
Biến tiềm ẩn bậc cao (Higher-Order Constructs – HOC) là kỹ thuật mô hình hóa các khái niệm trừu tượng đa chiều trong PLS-SEM thông qua các thành phần con cụ thể (LOC). Vấn đề cốt lõi khiến các nghiên cứu thất bại thường nằm ở sự nhầm lẫn trong quy trình xác định và ước lượng tham số, dẫn đến sai lệch về độ tin cậy. Giải pháp tối ưu được Sarstedt và cộng sự (2019) khuyến nghị là sử dụng Phương pháp Lặp chỉ báo mở rộng (Extended Repeated Indicators) để giảm thiểu sai số đo lường hoặc Phương pháp Hai giai đoạn (Two-Stage Approach) để đánh giá chính xác mô hình cấu trúc.

1. Tổng Quan & Lý Thuyết Nền Tảng (Overview & Theoretical Foundations)
1.1 Thông tin định danh bài báo
- Tiêu đề gốc: How to specify, estimate, and validate higher-order constructs in PLS-SEM
- Tiêu đề tiếng Việt: Cách xác định, ước lượng và kiểm định các khái niệm bậc cao trong PLS-SEM
- Tác giả: Marko Sarstedt, Joseph F. Hair Jr, Jun-Hwa Cheah, Jan-Michael Becker, Christian M. Ringle
- Tạp chí: Australasian Marketing Journal (2019)
Biến tiềm ẩn bậc cao (Higher-Order Constructs – HOC), hay còn gọi là mô hình thành phần phân cấp (Hierarchical Component Models – HCM), là một cấu trúc trừu tượng phức tạp được đo lường thông qua các thành phần con cụ thể hơn (Lower-Order Components – LOC). Chúng cho phép các nhà nghiên cứu mô hình hóa một khái niệm ở cấp độ trừu tượng cao hơn (thành phần bậc cao – ví dụ: Sự hài lòng tổng thể) và các khía cạnh cụ thể của nó (thành phần bậc thấp – ví dụ: Hài lòng về giá, Hài lòng về dịch vụ). Việc sử dụng HOC giúp nắm bắt được bản chất đa chiều của các khái niệm tâm lý xã hội mà một biến đơn lẻ không thể đo lường hết được.
Vấn đề cốt lõi mà các nhà nghiên cứu thường gặp phải là sự nhầm lẫn nghiêm trọng trong quy trình ba bước: xác định (specification), ước lượng (estimation) và kiểm định (validation) HOC. Những sai sót này thường dẫn đến việc sử dụng sai thuật toán (Mode A vs Mode B), hoặc sai lầm trong việc đánh giá độ tin cậy và giá trị hội tụ (ví dụ: đánh giá HOC dựa trên các chỉ báo lặp lại thay vì đánh giá mối quan hệ giữa HOC và LOC). Giải pháp tối ưu và chuẩn xác nhất được đề xuất trong bài báo là sử dụng phương pháp lặp chỉ báo mở rộng (Extended Repeated Indicators Approach) để xử lý các biến nội sinh, hoặc phương pháp hai giai đoạn (Two-Stage Approach) để đánh giá mô hình cấu trúc.
1.2. Lợi ích cốt lõi của việc sử dụng HOC
Tại sao chúng ta nên phức tạp hóa mô hình bằng HOC thay vì giữ nguyên các cấu trúc bậc một đơn giản? Dựa trên phân tích sâu từ tài liệu gốc, việc sử dụng HOC mang lại 3 lợi ích chiến lược và thực tiễn:
- Sự tối giản mô hình (Model Parsimony): HOC giúp giảm đáng kể số lượng các mối quan hệ đường dẫn (path relationships) trong mô hình cấu trúc. Thay vì phải vẽ hàng loạt mũi tên từ 5-6 biến con đến biến phụ thuộc (tạo ra một “mạng nhện” các giả thuyết), ta chỉ cần một mũi tên duy nhất từ biến bậc cao. Điều này giúp mô hình gọn gàng, tăng bậc tự do (degrees of freedom) và giúp việc diễn giải kết quả trở nên tập trung hơn vào các khái niệm cốt lõi.
- Khắc phục nghịch lý “Băng thông – Độ trung thực” (Bandwidth-Fidelity Dilemma): Đây là sự đánh đổi kinh điển trong đo lường: “Băng thông” là độ bao phủ rộng của thông tin, còn “Độ trung thực” là sự chính xác chi tiết. Các biến bậc thấp cung cấp độ trung thực cao nhưng phạm vi hẹp. HOC cho phép cân bằng điều này bằng cách vừa nắm bắt được khái niệm rộng (ở cấp độ bậc cao) để đảm bảo băng thông, vừa đo lường được chi tiết cụ thể (ở cấp độ bậc thấp) để đảm bảo độ trung thực.
