
Dữ liệu ngoại lai là các giá trị quan sát chênh lệch một cách bất thường so với phân phối chung của tổng thể tập mẫu. Nguyên nhân chính là do sai số hệ thống trong khâu đo lường hoặc sự biến thiên cực đoan của tự nhiên. Giải pháp nhanh nhất là sử dụng biểu đồ Boxplot hoặc tính toán điểm chuẩn Z-score trên phần mềm SPSS để phát hiện, từ đó quyết định loại bỏ hoặc chuẩn hóa nhằm bảo vệ tính chính xác của mô hình nghiên cứu.

1. Dữ liệu ngoại lai là gì?
Định nghĩa chi tiết: Dữ liệu ngoại lai (Outliers) là một thuật ngữ nền tảng thuộc lĩnh vực Khoa học Dữ liệu và Thống kê học ứng dụng. Nó chỉ định một hoặc một nhóm các điểm dữ liệu có giá trị nằm ngoài phạm vi phân phối xác suất dự kiến của tập dữ liệu.
So sánh sự khác biệt: So với các điểm dữ liệu thông thường (Inliers) đại diện cho xu hướng trung tâm của tổng thể, dữ liệu ngoại lai mang tính chất dị biệt. Thay vì củng cố mô hình dự báo như dữ liệu chuẩn, giá trị ngoại lai có khả năng làm biến dạng các đại lượng thống kê mô tả (Mean, Variance) và làm chệch đường hồi quy tuyến tính.
Luận điểm chính: Sự tồn tại của các giá trị bất thường này không hẳn là một sai sót, mà đôi khi là tín hiệu của một biến số chưa được khám phá.
Các thành phần cốt lõi:
- Giá trị cực đoan dưới (Lower Outliers): Nằm thấp hơn đáng kể so với ngưỡng phân vị thứ nhất (Q1).
- Giá trị cực đoan trên (Upper Outliers): Nằm cao hơn đáng kể so với ngưỡng phân vị thứ ba (Q3).
- Khoảng cách dị biệt: Mức độ sai lệch chuẩn tính từ giá trị trung bình cộng.
Mục tiêu cốt lõi: Xác định và xử lý chính xác các điểm dữ liệu bất thường này nhằm tối ưu hóa độ tin cậy (Reliability) và độ giá trị (Validity) của các mô hình kinh tế lượng.

2. Lịch sử hình thành và phương pháp phát hiện
Giai đoạn Khởi nguồn:
Khái niệm về sự sai lệch chuẩn đã được manh nha từ thế kỷ 19. Học giả Francis Galton (1889) trong tác phẩm “Natural Inheritance” đã đặt nền móng cho việc phân tích sự phân tán của dữ liệu. Ông đặt câu hỏi về việc làm thế nào để xử lý các phép đo không tuân theo phân phối chuẩn Gaussian, từ đó khởi xướng khái niệm về các điểm dị biệt.
Giai đoạn Hoàn thiện/Phát triển:
John Tukey (1977) với tác phẩm kinh điển “Exploratory Data Analysis” đã đưa ra bước ngoặt lớn. Ông phát triển biểu đồ hộp (Boxplot) và phương pháp Tứ phân vị (Interquartile Range – IQR) để cô lập dữ liệu ngoại lai một cách trực quan và chuẩn xác về mặt toán học mà không bị phụ thuộc vào giá trị trung bình (vốn rất dễ bị bóp méo).
3. Các miền nội dung khái niệm cốt lõi (Core Concepts)
Để xử lý dữ liệu chuẩn xác, nhà nghiên cứu cần nắm vững các giả định nền tảng sau:
Các giả định nền tảng:
- Giả định về phân phối chuẩn (Normality): Phần lớn các bài toán kiểm định giả thuyết (T-test, ANOVA) đều giả định tập dữ liệu tuân theo phân phối chuẩn. Sự xuất hiện của giá trị dị biệt sẽ phá vỡ giả định này.
- Giả định về sai số ngẫu nhiên: Mọi hệ thống thu thập thông tin đều tồn tại sai số ngẫu nhiên, nhưng khi sai số vượt qua ranh giới ngẫu nhiên để trở thành sai số hệ thống, điểm dữ liệu đó trở thành ngoại lai.
Các đặc tính/biến số quan trọng:
- Mức độ chênh lệch (Magnitude): Khoảng cách tuyệt đối từ điểm ngoại lai đến trung vị (Median).
- Tần suất xuất hiện (Frequency): Tỷ lệ phần trăm các điểm bất thường trên tổng dung lượng mẫu (N).
- Tác động đòn bẩy (Leverage): Khả năng một điểm dữ liệu kéo lệch đường hồi quy (Regression Line) về phía nó.
