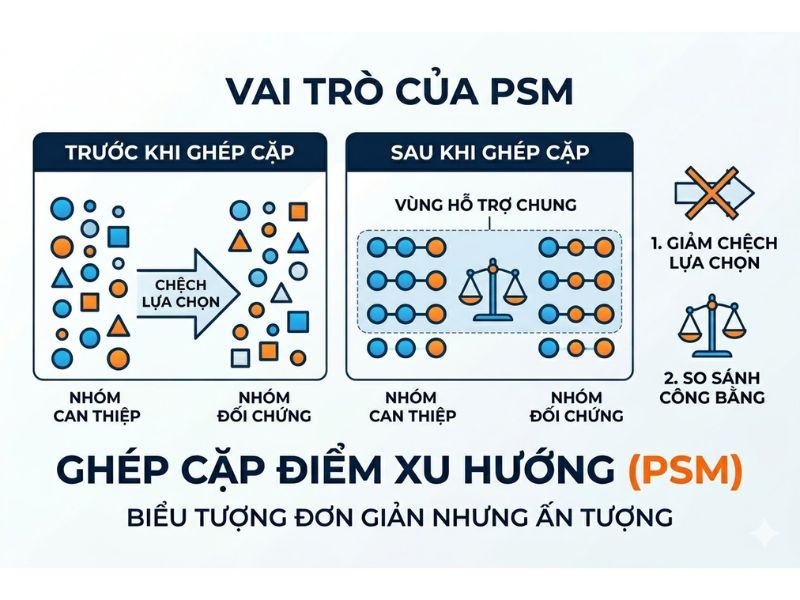
Khái niệm và nền tảng lý thuyết của Ghép cặp điểm xu hướng (Propensity Score Matching – PSM)
Kỹ thuật Ghép cặp điểm xu hướng (Propensity Score Matching – PSM) được xây dựng dựa trên các nền tảng lý thuyết xác suất thống kê vững chắc.
- Định nghĩa điểm xu hướng (Propensity Score): Điểm xu hướng là xác suất có điều kiện (Conditional Probability) của việc một cá thể được phân bổ vào nhóm can thiệp, tính toán dựa trên một tập hợp các biến số quan sát được (Covariates).
- Khuôn mẫu kết quả tiềm năng (Potential Outcomes Framework): Lý thuyết này (còn gọi là mô hình Neyman-Rubin) lập luận rằng mỗi cá thể có hai kết quả tiềm năng: một kết quả khi nhận can thiệp và một kết quả khi không nhận can thiệp. Hiệu ứng nhân quả chính là phần chênh lệch giữa hai trạng thái này.
- Lịch sử hình thành: Khái niệm này được phát triển bởi Paul Rosenbaum và Donald Rubin (1983). Hai nhà khoa học này đã chứng minh rằng việc ghép cặp trực tiếp trên điểm xu hướng có giá trị thống kê tương đương với việc ghép cặp trên toàn bộ không gian biến số đa chiều.
Các giả định cốt lõi để đảm bảo tính hợp lệ của mô hình PSM
Để kết quả của mô hình mang tính đại diện và có độ tin cậy cao, nghiên cứu phải thỏa mãn các giả định toán học sau:
- Giả định độc lập có điều kiện (Conditional Independence Assumption – CIA): Giả định này bắt buộc mọi biến nhiễu ảnh hưởng đến việc lựa chọn can thiệp và kết quả đầu ra đều đã được quan sát và đưa vào mô hình. Khi kiểm soát điểm xu hướng, kết quả tiềm năng độc lập với trạng thái can thiệp.
- Giả định vùng hỗ trợ chung (Common Support / Overlap): Mọi cá thể trong mẫu nghiên cứu, bất kể thuộc nhóm nào, đều phải có xác suất lớn hơn 0 và nhỏ hơn 1 để nhận can thiệp. Giả định này đảm bảo luôn tồn tại các cá thể tương đồng để tiến hành ghép cặp.
- Tầm quan trọng của các biến quan sát (Observed variables): Sự thành công của mô hình phụ thuộc hoàn toàn vào chất lượng và số lượng của các biến hiệp biến được thu thập. Mô hình không thể xử lý các biến nhiễu ẩn (Unobserved confounders).
