
Trong bối cảnh bùng nổ của Trí tuệ nhân tạo tạo sinh (Generative AI) và các Mô hình ngôn ngữ lớn (LLMs), việc quản lý khối lượng khổng lồ dữ liệu phi cấu trúc đòi hỏi một giải pháp lưu trữ hoàn toàn mới. Khi tìm hiểu về hạ tầng dữ liệu hiện đại, câu hỏi Vector Database là gì đang trở thành tâm điểm của các kỹ sư dữ liệu và nhà phát triển AI. Bài viết này sẽ phân tích chuyên sâu về kiến trúc kỹ thuật, thuật toán cốt lõi và ứng dụng thực tiễn của hệ quản trị cơ sở dữ liệu vector, vượt ra ngoài các khái niệm lưu trữ truyền thống.

Vector Database là gì dưới góc độ kỹ thuật và kiến trúc dữ liệu?
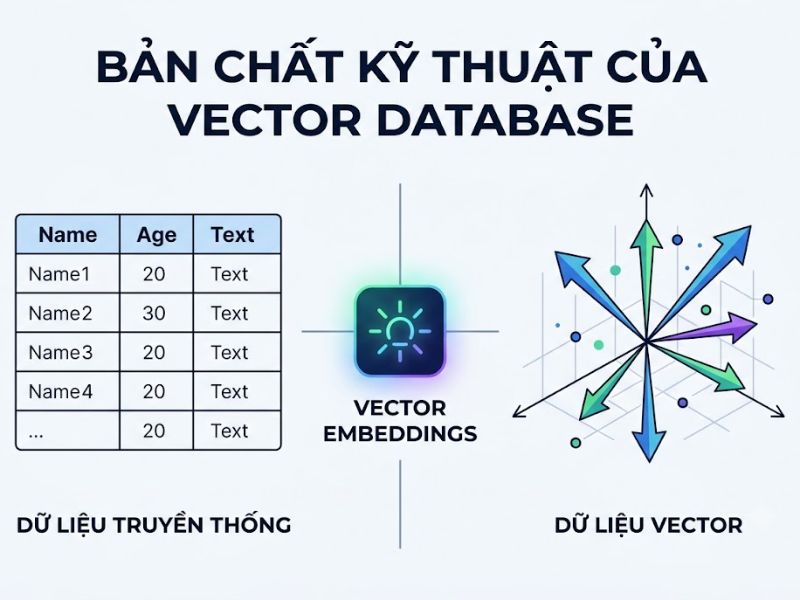
Vector Database là gì? Khái niệm này chỉ một loại cơ sở dữ liệu chuyên dụng được thiết kế đặc biệt để lưu trữ, lập chỉ mục, quản lý và truy xuất các biểu diễn toán học của dữ liệu được gọi là “vector embeddings”. Thay vì lưu trữ dữ liệu dưới dạng văn bản tĩnh hoặc bảng quan hệ, cơ sở dữ liệu vector lưu trữ thông tin dưới dạng các dãy số thực trong một không gian toán học đa chiều (n-dimensional space), cho phép hệ thống tính toán và đo lường khoảng cách hoặc độ tương đồng giữa các điểm dữ liệu.
“Theo nghiên cứu từ Viện Công nghệ Thông tin, cơ sở dữ liệu vector là xương sống của mọi hệ thống AI hiện đại, giải quyết triệt để nút thắt cổ chai trong việc xử lý dữ liệu phi cấu trúc (unstructured data) như văn bản, hình ảnh, âm thanh và video bằng cách chuyển hóa chúng thành ngôn ngữ mà máy học có thể hiểu được.”
Vector Embeddings trong không gian đa chiều
Để hiểu sâu hơn về cơ sở dữ liệu vector, chúng ta cần nắm vững cơ chế tạo ra vector embeddings. Các mô hình AI (như text-embedding-ada-002 của OpenAI hoặc BERT) sẽ nạp dữ liệu thô và xuất ra một mảng các số thực. Mỗi con số đại diện cho một đặc trưng ngữ nghĩa của dữ liệu đó. Một mô hình có thể ánh xạ một tài liệu thành một vector có 768 chiều hoặc 1536 chiều. Khi hai đoạn văn bản có ý nghĩa tương đồng nhau, các vector của chúng sẽ nằm gần nhau trong không gian đa chiều này.
