
Mô hình Composites of Composites là một cấu trúc bậc hai phức tạp (Type IV), nơi cả biến tiềm ẩn bậc cao (HOC) và bậc thấp (LOC) đều được thiết kế dưới dạng biến tổ hợp (emergent variables). Nghiên cứu của Schuberth, Rademaker và Henseler (2020) khẳng định rằng các phương pháp truyền thống (như Lặp lại chỉ báo Mode A) thường gây ra sai số nghiêm trọng và bỏ qua bước đánh giá sự phù hợp tổng thể (Overall Model Fit).
Sử dụng phương pháp Hai giai đoạn (Two-stage approach) kết hợp với quy trình Kiểm định sự phù hợp hai bước (Two-step testing procedure). Đây là phương pháp duy nhất đảm bảo tính nhất quán Fisher (Fisher consistency) và giúp nhà nghiên cứu phát hiện các mô hình bị chỉ định sai (misspecified models).

1. Tổng quan & Lý thuyết nền tảng (Overview & Theoretical Foundations)
1.1. Thông tin định danh và Giá trị học thuật
Nghiên cứu này không chỉ là một bài báo kỹ thuật mà là một sự “sửa sai” cho các thực hành PLS-PM phổ biến nhưng thiếu chính xác trước đây.
- Tác giả: Florian Schuberth, Manuel Elias Rademaker, Jörg Henseler (Nhóm tác giả tiên phong về Confirmatory Composite Analysis).
- Nguồn: Industrial Management & Data Systems (2020).
- Vấn đề nghiên cứu: Đa số các hướng dẫn SEM hiện nay tập trung vào mô hình Nhân tố (Factor models) hoặc mô hình Kết quả (Reflective). Có rất ít hướng dẫn chuẩn xác cho mô hình mà bản chất của nó là sự “tổng hợp” ở cả hai cấp độ (Composite of Composites).
1.2. Sự dịch chuyển từ Factor sang Composite trong SEM
Để hiểu bài báo, cần phân biệt rõ hai trường phái tư duy trong SEM:
- Trường phái 1: Mô hình Nhân tố chung (Common Factor Model / Reflective)
- Triết lý: Biến tiềm ẩn là thực thể có thật (ví dụ: “Trí thông minh”). Các biến quan sát (điểm thi toán, văn) chỉ là sự phản ánh của nó.
- Toán học: $x_i = \lambda_i \xi + \epsilon_i$ (Biến quan sát = Hệ số tải $\times$ Biến tiềm ẩn + Sai số).
- Hệ quả: Các biến quan sát bắt buộc phải có tương quan mạnh với nhau.
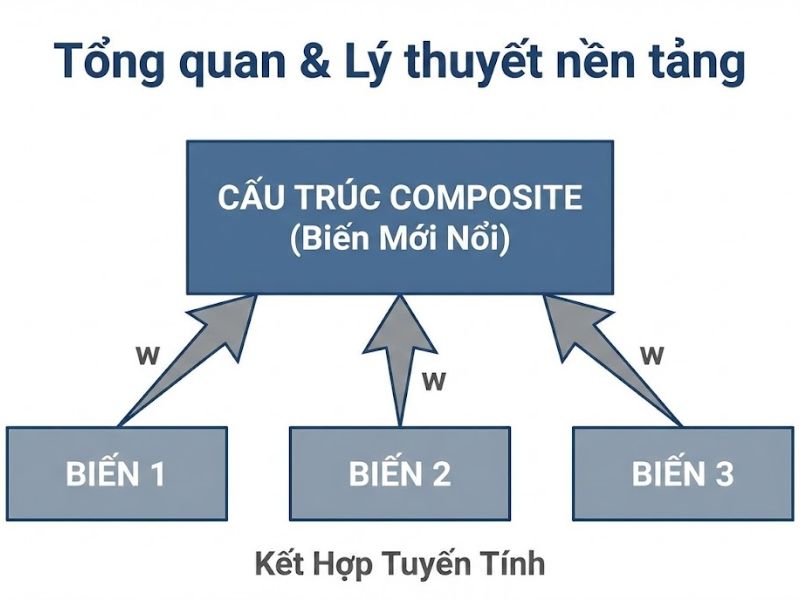
- Trường phái 2: Mô hình Biến tổng hợp (Composite Model / Formative)
- Triết lý: Biến tiềm ẩn là một khái niệm được tạo ra/tổng hợp từ các thành phần (ví dụ: “Chỉ số HDI”, “Sức khỏe tài chính”). Nó không tồn tại độc lập nếu thiếu các thành phần.
