
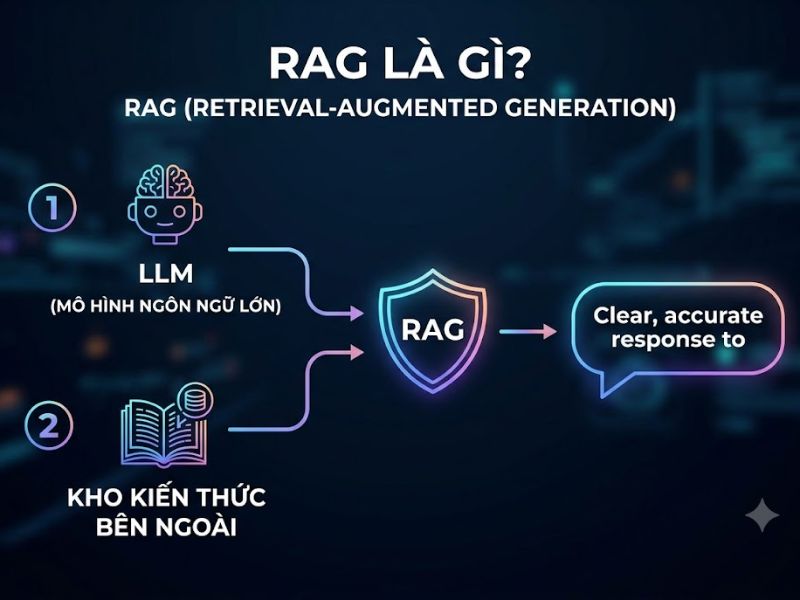
RAG là gì? RAG (Retrieval-Augmented Generation – Tạo sinh tăng cường truy xuất) là một khung kiến trúc trí tuệ nhân tạo (AI) được thiết kế để cải thiện chất lượng, độ chính xác và tính cập nhật của các Mô hình ngôn ngữ lớn (LLM) bằng cách liên kết mô hình này với các cơ sở dữ liệu tri thức bên ngoài trước khi tiến hành tạo sinh văn bản. Việc hiểu rõ nền tảng công nghệ RAG là gì đóng vai trò then chốt giúp các doanh nghiệp giải quyết triệt để tình trạng “ảo giác AI” (AI Hallucination) và nâng cao độ tin cậy của các hệ thống AI chuyên ngành.

Nền tảng công nghệ RAG là gì?
Khái niệm RAG là gì được định nghĩa một cách chính xác dựa trên nền tảng kỹ thuật do Meta AI giới thiệu. RAG là một hệ thống lai (hybrid system) kết hợp giữa hai thành phần: cơ chế truy xuất thông tin độc lập (retriever) và mô hình học sâu tạo sinh (generator). Thay vì chỉ dựa vào tham số trọng số (weights) được huấn luyện từ trước, RAG bắt buộc mô hình LLM phải tham chiếu đến một tập dữ liệu thực tế, được cập nhật liên tục để trích xuất ngữ cảnh trước khi đưa ra câu trả lời.
Nguyên lý khoa học: Theo nghiên cứu “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” công bố năm 2020 bởi Patrick Lewis và các nhà nghiên cứu tại Meta AI, kiến trúc RAG sử dụng mô hình Dense Passage Retriever (DPR) để chuyển đổi tài liệu thành các vector số học (embeddings), sau đó đối chiếu độ tương đồng cosine (cosine similarity) với truy vấn của người dùng để tìm ra thông tin ngữ cảnh chính xác nhất, trước khi cấp phát dữ liệu này cho mô hình seq2seq để tạo sinh văn bản.
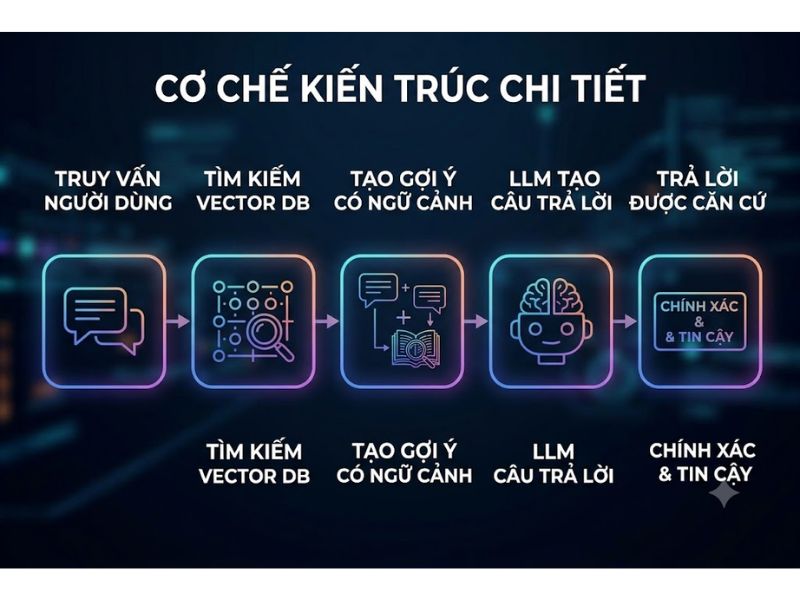
Cơ chế hoạt động của kiến trúc RAG là gì?