Các thuật toán cốt lõi vận hành Vector Database
Cơ sở dữ liệu vector không tìm kiếm theo các từ khóa khớp chính xác (keyword matching) mà dựa trên tìm kiếm ngữ nghĩa (semantic search) thông qua việc đo lường độ gần gũi.
1. Thuật toán tìm kiếm lân cận gần nhất (K-Nearest Neighbors – kNN)
kNN là phương pháp tra cứu cơ bản nhất, trong đó hệ thống sẽ tính toán khoảng cách từ vector truy vấn đến toàn bộ các vector có trong cơ sở dữ liệu để tìm ra ‘k’ vector gần nhất. Mặc dù cho ra kết quả chính xác tuyệt đối, thuật toán này tiêu tốn quá nhiều tài nguyên tính toán (O(N)) và không khả thi với kho dữ liệu hàng tỷ bản ghi.
2. Thuật toán lân cận gần nhất gần đúng (Approximate Nearest Neighbor – ANN)
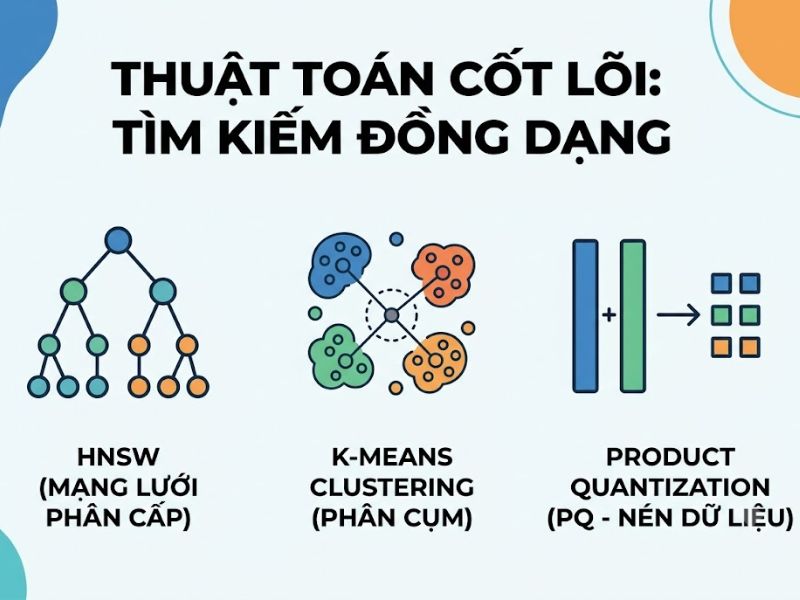
Để giải quyết bài toán hiệu suất của kNN, các cơ sở dữ liệu vector hiện đại sử dụng thuật toán ANN. Thuật toán này đánh đổi một tỷ lệ nhỏ về độ chính xác (Precision) để đổi lấy tốc độ truy xuất siêu tốc (tính bằng mili-giây). Các cấu trúc dữ liệu phổ biến phục vụ ANN bao gồm:
- HNSW (Hierarchical Navigable Small World): Xây dựng một đồ thị đa tầng, cho phép tìm kiếm nhanh từ các điểm tổng quát xuống các điểm chi tiết.
- IVF (Inverted File Index): Phân cụm không gian vector thành các ô (cells) dạng biểu đồ Voronoi, giới hạn phạm vi tìm kiếm chỉ trong các cụm chứa vector truy vấn.
- PQ (Product Quantization): Kỹ thuật nén dữ liệu giúp giảm dung lượng bộ nhớ của vector nhưng vẫn duy trì khả năng tính toán khoảng cách.
3. Các phép đo độ tương đồng (Similarity Measures)
Khi hệ thống xác định vị trí của các vector, nó sử dụng các công thức toán học không gian để đo lường:
- Cosine Similarity: Đo lường góc giữa hai vector. Góc càng nhỏ (Cosine tiến gần đến 1), dữ liệu càng giống nhau về mặt ngữ nghĩa, bất kể độ dài vector.