Phân tích chi tiết quy trình thực hiện Ghép cặp điểm xu hướng (Propensity Score Matching – PSM)
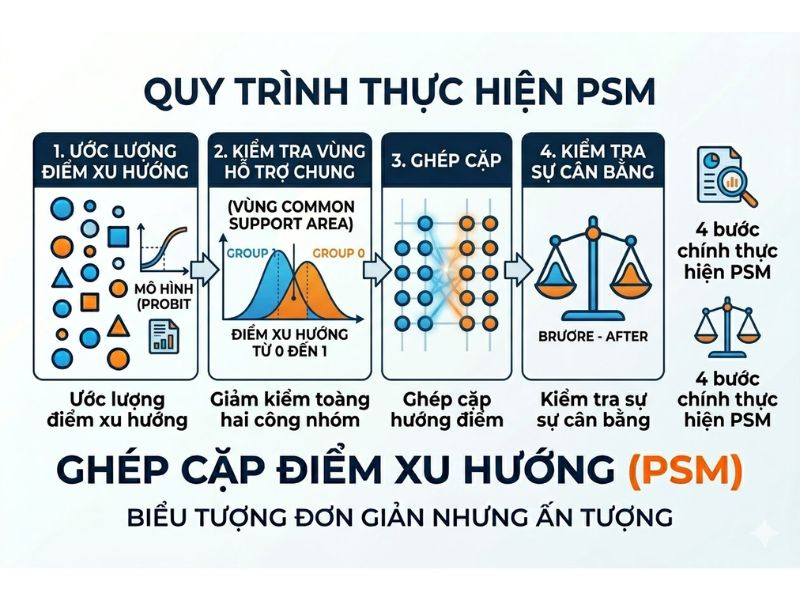
Việc thực thi kỹ thuật Ghép cặp điểm xu hướng (Propensity Score Matching – PSM) bao gồm 4 bước chuẩn hóa:
- Bước 1: Lựa chọn các biến số hiệp biến (Covariates): Xác định các biến độc lập tác động đồng thời đến biến can thiệp và biến kết quả dựa trên tổng quan tài liệu (Literature Review). Tuyệt đối không đưa vào các biến bị ảnh hưởng bởi can thiệp.
- Bước 2: Ước lượng điểm xu hướng: Sử dụng mô hình hồi quy nhị phân (Probit hoặc Logit) để tính toán xác suất nhận can thiệp của từng quan sát trong mẫu.
- Bước 3: Lựa chọn thuật toán ghép cặp phù hợp: Dựa vào phân phối của tập dữ liệu để chọn thuật toán tính toán khoảng cách phù hợp (ví dụ: Nearest Neighbor, Radius, Kernel).
- Bước 4: Ước lượng hiệu quả can thiệp: Tính toán tác động nhân quả trung bình, bao gồm Tác động trung bình (ATE – Average Treatment Effect), Tác động trên nhóm được can thiệp (ATT – Average Treatment Effect on the Treated), hoặc Tác động trên nhóm đối chứng (ATC).
Các thuật toán ghép cặp phổ biến và tiêu chí lựa chọn trong thực tế
Mỗi thuật toán cung cấp một cơ chế xử lý dữ liệu khác nhau, tùy thuộc vào kích thước mẫu và mức độ dung sai của nghiên cứu.