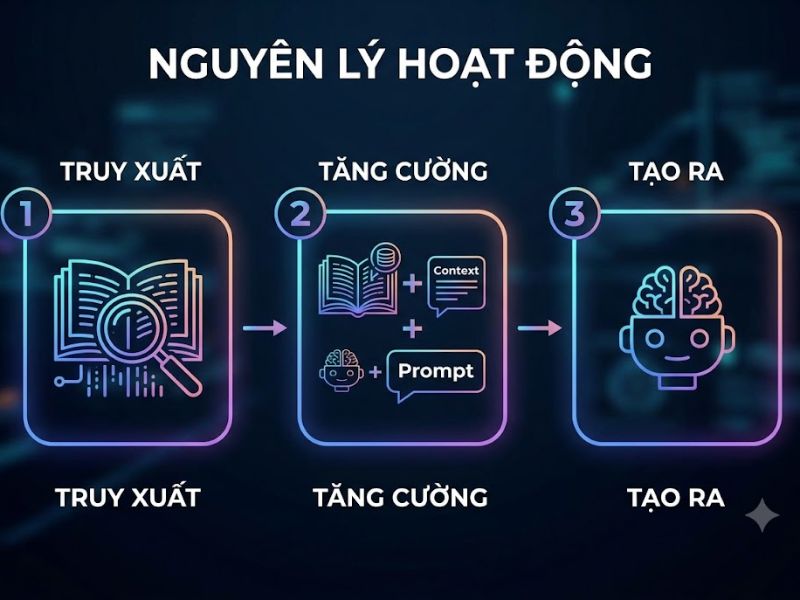
Quy trình vận hành của RAG bao gồm 3 giai đoạn tuyến tính và chặt chẽ. Hệ thống không cho phép LLM tự động đoán câu trả lời mà phải trải qua quy trình xác thực dữ liệu gốc.
- Giai đoạn 1: Truy xuất (Retrieval): Khi người dùng nhập truy vấn, hệ thống sẽ sử dụng thuật toán nhúng (Embedding Model) để biến đổi truy vấn văn bản thành một vector đa chiều. Vector truy vấn này được so sánh với hệ thống cơ sở dữ liệu vector (Vector Database) chứa dữ liệu doanh nghiệp để tìm ra các đoạn văn bản (chunks) có ý nghĩa tương đồng nhất.
- Giai đoạn 2: Tăng cường ngữ cảnh (Augmented): Các đoạn thông tin vừa được truy xuất sẽ được gắn kèm (append) vào truy vấn ban đầu của người dùng, tạo thành một câu lệnh mới (Prompt) giàu ngữ cảnh.
- Giai đoạn 3: Tạo sinh văn bản (Generation): Prompt đã được tăng cường này được gửi đến LLM (như GPT-4, Llama 3). LLM đọc nguồn thông tin thực tế được cung cấp và tiến hành tổng hợp, định dạng lại thành một câu trả lời tự nhiên, chính xác và có trích dẫn nguồn rõ ràng.
So sánh tối ưu hóa LLM: Fine-Tuning và RAG là gì?
Để nhận thức rõ giá trị của RAG là gì trong việc triển khai AI, việc so sánh trực diện phương pháp RAG với quy trình Tinh chỉnh (Fine-Tuning) là bắt buộc. Dưới đây là bảng số liệu so sánh tham chiếu thông số kỹ thuật:
| Tiêu chí kỹ thuật | Kiến trúc RAG (Retrieval-Augmented Generation) | Phương pháp Fine-Tuning (Tinh chỉnh mô hình) |
| Nguồn dữ liệu | Trích xuất từ Vector Database ngoài (Cập nhật thời gian thực) | Tích hợp sâu vào tham số mô hình (Tĩnh) |
| Chi phí vận hành | Thấp (Chỉ tốn phí lưu trữ vector và API truy vấn) | Rất cao (Đòi hỏi năng lực điện toán GPU lớn) |
| Tính minh bạch (Auditability) | Cao. Có khả năng truy xuất trực tiếp nguồn tài liệu. | Thấp. Mô hình hoạt động như một “hộp đen” (Black box). |
| Rủi ro ảo giác AI (Hallucination) | Dưới 5% (Phụ thuộc hoàn toàn vào dữ liệu cấp phát) | 15% – 20% (Phụ thuộc vào chất lượng tập dữ liệu huấn luyện) |
| Khả năng cập nhật | Tức thì (Chỉ cần thêm tài liệu mới vào cơ sở dữ liệu) | Chậm (Cần huấn luyện lại toàn bộ mô hình) |
Những lợi ích vượt trội của doanh nghiệp khi triển khai RAG là gì?
