
Rò rỉ dữ liệu và tiêu hao băng thông do các trình thu thập thông tin của bên thứ ba là hai vấn đề nghiêm trọng đối với hệ thống máy chủ. Việc thiết lập hàng rào kỹ thuật chính xác để chặn bot Semrush Ahrefs thu thập dữ liệu website là yêu cầu bắt buộc nhằm duy trì hiệu suất hoạt động và bảo vệ dữ liệu nền tảng. Hướng dẫn dưới đây cung cấp các giải pháp kỹ thuật triệt để nhằm tối ưu hóa tài nguyên mạng, ngăn chặn rò rỉ dữ liệu và củng cố bảo mật hệ thống.

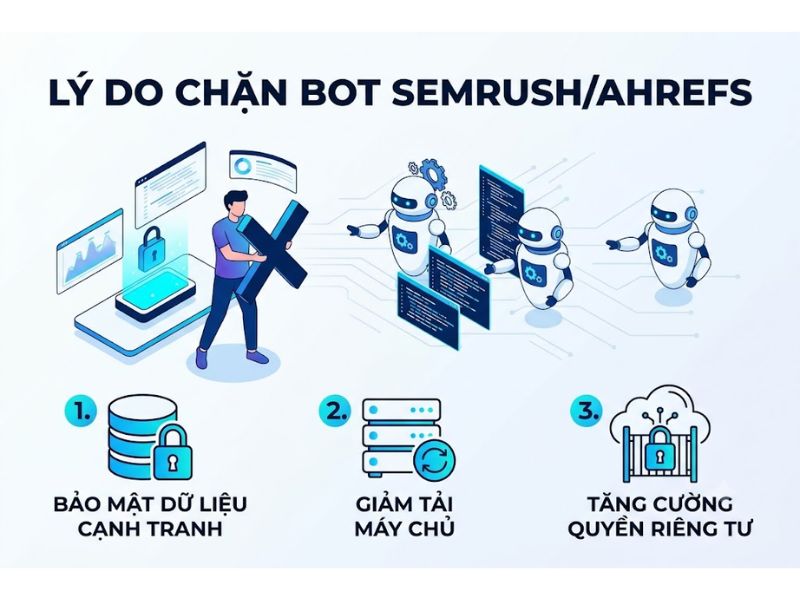
Tại sao quản trị viên cần chặn bot Semrush Ahrefs thu thập dữ liệu website?
Quản trị viên cần chặn bot Semrush Ahrefs thu thập dữ liệu website vì 3 nguyên nhân chính: bảo vệ tài nguyên máy chủ, ngăn chặn đối thủ phân tích chiến lược, và bảo mật thông tin nội bộ. Việc không kiểm soát các trình thu thập thông tin này sẽ gây ra những hệ lụy trực tiếp đến hiệu năng và lợi thế cạnh tranh của doanh nghiệp.
Bảo vệ băng thông và tài nguyên máy chủ (Server Resources)
Lưu lượng truy cập ảo từ các công cụ này gây quá tải hệ thống máy chủ. Quá trình quét liên tục tiêu tốn tài nguyên bộ nhớ (RAM) và năng lượng xử lý (CPU), trực tiếp làm giảm tốc độ tải trang đối với người dùng thực. Các bot này thường thực hiện hàng chục nghìn truy vấn mỗi ngày, có khả năng làm cạn kiệt băng thông của các máy chủ có cấu hình thấp hoặc gói hosting bị giới hạn tài nguyên.
Ngăn chặn đối thủ phân tích chiến lược tối ưu hóa (SEO Strategy)
Các trình thu thập thông tin trích xuất dữ liệu về hồ sơ liên kết (backlink profile) và cấu trúc cụm chủ đề (topic cluster). Việc bảo vệ dữ liệu này giúp chiến lược tối ưu hóa kỹ thuật không bị đối thủ cạnh tranh sao chép hoặc phân tích ngược. Bằng cách từ chối truy cập đối với Ahrefs và Semrush, nền tảng của bạn sẽ “tàng hình” trước các công cụ theo dõi thị trường, bảo vệ hoàn toàn nỗ lực xây dựng liên kết.
Bảo mật thông tin nội bộ và dữ liệu nhạy cảm
Hệ thống máy chủ thường chứa các trang đang trong giai đoạn thử nghiệm (staging) hoặc dữ liệu nội bộ chưa sẵn sàng xuất bản. Thiết lập lệnh từ chối truy cập giúp hạn chế triệt để nguy cơ rò rỉ các dữ liệu chưa được công bố này ra ngoài môi trường mạng internet. Điều này ngăn chặn rủi ro dữ liệu nhạy cảm vô tình bị lập chỉ mục trên cơ sở dữ liệu của bên thứ ba.