Bảng so sánh phân loại Dữ liệu ngoại lai:
| Tiêu chí | Dữ liệu Ngoại lai Mức độ nhẹ (Mild Outliers) | Dữ liệu Ngoại lai Cực đoan (Extreme Outliers) |
| Công thức xác định (Boxplot) | Nằm ngoài [Q1 – 1.5IQR] hoặc [Q3 + 1.5IQR] | Nằm ngoài [Q1 – 3IQR] hoặc [Q3 + 3IQR] |
| Bản chất nguyên nhân | Thường do biến thiên tự nhiên của tập mẫu. | Đa phần do lỗi hệ thống hoặc lỗi nhập liệu. |
| Tác động đến mô hình | Gây nhiễu nhẹ, có thể dùng mô hình phi tham số để khắc phục. | Làm chệch hoàn toàn kết quả hồi quy và kiểm định p-value. |
| Giải pháp ưu tiên | Giữ lại và chuẩn hóa dữ liệu (Data Transformation). | Loại bỏ khỏi tập dữ liệu (Data Trimming) nếu xác nhận là lỗi. |
4. Nội hàm các khái niệm và Thang đo các biến (Measurement Scales)
Đối với nhà nghiên cứu định lượng, việc đo lường và phát hiện cần dựa trên các chuẩn mực sau:
- Đo lường qua Khoảng tứ phân vị (IQR Method):
- Phân loại: Sử dụng trên phần mềm SPSS để vẽ Boxplot.
- Cách đo lường: Dữ liệu được sắp xếp theo thứ tự, tính toán Q1 (25%) và Q3 (75%). Các giá trị vượt ngưỡng 1.5 lần IQR được gán nhãn là ngoại lai. Đây là thang đo tối ưu cho dữ liệu bị lệch (Skewed data).
- Đo lường qua Điểm chuẩn (Z-score Method):
- Phân loại: Phù hợp cho biến định lượng liên tục có phân phối chuẩn.
- Cách đo lường: Chuyển đổi mọi điểm dữ liệu thành điểm Z. Giá trị nào có |Z| > 3 được định danh là dữ liệu ngoại lai.

5. Các nghiên cứu liên quan tiêu biểu (Related Studies)
- Nhóm 1 – Các bài báo nền tảng: Tukey, J. W. (1977). Exploratory Data Analysis. Công trình này khai sinh ra phương pháp phát hiện dị biệt thông qua đồ thị Boxplot, thiết lập chuẩn mực toán học IQR vẫn được phần mềm SPSS áp dụng đến nay.
- Nhóm 2 – Ứng dụng trong Tài chính: Fama, E. F. (1965). The Behavior of Stock-Market Prices (Journal of Business). Nghiên cứu chỉ ra rằng dữ liệu tài chính (giá cổ phiếu) thường chứa nhiều giá trị ngoại lai đuôi béo (fat tails), đòi hỏi phải giữ lại thay vì xóa bỏ để phản ánh rủi ro khủng hoảng.
- Nhóm 3 – Phân tích tổng hợp: Rousseeuw, P. J., & Hubert, M. (2011). Robust statistics for outlier detection (Wiley Interdisciplinary Reviews). Bài báo tổng hợp các phương pháp luận chứng minh sự cần thiết của thống kê mạnh (Robust statistics) để đối phó với dữ liệu dị biệt.
6. Những mặt hạn chế và khoảng trống nghiên cứu (Limitations)
Không có phương pháp xử lý nào là hoàn hảo tuyệt đối. Quá trình làm sạch tập mẫu tồn tại 3 hạn chế lớn:
- Hạn chế về bối cảnh (Contextual Limitation): Các công thức toán học vô tri (như Z-score > 3) có thể gạch bỏ nhầm những thông tin mang tính đột phá. Lịch sử khoa học có nhiều phát minh bắt nguồn từ việc phân tích các giá trị dị biệt.
- Hạn chế về đo lường (Measurement Limitation): Đối với các tập mẫu quá nhỏ (N < 30), các công thức nhận diện ngoại lai thường thiếu độ tin cậy và có thể chỉ điểm sai lệch.
- Hạn chế về tính đa biến (Multivariate Assumption): Phân tích Boxplot chỉ hiệu quả trên từng biến đơn lẻ (Univariate). Việc phát hiện ngoại lai đa biến (Mahalanobis Distance) đòi hỏi thao tác phức tạp hơn rất nhiều.
7. Các hướng nghiên cứu (Research Applications)
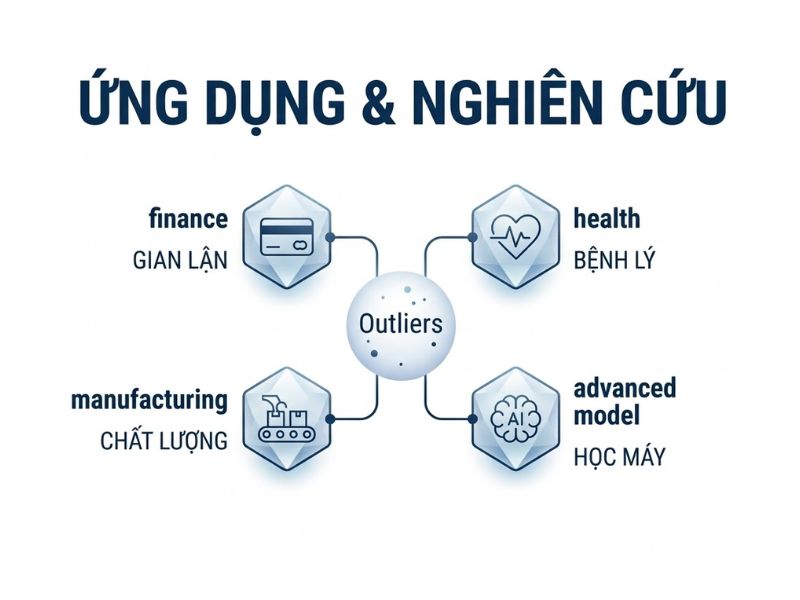
- Kết hợp với Machine Learning (Học máy): Ứng dụng thuật toán Isolation Forest hoặc SVM (Support Vector Machine) để hệ thống tự động nhận diện giá trị bất thường trong tập dữ liệu Big Data thay vì làm thủ công trên SPSS.