- Giảm đa cộng tuyến (Collinearity Reduction): Trong các mô hình sử dụng chỉ báo nguyên nhân (formative indicators), hiện tượng đa cộng tuyến giữa các biến độc lập thường rất cao, gây sai lệch trọng số. HOC cung cấp phương tiện để giảm đa cộng tuyến bằng cách sắp xếp lại các chỉ báo/biến này vào các chiều hướng con cụ thể, tách biệt phương sai của chúng, từ đó giúp các ước lượng thống kê trở nên ổn định và tin cậy hơn.
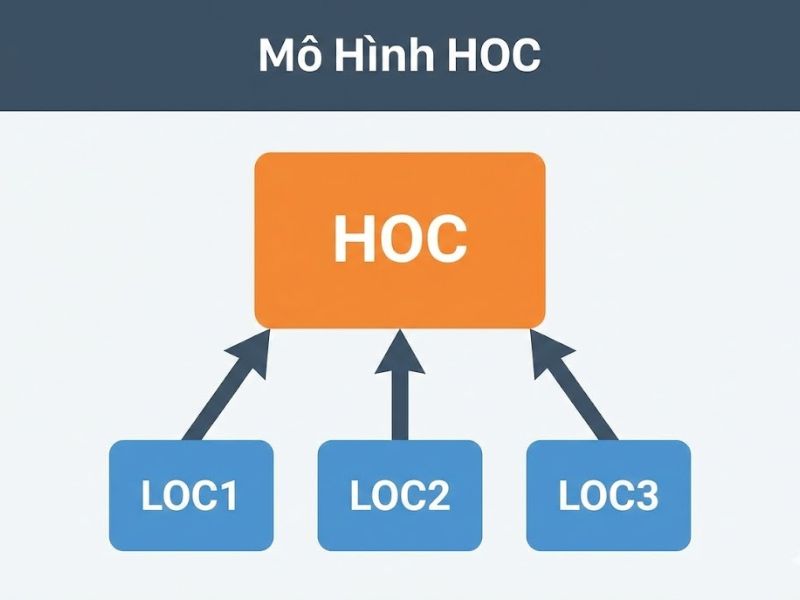
2. Phân Loại Cấu Trúc Khái Niệm Bậc Cao (Specification)
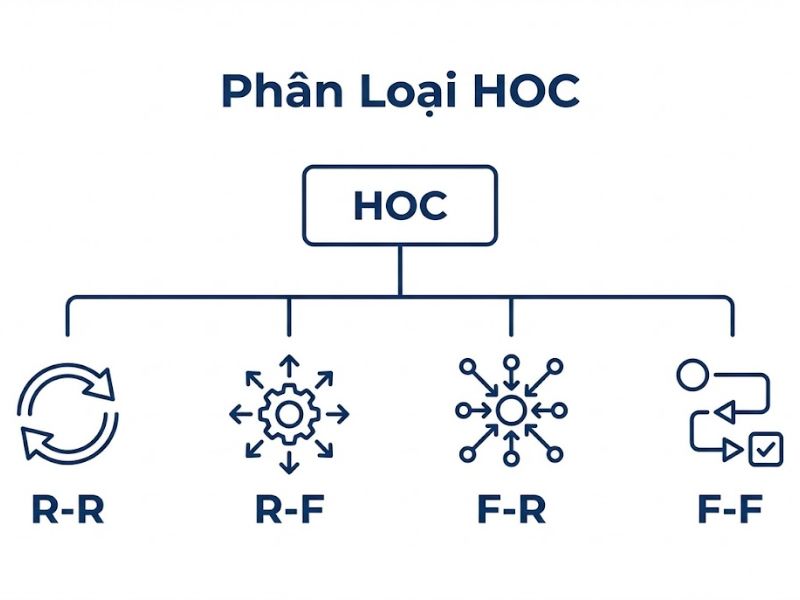
Để xác định đúng HOC, nhà nghiên cứu không được tùy ý lựa chọn mà cần dựa trên nền tảng lý thuyết đo lường (Measurement Theory) để quyết định mối quan hệ giữa Biến bậc cao (HOC) và Biến bậc thấp (LOC). Có 4 loại mô hình HOC cơ bản dựa trên sự kết hợp của hai mối quan hệ (LOC-Indicators và HOC-LOC), như mô tả trong Hình 1 của tài liệu gốc:
- Loại I: Phản ánh – Phản ánh (Reflective-Reflective): Đây là dạng phổ biến nhất. Ở cấp độ dưới, các chỉ báo phản ánh LOC. Ở cấp độ trên, các LOC phản ánh HOC.
- Bản chất: Các LOC là sự biểu hiện cụ thể của HOC. Ví dụ: Nếu “Sức khỏe thương hiệu” (HOC) tăng lên, thì cả “Nhận biết” và “Hình ảnh” (LOCs) đều sẽ tăng theo. Các LOC có tương quan mạnh với nhau.
- Loại II: Phản ánh – Cấu tạo (Reflective-Formative): Ở cấp độ dưới, các chỉ báo phản ánh LOC. Nhưng ở cấp độ trên, các LOC kết hợp lại để tạo thành (form) HOC.
- Bản chất: HOC là tổng hợp đại số của các LOC. Ví dụ: “Chất lượng dịch vụ” (HOC) được tạo thành bởi “Chất lượng kỹ thuật” và “Chất lượng chức năng”. Việc thay đổi một LOC không nhất thiết làm thay đổi các LOC khác.