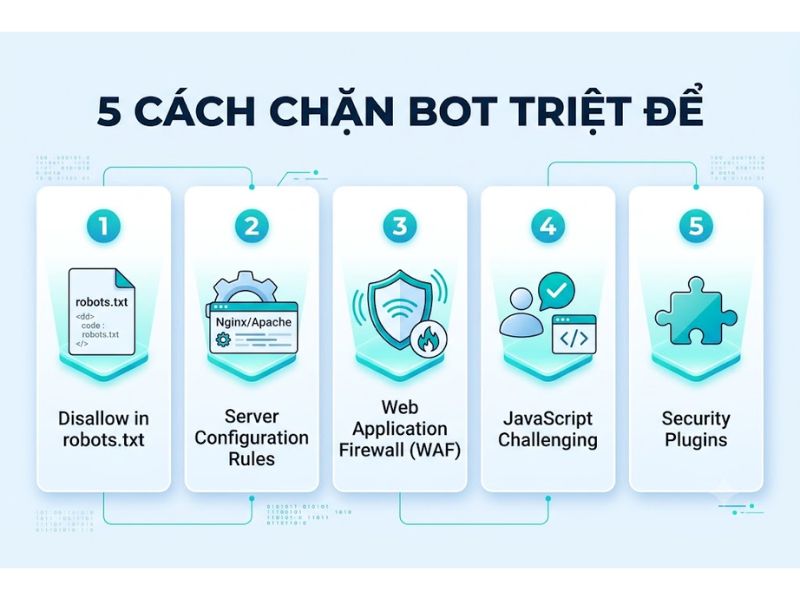
5 phương pháp chặn bot Semrush Ahrefs thu thập dữ liệu website triệt để nhất
Có 5 phương pháp chặn bot Semrush Ahrefs thu thập dữ liệu website triệt để nhất bao gồm: cấu hình tệp robots.txt, thiết lập quy tắc trên tệp .htaccess, cấu hình tệp nginx.conf, thiết lập tường lửa ứng dụng web, và khóa dải địa chỉ IP qua cPanel. Quản trị viên cần lựa chọn phương pháp phù hợp dựa trên hạ tầng máy chủ đang sử dụng.
1. Cấu hình tệp robots.txt để từ chối User-Agent
Cú pháp chuẩn xác áp dụng cho SemrushBot và AhrefsBot là khai báo lệnh “Disallow: /” cho từng User-Agent tương ứng ngay tại thư mục gốc. Tệp robots.txt có ưu điểm là dễ thiết lập, cấu hình nhanh chóng và không yêu cầu can thiệp vào tầng máy chủ, nhưng bị giới hạn bởi tính tự nguyện tuân thủ của các trình thu thập thông tin.
2. Thiết lập quy tắc chặn trên tệp .htaccess (Dành cho máy chủ Apache)
Đối với máy chủ Apache, đoạn mã (code snippet) từ chối truy cập thông qua HTTP_USER_AGENT là biện pháp chặn bắt buộc ở cấp độ lõi máy chủ. Cú pháp RewriteCond kết hợp với lệnh cấm sẽ loại bỏ toàn bộ các yêu cầu truy cập phát sinh từ hai công cụ này. Phương pháp này ép buộc máy chủ trả về mã lỗi 403 Forbidden ngay khi phát hiện chuỗi nhận dạng User-Agent bị liệt vào danh sách đen.
3. Cấu hình tệp nginx.conf (Dành cho máy chủ Nginx)
Trên máy chủ Nginx, giải pháp kỹ thuật xử lý yêu cầu (request) ở tầng máy chủ (server-level) mang lại hiệu suất tối ưu và mức độ chịu tải tốt hơn. Quản trị viên sử dụng khối lệnh điều kiện if ($http_user_agent ~* (AhrefsBot|SemrushBot)) để kiểm tra biến định danh và trả về mã trạng thái 403 cho các kết nối từ bot phân tích. Hành động này giúp từ chối yêu cầu ngay lập tức mà không cần gọi đến mã nguồn ứng dụng (PHP/Node.js).
4. Thiết lập tường lửa ứng dụng web (WAF) qua Cloudflare
Việc sử dụng “Firewall Rules” để chặn theo chuỗi User-Agent trực tiếp trên mạng phân phối nội dung (CDN) giúp bảo vệ máy chủ gốc một cách tuyệt đối. Kỹ thuật này ngăn chặn các luồng dữ liệu độc hại trước khi chúng tiếp cận cơ sở hạ tầng mạng của website. Máy chủ nội bộ sẽ không phải chịu bất kỳ áp lực xử lý nào từ các request bị chặn bởi WAF.
