
Crawl budget (ngân sách thu thập dữ liệu) là tổng số lượng liên kết (URL) mà hệ thống tìm kiếm có khả năng và mong muốn thu thập trên một trang web trong một khoảng thời gian nhất định.
Trong lĩnh vực tối ưu hóa kỹ thuật (Technical SEO), việc nắm rõ định nghĩa crawl budget là gì giúp quản trị viên ngăn chặn tình trạng lãng phí tài nguyên máy chủ vào các trang web rác, kém chất lượng. Bằng cách thực thi các chiến lược phân bổ ngân sách chuẩn xác, hệ thống tìm kiếm sẽ luôn ưu tiên phát hiện và lập chỉ mục (index) các nội dung mới có giá trị chuyển đổi cao, từ đó thúc đẩy thứ hạng trang web một cách nhanh chóng.

Cơ Chế Hoạt Động Của Googlebot Và Quá Trình Thu Thập Dữ Liệu
Để làm chủ ngân sách thu thập dữ liệu, quản trị viên bắt buộc phải hiểu thấu đáo cơ chế vận hành nền tảng của hệ thống tìm kiếm thông qua hai quá trình cốt lõi.
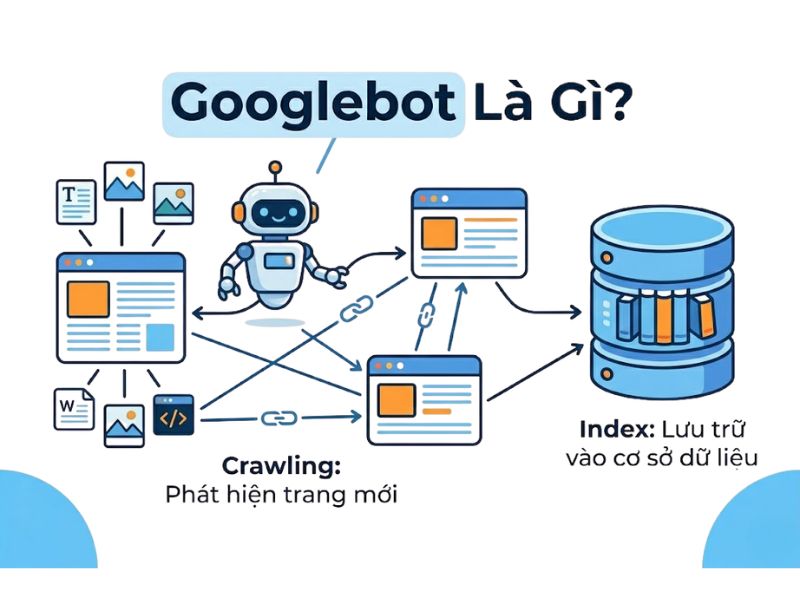
Googlebot là gì?
Googlebot là trình thu thập dữ liệu web tự động (spider/robot) của Google. Nhiệm vụ chuyên biệt của hệ thống robot này là liên tục truy cập các trang web, quét mã nguồn (HTML, CSS, JavaScript) và trích xuất dữ liệu để đưa về trung tâm lưu trữ. Quá trình bot Google thu thập dữ liệu diễn ra không ngừng nghỉ 24/7 để theo kịp sự thay đổi từng giây trên mạng Internet, đảm bảo kho dữ liệu của hệ thống luôn giữ được độ tươi mới.
Crawling là gì? Phân biệt giữa thu thập dữ liệu và lập chỉ mục
Crawling là bước tiếp cận đầu tiên khi Googlebot đi theo các liên kết nội bộ và liên kết ngoài để khám phá mạng lưới trang web. Sau khi hoàn tất bước này, các khối dữ liệu thô mới được chuyển sang quá trình lập chỉ mục (index website) để phân loại, lưu trữ và sẵn sàng phục vụ cho các truy vấn tìm kiếm của người dùng. Thu thập dữ liệu là điều kiện tiên quyết; một liên kết nếu không được thu thập sẽ vĩnh viễn không thể xuất hiện trên bảng xếp hạng tìm kiếm.
