
Mô hình IGSCA là phương pháp phân tích phương trình cấu trúc (SEM) tích hợp, chuyên xử lý các hiện tượng phức tạp trong kinh doanh. Nguyên nhân chính khiến các mô hình SEM truyền thống gặp lỗi là do không thể ước lượng đồng thời biến nhân tố (factor) và biến thành phần (component) mà không gây chệch tham số. Giải pháp nhanh nhất là ứng dụng mô hình IGSCA kết hợp với các ngưỡng cắt (cutoff) của chỉ số GFI và SRMR được điều chỉnh theo quy mô mẫu để đánh giá chính xác độ phù hợp của mô hình.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: Integrated Generalized Structured Component Analysis: On the Use of Model Fit Criteria in International Management Research
- Tiêu đề tiếng Việt: Phân tích thành phần cấu trúc tổng quát tích hợp: Về việc sử dụng các tiêu chuẩn độ phù hợp mô hình trong nghiên cứu Quản trị Quốc tế
- Tác giả: Gyeongcheol Cho, Christopher Schlaegel, Heungsun Hwang, Younyoung Choi, Marko Sarstedt, Christian M. Ringle
- Tạp chí: Management International Review (2022)
1.2 Bối cảnh thực tiễn & Khoảng trống nghiên cứu
Nghiên cứu trong lĩnh vực Quản trị Quốc tế (IM) và Kinh doanh Quốc tế (IB) đặc trưng bởi tính phức tạp cao của các hiện tượng. Mô hình phương trình cấu trúc (SEM) trước nay vẫn được chia thành hai lĩnh vực loại trừ lẫn nhau: dựa trên yếu tố (factor-based SEM) và dựa trên thành phần (component-based SEM).
Tuy nhiên, nghiên cứu IM/IB hiện đại cần một mô hình tổng quát để xem xét đồng thời nhiều loại cấu trúc: một số đại diện cho các yếu tố (ví dụ: khoảng cách văn hóa) và một số khác đại diện cho các thành phần (ví dụ: kinh nghiệm quốc tế). Việc bỏ qua sự phù hợp giữa đại diện cấu trúc và phương pháp ước lượng sẽ tạo ra các kết quả bị chệch (biased estimates), dẫn đến những suy luận sai lầm. Phương pháp mô hình IGSCA ra đời để lấp đầy khoảng trống này, cung cấp một khung phân tích không chệch cho cả hai loại cấu trúc.
1.3 Lịch sử hình thành và Hệ thống Lý thuyết nền tảng (Theoretical Foundations)
Để hiểu sự ra đời của mô hình IGSCA, cần rà soát lịch sử ứng dụng các lý thuyết đo lường trong SEM:
- Giai đoạn Khởi nguồn (Factor-based & Component-based): Lý thuyết đo lường (Measurement Theory) phân định rõ hai trường phái. Phân tích cấu trúc hiệp phương sai (CSA) được coi là tiêu chuẩn thống kê cho SEM dựa trên yếu tố. Trong khi đó, Phân tích thành phần cấu trúc tổng quát (GSCA) và Mô hình hóa đường dẫn bình phương tối thiểu riêng phần (PLSPM) là phương pháp nổi bật cho SEM dựa trên thành phần.
- Giai đoạn Tích hợp (IGSCA – Hwang et al., 2021): Dựa trên giả định rằng các khái niệm quản trị không hoàn toàn thuần túy là yếu tố hay thành phần, IGSCA được phát triển để kết hợp thuật toán của GSCA (ước lượng thành phần) và GSCA_M (ước lượng yếu tố) vào một khung duy nhất.
- Lý thuyết Học tập qua trải nghiệm (Experiential Learning Theory – Kolb, 1984): Trong bài báo này, mô hình minh họa thực nghiệm được xây dựng dựa trên lý thuyết của Kolb, lập luận rằng Trí tuệ văn hóa (Cultural Intelligence) được hình thành từ đặc điểm tính cách và kinh nghiệm quốc tế. Việc học tập và phản ánh liên tục từ môi trường quốc tế đóng vai trò như chất xúc tác để gia tăng năng lực thích ứng đa văn hóa.