- Loại III: Cấu tạo – Phản ánh (Formative-Reflective): Ở cấp độ dưới, các chỉ báo tạo thành LOC. Ở cấp độ trên, các LOC phản ánh HOC.
- Bản chất: Loại này rất hiếm gặp trong thực tế nghiên cứu.
- Loại IV: Cấu tạo – Cấu tạo (Formative-Formative): Cả hai cấp độ đều là quan hệ nguyên nhân (formative).
- Bản chất: Thường dùng cho các chỉ số tổng hợp phức tạp (composite indices), ví dụ như chỉ số năng lực cạnh tranh quốc gia, nơi các biến thành phần đóng góp vào chỉ số chung nhưng không nhất thiết có tương quan với nhau.
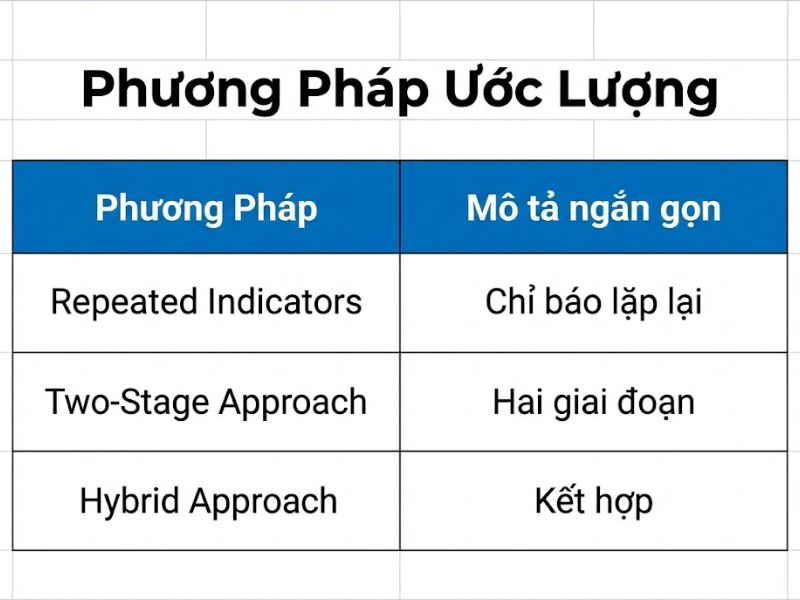
3. Các Phương Pháp Ước Lượng HOC Trong PLS-SEM (Estimation)
Sarstedt và cộng sự (2019) nhấn mạnh rằng việc lựa chọn phương pháp ước lượng sai sẽ dẫn đến sai lệch tham số. Dưới đây là các phương pháp xử lý HOC trong phần mềm SmartPLS:
3.1. Phương pháp Lặp chỉ báo (Repeated Indicators Approach)
- Cơ chế: Tất cả các chỉ báo của các biến con (LOC) được gán lại (lặp lại) cho biến cha (HOC). Ví dụ: Nếu LOC_1 có chỉ báo x1, x2, x3 và LOC_2 có x4, x5, x6, thì HOC sẽ được đo lường bởi toàn bộ tập hợp x1 đến x6.
- Ưu điểm: Dễ thực hiện, ước lượng tốt các tham số của mô hình đo lường (loadings/weights giữa HOC và LOC).
- Hạn chế nghiêm trọng: Khi HOC là biến nội sinh (biến phụ thuộc) trong mô hình đường dẫn, phương sai của nó được giải thích gần như hoàn toàn bởi các LOC (vì chúng dùng chung tập chỉ báo). Điều này dẫn đến R bình phương (R²) ≈ 1.0. Hệ quả là các đường dẫn từ các biến tiền đề (antecedents) khác đến HOC sẽ bị “triệt tiêu” về 0 và không có ý nghĩa thống kê, dẫn đến kết luận sai lầm rằng các biến tiền đề không tác động đến HOC.
3.2. Phương pháp Lặp chỉ báo Mở rộng (Extended Repeated Indicators Approach)
- Giải pháp cho vấn đề R²=1: Becker và cộng sự (2012) đề xuất phương pháp “Mở rộng”. Thay vì chỉ xét mối quan hệ trực tiếp (vốn bị ước lượng bằng 0), nhà nghiên cứu phải thiết lập mô hình bằng cách vẽ thêm các đường dẫn từ khái niệm tiền đề (Y5) đến tất cả các thành phần bậc thấp (Y1-Y3) của HOC.
- Cách đọc kết quả: Nhà nghiên cứu không được đọc hệ số đường dẫn trực tiếp (Direct Effect). Thay vào đó, phải phân tích Tác động tổng hợp (Total Effects) của khái niệm tiền đề lên HOC. Tác động tổng hợp này bao gồm cả tác động gián tiếp đi qua các LOC, phản ánh chính xác bức tranh thực tế về mối quan hệ nhân quả.