- Toán học: $\xi = \sum w_i x_i$ (Biến tiềm ẩn = Tổng trọng số $\times$ Biến quan sát).
- Hệ quả: Các biến quan sát không nhất thiết phải có tương quan với nhau (ví dụ: Tăng doanh thu và Giảm chi phí đều tạo nên Lợi nhuận, nhưng chúng có thể biến thiên ngược chiều).
Lưu ý: Bài báo này tập trung hoàn toàn vào Trường phái 2. Nếu bạn áp dụng tư duy của Trường phái 1 (đánh giá Cronbach’s Alpha, AVE) cho mô hình này, bạn đang sai về mặt phương pháp luận.
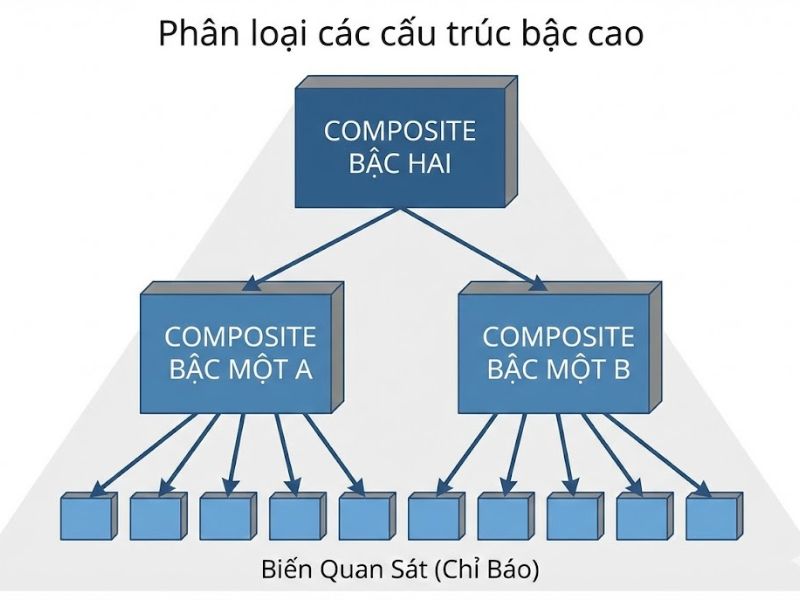
2. Phân loại các cấu trúc bậc cao (Typology of Hierarchical Constructs)
Mô hình bậc hai (Second-order Construct – SOC) xuất hiện khi một khái niệm quá trừu tượng để đo lường trực tiếp bằng chỉ báo, nên phải đo lường thông qua các khái niệm con. Có 4 loại cơ bản:
- Loại I (Reflective-Reflective): Biến bậc cao là nhân tố chung, biến bậc thấp cũng là nhân tố chung. (Ví dụ: Sự hài lòng chung -> Sự hài lòng về giá, Sự hài lòng về dịch vụ).
- Loại II (Reflective-Formative): Biến bậc cao là nhân tố chung, nhưng được tạo thành từ các biến bậc thấp dạng tổ hợp. (Hiếm gặp).
- Loại III (Formative-Reflective): Biến bậc cao là tổ hợp, nhưng các biến con là nhân tố chung. (Rất phổ biến: Ví dụ Chất lượng dịch vụ tổng thể được tạo thành từ 5 thành phần SERVQUAL).
- Loại IV (Formative-Formative / Composite of Composites):
- Định nghĩa: Cả biến mẹ (HOC) và biến con (LOC) đều là biến tổ hợp.
- Ví dụ:Hiệu suất Doanh nghiệp.
- Biến mẹ (Hiệu suất) được tổng hợp từ: Hiệu suất Tài chính & Hiệu suất Marketing.
- Biến con (Hiệu suất Tài chính) lại được tổng hợp từ: ROA, ROE, ROI.
- Tầm quan trọng: Đây là mô hình sát thực tế nhất trong quản trị kinh doanh, nơi các khái niệm thường là sự “cấu thành” (Design) hơn là “phát hiện” (Discovery).