2. Khái Niệm Hóa và Cấu Trúc Khái Niệm (Conceptualization)
Biến quan sát (Observed variables) là các chỉ báo có thể đo lường trực tiếp. Cấu trúc (Constructs) là những trừu tượng tinh thần không thể đo lường trực tiếp. Dưới góc độ lý thuyết, có hai cấu trúc cốt lõi:
- Yếu tố (Factors): Đại diện cho một thực tại bên ngoài (external reality) độc lập với các biến quan sát, và chính nó tạo ra mô hình tương quan của các biến này. Các biến quan sát xuất phát từ yếu tố được gọi là chỉ báo kết quả/phản xạ (effect/reflective indicators). Ví dụ: Định hướng thị trường quốc tế, năng lực thể chế.
- Thành phần (Components): Được định nghĩa là sự tóm tắt của các biến quan sát hoặc một chỉ số (index). Các biến quan sát xây dựng nên thành phần được gọi là chỉ báo hỗn hợp (composite indicators). Ví dụ: Trí tuệ văn hóa, Tư duy toàn cầu, sự điều chỉnh giao thoa văn hóa.

3. Các Phương Pháp SEM Khác Nhau và Đánh Giá Trong IM/IB (2012-2021)
3.1 Khả năng xử lý của các phương pháp
Hwang và cộng sự (2021) chỉ ra rằng mô hình IGSCA tạo ra các ước lượng tham số không chệch (unbiased) trong các mô hình kết hợp. Bảng dưới đây so sánh hành vi của các phương pháp thống kê:
Bảng 1: Hành vi kỳ vọng của các phương pháp SEM khi ước lượng tham số mô hình chứa cả yếu tố và thành phần
| Phương pháp SEM | Tải lượng yếu tố (Factor Loadings) | Tải lượng thành phần (Component Loadings) | Đường dẫn giữa các yếu tố | Đường dẫn giữa các thành phần | Đường dẫn nối yếu tố và thành phần |
| CSA | 0 | – | 0 | + | + |
| PLSPM | + | 0 | – | 0 | – |
| GSCA_M | 0 | – | 0 | + | + |
| GSCA | + | 0 | – | 0 | – |
| PLSc | 0 | 0 | 0 | 0 | 0 |
| IGSCA | 0 | 0 | 0 | 0 | 0 |
(Ghi chú: 0 = Không chệch, + = Chệch dương, – = Chệch âm)
3.2 Tình trạng ứng dụng thực tiễn trong IM/IB
Đánh giá 203 bài báo từ 6 tạp chí IM/IB hàng đầu (Management International Review, International Business Review, Journal of International Management, Journal of World Business, Journal of International Business Studies, và Global Strategy Journal) giai đoạn 2012-2021 cho thấy một khoảng trống lớn về phương pháp luận:
- 115 bài sử dụng CSA (57%).
- 86 bài sử dụng PLSPM (42%).
- 2 bài sử dụng GSCA (1%).
- 0 bài sử dụng PLSc, GSCA_M, hoặc IGSCA.
Việc các nhà nghiên cứu IM/IB quá phụ thuộc vào CSA và PLSPM là một vấn đề nghiêm trọng, bởi vì cả hai phương pháp này đều không thể đưa cả yếu tố và thành phần vào cùng một mô hình mà không gây chệch tham số.
4. Quy Trình Mô Phỏng và Công Thức Cốt Lõi (Simulation Process & Formulas)
4.1 Thiết kế Nghiên cứu Mô phỏng (Monte-Carlo Simulation)
Nghiên cứu tiến hành mô phỏng để đánh giá khả năng phân biệt mô hình đúng/sai của GFI và SRMR trong mô hình IGSCA.
- Điều kiện: Số lượng cấu trúc (3, 5, 7), số chỉ báo mỗi cấu trúc (3, 5, 7), kích thước tải lượng, và tương quan giữa các yếu tố/thành phần (r = 0, 0.2, 0.4).