Bằng việc áp dụng chuẩn xác kiến trúc RAG, doanh nghiệp có thể giải quyết được bài toán chi phí và độ chính xác của AI. Các lợi ích cụ thể bao gồm:
- Đảm bảo tính thực tế và minh bạch: RAG buộc AI tạo ra thông tin dựa trên dữ liệu thật của doanh nghiệp. Mọi câu trả lời đều có thể đối chiếu chéo (cross-check) trực tiếp với tài liệu gốc, loại bỏ hoàn toàn các thông tin bịa đặt.
- Tiết kiệm tối đa ngân sách điện toán: Doanh nghiệp không cần đầu tư máy chủ GPU đắt đỏ để huấn luyện (train) lại LLM chuyên ngành. Hệ thống chỉ yêu cầu thiết lập đường ống dữ liệu (Data Pipeline) và Vector Database.
- Bảo mật dữ liệu tuyệt đối: Khi áp dụng RAG nội bộ, dữ liệu nhạy cảm của tổ chức không bị đưa vào tham số của các mô hình ngôn ngữ công khai, đảm bảo tính tuân thủ quy định bảo mật (GDPR, HIPAA).
- Kiểm soát quyền truy cập theo ngữ cảnh: RAG cho phép phân quyền (Role-based access control) trong giai đoạn truy xuất. Nghĩa là nhân viên cấp thấp sẽ không thể dùng AI để truy xuất các báo cáo tài chính nội bộ cấp C-level.

Câu hỏi thường gặp (FAQ) về công nghệ RAG
Vector Database trong RAG là gì?
Vector Database (Cơ sở dữ liệu vector) là hệ thống lưu trữ dữ liệu dưới dạng các điểm số toán học (vector) trong không gian đa chiều. Trong RAG, Vector Database (như Pinecone, Milvus, ChromaDB) có nhiệm vụ lưu trữ các đoạn tài liệu đã được mã hóa và thực hiện thuật toán tìm kiếm tương đồng (Semantic Search) cực kỳ nhanh chóng để tìm ra dữ liệu khớp với câu hỏi của người dùng.
AI Hallucination là gì và RAG khắc phục nó như thế nào?
AI Hallucination (Ảo giác AI) là hiện tượng LLM tự tạo ra các thông tin sai lệch, phi logic nhưng lại trình bày bằng văn phong rất tự tin. RAG khắc phục hoàn toàn hiện tượng này bằng cách áp đặt cơ chế “chỉ trả lời dựa trên ngữ cảnh được cung cấp”. Nếu thông tin không tồn tại trong tập dữ liệu truy xuất, hệ thống RAG sẽ được cấu hình để phản hồi: “Tôi không có đủ thông tin để trả lời câu hỏi này”.
Advanced RAG là gì so với Naive RAG?
Advanced RAG (RAG nâng cao) là các kỹ thuật tối ưu hóa đường ống dữ liệu nhằm cải thiện độ chính xác của tìm kiếm, vượt ra khỏi quy trình cơ bản (Naive RAG). Các phương pháp Advanced RAG bao gồm Tối ưu hóa phân đoạn dữ liệu (Chunking Optimization), Truy xuất kết hợp (Hybrid Search giữa Vector và Keyword), và Xếp hạng lại (Re-ranking) sử dụng các mô hình chuyên biệt như Cohere Rerank để đưa tài liệu liên quan nhất lên đầu ngữ cảnh.
Kết luận
Tổng kết lại, bản chất của RAG là gì? RAG là bước tiến khoa học giải quyết khoảng trống giữa khả năng giao tiếp của Mô hình ngôn ngữ lớn (LLM) và sự thật khách quan của dữ liệu độc quyền. Thay vì nhồi nhét mọi kiến thức vào một mô hình khổng lồ, RAG đóng vai trò như một thủ thư thông minh: tìm kiếm chính xác tài liệu cần thiết và sử dụng năng lực ngôn ngữ của AI để giải thích tài liệu đó cho người dùng. Hiểu rõ kiến trúc RAG là gì sẽ là lợi thế cạnh tranh cốt lõi cho bất kỳ tổ chức nào muốn ứng dụng AI Tạo sinh vào môi trường sản xuất thực tế.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