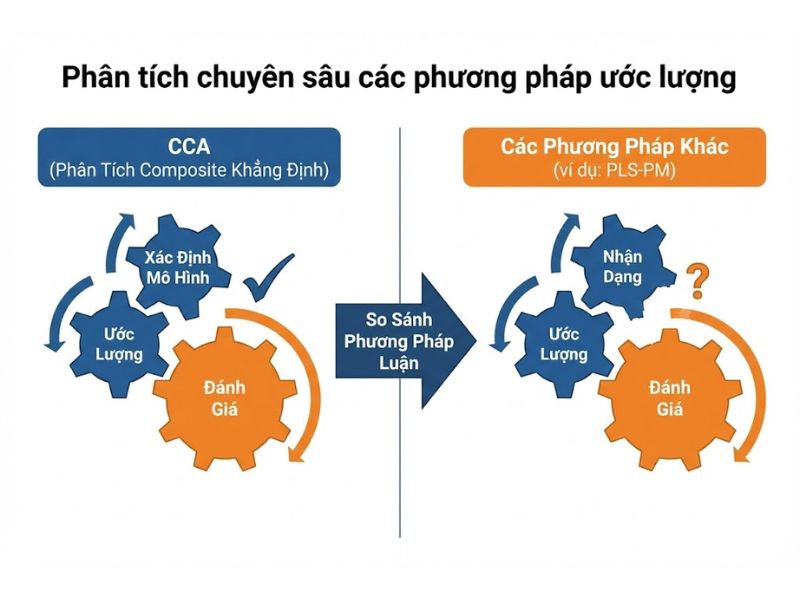
3. Phân tích chuyên sâu các phương pháp ước lượng (Estimation Methods)
Đây là phần trọng tâm kỹ thuật của bài báo. Tại sao các phương pháp cũ lại sai?
3.1. Phương pháp Lặp lại chỉ báo (Repeated Indicators Approach) – Lỗi thường gặp
- Cách làm: Gán toàn bộ chỉ báo của các biến con (LOCs) cho biến mẹ (HOC).
- Cơ chế sai lệch:
- Nếu dùng Mode A (Correlation weights): Các chỉ báo sẽ cạnh tranh nhau để giải thích phương sai. LOC nào có nhiều chỉ báo hơn sẽ chiếm trọng số lớn hơn một cách bất công (Number of items bias).
- Nếu dùng Mode B (Regression weights): Về lý thuyết là đúng cho Composite, nhưng nếu các chỉ báo có tương quan cao (collinearity), trọng số sẽ không ổn định và có thể dẫn đến hiện tượng sai dấu (sign flip).
- Kết luận của bài báo: Phương pháp này thường đánh giá thấp (underestimate) các mối quan hệ đường dẫn cấu trúc.
3.2. Phương pháp Hai giai đoạn (Two-Stage Approach) – Chuẩn mực vàng
Phương pháp này tách biệt quá trình đo lường và quá trình cấu trúc, giúp tránh nhiễu.
- Giai đoạn 1 (Lưu điểm số): Chạy mô hình mà không có biến bậc hai. Quan trọng là phải để các biến bậc một (LOCs) ở trạng thái bão hòa (saturated) – tức là cho phép chúng tương quan tự do với nhau. Mục tiêu là tính toán ra “Điểm số biến tiềm ẩn” (Latent Variable Scores – LVS) chính xác nhất cho từng LOC.
- Giai đoạn 2 (Ước lượng cấu trúc): Dùng các LVS này như là các chỉ báo (indicators) duy nhất cho biến bậc hai. Lúc này, mô hình trở nên đơn giản và dễ ước lượng hơn.
- Tại sao nó ưu việt? Nó đạt được Tính nhất quán Fisher (Fisher Consistency). Nghĩa là: Nếu kích thước mẫu tiến tới vô cùng ($N \to \infty$), giá trị ước lượng sẽ hội tụ về đúng giá trị thực của tham số trong tổng thể. Các phương pháp khác không làm được điều này.
3.3. Phương pháp Hai giai đoạn nhúng (Embedded Two-Stage)
- Một biến thể tích hợp cả hai giai đoạn vào một lần chạy toán học. Tuy nhiên, nghiên cứu chỉ ra rằng phương pháp này kém ổn định hơn ở các mẫu nhỏ và có tỷ lệ không hội tụ (non-convergence) cao hơn so với phương pháp Two-Stage tiêu chuẩn.
4. Đánh giá sự phù hợp tổng thể (Overall Model Fit Assessment)
Đây là đóng góp “cách mạng” của bài báo. Trước đây, người dùng PLS-SEM thường chỉ nhìn vào R^2 (khả năng dự báo). Schuberth et al. lập luận rằng: Dự báo tốt không có nghĩa là Mô hình đúng.