- Có tổng cộng 81 mô hình quần thể được thiết lập.
- Quy mô mẫu (N): 50, 100, 200, 500, 1000, và 2000.
- Mỗi điều kiện tạo 1.000 mẫu ngẫu nhiên để tính toán tỷ lệ lỗi Loại I (Type I error – từ chối mô hình đúng) và Loại II (Type II error – chấp nhận mô hình sai).
4.2 Công thức Toán học Nền tảng (Mathematical Formulas)
Trong IGSCA, mô hình đo lường cho yếu tố (GSCA_M) và thành phần (GSCA) được tích hợp. Hàm mục tiêu cần tối thiểu hóa được định nghĩa là:
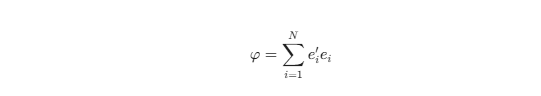
Chỉ số Mức độ Phù hợp (Goodness-of-Fit Index – GFI) được tính bằng:
Phần dư Bình phương Trung bình Chuẩn hóa (SRMR) được tính bằng: +1
Lưu ý rằng để đo lường mức độ dự báo bên cạnh mức độ phù hợp, các nhà nghiên cứu thường sử dụng thêm các chỉ số như R² và Q², tuy nhiên GFI và SRMR là hai chỉ số nòng cốt để kiểm định cấu trúc tổng thể.
5. Thang Đo Lường Thực Nghiệm (Measurement Scale)
Bài báo minh họa bằng dữ liệu thực tế đo lường Trí tuệ văn hóa (CQ) từ sinh viên quốc tế ở Đức (n = 195) và Bỉ (n = 85).
Bảng 2: Hệ thống Biến quan sát (Items)
| Khái niệm (Construct) | Loại biến | Ký hiệu | Nội dung câu hỏi (English) | Bản dịch gợi ý (Vietnamese) |
| Sự cởi mở (Openness) | Factor | open1 – open4 | Mini-IPIP Scale | Thang đo Mini-IPIP về Sự cởi mở |
| Sự tận tâm (Conscientiousness) | Factor | cons1 – cons3 | Mini-IPIP Scale | Thang đo Mini-IPIP về Sự tận tâm |
| Sự hướng ngoại (Extraversion) | Factor | extra1 – extra4 | Mini-IPIP Scale | Thang đo Mini-IPIP về Sự hướng ngoại |
| Sự dễ chịu (Agreeableness) | Factor | agre1 – agre4 | Mini-IPIP Scale | Thang đo Mini-IPIP về Sự dễ chịu |
| Sự ổn định cảm xúc (Emotional Stability) | Factor | emot1 – emot3 | Mini-IPIP Scale | Thang đo Mini-IPIP về Sự ổn định cảm xúc |
| Kinh nghiệm quốc tế (International Experience) | Component | inte1 – inte5 | Number of countries lived, visited, formal education | Số quốc gia đã sống, đến thăm, học tập |
| Trí tuệ văn hóa (Cultural Intelligence – CQ) | Component | cq1 – cq4 | E-CQS dimensions (Motivational, Cognitive, Behavioral, Metacognitive) | E-CQS (Động lực, Nhận thức, Hành vi, Siêu nhận thức) |
Đánh giá thực nghiệm:
- Mẫu Đức (n = 195): Đạt độ tin cậy nhất quán nội bộ (CR, Cronbach’s alpha ≥ 0.7). Đạt độ phù hợp mô hình với GFI = 0.904 và SRMR = 0.077. +1
- Mẫu Bỉ (n = 85): Độ tin cậy thấp. Mô hình thiếu sự phù hợp nghiêm trọng với GFI = 0.832 và SRMR = 0.104. Khuyến nghị không tiếp tục diễn giải mô hình với mẫu này.

6. Mạng Lưới Quan Hệ Lý Thuyết (Nomological Network)
- Tiền tố (Antecedents): 5 đặc điểm tính cách (Big Five – Factors) và Kinh nghiệm quốc tế (Components).