| Thuật toán | Cơ chế hoạt động | Ưu điểm cốt lõi | Nhược điểm/Hạn chế |
| Ghép cặp lân cận gần nhất (Nearest Neighbor Matching) | Chọn cá thể ở nhóm đối chứng có điểm xu hướng gần nhất với cá thể nhóm can thiệp. | Dễ thực hiện, giải thích đơn giản. | Có thể ghép cặp các cá thể có khoảng cách điểm quá xa nếu không đặt giới hạn. |
| Ghép cặp theo bán kính (Radius & Caliper Matching) | Chỉ ghép cặp các đối tượng nằm trong một bán kính (caliper) cho trước. | Đảm bảo độ tương đồng cao, giảm sai số (Bias). | Làm giảm kích thước mẫu do loại bỏ các quan sát ngoài bán kính. |
| Ghép cặp hạt nhân (Kernel Matching) | Gán trọng số cho toàn bộ nhóm đối chứng dựa trên khoảng cách điểm xu hướng. | Tối đa hóa kích thước mẫu, giảm phương sai (Variance). | Tính toán phức tạp, có thể bao gồm các quan sát kém tương đồng. |
| Ghép cặp phân tầng (Stratification Matching) | Chia mẫu thành các tầng (strata) dựa trên dải điểm xu hướng và so sánh bên trong mỗi tầng. | Đánh giá được hiệu ứng can thiệp theo từng phân khúc. | Số lượng quan sát trong một số tầng có thể quá ít để đạt ý nghĩa thống kê. |
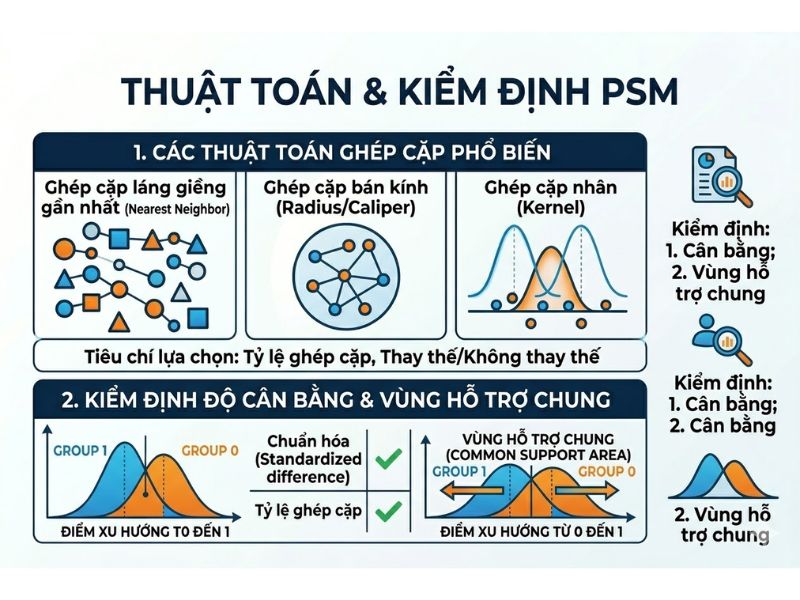
Kiểm định độ cân bằng (Balance checks) và vùng hỗ trợ chung (Common Support)
Sau khi chạy thuật toán, nhà nghiên cứu phải xác nhận tính hợp lệ của việc ghép cặp thông qua các bài kiểm định:
- Sử dụng chênh lệch trung bình chuẩn hóa (Standardized Mean Difference – SMD): SMD đo lường sự khác biệt về trung bình của các biến hiệp biến giữa hai nhóm. Ngưỡng chấp nhận thông thường là SMD < 0.1 (hoặc 10%).
- Đồ thị Love Plot và phân phối mật độ điểm xu hướng: Love Plot trực quan hóa sự sụt giảm của SMD trước và sau khi ghép cặp. Đồ thị phân phối (Density plot) giúp xác nhận giả định vùng hỗ trợ chung (Common Support) có được đảm bảo hay không.
- Xử lý khi các biến số không đạt điều kiện cân bằng: Nếu dữ liệu chưa cân bằng, nhà nghiên cứu cần thay đổi thuật toán ghép cặp, thêm biến tương tác (interaction terms), hoặc thay đổi mô hình tính điểm xu hướng (từ Logit sang Probit và ngược lại).
So sánh phương pháp PSM với các mô hình hồi quy truyền thống (OLS)
Trong suy diễn nhân quả, PSM mang lại nhiều lợi thế vượt trội so với Hồi quy bình phương tối thiểu thông thường (OLS).
- Tính phi tham số và giảm bớt sự phụ thuộc vào dạng hàm: OLS yêu cầu giả định khắt khe về dạng hàm tuyến tính giữa biến độc lập và phụ thuộc. Ngược lại, PSM là phương pháp tiếp cận phi tham số, giúp tránh được sai số do thiết lập sai dạng hàm (Functional form misspecification).