2 Thành Phần Nền Tảng Cấu Thành Ngân Sách Thu Thập Dữ Liệu
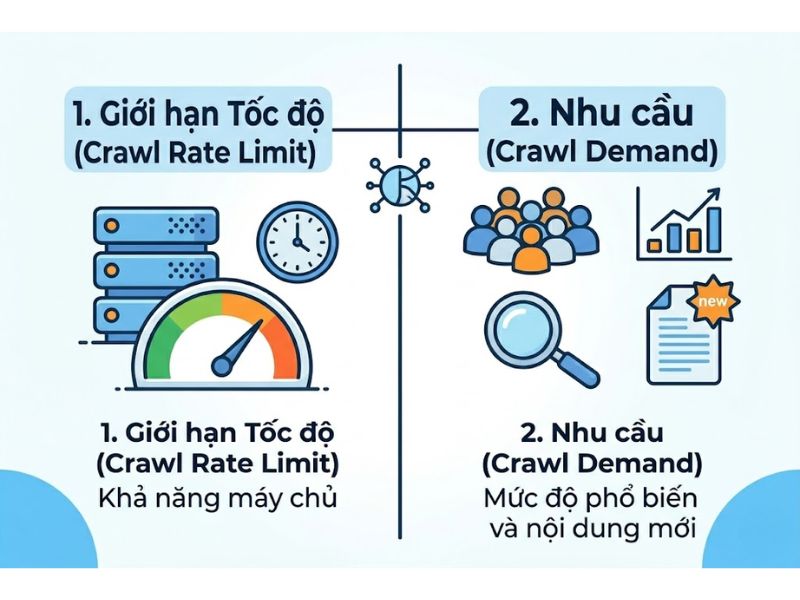
Googlebot không bao giờ phân bổ tài nguyên máy chủ một cách ngẫu nhiên. Ngân sách này được hệ thống định hình và điều tiết tự động bởi 2 biến số kỹ thuật quan trọng sau:
1. Giới hạn tốc độ thu thập (Crawl Rate Limit)
Crawl rate (giới hạn tốc độ thu thập) là số lượng kết nối đồng thời tối đa mà trình thu thập tạo ra khi quét một trang web. Mục đích cốt lõi của giới hạn này là bảo vệ tình trạng hoạt động ổn định của máy chủ lưu trữ (hosting/server). Nếu Googlebot gửi quá nhiều yêu cầu cùng lúc và nhận thấy máy chủ phản hồi chậm hoặc báo lỗi, hệ thống sẽ tự động giảm tốc độ thu thập xuống để không làm sập hạ tầng của bạn.
2. Nhu cầu thu thập (Crawl Demand)
Crawl demand là mức độ ưu tiên và sự hứng thú của công cụ tìm kiếm đối với một tài liệu web cụ thể. Nhu cầu này bị chi phối trực tiếp bởi độ tươi mới của nội dung và mức độ phổ biến của trang web trên Internet. Các trang web duy trì tần suất xuất bản bài viết chuyên sâu đều đặn và sở hữu mạng lưới liên kết chặt chẽ sẽ kích thích bot tìm kiếm quay lại quét dữ liệu liên tục với ngân sách dồi dào hơn.
Tại Sao Trang Web Phải Tối Ưu Crawl Budget Tuyệt Đối?
Tối ưu hóa ngân sách thu thập dữ liệu là bài toán then chốt xoay quanh việc kiểm soát Chi phí truy xuất thông tin (Cost of Retrieval). Chi phí truy xuất là tổng lượng tài nguyên máy chủ mà công cụ tìm kiếm phải bỏ ra để thu thập, lập chỉ mục, kết xuất và đánh giá một tài liệu web trước khi phục vụ người dùng.