4.1. Tại sao R^2 là không đủ?
Bạn có thể có một mô hình với R^2 = 0.8$ (rất cao), nhưng về mặt cấu trúc lý thuyết lại sai hoàn toàn (ví dụ: đặt ngược chiều mũi tên nhân quả). $R^2$ không phát hiện được điều này. Chúng ta cần các chỉ số kiểm định sự phù hợp (Goodness-of-Fit).
4.2. Bộ ba chỉ số vàng: SRMR, dG_G, d_L
Để kiểm định xem mô hình Composite of Composites có khớp với dữ liệu thực tế hay không, cần dùng:
- SRMR (Standardized Root Mean Square Residual):
- Là trung bình bình phương phần dư chuẩn hóa giữa Ma trận tương quan thực tế và Ma trận tương quan do mô hình hàm ý.
- Ngưỡng: Giá trị < 0.08 (hoặc thận trọng hơn là < 0.05$) cho thấy mô hình phù hợp.
- Khoảng cách trắc địa (d_G) và Khoảng cách Euclid (d_L):
- Dùng trong kỹ thuật Bootstrap để tạo ra khoảng tin cậy.
- Quy tắc: Nếu giá trị d_G và d_L thực tế nhỏ hơn giá trị phân vị 95% (HI95) của phân phối Bootstrap, mô hình được chấp nhận (không bác bỏ giả thuyết H0).
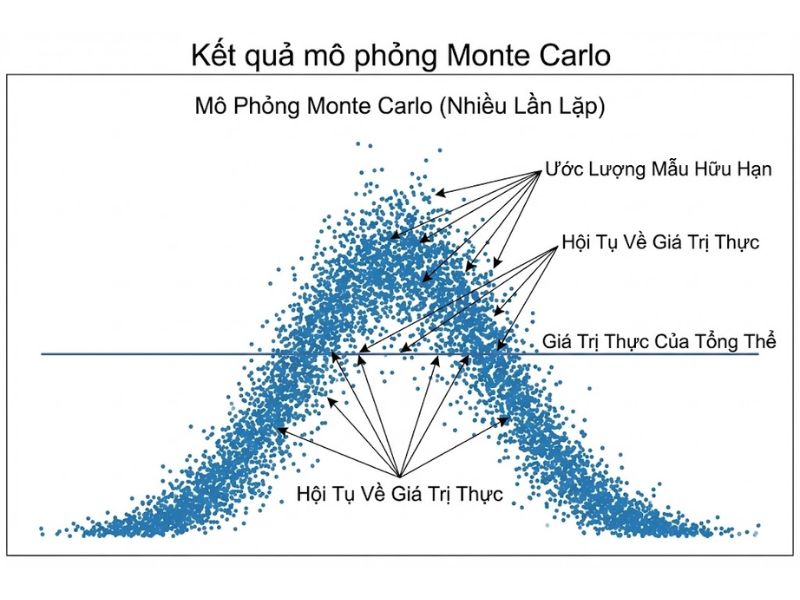
5. Kết quả mô phỏng Monte Carlo (Simulation Results)
Để chứng minh các luận điểm trên, các tác giả đã chạy hàng nghìn mô phỏng với các điều kiện khác nhau (kích thước mẫu 50, 100, 500; độ mạnh của đường dẫn 0.1, 0.5…).
Kết quả chính:
- Về độ chệch (Bias): Phương pháp Lặp lại chỉ báo (đặc biệt là Mode A) sinh ra độ chệch lớn nhất. Phương pháp Two-Stage (Mode B) có độ chệch gần như bằng 0 khi mẫu lớn (Nhất quán).
- Sức mạnh kiểm định (Power): Quy trình kiểm định hai bước (Two-step testing) có khả năng phát hiện Mô hình bị chỉ định sai cực tốt.
- Ví dụ: Nếu thực tế dữ liệu không có cấu trúc bậc hai, nhưng nhà nghiên cứu cố tình vẽ mô hình bậc hai, quy trình này sẽ báo SRMR cao (bác bỏ mô hình) ngay lập tức. Đây là điều mà các phương pháp cũ không làm được.
6. Hướng dẫn thực hiện: Quy trình kiểm định hai bước (The Two-Step Testing Procedure)
Dưới đây là quy trình chuẩn hóa (SOP) để bạn áp dụng vào nghiên cứu thực tế (sử dụng SmartPLS, ADANCO hoặc R-seminr):
GIAI ĐOẠN 1: Đánh giá Mô hình đo lường (Measurement Model Assessment)
Mục tiêu: Đảm bảo các biến con (LOCs) được đo lường chính xác.