3.3. Phương pháp Hai giai đoạn (Two-Stage Approach)
Đây là phương pháp thay thế ưu việt khi mô hình phức tạp hoặc khi muốn thực hiện các đánh giá dự báo. Có hai biến thể chính:
- Phương pháp Hai giai đoạn Nhúng (Embedded Two-Stage):
- Giai đoạn 1: Chạy mô hình lặp chỉ báo, sau đó lưu lại Điểm số biến tiềm ẩn (Latent Variable Scores – LVS) của các LOC.
- Giai đoạn 2: Xây dựng lại mô hình. Lúc này, HOC được đo lường bằng các chỉ báo đơn (single items), chính là các điểm số LVS đã lưu từ giai đoạn 1.
- Phương pháp Hai giai đoạn Tách rời (Disjoint Two-Stage):
- Giai đoạn 1: Chỉ chạy mô hình với các LOC (xóa bỏ hoàn toàn HOC khỏi mô hình). Liên kết trực tiếp các biến tiền đề với các LOC. Sau đó, lưu điểm số LVS của các LOC.
- Giai đoạn 2: Tạo biến HOC và sử dụng điểm số LVS của LOC (từ giai đoạn 1) để làm chỉ báo cho nó. Tuy nhiên, điểm khác biệt quan trọng là: Các biến khác trong mô hình vẫn giữ nguyên là thước đo đa mục (multi-item measures) chứ không chuyển thành chỉ báo đơn như phương pháp Nhúng.
- Ưu điểm: Phương pháp Tách rời cho phép đánh giá đầy đủ các tiêu chí của mô hình cấu trúc (như f^2, Q^2, PLSpredict) chính xác hơn phương pháp Nhúng, vì nó bảo toàn được phương sai của các biến khác.
3.4. Cài đặt Thuật toán (Algorithm Settings)
Việc chọn sai chế độ (Mode) ước lượng là lỗi kỹ thuật phổ biến nhất. Hãy tuân thủ quy tắc sau:
- Quy tắc Mode:
- Dùng Mode A (Correlation weights) cho HOC dạng Phản ánh (Reflective).
- Dùng Mode B (Regression weights) cho HOC dạng Cấu tạo (Formative).
- Lưu ý đặc biệt: Kể cả khi các chỉ báo lặp lại là Reflective, nhưng nếu mối quan hệ giữa HOC và LOC là Formative (tức là LOC tạo nên HOC – Loại II), bạn bắt buộc phải chuyển chế độ của HOC sang Mode B.
- Cơ chế trọng số: Khuyến nghị luôn sử dụng Path Weighting Scheme làm mặc định để tối ưu hóa giá trị R² cho các biến nội sinh.
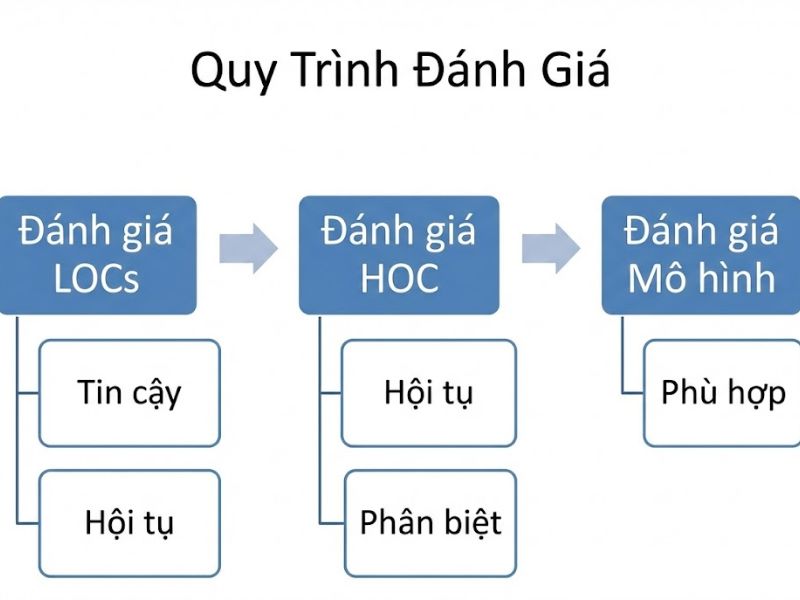
4. Quy Trình Kiểm Định & Đánh Giá (Validation Guidelines)
Việc kiểm định HOC đòi hỏi sự cẩn trọng và quy trình khắt khe hơn biến thông thường. Quy trình bao gồm 2 cấp độ riêng biệt:
4.1. Cấp độ 1: Đánh giá các thành phần bậc thấp (LOCs)
Trước tiên, phải đảm bảo các LOC đạt chuẩn về độ tin cậy và giá trị như một biến thông thường. Nếu LOC không đạt, HOC sẽ vô nghĩa.
- Độ tin cậy nhất quán nội bộ: Cronbach’s Alpha, Composite Reliability (CR).
- Giá trị hội tụ: AVE > 0.5.
- Giá trị phân biệt: HTMT < 0.85 (hoặc 0.90).