- Dot Product (Tích vô hướng): Nhân các thành phần tương ứng của hai vector. Hiệu quả khi các vector đã được chuẩn hóa.
- Euclidean Distance (L2 Norm): Đo khoảng cách đường thẳng giữa hai điểm trong không gian. Khoảng cách càng ngắn, sự tương đồng càng cao.
So sánh Vector Database với Relational Database (SQL) và NoSQL
Việc đặt Vector Database lên bàn cân với các hệ quản trị cơ sở dữ liệu truyền thống giúp làm rõ giá trị cốt lõi của hệ thống này.
| Tiêu chí | Relational Database (SQL) | Cơ sở dữ liệu NoSQL | Vector Database |
| Loại dữ liệu chính | Dữ liệu có cấu trúc cao (Bảng, hàng, cột). | Dữ liệu bán cấu trúc (JSON, Document, Key-Value). | Dữ liệu phi cấu trúc đã được mã hóa thành Vector Embeddings. |
| Cơ chế truy vấn | Khớp chính xác xác định (Exact Match), dùng SQL query. | Truy vấn theo khóa, thuộc tính, hoặc text-search cơ bản. | Tìm kiếm độ tương đồng (Similarity/Semantic Search). |
| Kiến trúc Indexing | B-Tree, Hash Index. | Inverted Index, B-Tree. | HNSW, IVF, LSH, PQ. |
| Kết quả trả về | Có hoặc không có (True/False hoặc tập hợp bản ghi chính xác). | Danh sách tài liệu khớp với siêu dữ liệu. | Danh sách xếp hạng theo độ gần gũi về ngữ nghĩa (kết quả mang tính xác suất). |
Tầm quan trọng của Vector Database trong kỷ nguyên Generative AI
Hiểu Vector Database là gì là bước đầu, áp dụng nó để giải quyết các giới hạn của Trí tuệ nhân tạo mới là yếu tố quyết định giá trị doanh nghiệp.
Tối ưu hóa mô hình RAG (Retrieval-Augmented Generation)
Các LLM như GPT-4 thường gặp phải vấn đề “ảo giác thông tin” (Hallucinations) và bị giới hạn bởi dữ liệu huấn luyện gốc không được cập nhật realtime. RAG kết hợp Vector Database để giải quyết triệt để vấn đề này.
- Thay vì tinh chỉnh (fine-tune) mô hình tốn kém, doanh nghiệp đưa tài liệu nội bộ vào Vector Database.
- Khi người dùng đặt câu hỏi, hệ thống chuyển câu hỏi thành vector, tìm kiếm ngữ nghĩa trong Vector Database để lấy ra các đoạn tài liệu liên quan nhất.
- LLM dùng chính các tài liệu này làm ngữ cảnh (context) để sinh ra câu trả lời chính xác, có căn cứ và cập nhật nhất.
Semantic Search và Xử lý ngôn ngữ tự nhiên (NLP)
Các công cụ tìm kiếm truyền thống phụ thuộc vào việc người dùng phải gõ chính xác từ khóa. Với cơ sở dữ liệu vector, người dùng có thể tìm kiếm bằng ngôn ngữ tự nhiên, thậm chí hỏi một câu hỏi mơ hồ. Hệ thống vẫn tìm ra kết quả chính xác dựa trên ý nghĩa đằng sau câu chữ.

Các hệ quản trị cơ sở dữ liệu Vector (Vector DBMS) hàng đầu
Thị trường hạ tầng dữ liệu đang chứng kiến sự trỗi dậy của nhiều nền tảng Vector DBMS mạnh mẽ:
- Pinecone: Dịch vụ cơ sở dữ liệu vector dạng Managed Cloud (SaaS) được tối ưu hóa cho tốc độ và khả năng mở rộng với độ trễ cực thấp. Rất phổ biến trong các ứng dụng AI tạo sinh.
- Milvus: Mã nguồn mở, kiến trúc phân tán đám mây. Milvus có khả năng xử lý hàng tỷ vector và hỗ trợ đa dạng các thuật toán index (FAISS, HNSW).