- Bước 1: Vẽ mô hình chỉ gồm các biến LOCs. Nối các biến này với nhau bằng mũi tên hai chiều (tương quan) hoặc cho phép tương quan tự do (Saturated Model).
- Bước 2: Cài đặt thuật toán: Chọn Mode B (Weighting scheme) cho các biến Composite.
- Bước 3: Chạy Bootstrap (5.000 mẫu).
- Bước 4: Kiểm tra Model Fit (SRMR, d_G, d_L).
- 🔴 Nếu SRMR > 0.08: Mô hình đo lường sai. Dừng lại. Kiểm tra xem có biến quan sát nào “lạc quẻ” không, hoặc định nghĩa khái niệm có vấn đề.
- 🟢 Nếu SRMR < 0.08: Mô hình đo lường tốt. Chuyển sang bước 5.
- Bước 5: Lưu lại (Export) điểm số biến tiềm ẩn (Latent Variable Scores) của tất cả các LOCs.
GIAI ĐOẠN 2: Đánh giá Mô hình cấu trúc (Structural Model Assessment)
Mục tiêu: Đảm bảo giả thuyết về cấu trúc bậc hai là đúng.
- Bước 6: Tạo mô hình mới. Tạo biến bậc hai (HOC).
- Bước 7: Nhập dữ liệu điểm số (Scores) vừa lưu ở Bước 5 vào làm biến quan sát cho HOC.
- Bước 8: Chạy lại thuật toán PLS (vẫn dùng Mode B cho HOC) và Bootstrap.
- Bước 9: Kiểm tra Model Fit lần 2.
- 🔴 Nếu SRMR cao: Giả thuyết về cấu trúc bậc hai sai. (Có thể các LOCs không thực sự tạo nên HOC như bạn nghĩ).
- 🟢 Nếu SRMR thấp: Cấu trúc bậc hai được xác nhận.
- Bước 10: Báo cáo kết quả cuối cùng (Hệ số đường dẫn Path Coefficients, R^2, f^2).
7. Ứng dụng quản trị doanh nghiệp (Managerial Implications)
Tại sao Giám đốc doanh nghiệp cần quan tâm đến lý thuyết này?
- Thiết kế KPI chính xác: Hầu hết các chỉ số KPI trong doanh nghiệp (Sức khỏe thương hiệu, Chỉ số đổi mới sáng tạo, Điểm hài lòng nhân viên) đều là Composite. Nếu dùng sai phương pháp (tư duy Factor), doanh nghiệp có thể loại bỏ nhầm các chỉ số quan trọng chỉ vì chúng “không tương quan” với các chỉ số khác.
- Ra quyết định đầu tư: Kết quả từ Mode B (Trọng số hồi quy) trong mô hình Composite of Composites cho biết chính xác: “Tăng 1 đơn vị yếu tố con X sẽ tăng bao nhiêu đơn vị hiệu suất tổng thể Y”. Điều này giúp tối ưu hóa ngân sách (nên đổ tiền vào Marketing hay R&D?).
- Tránh ngụy biện: Giúp doanh nghiệp tránh được việc tin vào các báo cáo có $R^2$ cao nhưng thực chất là mô hình vô nghĩa (Good prediction but bad science).
8. Các câu hỏi thường gặp (FAQ – Researcher Edition)
SmartPLS mặc định là Mode A, tôi có bắt buộc phải chỉnh sang Mode B không?
Với Composite of Composites, câu trả lời là BẮT BUỘC. Mode A sẽ làm thổi phồng hệ số tải (loadings) và làm xẹp hệ số đường dẫn (path coefficients). Bạn phải vào phần cài đặt thuật toán (Algorithm Settings) và chọn “Regression Weights” (Mode B).
Nếu tôi dùng Mode B, hiện tượng Đa cộng tuyến (Multicollinearity) có đáng lo không?
Có. Mode B rất nhạy cảm với cộng tuyến. Nếu VIF giữa các biến con (LOCs) > 3.3, trọng số sẽ bị dao động mạnh (không tin cậy). Lúc này, bạn cần cân nhắc gộp các biến con lại hoặc loại bỏ bớt biến con trùng lặp.
Phương pháp này có áp dụng cho CB-SEM (AMOS) không?