4.2. Cấp độ 2: Đánh giá thành phần bậc cao (HOC)
(Lưu ý: Không đánh giá HOC dựa trên các chỉ báo lặp lại (items), mà phải dựa trên mối quan hệ giữa HOC và LOC)
- Đối với mô hình Phản ánh – Phản ánh (Reflective-Reflective):
- Coi các LOC như là các “items” của HOC.
- Tính toán thủ công: Phần mềm SmartPLS sẽ tính toán dựa trên các chỉ báo lặp lại, điều này không chính xác. Bạn cần tính tay các chỉ số:
- AVE = (Σ λ²) / M (với λ là hệ số tải của LOC lên HOC, M là số lượng LOC).
- CR = (Σ λ)² / [ (Σ λ)² + Σ(1 – λ²) ].
- Giá trị phân biệt (Discriminant Validity): Phải đánh giá HOC như một tổng thể với các biến khác trong mô hình (lưu ý: không bao gồm các LOC của chính nó trong phép so sánh này vì chúng chắc chắn có tương quan cao).
- Đối với mô hình Phản ánh – Cấu tạo (Reflective-Formative):
- Giá trị hội tụ: Thực hiện Phân tích dư thừa (Redundancy Analysis). Sử dụng một biến đơn (Global single item) đo lường khái niệm chung, cho HOC tác động lên biến đơn này. Hệ số đường dẫn phải >= 0.70.
- Đa cộng tuyến: Kiểm tra hệ số phóng đại phương sai (VIF) giữa các LOC. Ngưỡng an toàn là VIF < 3.0 (hoặc tối đa là 5.0).
- Trọng số (Weights): Kiểm tra độ lớn và mức ý nghĩa thống kê (p-value < 0.05) của đường dẫn từ LOC-> HOC. Nếu trọng số không có ý nghĩa, cần kiểm tra hệ số tải (loading) trước khi quyết định loại bỏ.
- Lưu ý quan trọng về mô hình cấu trúc:
- Khi sử dụng phương pháp Hai giai đoạn Nhúng (Embedded), các đánh giá như Blindfolding hay PLSpredict nên thực hiện ở Giai đoạn 1 để đảm bảo độ chính xác.
- Phương pháp Hai giai đoạn Tách rời (Disjoint) cho phép thực hiện tất cả các đánh giá cấu trúc này ở Giai đoạn 2 một cách bình thường.
5. Minh Họa Thực Nghiệm: Mô Hình Danh Tiếng Doanh Nghiệp
Để minh họa cho các nguyên tắc trên, bài báo sử dụng mô hình Danh tiếng Doanh nghiệp (REPU) được cấu thành từ 2 biến con: Năng lực (COMP) và Sự yêu thích (LIKE), chịu tác động bởi 4 biến tiền đề (Chất lượng, Hiệu quả, Trách nhiệm xã hội, Sự hấp dẫn).
5.1. Kết quả từ Phương pháp Lặp chỉ báo (Reflective-Reflective)
- Hệ số tải (Loadings): Kết quả phân tích cho thấy đường dẫn từ REPU xuống COMP là 0.897 và xuống LIKE là 0.927. Các hệ số này rất cao, chứng tỏ hai thành phần này phản ánh mạnh mẽ khái niệm danh tiếng.
- Độ tin cậy (Tính toán thủ công):
- AVE_{REPU} = (0.897^2 + 0.927^2) / 2 = 0.832$ (Vượt xa ngưỡng yêu cầu 0.5).
- Độ tin cậy tổng hợp (CR) = 0.908.
- Giá trị phân biệt: Chỉ số HTMT giữa REPU và các biến khác (như CUSA, CUSL) đều dưới ngưỡng bảo thủ 0.85, xác nhận tính phân biệt của HOC.
5.2. Kết quả từ Phương pháp Lặp chỉ báo Mở rộng (Reflective-Formative)
- Trong trường hợp giả định REPU là biến Formative được tạo bởi COMP và LIKE.
- Nếu chạy mô hình chuẩn (Standard Repeated Indicators), $R^2$ của REPU xấp xỉ 1.0, và các biến tiền đề (QUAL, PERF…) đều có hệ số đường dẫn gần bằng 0 và không có ý nghĩa. Đây là sai lệch do phương pháp.
- Khi chạy phương pháp Mở rộng (xét Total Effects): Kết quả thay đổi hoàn toàn. Phát hiện ra rằng Chất lượng (QUAL) có tác động tổng hợp mạnh nhất lên Danh tiếng (0.432), theo sau là Trách nhiệm xã hội (CSOR – 0.223) và Sự hấp dẫn (ATTR – 0.192). Điều này chứng minh tầm quan trọng của việc sử dụng đúng phương pháp để không bỏ sót các phát hiện quan trọng.