Nguyên tắc của Thẩm quyền chủ đề (Topical Authority) khẳng định rõ ràng: chi phí xếp hạng một trang web không thể lớn hơn chi phí từ chối xếp hạng trang web đó. Hệ thống tìm kiếm luôn tìm cách giảm thiểu chi phí này ở mức tối đa. Nếu nội dung của bạn trùng lặp, kiến trúc web lỏng lẻo gây nghẽn cổ chai, chi phí xử lý sẽ vượt quá giá trị mà nội dung mang lại, dẫn đến việc công cụ tìm kiếm loại bỏ tài liệu đó khỏi hệ thống. Việc thực thi crawl budget SEO hoàn hảo giúp giảm thiểu triệt để chi phí truy xuất, từ đó đưa trang web trở thành một thực thể uy tín được ưu tiên lập chỉ mục ngay lập tức.
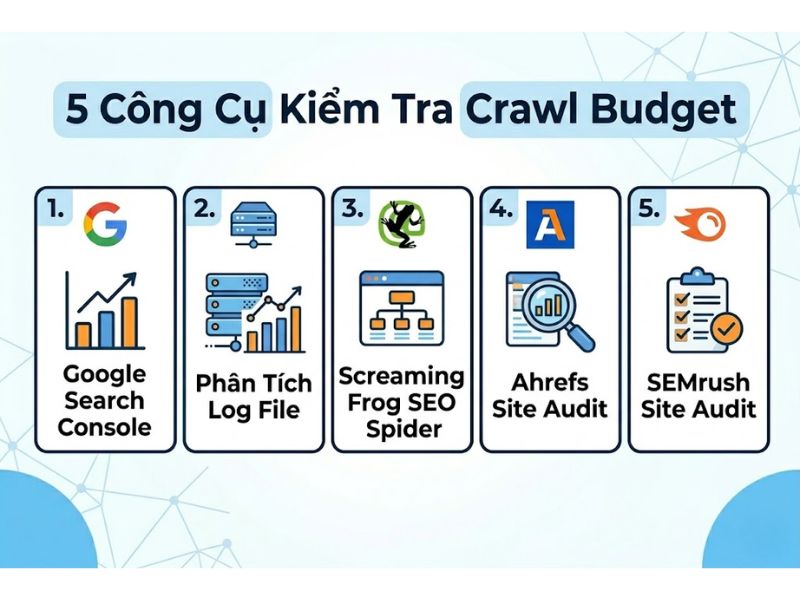
5 Cách Kiểm Tra Và Theo Dõi Crawl Budget Chuẩn Chuyên Gia
Để tối ưu hóa, bạn cần biết chính xác hệ thống tìm kiếm đang tiêu tốn ngân sách vào đâu. Dưới đây là 5 phương pháp và công cụ mạnh mẽ nhất để kiểm tra khả năng thu thập dữ liệu:
1. Google Search Console – Báo Cáo Crawl Stats
Đây là công cụ đo lường chính thống và miễn phí từ chính Google. Bằng cách truy cập Cài đặt > Thống kê thu thập dữ liệu (Crawl Stats), bạn sẽ nhận được báo cáo toàn cảnh về:
- Tổng số yêu cầu thu thập dữ liệu trong 90 ngày qua.
- Tổng kích thước dữ liệu máy chủ đã tải xuống.
- Thời gian phản hồi trung bình của máy chủ.
Nếu biểu đồ thời gian phản hồi tăng vọt, báo hiệu máy chủ đang quá tải và Googlebot đang buộc phải giảm tốc độ quét.