Không. CB-SEM dựa trên ma trận hiệp phương sai và giả định phân phối chuẩn đa biến, thường khó xử lý các mô hình Composite (Formative) thuần túy. PLS-PM (như trong bài báo này) là công cụ phù hợp nhất.
9. Tài liệu tham khảo (References)
Dưới đây là danh sách đầy đủ các tài liệu tham khảo được trích dẫn trong bài báo:
- Agarwal, R. and Karahanna, E. (2000), “Time flies when you’re having fun…”, MIS Quarterly, 24(4), 665-694.
- Ainin, S., et al. (2015), “Factors influencing the use of social media…”, Industrial Management & Data Systems, 115(3), 570-588.
- Akaike, H. (1998), “Information theory and an extension of the maximum likelihood principle…”, Springer Series in Statistics.
- Barrett, P. (2007), “Structural equation modelling: Adjudging model fit”, Personality and Individual Differences, 42(5), 815-824.
- Becker, J.-M., Klein, K., and Wetzels, M. (2012), “Hierarchical latent variable models in PLS-SEM…”, Long Range Planning, 45(5), 359-394.
- Benitez, J., et al. (2018a), “IT-enabled knowledge ambidexterity…”, Information & Management, 55(1), 131-143.
- Benitez, J., et al. (2020), “How to perform and report an impactful analysis using partial least squares…”, Information & Management, 57(2), 103168.
- Benitez, J., et al. (2018b), “How information technology influences opportunity exploration…”, Information & Management.
- Bentler, P. M. (1990), “Comparative fit indexes in structural models”, Psychological Bulletin, 107(2), 238-246.
- Bentler, P. M. and Bonett, D. G. (1980), “Significance tests and goodness of fit…”, Psychological Bulletin, 88(3), 588-606.
- Beran, R. and Srivastava, M. S. (1985), “Bootstrap tests and confidence regions…”, The Annals of Statistics, 13(1), 95-115.
- Bollen, K. A. (1989), Structural Equations with Latent Variables, John Wiley & Sons.
- Bollen, K. A. and Bauldry, S. (2011), “Three Cs in measurement models…”, Psychological Methods, 16(3), 265-284.
- Bollen, K. A. and Stine, R. A. (1992), “Bootstrapping goodness-of-fit measures…”, Sociological Methods & Research, 21(2), 205-229.
- Brock, J. K.-U. and Zhou, Y. J. (2005), “Organizational use of the Internet…”, Internet Research, 15(1), 67-87.
- Cadogan, J. W. and Lee, N. (2013), “Improper use of endogenous formative variables”, Journal of Business Research, 66(2), 233-241.
- Cheah, J.-H., et al. (2019), “A comparison of five reflective formative estimation approaches…”, Quality & Quantity, 53(3), 1421-1458.
- Chin, W. W. and Todd, P. A. (1995), “On the use, usefulness, and ease of use…”, MIS Quarterly, 19(2), 237-246.
- Cohen, J. (1988), Statistical Power Analysis for the Behavioral Sciences.
- Cohen, J. (1992), “A power primer”, Psychological Bulletin, 112(1), 155-159.
- Cohen, P., et al. (1990), “Problems in the measurement of latent variables…”, Applied Psychological Measurement, 14(2), 183-196.
- Cole, D. A., et al. (1993), “Multivariate group comparisons…”, Psychological Bulletin, 114(1), 174-184.
- Danks, N. P., et al. (2020), “Model selection uncertainty…”, Journal of Business Research, 113, 13-24.
- Dijkstra, T. K. (1981), Latent variables in linear stochastic models…, PhD thesis.
- Dijkstra, T. K. (2013), “On the extraction of weights…”, Central European Journal of Operations Research, 21(1), 103-123.
- Dijkstra, T. K. (2016), “High-dimensional concepts…”, Cluj Economics and Business Seminar.
- Dijkstra, T. K. (2017), “A perfect match between a model and a mode”, in Partial Least Squares Path Modeling…, Springer.
- Dijkstra, T. K. and Henseler, J. (2015), “Consistent and asymptotically normal PLS estimators…”, Computational Statistics & Data Analysis, 81(1), 10-23.
- Dijkstra, T. K. and Schermelleh-Engel, K. (2014), “Consistent partial least squares for nonlinear structural equation models”, Psychometrika, 79(4), 585-604.
- Duarte, P. and Amaro, S. (2018), “Methods for modelling reflective-formative second order constructs…”, Journal of Hospitality and Tourism Technology, 9(3), 295-313.