6. Bảng Checklist Dành Cho Nhà Nghiên Cứu (Structured Data)
Dưới đây là bảng tổng hợp các khuyến nghị kỹ thuật (Checklist) được trích xuất và hệ thống hóa từ Bảng 7 của tài liệu gốc. Đây là công cụ đối chiếu thiết yếu để đảm bảo nghiên cứu của bạn đạt chuẩn khoa học:
| Tiêu chí | Khuyến nghị thực hiện (Best Practices) |
| Xác định (Specification) | – Nếu HOC là ngoại sinh (biến độc lập): Dùng phương pháp Lặp chỉ báo (để tối ưu tham số đo lường) hoặc Hai giai đoạn (để tối ưu tham số cấu trúc).- Nếu HOC là nội sinh (biến phụ thuộc): Bắt buộc dùng Lặp chỉ báo Mở rộng hoặc Hai giai đoạn (đặc biệt cho loại Formative) để tránh lỗi R²=1. |
| Ước lượng (Estimation) | – HOC dạng Phản ánh (Type I, III): Cài đặt thuật toán là Mode A.- HOC dạng Cấu tạo (Type II, IV): Cài đặt thuật toán là Mode B (bất kể chỉ báo con là gì).- Cơ chế trọng số: Luôn sử dụng Path Weighting Scheme. |
| Đánh giá Đo lường (Measurement) | – Đánh giá LOC trước theo tiêu chuẩn thông thường (Alpha, CR, AVE).- Diễn giải quan hệ HOC-LOC như là mô hình đo lường của HOC.- Với Reflective HOC: Tính thủ công AVE, CR; Kiểm tra HTMT.- Với Formative HOC: Kiểm tra VIF (Collinearity), Độ lớn và ý nghĩa của Trọng số (Weights), Phân tích dư thừa (Redundancy). |
| Đánh giá Cấu trúc (Structural) | – Không coi LOC là phần tử của mô hình cấu trúc.- Nếu dùng Lặp chỉ báo Mở rộng: Phải báo cáo và diễn giải Tác động tổng hợp (Total Effects) thay vì tác động trực tiếp. |
7. Ứng Dụng Thực Tiễn (Managerial Applications)
Việc sử dụng các khái niệm bậc cao (HOC) giúp nâng cao tính trừu tượng và sự tối giản cho mô hình nghiên cứu, giải quyết triệt để vấn đề “băng thông – độ trung thực”.
- Về mặt học thuật: HOC cho phép các nhà nghiên cứu xây dựng các khung lý thuyết phức tạp hơn nhưng vẫn giữ được sự gọn gàng (parsimony). Nó đặc biệt hữu ích khi nghiên cứu các khái niệm vĩ mô (như Thành quả doanh nghiệp, Định hướng thị trường) vốn được cấu thành từ nhiều khía cạnh nhỏ.
- Về mặt quản trị doanh nghiệp: HOC cung cấp cái nhìn tổng thể cho các nhà quản lý (C-level). Ví dụ, thay vì báo cáo 10 chỉ số rời rạc, bộ phận Marketing có thể tổng hợp thành một chỉ số “Sức khỏe thương hiệu” (HOC). Tuy nhiên, khi cần hành động cụ thể, họ có thể “khoan sâu” xuống các biến LOC (ví dụ: cải thiện “Hình ảnh” hay “Nhận biết”).
8. Lời kết
Tuy nhiên, nhà nghiên cứu cần phân biệt rõ ràng giữa các phương pháp ước lượng (Lặp chỉ báo vs Hai giai đoạn) và tuân thủ nghiêm ngặt quy trình kiểm định riêng biệt cho HOC. Việc áp dụng sai phương pháp (ví dụ: dùng Mode A cho Formative HOC, hay quên tính Total Effects) có thể dẫn đến việc kết quả nghiên cứu bị sai lệch hoàn toàn.
9. Tài liệu tham khảo
Dưới đây là danh sách toàn bộ tài liệu tham khảo từ bài báo gốc, được định dạng lại theo chuẩn APA 7th Edition (American Psychological Association).
Agarwal, R., & Karahanna, E. (2000). Time flies when you’re having fun: Cognitive absorption and beliefs about information technology usage. MIS Quarterly, 24(4), 665–694.
Aguirre-Urreta, M. J., & Rönkkö, M. (2018). Statistical inference with PLSc using bootstrap confidence intervals. MIS Quarterly, 42(3), 1001–1020.
Becker, J.-M., Klein, K., & Wetzels, M. (2012). Hierarchical latent variable models in PLS-SEM: Guidelines for using reflective-formative type models. Long Range Planning, 45(5-6), 359–394.
Becker, J.-M., Ringle, C. M., & Sarstedt, M. (2018). Estimating moderating effects in PLS-SEM and PLSc-SEM: Interaction term generation data treatment. Journal of Applied Structural Equation Modeling, 2(2), 1–21.
Cass, A. O. (2001). Consumer self-monitoring, materialism and involvement in fashion clothing. Australasian Marketing Journal, 9(1), 46–60.
Cheah, J.-H., Sarstedt, M., Ringle, C. M., Ramayah, T., & Ting, H. (2018). Convergent validity assessment of formatively measured constructs in PLS-SEM: On using single-item versus multi-item measures in redundancy analyses. International Journal of Contemporary Hospitality Management, 30(11), 3192–3210.