- Khả năng xử lý vấn đề “đa chiều” (Curse of Dimensionality): Khi số lượng biến kiểm soát quá lớn, OLS dễ gặp hiện tượng đa cộng tuyến. PSM nén toàn bộ thông tin đa chiều này thành một chỉ số vô hướng (điểm xu hướng) duy nhất.
- Khi nào nên kết hợp PSM với sai phân trong sai phân (Difference-in-Differences – DiD): Việc kết hợp PSM-DiD được ứng dụng khi dữ liệu có cấu trúc mảng (Panel data). PSM giải quyết biến nhiễu quan sát được, trong khi DiD khử đi tác động của các yếu tố không quan sát được nhưng bất biến theo thời gian.
Các công cụ phần mềm hỗ trợ thực hiện Ghép cặp điểm xu hướng (Propensity Score Matching – PSM)
Việc tính toán mô hình hiện nay được tự động hóa qua các ngôn ngữ lập trình thống kê mạnh mẽ.
- Thực hiện trên Stata: Lệnh psmatch2 và teffects psmatch cung cấp bộ công cụ toàn diện từ tính điểm, chọn thuật toán đến kiểm định độ cân bằng.
- Sử dụng R: Gói thư viện MatchIt và twang cho phép tùy biến chuyên sâu các biểu đồ trực quan như Love Plot và hỗ trợ đa dạng thuật toán ghép.
- Ứng dụng trong SPSS và Python: SPSS hỗ trợ thông qua công cụ Propensity Score Matching tích hợp sẵn. Python xử lý hiệu quả qua thư viện CausalML và DoWhy dành cho các bộ dữ liệu siêu lớn.
FAQ – Giải đáp các thắc mắc chuyên sâu về Ghép cặp điểm xu hướng (Propensity Score Matching – PSM)
PSM có giải quyết được sai lệch do các biến không quan sát được không?
Không, PSM chỉ kiểm soát được các sai lệch phát sinh từ các biến đã được quan sát (Observed covariates). Để giải quyết sai lệch từ các biến không quan sát được, nhà nghiên cứu cần sử dụng công cụ Biến công cụ (Instrumental Variables – IV) hoặc mô hình Sai phân trong sai phân (DiD).
Tại sao cỡ mẫu thường bị giảm đáng kể sau khi ghép cặp?
Cỡ mẫu giảm do thuật toán loại bỏ các quan sát nằm ngoài vùng hỗ trợ chung (Common Support) hoặc vượt qua giới hạn Caliper. Việc đánh đổi cỡ mẫu này là cần thiết để đảm bảo sự tương đồng tuyệt đối giữa hai nhóm, giúp giảm thiểu độ chệch (Bias) cho kết quả ước lượng.
Làm thế nào để chọn Caliper tối ưu cho nghiên cứu?
Caliper tối ưu thông thường được thiết lập ở mức 0.2 lần độ lệch chuẩn của điểm xu hướng đã được biến đổi logit (theo chuẩn của Austin, 2011). Mức thiết lập này được khoa học chứng minh là cân bằng tốt nhất giữa việc loại bỏ sai số và duy trì đủ lượng quan sát thống kê.
Kết luận
Ghép cặp điểm xu hướng (Propensity Score Matching – PSM) đóng vai trò là một khuôn khổ luận lý sắc bén nhằm trích xuất tác động nhân quả từ dữ liệu quan sát. Phương pháp này cung cấp giải pháp triệt để cho bài toán sai lệch lựa chọn (Selection Bias), giúp các mô hình kinh tế lượng vượt qua những hạn chế của OLS truyền thống. Việc nắm vững quy trình thực thi, từ kiểm định độ cân bằng, giả định nền tảng đến việc kết hợp các công cụ thuật toán mở ra giá trị ứng dụng cao cho việc ra quyết định thực chứng. Để đi sâu hơn vào các phương pháp luận và kỹ thuật định lượng này, bạn có thể tham khảo thêm các tài liệu hệ thống tại chuyên trang nghiên cứu khoa học.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



