
Nếu bạn đang tự hỏi LLM là gì, thì về mặt kỹ thuật, LLM (Large Language Model – Mô hình ngôn ngữ lớn) là một dạng trí tuệ nhân tạo chuyên sâu dựa trên kiến trúc mạng nơ-ron học sâu (Deep Learning), được huấn luyện trên hàng tỷ, thậm chí hàng nghìn tỷ tham số từ các tập dữ liệu văn bản khổng lồ. Mục đích cốt lõi của LLM là hiểu, phân tích, suy luận và tạo ra ngôn ngữ tự nhiên tương tự như con người. Việc nắm bắt chính xác và toàn diện bản chất LLM là gì sẽ giúp các kỹ sư và doanh nghiệp khai thác tối đa năng lực của AI tạo sinh trong môi trường thực tiễn.

LLM là gì? Khái niệm Mô hình ngôn ngữ lớn nền tảng
Khái niệm LLM là gì có thể được giải đáp một cách trực diện: Đây là một hệ thống thuật toán học máy phức tạp, được thiết kế để xử lý ngôn ngữ tự nhiên thông qua việc dự đoán phân phối xác suất của từ (token) tiếp theo trong một chuỗi văn bản. Mô hình biểu diễn toán học các mối quan hệ ngữ nghĩa, cú pháp bằng cách ánh xạ các từ vựng vào một không gian vector đa chiều (Embeddings).
“Mô hình ngôn ngữ lớn bản chất là một cấu trúc nén tri thức thống kê khổng lồ vào không gian mạng nơ-ron, cho phép hệ thống trích xuất suy luận ngôn ngữ thông qua việc phân tích xác suất và trọng số toán học.”
Cơ chế hoạt động của Mô hình ngôn ngữ lớn (LLM)
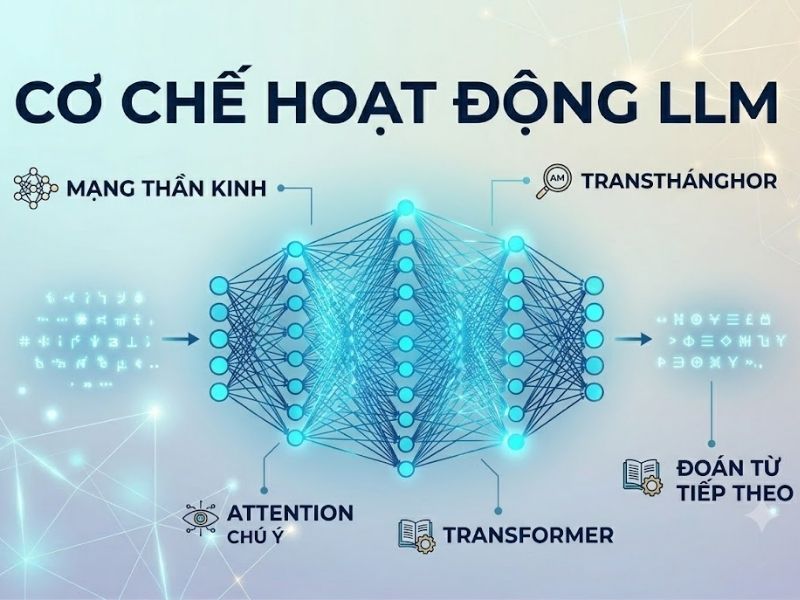
Để hiểu sâu hơn hệ thống LLM là gì vận hành ra sao, chúng ta cần phân tích kiến trúc lõi cốt lõi của công nghệ này. Hầu hết các LLM hiện đại đều dựa trên kiến trúc mạng nơ-ron có tên là Transformer.
Kiến trúc Transformer và cơ chế Self-Attention (Tự chú ý)
Được giới thiệu vào năm 2017 bởi đội ngũ nghiên cứu của Google (Vaswani et al.) qua bài báo “Attention Is All You Need”, Transformer đã thay đổi hoàn toàn cách máy tính xử lý Xử lý ngôn ngữ tự nhiên (NLP).
Cơ chế cốt lõi tạo nên sức mạnh của kiến trúc này là Self-Attention. Quá trình này cho phép mô hình đánh giá và gán trọng số (tầm quan trọng) cho các từ khác nhau trong cùng một ngữ cảnh đầu vào, bất kể vị trí khoảng cách của chúng. Nhờ đó, LLM duy trì được liên kết ngữ cảnh dài hạn, giải quyết triệt để vấn đề quên dữ liệu của các mô hình RNN hay LSTM trước đây.
Quá trình mã hóa (Encoding) và giải mã (Decoding)
- Encoder (Bộ mã hóa): Chịu trách nhiệm phân tích văn bản đầu vào, trích xuất đặc trưng ngữ nghĩa và chuyển đổi chúng thành các ma trận vector toán học.