Cheah, J.-H., Ting, H., Ramayah, T., Memon, M. A., Cham, T.-H., & Ciavolino, E. (2019). A comparison of five reflective-formative estimation approaches: Reconsideration and recommendations for tourism research. Quality & Quantity, 53, 1421–1458.
Chin, W. W. (1998). The partial least squares approach to structural equation modeling. In G. A. Marcoulides (Ed.), Modern methods for business research (pp. 295–336). Erlbaum.
Chin, W. W. (2010a). Bootstrap cross-validation indices for PLS path model assessment. In V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of partial least squares: Concepts, methods and applications (pp. 83–97). Springer.
Chin, W. W. (2010b). How to write up and report PLS analyses. In V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of partial least squares: Concepts, methods and applications (pp. 655–690). Springer.
Cronbach, L. J., & Gleser, G. C. (1965). Psychological tests and personnel decisions. University of Illinois Press.
Danks, N. P., & Ray, S. (2018). Predictions from partial least squares models. In F. Ali, S. M. Rasoolimanesh, & C. Cobanoglu (Eds.), Applying partial least squares in tourism and hospitality research (pp. 35–52). Emerald Publishing.
DeVellis, R. F. (2016). Scale development: Theory and applications (4th ed.). Sage.
Dijkstra, T. K., & Henseler, J. (2015). Consistent partial least squares path modeling. MIS Quarterly, 39(2), 297–316.
Eberl, M. (2010). An application of PLS in multi-group analysis: The need for differentiated corporate-level marketing in the mobile communications industry. In V. E. Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of partial least squares: Concepts, methods and applications (pp. 487–514). Springer.
Edwards, J. R. (2001). Multidimensional constructs in organizational behavior research: An integrative analytical framework. Organizational Research Methods, 4(2), 144–192.
Fink, A. (2017). How to conduct surveys: A step-by-step guide (6th ed.). Sage.
Franke, G. R., & Sarstedt, M. (2019). Heuristics versus statistics in discriminant validity testing: A comparison of four procedures. Internet Research. Advance online publication.
Gudergan, S. P., Ringle, C. M., Wende, S., & Will, A. (2008). Confirmatory tetrad analysis in PLS path modeling. Journal of Business Research, 61(12), 1238–1249.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2017a). A primer on partial least squares structural equation modeling (PLS-SEM) (2nd ed.). Sage.
Hair, J. F., Hult, G. T. M., Ringle, C. M., Sarstedt, M., & Thiele, K. O. (2017b). Mirror, mirror on the wall: A comparative evaluation of composite-based structural equation modeling methods. Journal of the Academy of Marketing Science, 45(5), 616–632.
Hair, J. F., Risher, J. J., Sarstedt, M., & Ringle, C. M. (2019). When to use and how to report the results of PLS-SEM. European Business Review, 31(1), 2–24.
Hair, J. F., Sarstedt, M., Ringle, C. M., & Gudergan, S. P. (2018). Advanced issues in partial least squares structural equation modeling (PLS-SEM). Sage.
Harrigan, P., Soutar, G., Choudhury, M. M., & Lowe, M. (2015). Modelling CRM in a social media age. Australasian Marketing Journal, 23(1), 27–37.
Henseler, J., Ringle, C. M., & Sarstedt, M. (2015). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115–135.
Hourigan, S. R., & Bougoure, U.-S. (2012). Towards a better understanding of fashion clothing involvement. Australasian Marketing Journal, 20(2), 127–135.
Hult, G. T. M., Hair, J. F., Proksch, D., Sarstedt, M., Pinkwart, A., & Ringle, C. M. (2018). Addressing endogeneity in international marketing applications of partial least squares structural equation modeling. Journal of International Marketing, 26(3), 1–21.
Hwang, H., & Takane, Y. (2014). Generalized structured component analysis: A component-based approach to structural equation modeling. Chapman and Hall/CRC.
Jarvis, C. B., MacKenzie, S. B., & Podsakoff, P. M. (2003). A critical review of construct indicators and measurement model misspecification in marketing and consumer research. Journal of Consumer Research, 30(2), 199–218.
Johnson, R. E., Rosen, C. C., & Chang, C.-H. (2011). To aggregate or not to aggregate: Steps for developing and validating higher-order multidimensional constructs. Journal of Business and Psychology, 26, 241–248.
Koryigit, O., & Ringle, C. M. (2011). The impact of brand confusion on sustainable brand satisfaction and private label proneness: A subtle decay of brand equity. Journal of Brand Management, 19, 195–212.
Latan, H., & Noonan, R. (Eds.). (2017). Partial least squares structural equation modeling: Basic concepts, methodological issues and applications. Springer.
Lohmöller, J.-B. (1989). Latent variable path modeling with partial least squares. Springer-Verlag.
Matthews, L., Sarstedt, M., Hair, J. F., & Ringle, C. M. (2016). Identifying and treating unobserved heterogeneity with FIMIX-PLS: Part II—A case study. European Business Review, 28(2), 208–224.