5. Khóa dải IP của bot thông qua hệ thống cPanel
Cách truy xuất và chặn trực tiếp các địa chỉ IP được xác thực của Ahrefs và Semrush được thực hiện thông qua công cụ IP Blocker tích hợp trong cPanel. Quản trị viên nhập chính xác các khối IP tĩnh do hệ thống công cụ này cung cấp vào danh sách đen để hệ thống tự động ngắt kết nối ở cấp độ mạng lưới.
Quy trình kiểm tra sau khi thiết lập lệnh chặn bot Semrush Ahrefs thu thập dữ liệu website
Quy trình kiểm tra sau khi thiết lập lệnh chặn bot Semrush Ahrefs thu thập dữ liệu website bao gồm 2 bước: phân tích nhật ký truy cập máy chủ và sử dụng công cụ mô phỏng trình thu thập thông tin. Quá trình kiểm tra đảm bảo các cấu hình tường lửa hoạt động trơn tru mà không làm gián đoạn trải nghiệm người dùng thực.
Phân tích nhật ký truy cập máy chủ (Access Logs)
Quản trị viên cần đọc và trích xuất dữ liệu nhật ký hệ thống để xác nhận mã trạng thái 403 Forbidden đối với các yêu cầu từ bot. Sự xuất hiện của mã trạng thái này trong Access Logs là bằng chứng kỹ thuật xác đáng cho thấy hệ thống đã từ chối quyền truy cập thành công, thay vì trả về mã 200 OK thông thường.
Sử dụng công cụ mô phỏng trình thu thập thông tin (Crawler Simulator)
Công cụ mô phỏng trình thu thập thông tin kiểm chứng tính hiệu quả của các rào cản kỹ thuật bằng cách giả lập User-Agent của Ahrefs hoặc Semrush. Khi bạn sử dụng công cụ giả lập quét qua cấu trúc URL, nếu báo cáo trả về lỗi kết nối bị từ chối, quy trình cấu hình chặn đã đạt tiêu chuẩn kỹ thuật an toàn.
Các rủi ro kỹ thuật cần tránh khi thiết lập quy tắc chặn
Có 2 rủi ro kỹ thuật cần tránh khi thiết lập quy tắc chặn là lỗi cú pháp gây chặn nhầm bọ tìm kiếm của Google và vòng lặp chuyển hướng do cấu hình tệp máy chủ sai lệch. Sự bất cẩn trong quá trình này có thể phá vỡ toàn bộ nền tảng hữu cơ của website.
Lỗi cú pháp gây chặn nhầm bọ tìm kiếm của Google (Googlebot)
Việc cấu hình sai cú pháp, đặc biệt là khi lạm dụng ký tự đại diện (wildcard) quá rộng, dẫn đến việc chặn nhầm Googlebot. Khuyết điểm này trực tiếp làm mất chỉ mục (deindex) của toàn bộ nền tảng trên công cụ tìm kiếm Google. Quản trị viên phải sử dụng biểu thức chính quy (Regex) chính xác tuyệt đối để tránh đưa các công cụ tìm kiếm hợp pháp vào danh sách đen.
Vòng lặp chuyển hướng (Redirect loops) do cấu hình tệp .htaccess sai
Các quy tắc điều hướng không chính xác tạo ra vòng lặp vô tận, gây sụp đổ tài nguyên máy chủ. Quản trị viên cần kiểm tra độc lập các đoạn mã cấu hình để đảm bảo luồng truy cập của người dùng thực hoạt động bình thường, và đảm bảo các chỉ thị trong .htaccess không xung đột với các logic mã nguồn hiện tại của website.
Câu hỏi thường gặp (FAQ)
AhrefsBot và SemrushBot có tuân thủ tệp robots.txt không?
Có, AhrefsBot và SemrushBot luôn tuân thủ tệp robots.txt. Cả hai nền tảng dữ liệu này đều được lập trình để đọc lệnh và tôn trọng quy định của giao thức loại trừ robot. Tuy nhiên, quản trị viên vẫn cần kết hợp thêm các lệnh cấm ở cấp độ máy chủ để thiết lập tính bảo mật đa lớp, phòng ngừa rủi ro từ các trình thu thập thông tin giả mạo User-Agent của họ.
Phương pháp nào tiết kiệm tài nguyên máy chủ nhất?
Thiết lập tường lửa ứng dụng web (WAF) qua Cloudflare là phương pháp tiết kiệm tài nguyên máy chủ nhất. Hệ thống chặn trực tiếp từ mạng phân phối nội dung giúp ngắt hoàn toàn các luồng truy cập ảo trước khi chúng tiêu thụ tài nguyên phần cứng tại máy chủ gốc (origin server), giúp giải phóng 100% dung lượng băng thông và tối ưu hóa chi phí vận hành.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!