- Edwards, J. R. (2001), “Multidimensional constructs in organizational behavior research…”, Organizational Research Methods, 4(2), 144-192.
- Fornell, C. and Bookstein, F. L. (1982), “Two structural equation models…”, Journal of Marketing Research, 19(4), 440-452.
- Gómez-Cedeño, M., et al. (2015), “Impact of human resources…”, Industrial Management & Data Systems, 115(1), 129-157.
- Green, K. W. and Inman, R. A. (2007), “The impact of JIT-II-selling…”, Industrial Management & Data Systems, 107(7), 1018-1035.
- Hair, J., et al. (2017a), “An updated and expanded assessment of PLS-SEM…”, Industrial Management & Data Systems, 117(3), 442-458.
- Hair, J. F., et al. (2020), “Assessing measurement model quality in PLS-SEM…”, Journal of Business Research, 109, 101-110.
- Hair, J. F., et al. (2017b), A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), Sage.
- Hair, J. F., et al. (2019a), “When to use and how to report the results of PLS-SEM”, European Business Review, 31(1), 2-24.
- Hair, J. F., et al. (2019b), “Rethinking some of the rethinking of partial least squares”, European Journal of Marketing, 53(4), 566-584.
- Hajiheydari, N. and Ashkani, M. (2018), “Mobile application user behavior…”, Information Systems, 77, 22-33.
- Henseler, J. (2017), “Bridging design and behavioral research…”, Journal of Advertising, 46(1), 178-192.
- Henseler, J. (2018), “Partial least squares path modeling: Quo vadis?”, Quality & Quantity, 52(1), 1-8.
- Henseler, J. (2019), ADANCO 2.0.1, Composite Modeling GmbH & Co.
- Henseler, J., et al. (2014), “Common beliefs and reality about PLS…”, Organizational Research Methods, 17(2), 182-209.
- Henseler, J. and Fassott, G. (2009), “Testing moderating effects in PLS path models…”, in Handbook of Partial Least Squares.
- Henseler, J., et al. (2016), “Using PLS path modeling in new technology research…”, Industrial Management & Data Systems, 116(1), 2-20.
- Henseler, J., et al. (2007), “Investigating the moderating role of fit…”, International Journal of Sports Marketing and Sponsorship, 8(4), 34-42.
- Hong, H.-K., et al. (2008), “The effect of knowledge…”, Industrial Management & Data Systems, 108(3), 385-404.
- Hsieh, C.-T., et al. (2006), “Information orientation…”, Industrial Management & Data Systems, 106(6), 825-840.
- Hsu, L.-C. (2017), “Investigating community members’ purchase intention…”, Industrial Management & Data Systems, 117(5), 766-800.
- Hu, L. and Bentler, P. M. (1999), “Cutoff criteria for fit indexes…”, Structural Equation Modeling, 6(1), 1-55.
- Johnson, R. E., et al. (2012), “Recommendations for improving the construct clarity…”, Human Resource Management Review, 22(2), 62-72.
- Jöreskog, K. (1969), “A general approach to confirmatory maximum likelihood factor analysis”, Psychometrika, 34(2), 183-202.
- Jöreskog, K. G. (1970), “A general method for estimating a linear structural equation system”, ETS Research Bulletin Series.
- Khan, G. F., et al. (2019), “Methodological research on partial least squares…”, Internet Research, 29(3), 407-429.
- Kline, R. B. (2015), Principles and Practice of Structural Equation Modeling, Guilford Press.
- Law, K. S. and Wong, C.-S. (1999), “Multidimensional constructs…”, Journal of Management, 25(2), 143-160.
- Lawley, D. N. and Maxwell, A. E. (1962), “Factor analysis as a statistical method”, The Statistician, 12(3), 209-229.
- Lee, S. M., et al. (2012), “Green supply chain management…”, Industrial Management & Data Systems, 112(8), 1148-1180.
- Leong, L.-Y., et al. (2017), “Understanding impulse purchase…”, Internet Research, 27(4), 786-818.
- Liengaard, B. D., et al. (accepted), “Prediction: Coveted, yet forsaken?…”, Decision Sciences.
- Lohmöller, J.-B. (1989), Latent Variable Path Modeling with Partial Least Squares, Physica.
- Mason, R. and Brown, W. G. (1975), “Multicollinearity problems…”, Social Science Research, 4(2), 135-149.