Nitzl, C., Roldán, J. L., & Cepeda Carrión, G. (2016). Mediation analysis in partial least squares path modeling: Helping researchers discuss more sophisticated models. Industrial Management & Data Systems, 116(9), 1849–1864.
Patel, V. K., Manley, S. C., Hair, J. F., Ferrell, O. C., & Pieper, T. M. (2016). Is stakeholder orientation relevant for European firms? European Management Journal, 34(6), 650–660. https://doi.org/10.1016/j.emj.2016.07.001
Polites, G. L., Roberts, N., & Thatcher, J. (2012). Conceptualizing models using multidimensional constructs: A review and guidelines for their use. European Journal of Information Systems, 21, 22–48.
Radomir, L., & Wilson, A. (2018). Corporate reputation: The importance of service quality and relationship investment. In N. K. Avkiran & C. M. Ringle (Eds.), Partial least squares structural equation modeling: Recent advances in banking and finance (pp. 77–123). Springer.
Raithel, S., & Schwaiger, M. (2015). The effects of corporate reputation perceptions of the general public on shareholder value. Strategic Management Journal, 36, 945–956.
Ramayah, T., Cheah, J.-H., Chuah, F., Ting, H., & Memon, M. A. (2016). Partial least squares structural equation modeling (PLS-SEM) using SmartPLS 3.0: An updated and practical guide to statistical analysis (2nd ed.). Pearson.
Relling, M., Schnittka, O., Ringle, C. M., Sattler, H., & Johnen, M. (2016). Community members perception of brand community character: Construction and validation of a new scale. Journal of Interactive Marketing, 36, 107–120.
Ringle, C. M., & Sarstedt, M. (2016). Gain more insight from your PLS-SEM results: The importance-performance map analysis. Industrial Management & Data Systems, 116(9), 1865–1886.
Ringle, C. M., Sarstedt, M., Mitchell, R., & Gudergan, S. P. (2019). Partial least squares structural equation modeling in HRM research. The International Journal of Human Resource Management. Advance online publication.
Ringle, C. M., Sarstedt, M., & Straub, D. W. (2012). Editor’s comments: A critical look at the use of PLS-SEM in MIS Quarterly. MIS Quarterly, 36(1), iii–xiv.
Ringle, C. M., Wende, S., & Becker, J.-M. (2015). SmartPLS 3 [Computer software]. SmartPLS. http://www.smartpls.com
Sarstedt, M., & Mooi, E. A. (2019). A concise guide to market research: The process, data, and methods using IBM SPSS Statistics (3rd ed.). Springer.
Sarstedt, M., Ringle, C. M., Cheah, J.-H., Ting, H., Moisescu, O. I., & Radomir, L. (2019). Structural model robustness checks in PLS-SEM. Tourism Economics. Advance online publication.
Sarstedt, M., Ringle, C. M., & Hair, J. F. (2017). Partial least squares structural equation modeling. In C. Homburg, M. Klarmann, & A. Vomberg (Eds.), Handbook of market research. Springer.
Sarstedt, M., Wilczynski, P., & Melewar, T. (2013). Measuring reputation in global markets—A comparison of reputation measures’ convergent and criterion validities. Journal of World Business, 48(3), 329–339.
Schwaiger, M. (2004). Components and parameters of corporate reputation. Schmalenbach Business Review, 56, 46–71.
Sharma, P. N., Shmueli, G., Sarstedt, M., Danks, N., & Ray, S. (2019). Prediction-oriented model selection in partial least squares path modeling. Decision Sciences. Advance online publication.
Shmueli, G., Ray, S., Velasquez Estrada, J. M., & Chatla, S. B. (2016). The elephant in the room: Evaluating the predictive performance of PLS models. Journal of Business Research, 69(10), 4552–4564.
Shmueli, G., Sarstedt, M., Hair, J. F., Cheah, J.-H., Ting, H., Vaithilingam, S., & Ringle, C. M. (2019). Predictive model assessment in PLS-SEM: Guidelines for using PLSpredict. European Journal of Marketing. Advance online publication.
Van Riel, A. C., Henseler, J., Kemény, I., & Sasovova, Z. (2017). Estimating hierarchical constructs using consistent partial least squares: The case of second-order composites of common factors. Industrial Management & Data Systems, 117(3), 459–477.
Voorhees, C. M., Brady, M. K., Calantone, R., & Ramirez, E. (2016). Discriminant validity testing in marketing: An analysis, causes for concern, and proposed remedies. Journal of the Academy of Marketing Science, 44, 119–134.
Wetzels, M., Odekerken-Schröder, G., & Van Oppen, C. (2009). Using PLS path modeling for assessing hierarchical construct models: Guidelines and empirical illustration. MIS Quarterly, 33(1), 177–195.
Wold, H. O. A. (1982). Soft modeling: The basic design and some extensions. In K. G. Jöreskog & H. O. A. Wold (Eds.), Systems under indirect observation: Causality, structure, prediction (Part II, pp. 1–54). North Holland.
Để hiểu sâu hơn về các số liệu tính toán mẫu và hướng dẫn thực hành trên SmartPLS, bạn nên tham khảo tài liệu gốc dưới đây.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