- Decoder (Bộ giải mã): Nhận ma trận từ Encoder, kết hợp với các từ đã được dự đoán ở bước trước để tính toán xác suất và xuất ra từ vựng tiếp theo một cách tuần tự (Autoregressive).
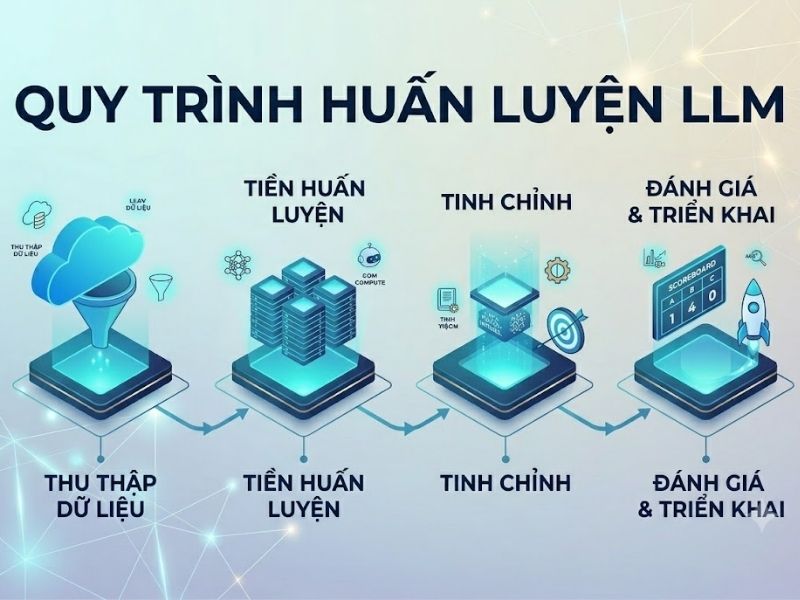
Quy trình huấn luyện LLM tiêu chuẩn công nghiệp
Một vòng đời để tạo ra các Mô hình ngôn ngữ lớn tối ưu đòi hỏi hàng nghìn GPU tính toán song song, kéo dài qua 3 giai đoạn nền tảng:
- Tiền huấn luyện (Pre-training): Đây là bước mô hình tiếp thụ dữ liệu văn bản thô, không gán nhãn quy mô Petabyte (Wikipedia, Common Crawl, sách khoa học). Tại đây, AI học các quy tắc ngữ pháp, cú pháp và các sự kiện thế giới cơ bản.
- Tinh chỉnh cấu trúc (Fine-tuning): Mô hình nền tảng (Foundation model) được tiếp tục huấn luyện trên các tập dữ liệu nhỏ hơn, có gán nhãn chất lượng cao để chuyên biệt hóa khả năng thực hiện một tác vụ cụ thể (tóm tắt, phân tích cảm xúc, hoặc sinh mã nguồn).
- Học tăng cường từ phản hồi con người (RLHF): RLHF (Reinforcement Learning from Human Feedback) là bước kiểm soát an toàn quyết định. Thuật toán sẽ điều chỉnh trọng số của LLM dựa trên điểm đánh giá của các chuyên gia con người, đảm bảo kết quả đầu ra vô hại, hữu ích và chính xác với ý định của người dùng.
So sánh LLM và ChatGPT: Đâu là ranh giới kỹ thuật?
Rất nhiều người bị nhầm lẫn khi tìm kiếm thông tin về LLM là gì và đánh đồng định nghĩa này trực tiếp với ChatGPT. Dưới đây là bảng phân tách chi tiết:
| Tiêu chí kỹ thuật | Mô hình ngôn ngữ lớn (LLM) | ChatGPT |
| Định nghĩa bản chất | Là công nghệ nền tảng, kiến trúc thuật toán học sâu lõi (Ví dụ: họ mô hình GPT-4, LLaMA 3, PaLM 2, Claude 3). | Là một phần mềm ứng dụng (Chatbot) cụ thể được xây dựng bên trên nền tảng của một LLM. |
| Mục đích sử dụng | Cung cấp khả năng tính toán, xử lý ngôn ngữ đa năng thông qua các API cho nhà phát triển hệ thống. | Cung cấp giao diện đàm thoại thân thiện, giải quyết truy vấn trực tiếp cho người dùng cuối (End-user). |
| Mức độ tùy biến | Khả năng tinh chỉnh linh hoạt, tích hợp sâu vào hệ thống nội bộ của doanh nghiệp. | Hoạt động chủ yếu như một hộp đen (Black-box), các tham số đã được nhà cung cấp thiết lập cố định. |
Ứng dụng thực tiễn của Mô hình ngôn ngữ lớn trong doanh nghiệp
Khả năng phân tích ngôn ngữ sâu của LLM đang tái cấu trúc năng suất trong nhiều khối ngành trọng điểm:
- Tự động hóa phát triển phần mềm: Các trợ lý lập trình tích hợp LLM hỗ trợ sinh mã nguồn (Code generation), tìm lỗi (Debugging) và viết tài liệu mô tả cho các ngôn ngữ như Python, Java, C++. Dữ liệu thực tế ghi nhận mức tăng 30-40% hiệu suất lập trình.