- Hậu tố (Consequences): Trí tuệ văn hóa (CQ – Component).
- Kết quả từ mẫu Đức: Đặc tính “Sự dễ chịu” (Agreeableness) có tác động tích cực đáng kể đến CQ. Các yếu tố khác không mang ý nghĩa thống kê trong bối cảnh mẫu sinh viên, gợi ý cần mở rộng bối cảnh nghiên cứu sang các quần thể phi sinh viên hoặc bổ sung kỹ thuật đo lường khác.
7. Hướng Dẫn Ứng Dụng Nghiên Cứu (Academic Implications)
Dành cho các nhà nghiên cứu: Cần đánh giá xem mô hình có chứa cả thành phần và yếu tố không. Nếu có, mô hình IGSCA là lựa chọn thống kê bắt buộc. +1
Dựa trên kết quả mô phỏng, dưới đây là tiêu chuẩn đánh giá độ phù hợp mô hình (Model Fit Cutoff Criteria) áp dụng riêng cho mô hình IGSCA:
Bảng 3: Tiêu chuẩn đánh giá độ phù hợp mô hình cho IGSCA
| Quy mô mẫu (Sample Size – N) | Ngưỡng cắt GFI (Goodness-of-Fit Index) | Ngưỡng cắt SRMR (Standardized Root Mean Squared Residual) | Lời khuyên cho nhà nghiên cứu |
| N = 50 | GFI ≥ 0.84 | SRMR ≤ 0.13 | Ưu tiên dùng SRMR vì GFI dễ gây lỗi loại I và II ở mẫu nhỏ (tỷ lệ lỗi SRMR là 0.034 so với GFI là 0.186). +3 |
| N = 100 | GFI ≥ 0.88 | SRMR ≤ 0.10 | Nên dùng kết hợp, nhưng SRMR vẫn đáng tin cậy hơn do giảm thiểu tỷ lệ lỗi trung bình. +1 |
| N = 200 | GFI ≥ 0.91 | SRMR ≤ 0.08 | Đạt tiêu chuẩn tối ưu cho các nghiên cứu kinh doanh thông thường. |
| N ≥ 500 | GFI ≥ 0.95 | SRMR ≤ 0.06 | Sử dụng độc lập 1 trong 2 chỉ số đều chính xác tuyệt đối và dẫn đến tỷ lệ lỗi bằng 0. |
8. Hạn Chế và Hướng Nghiên Cứu Tương Lai (Limitations & Future Research)
Bất kỳ mô hình lý thuyết nào cũng tồn tại những giới hạn nhất định:
- Hạn chế về chỉ số dự đoán: Sự phù hợp của mô hình (Model Fit) với dữ liệu mẫu không đồng nghĩa với việc mô hình có khả năng dự đoán (predictive power) cao cho các quan sát ngoài mẫu (out-of-sample). Cần kết hợp sử dụng cả thước đo phù hợp và số liệu đo lường khả năng dự đoán.
- Hạn chế về thông số mô phỏng: Nghiên cứu mô phỏng Monte-Carlo hiện tại có thể được mở rộng bằng cách điều chỉnh sự đa dạng của các ma trận hiệp phương sai và vi phạm giả định sai số đo lường (ví dụ như khi các sai số đo lường không độc lập).
- Định hướng đo lường thành phần bậc cao: Nghiên cứu tương lai nên đánh giá hiệu quả của các phương pháp trọng số chỉ báo (indicator weighting methods) khác nhau đối với cấu trúc thành phần bậc cao trong bối cảnh IGSCA.
9. Ứng Dụng Quản Trị Doanh Nghiệp (Managerial Implications)
- Thiết lập mô hình phân tích hành vi khách hàng: Khi đánh giá “Sự trung thành của khách hàng” (Component) dựa trên “Trải nghiệm thương hiệu” (Factor), đội ngũ Data Analytics của doanh nghiệp bắt buộc phải dùng mô hình IGSCA. Dùng sai thuật toán sẽ ra sai trọng số, dẫn đến chiến lược Marketing lãng phí ngân sách do dự báo sai lệch thị hiếu cốt lõi.