- Weaviate: Vector search engine mã nguồn mở có khả năng tự động vectorize dữ liệu đầu vào (tích hợp sẵn các mô hình ML) và hỗ trợ tìm kiếm kết hợp (hybrid search – cả vector và keyword).
- ChromaDB: Phù hợp cho việc phát triển ứng dụng AI cục bộ (local) với cấu trúc nhẹ, dễ dàng tích hợp cùng LangChain và LlamaIndex.
Ứng dụng thực tiễn của Vector Database trong doanh nghiệp
Việc áp dụng cơ sở dữ liệu vector không chỉ giới hạn ở các phòng thí nghiệm AI mà đã thâm nhập sâu vào vận hành doanh nghiệp:
- Hệ thống gợi ý thông minh (Recommendation Systems): Các nền tảng như Netflix hay Spotify sử dụng vector embeddings để biểu diễn hồ sơ người dùng (sở thích) và thuộc tính sản phẩm. Vector Database giúp tính toán độ tương đồng tức thời để đưa ra các gợi ý chính xác cá nhân hóa cao.
- Tìm kiếm hình ảnh qua hình ảnh (Reverse Image Search): Trong thương mại điện tử, người dùng tải lên một bức ảnh áo sơ mi. Hệ thống nhúng ảnh thành vector và truy xuất các sản phẩm có vector gần giống nhất trong kho hàng để hiển thị.
- Phát hiện gian lận và bất thường (Anomaly Detection): Dữ liệu giao dịch được chuyển thành không gian đa chiều. Các giao dịch hợp pháp sẽ tạo thành các cụm vector. Một giao dịch lừa đảo sẽ nằm ở một vị trí bất thường (khoảng cách rất xa so với các cụm), cho phép hệ thống bảo mật khóa giao dịch ngay lập tức.

Câu hỏi thường gặp (FAQ)
Vector Database có thay thế hoàn toàn Relational Database không?
Không. Hai hệ thống này giải quyết các bài toán hoàn toàn khác nhau. Relational Database vẫn là tiêu chuẩn vàng cho dữ liệu giao dịch (ACID, tài chính, thanh toán). Vector Database đóng vai trò lưu trữ và xử lý dữ liệu phi cấu trúc phục vụ AI và tìm kiếm ngữ nghĩa. Doanh nghiệp hiện đại cần vận hành song song cả hai.
Tính năng Hybrid Search trong Vector Database là gì?
Đây là sự kết hợp giữa tìm kiếm độ tương đồng vector (Semantic search) và tìm kiếm từ khóa truyền thống (BM25/Keyword search) trong cùng một truy vấn. Hybrid search giúp cân bằng giữa việc hiểu ngữ nghĩa và đảm bảo không bỏ sót các thuật ngữ chuyên ngành mang tính chính xác tuyệt đối.
Làm thế nào để chọn đúng Vector Database cho dự án AI?
Quyết định dựa trên 3 yếu tố cốt lõi: 1) Quy mô dữ liệu (Scale) – Nếu là hàng tỷ vector, hãy chọn Milvus; 2) Tính tiện lợi (Ease of use) – Nếu muốn triển khai nhanh không cần quản lý hạ tầng, Pinecone là tối ưu; 3) Khả năng tùy chỉnh – Weaviate hoặc Qdrant sẽ phù hợp nếu dự án cần tính năng hybrid search và quản lý metadata phức tạp.
Kết luận
Bài viết đã phân tích toàn diện và sâu sắc để trả lời triệt để cho truy vấn Vector Database là gì. Không chỉ đơn thuần là một trào lưu công nghệ, cơ sở dữ liệu vector là mảnh ghép hạ tầng không thể thiếu giúp mở khóa toàn bộ tiềm năng của dữ liệu phi cấu trúc. Bằng việc tận dụng thuật toán ANN, biểu diễn không gian đa chiều và kiến trúc RAG, Vector Database cung cấp bộ nhớ dài hạn, chính xác và có khả năng mở rộng vô hạn cho các mô hình AI tiên tiến nhất hiện nay. Các doanh nghiệp nắm bắt và làm chủ công nghệ này sớm sẽ có lợi thế cạnh tranh tuyệt đối trong việc xây dựng các ứng dụng thông minh vượt trội.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