- Phân tích và trích xuất dữ liệu phi cấu trúc: Ứng dụng trong ngành tài chính – pháp lý để đọc hiểu, tóm tắt và đối chiếu hàng vạn trang hợp đồng, báo cáo kiểm toán chỉ trong vài phút xử lý.
- Xây dựng hệ thống RAG nội bộ: Khả năng truy xuất thế hệ tăng cường (Retrieval-Augmented Generation) kết hợp LLM với cơ sở dữ liệu nội bộ để cung cấp thông tin chính xác, bảo mật theo thời gian thực cho nhân viên.

Ưu điểm và rào cản kỹ thuật của LLM hiện nay
Ưu thế về năng lực suy luận
LLM sở hữu sức mạnh của Zero-shot và Few-shot learning. Các mô hình hiện đại có khả năng thực thi các tác vụ logic mới hoàn toàn mà không cần trải qua bước huấn luyện dữ liệu lại từ đầu, tối ưu hóa đáng kể chi phí triển khai hệ thống.
Vấn đề “Ảo giác” (Hallucinations) và rủi ro tính toán
Rào cản học thuật lớn nhất hiện nay là Hallucinations – trạng thái mô hình tự tạo ra thông tin sai lệch nghiêm trọng nhưng trình bày với một cấu trúc ngôn ngữ vô cùng tự tin và logic. Nhà khoa học máy tính Yann LeCun đã chỉ ra rằng các LLM theo kiến trúc tự hồi quy (Autoregressive) hiện tại vẫn thiếu đi một bộ máy kiểm chứng thực tế vững chắc. Bên cạnh đó, chi phí tài nguyên điện toán (Inference cost) khổng lồ là bài toán mà các doanh nghiệp công nghệ phải giải quyết.
Câu hỏi thường gặp (FAQ) về ứng dụng LLM
Mô hình ngôn ngữ lớn có khả năng tư duy như con người không?
Không. Bản chất của LLM là các mô hình toán học thống kê dự đoán xác suất chuỗi từ. Chúng hoàn toàn không có nhận thức, cảm xúc hay khả năng hiểu được thế giới vật lý thực như bộ não con người.
Phương pháp tối ưu chi phí khi doanh nghiệp tích hợp LLM là gì?
Để tiết kiệm chi phí, doanh nghiệp nên ứng dụng kỹ thuật Lượng tử hóa (Quantization) để nén dung lượng mô hình, hoặc ưu tiên triển khai các LLM mã nguồn mở nhẹ (như Mistral-7B, LLaMA-8B) kết hợp cơ chế RAG thay vì mua API từ các mô hình thương mại đắt đỏ.
Sự khác biệt giữa LLM và AI tạo sinh (Generative AI) là gì?
Generative AI là khái niệm bao trùm (Umbrella term) chỉ mọi hệ thống AI có khả năng tạo ra dữ liệu mới (văn bản, hình ảnh, âm thanh, video). LLM là một nhánh con thuộc Generative AI, nhưng chỉ tập trung xử lý và tạo ra cấu trúc dữ liệu dưới dạng văn bản tự nhiên.
Đúc kết lại bản chất LLM là gì?
Khái quát về việc LLM là gì, đây là công nghệ nhận thức ngôn ngữ mang tính cách mạng của khoa học máy tính. Bằng sự kết hợp giữa khối lượng dữ liệu khổng lồ và sức mạnh tính toán song song, Mô hình ngôn ngữ lớn không chỉ dừng lại ở mức độ phần mềm, mà đang trở thành hạ tầng công nghệ thiết yếu để xây dựng một thế hệ các hệ thống tự động hóa thông minh trong tương lai.
Giảng viên Nguyễn Thanh Phương là chuyên gia chuyên sâu về Nghiên cứu khoa học, Ứng dụng AI, Digital Marketing và Quản trị bản thân. Với kinh nghiệm giảng dạy thực chiến, tác giả trực tiếp hướng dẫn ứng dụng phương pháp luận và phân tích dữ liệu chuyên sâu cho người học nên được sinh viên gọi là Thầy giáo quốc dân. Mọi nội dung chia sẻ đều tuân thủ nguyên tắc khách quan, thực chứng và mang giá trị ứng dụng cao, hướng tới mục tiêu cốt lõi: “Làm bạn tốt hơn!