- Đánh giá nhân sự toàn cầu: Sử dụng thang đo CQ và mô hình thống kê chuẩn xác giúp bộ phận Nhân sự (HR) sàng lọc đúng nhân tài cho các dự án đa quốc gia, loại bỏ sai số do đánh giá định tính cảm tính.
10. Các Câu Hỏi Thường Gặp (FAQ)
Sự khác biệt cốt lõi giữa PLSPM và Mô hình IGSCA là gì?
PLSPM chỉ tối ưu cho các cấu trúc thành phần (Component-based) và gây chệch hệ số khi ước lượng biến nhân tố (Factor). Mô hình IGSCA tích hợp cả hai thuật toán, cho phép ước lượng không chệch (unbiased) trong một mô hình chứa hỗn hợp cả Factor và Component.
Khi nào thì tôi chỉ nên dùng SRMR mà không cần quan tâm đến GFI trong IGSCA?
Khi quy mô mẫu của bạn rất nhỏ (N < 200). Kết quả mô phỏng Monte-Carlo cho thấy SRMR có tỷ lệ lỗi (Error rate) thấp hơn hẳn GFI ở cỡ mẫu nhỏ, do đó đáng tin cậy hơn để phát hiện sự sai lệch.
Tôi có thể sử dụng ngưỡng cắt GFI ≥ 0.90 và SRMR ≤ 0.08 của phương pháp CB-SEM sang IGSCA không?
Tuyệt đối không. Các ngưỡng cắt truyền thống không áp dụng được cho mô hình IGSCA. Bạn phải sử dụng các ngưỡng cắt động (như GFI ≥ 0.88 cho N=100 hoặc GFI ≥ 0.91 cho N=200) được khuyến nghị trong nghiên cứu này.
11. Tài Liệu Tham Khảo (References)
- Aguinis, H., Cascio, W. F., & Ramani, R. S. (2017). Science’s reproducibility and replicability crisis: International business is not immune. Journal of International Business Studies, 48(6), 653-663.
- Aguinis, H., Ramani, R. S., & Cascio, W. F. (2020). Methodological practices in international business research… Journal of International Business Studies, 51(9), 1593-1608.
- Ang, S., & van Dyne, L. (2008). Conceptualization of cultural intelligence… In Handbook of Cultural Intelligence.
- Bollen, K. A. (1989). Structural equations with latent variables. Wiley.
- Borsboom, D., Mellenbergh, G. J., & Van Heerden, J. (2004). The concept of validity. Psychological Review, 111(4), 1061-1071.
- Cho, G., Hwang, H., Sarstedt, M., & Ringle, C. M. (2020). Cutoff criteria for overall model fit indexes in generalized structured component analysis. Journal of Marketing Analytics, 8, 189-202.
- Hwang, H., Cho, G., Jung, K., Falk, C. F., Flake, J., & Jin, M. J. (2021). An approach to structural equation modeling with both factors and components: Integrated generalized structured component analysis. Psychological Methods, 26(3), 273-294.
12. Lời Kêu Gọi Hành Động (CTA)
Việc hiểu sâu bản chất thống kê của mô hình IGSCA là bước đệm thiết yếu để các nghiên cứu Quản trị kinh doanh vươn tầm xuất bản quốc tế (Q1/Q2 ISI/Scopus). Đừng để việc chỉ định sai mô hình phá hỏng toàn bộ dữ liệu khảo sát giá trị của bạn. Hãy nhấp vào liên kết bên dưới để tải toàn văn bài báo gốc nhằm đi sâu vào các công thức đạo hàm và ứng dụng ngay vào phần mềm nghiên cứu.
Cho, G., Schlaegel, C., Hwang, H., Choi, Y., Sarstedt, M., & Ringle, C. M. (2022). Integrated generalized structured component analysis: On the use of model fit criteria in international management research. Management International Review, 62(4), 569–609.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