2. Phân Tích Nhật Ký Máy Chủ (Log File Analysis)
Đây là chiến lược kiểm tra cấp độ chuyên gia mang lại độ chính xác 100%. Bằng cách xuất tệp nhật ký trực tiếp từ máy chủ (Apache, Nginx) và phân tích bằng các công cụ như Screaming Frog Log File Analyser, bạn có thể nhìn thấu mọi bước đi của bot:
- Phát hiện chính xác những URL vô giá trị nào đang bị bot quét hàng ngàn lần mỗi ngày (Crawl traps).
- Nhận diện các mã phản hồi lỗi (4xx, 5xx) bị khuất lấp mà Google Search Console chưa kịp báo cáo.
- Xác định các trang chủ lực bị hệ thống “bỏ quên”.
3. Quét Toàn Diện Bằng Screaming Frog SEO Spider
Screaming Frog là phần mềm mô phỏng lại cách Googlebot thu thập dữ liệu trên trang web của bạn. Bằng cách thiết lập cấu hình quét tương tự Googlebot, phần mềm này giúp bạn:
- Liệt kê toàn bộ cấu trúc cây thư mục (Architecture).
- Phát hiện các chuỗi chuyển hướng (Redirect chains) và vòng lặp chuyển hướng (Redirect loops) gây cạn kiệt ngân sách.
- Tìm ra các liên kết mồ côi (Orphan pages) không nhận được bất kỳ luồng ngân sách thu thập nào từ hệ thống liên kết nội bộ.
4. Đánh Giá Sức Khỏe Trang Bằng Ahrefs Site Audit
Ahrefs cung cấp mô-đun Site Audit cực kỳ trực quan để chấm điểm sức khỏe kỹ thuật của trang web. Tính năng này tự động đánh dấu các yếu tố làm hao hụt crawl budget như:
- Trang tải chậm, kích thước tệp HTML hoặc hình ảnh quá lớn.
- Sự tồn tại của các liên kết gãy.
- Việc sử dụng sai thẻ Canonical gây bối rối cho trình thu thập.
5. Theo Dõi Khả Năng Thu Thập Cùng SEMrush Site Audit
Tương tự Ahrefs, SEMrush Site Audit có một báo cáo chuyên biệt mang tên “Crawlability” (Khả năng thu thập). Báo cáo này cảnh báo ngay lập tức nếu:
- Tệp robots.txt có cấu trúc chặn sai lệch khiến bot không thể vào các thư mục quan trọng.
- Bản đồ trang web (Sitemap) chứa các liên kết lỗi hoặc liên kết chuyển hướng.
- Độ sâu của trang web (Crawl depth) quá lớn, khiến các trang mất hơn 4 lượt nhấp chuột để tiếp cận.
9 Chiến Lược Tối Ưu Crawl Budget Hiệu Quả Nhất
Sau khi đã nắm rõ tình trạng hệ thống thông qua 5 công cụ trên, hãy triển khai đồng bộ 9 chiến lược thực chiến sau để tối đa hóa hiệu suất:
- Thiết lập quy tắc tệp Robots.txt nghiêm ngặt: Sử dụng lệnh Disallow để chặn bot truy cập các thư mục mã nguồn, trang tìm kiếm nội bộ, bộ lọc sản phẩm (Faceted navigation) hoặc các tham số URL động.
- Làm sạch sơ đồ trang web (Sitemap XML): Đảm bảo bản đồ trang web chỉ chứa các liên kết trả về mã trạng thái 200 OK. Tuyệt đối không để sitemap chứa trang lỗi 404 hoặc trang đã bị chặn bởi robots.txt.
- Tiêu diệt các chuỗi chuyển hướng: Trình thu thập dữ liệu sẽ lập tức rời đi nếu phải đi qua 3 đến 4 trạm chuyển hướng. Hãy cấu hình lệnh 301 trỏ trực tiếp từ liên kết gốc đến liên kết đích cuối cùng.
- Xóa sổ hoàn toàn lỗi máy chủ (5xx) và lỗi không tìm thấy (4xx): Bất kỳ lỗi máy chủ nào cũng làm bot hoảng sợ và giảm giới hạn tốc độ thu thập ngay lập tức. Sửa chữa hoặc điều hướng toàn bộ các liên kết gãy này.