- Kết hợp với Lý thuyết Quản trị rủi ro: Phân tích chuyên sâu các điểm ngoại lai để nhận diện “Thiên nga đen” (Black Swan) – những sự kiện hiếm gặp nhưng gây hậu quả kinh tế thảm khốc, từ đó xây dựng các kịch bản dự báo khủng hoảng doanh nghiệp.
8. Cách ứng dụng lý thuyết vào thực tiễn doanh nghiệp (Practical Application)
Việc nắm vững bản chất dữ liệu bất thường cung cấp bộ công cụ tư duy sắc bén cho các nhà quản lý:
- Ứng dụng 1: Quản trị chất lượng sản xuất (Six Sigma). Các lỗi kỹ thuật trên dây chuyền sản xuất chính là những giá trị ngoại lai. Giám đốc vận hành dùng biểu đồ kiểm soát (Control Charts) để nhận diện nhanh sản phẩm lỗi vượt ngưỡng ±3 Sigma và lập tức dừng dây chuyền bảo trì.
- Ứng dụng 2: Phát hiện gian lận tài chính (Fraud Detection). Trong ngành ngân hàng, giao dịch thẻ tín dụng có giá trị lớn bất thường hoặc tại quốc gia khác so với hành vi mua sắm thông thường của khách hàng sẽ bị AI đánh dấu là ngoại lai để khóa thẻ tự động.
- Ứng dụng 3: Tối ưu hóa Marketing. Khi đánh giá chỉ số ROI, LTV hay CAC của các chiến dịch, việc loại bỏ các giao dịch “sỉ” đột biến (ngoại lai) sẽ giúp Marketer có được bức tranh chuẩn xác về hành vi của khách hàng bán lẻ thông thường.
9. Các câu hỏi thường gặp (FAQ)
Làm thế nào để quyết định xóa hay giữ dữ liệu ngoại lai?
Chỉ xóa khi bạn có bằng chứng chắc chắn đó là lỗi nhập liệu hoặc lỗi công cụ đo lường. Nếu giá trị đó phản ánh sự thật khách quan của tập mẫu, bạn bắt buộc phải giữ lại và sử dụng các thuật toán phi tham số.
Kiểm định Z-score có áp dụng được cho mọi loại dữ liệu không?
Không. Điểm chuẩn Z-score chỉ chính xác khi tập dữ liệu gốc của bạn phân phối tiệm cận chuẩn. Đối với dữ liệu lệch (Skewed), phương pháp IQR thông qua Boxplot trên SPSS là lựa chọn chuẩn khoa học.
Dữ liệu ngoại lai có ảnh hưởng đến giá trị trung vị (Median) không?
Trung vị (Median) là một đại lượng thống kê mạnh (Robust Statistic), do đó nó hầu như không bị ảnh hưởng bởi sự xuất hiện của các điểm dị biệt. Trong khi đó, giá trị trung bình cộng (Mean) sẽ bị bóp méo nghiêm trọng.
10. Kết luận
Nhìn chung, dữ liệu ngoại lai không chỉ là những con số nhiễu loạn trên bảng tính SPSS, mà bản chất của chúng là tấm gương phản chiếu chất lượng của toàn bộ quá trình thu thập thông tin và sự phức tạp của hiện tượng nghiên cứu. Việc phát hiện chính xác thông qua Tứ phân vị (IQR) và ứng dụng tư duy phân tích nhạy bén để ra quyết định xử lý là kỹ năng bắt buộc của một nhà nghiên cứu chuẩn mực. Nắm vững phương pháp này giúp các học giả, chuyên viên phân tích nâng cao tính giá trị của mô hình toán học, từ đó đưa ra các chiến lược kinh doanh và học thuật mang tính thực tiễn cao.
Bài viết được nghiên cứu, tổng hợp và phân tích chuyên sâu nhằm phục vụ cộng đồng học thuật và doanh nghiệp. Tham khảo thêm các kiến thức quản trị, nghiên cứu khoa học và thống kê ứng dụng được chia sẻ bởi nhà nghiên cứu Nguyễn Thanh Phương.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