- Mulaik, S. A., et al. (1989), “Evaluation of goodness-of-fit indices…”, Psychological Bulletin, 105(3), 430.
- Mulaik, S. A. and Quartetti, D. A. (1997), “First order or higher order general factor?”, Structural Equation Modeling, 4(3), 193-211.
- Noonan, R. and Wold, H. (1982), “PLS path modeling with indirectly observed variables…”, in Systems under Indirect Observation.
- Pérez-López, S. and Alegre, J. (2012), “Information technology competency…”, Industrial Management & Data Systems, 112(4), 644-662.
- Polites, G. L., et al. (2012), “Conceptualizing models using multidimensional constructs…”, European Journal of Information Systems, 21(1), 22-48.
- R Core Team (2019), R: A Language and Environment for Statistical Computing.
- Rademaker, M. and Schuberth, F. (2020), cSEM: Composite-Based Structural Equation Modeling, R package.
- Ramayah, T., et al. (2016), Partial Least Squares Structural Equation Modeling…, Pearson.
- Rasoolimanesh, S. M., et al. (2019), “Investigating the effects of tourist engagement…”, The Service Industries Journal, 39(7-8), 559-574.
- Raykov, T. and Penev, S. (1999), “On structural equation model equivalence”, Multivariate Behavioral Research, 34(2), 199-244.
- Rigdon, E. E. (2012), “Rethinking partial least squares…”, Long Range Planning, 45(5), 341-358.
- Rigdon, E. E. (2014), “Comment on ‘Improper use of endogenous formative variables'”, Journal of Business Research, 67(1), 2800-2802.
- Rigdon, E. E. (2016), “Choosing PLS path modeling…”, European Management Journal, 34(6), 598-605.
- Ringle, C. M., et al. (2012), “A critical look at the use of PLS-SEM…”, MIS Quarterly, 36(1), iii-xiv.
- Ringle, C. M., et al. (2015), SmartPLS 3.
- Rönkkö, M. (2019), matrixpls: Matrix-based Partial Least Squares Estimation.
- Sarstedt, M., et al. (2019), “How to specify, estimate, and validate higher-order constructs in PLS-SEM”, Australasian Marketing Journal, 27(3), 197-211.
- Schuberth, F. (forthcoming), “Confirmatory composite analysis…”, Review of Managerial Science.
- Schuberth, F., et al. (2018), “Confirmatory composite analysis”, Frontiers in Psychology, 9(2541).
- Schumacker, R. E. and Lomax, R. G. (2009), A Beginner’s Guide to Structural Equation Modeling, Routledge.
- Schwarz, G. (1978), “Estimating the dimension of a model”, The Annals of Statistics, 6(2), 461-464.
- Sharma, P., et al. (2019), “PLS-based model selection…”, Journal of the Association for Information Systems, 20(4), 346-397.
- Shmueli, G. (2010), “To explain or to predict?”, Statistical Science, 25(3), 289-310.
- Steiger, J. H. (2007), “Understanding the limitations…”, Personality and Individual Differences, 42(5), 893-898.
- Tenenhaus, M., et al. (2005), “PLS path modeling”, Computational Statistics & Data Analysis, 48(1), 159-205.
- Van Riel, A. C. R., et al. (2017), “Estimating hierarchical constructs…”, Industrial Management & Data Systems, 117(3), 459-477.
- Venables, W. N. and Ripley, B. D. (2002), Modern Applied Statistics with S, Springer.
- Vernon, T. and Eysenck, S. (2007), “Introduction”, Personality and Individual Differences, 42(5), 813.
- Wetzels, M., et al. (2009), “Using PLS path modeling for assessing hierarchical construct models…”, MIS Quarterly, 33(1), 177-195.
- Wilson, B. (2010), “Using PLS to investigate interaction effects…”, in Handbook of Partial Least Squares.
- Wilson, B. and Henseler, J. (2007), “Modeling reflective higher-order constructs…”, in Conference Proceedings ANZMAC 2007.
- Wold, H. (1982), “Soft modeling: The basic design and some extensions”, in Systems under Indirect Observation.
- Yim, B. and Leem, B. (2013), “The effect of the supply chain social capital”, Industrial Management & Data Systems, 113(3), 324-349.
- Yuan, K.-H. (2005), “Fit indices versus test statistics”, Multivariate Behavioral Research, 40(1), 115-148.
Hãy tải ngay bài báo gốc (PDF) để xem chi tiết các bảng số liệu mô phỏng tại đường dẫn dưới đây:
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