- Áp dụng thẻ Canonical để xử lý nội dung trùng lặp: Dùng thẻ rel=”canonical” để hợp nhất luồng sức mạnh thu thập cho một liên kết duy nhất, tránh việc bot phải quét đi quét lại 1 bài viết trên 5 đường dẫn khác nhau.
- Xây dựng mạng lưới liên kết nội bộ ngữ nghĩa: Phân bổ các liên kết nội bộ khoa học từ trang chủ, trang danh mục lớn trỏ về các bài viết ngách. Một hệ thống Mạng lưới nội dung ngữ nghĩa (Semantic Content Network) chặt chẽ sẽ luân chuyển ngân sách thu thập lan tỏa đều khắp toàn bộ trang web.
- Loại bỏ nội dung mỏng (Thin Content): Xóa bỏ hoặc gộp các bài viết quá ngắn, nghèo nàn thông tin để dồn ngân sách cho các bài viết chuyên sâu (Quality Nodes) có khả năng xếp hạng cao.
- Nâng cấp tốc độ phản hồi máy chủ (TTFB): Thời gian máy chủ phản hồi càng thấp, bot càng quét được nhiều trang. Sử dụng bộ nhớ đệm (Cache), máy chủ cục bộ và tối ưu cơ sở dữ liệu để đạt TTFB dưới 200ms.
- Tối ưu hóa kiến trúc trang web phẳng: Đảm bảo mọi liên kết trên trang web đều có thể được truy cập chỉ trong vòng tối đa 3 lần nhấp chuột tính từ trang chủ.

Các Câu Hỏi Thường Gặp Về Ngân Sách Thu Thập Dữ Liệu (FAQ)
Trang web nhỏ (dưới 1.000 URL) có cần quan tâm đến Crawl Budget không?
Có. Mặc dù các trang web có quy mô dưới 1.000 liên kết thường được máy chủ tìm kiếm thu thập toàn bộ dữ liệu trong thời gian rất ngắn mà không lo cạn kiệt tài nguyên, nhưng việc chuẩn hóa cấu trúc kỹ thuật ngay từ đầu là vô cùng cần thiết. Nó giúp loại bỏ các mã lỗi ẩn, thiết lập luồng phân phối ngân sách chuẩn mực và tạo nền tảng vững chắc khi dự án mở rộng lên hàng chục ngàn liên kết trong tương lai.
Làm thế nào để biết hệ thống đang cạn kiệt ngân sách thu thập?
Có 3 dấu hiệu cảnh báo nghiêm trọng nhất: thứ nhất, các bài viết mới xuất bản mất từ nhiều tuần đến vài tháng mới được lập chỉ mục; thứ hai, những bản cập nhật trên bài viết cũ không được hệ thống ghi nhận; thứ ba, báo cáo trong Google Search Console xuất hiện tình trạng tăng vọt của nhóm lỗi kỹ thuật “Đã phát hiện – hiện chưa lập chỉ mục” (Discovered – currently not indexed).
Kết Luận
Việc nắm vững định nghĩa crawl budget là gì và triển khai đồng bộ các phương pháp kiểm tra, tối ưu hóa là nền tảng cốt lõi trong quản trị hạ tầng trang web. Một ngân sách thu thập dữ liệu được thiết lập chuẩn xác sẽ giảm thiểu hoàn toàn chi phí truy xuất thông tin của hệ thống tìm kiếm, đảm bảo các tài liệu giá trị luôn được ưu tiên lập chỉ mục với tốc độ cao nhất. Hãy duy trì thói quen quét hệ thống định kỳ bằng các công cụ chuyên sâu và dọn dẹp cấu trúc dữ liệu để xây dựng khối thẩm quyền chủ đề vững chắc, lâu dài.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



